Комментарии 166
Крайности — это всегда плохо, мое мнение что будущее за технологиями, которые позволяют использовать несколько подходов одновременно, то есть дают возможность использовать тот подход и те инструменты, которые наилучшим способом решают поставленную задачу, причем несколько подходов можно использовать одновременно. Как пример, могу назвать .NET, C# в котором есть LINQ, да и теперь еще есть возможность использовать F#. Уверен что такие же возможности, есть и в других языках и технологиях, просто в будущем они должны стать более совершенными.
Ну это вы загнули, .NET никогда(!!!) не будет технологией будущего.
А тот же самый Python и Scala (у которой, кстати, есть ФАТАЛЬНЫЙ НЕДОСТАТОК) являются мультипарадигмальными языками в нормальном смысле этого слова. Не претендующие являть собой ООП, ФП или что-то иное.
PS: F#, C# как и LINQ не нужны. C# — глупая пародия на Java, F# — жалкая пародия на ML, а LINQ — никому не нужный костыль. Единственное что — у всех них нет фатального недостатка.
А тот же самый Python и Scala (у которой, кстати, есть ФАТАЛЬНЫЙ НЕДОСТАТОК) являются мультипарадигмальными языками в нормальном смысле этого слова. Не претендующие являть собой ООП, ФП или что-то иное.
PS: F#, C# как и LINQ не нужны. C# — глупая пародия на Java, F# — жалкая пародия на ML, а LINQ — никому не нужный костыль. Единственное что — у всех них нет фатального недостатка.
Зря вы так. C# очень мощный язык. Да, он начался как пародия на Java, но посмотрите сейчас — многие моменты в C# реализованы лучше, чем в Java. (и наоборот). Эти языки были и будут сосуществовать в конкуренции. Главный недостаток C# — ограниченность платформой Windows (да, есть Mono, но это не тоже самое, что весь .NET)
НЛО прилетело и опубликовало эту надпись здесь
Тоже интересно было бы узнать, в чем состоит фатальный недостаток Scala
Фатальный недостаток — самостоятельный термин.
И да, скала им явно обладает.
И да, скала им явно обладает.
Я очень люблю лурк, там можно провести много часов в упоительном угаре, но был бы благодарен за более конкретное описание оного. Я прочитал статью и не совсем понял, причем тут Scala. Сам перешел на нее полгода назад после 10 лет программирования на Джаве и получаю большое удовольствие. Хотелось бы понять, где я что проглядел.
Потому и не понимаете, раз 10 лет писали на Java). Скорее всего людям не нравиться то, что она работает поверх JVM.
Мысль понял. Видимо, понятие фатального недостатка весьма субьективно. По мне, так каждый язык хорош в своей области применения.
Кстати, да. Какое-то предубеждение к софту, работающему под JVM или CRT.
На мой взгляд это плюс, JVM имеет одни из самых быстрых виртуальных машин с JIT-ом, да и все библиотеки из java мира можно использовать… а не писать с нуля.
Лучшая виртуальная машина — её отсутствие :)
Компилятор создает код совместимый для всех устройств, в то время как VM может производить оптимизации конкретно на запущенном устройстве, имея при этом больше информации о процессоре и как под него оптимизировать код.
Может != делает. Сложность этого процесса такова, что разработка вменяемой VM стоит сумасшедших денег. Но и тогда в приоритете — надёжность, что не позволяет внедрять самые агрессивные способы оптимизации. Так что в реальности всё намного грустнее, чем в теории…
Компилятор создает код оптимизированный под указанный процессор. Что укажешь, то и создаст :)
Проблема в том что процессоров много. Приложения придется делать не только под виндовс/линукс/макось а еще и под конкретный процессор. Счастье-то какое… в итоге на странице закачки приложения будет порядка сотни вариантов выбора… если еще скомпилируют под все процессоры. А ведь нужно еще и тестировать! Как минимум каждый вариант приложения под предназначенный для него процессор… это кромешный ад.
Проще тогда компилировать приложение по месту… но тогда приходим к тому от чего уходили.
Проще тогда компилировать приложение по месту… но тогда приходим к тому от чего уходили.
Это возможно и без виртуальной машины. Если вы будете поставлять инсталлятор, хранящий код в одном из промежуточных представлений, использующихся в вашем компиляторе, то он во время инсталляции сможет осуществить оптимизирующую кодогенерацию под конкретную машину пользователя. В инфраструктуре LLVM что-то подобное, в принципе, уже можно сделать.
Ясно, что семейство платформ при подготовке такого инсталлятора вы себе уже представляете (для младшего набора команд скомпилирован сам инсталлятор, по всей видимости), так что весь зоопарк кодогенераторов такой инсталлятор вовсе не обязан нести на борту. Оптимизации ему нужны тоже исключительно машинно-зависимые, например, векторизатор (под SSE/2/3/4, AVX/2 в x86, например), машинно-независимые оптимизации уже выполнены на предыдующих стадиях компиляции.
Более того, если вас всё же не пугает наличие более высокоуровневых оптимизаций в составе инсталлятора, то в его опциях в привычном разделе «Modify» сможет появится пункт в стиле «Recompile with profiling information», в идеале, необходимую профилирующую информацию вы сможете собирать даже не останавливая приложения (семлирующий профайлер, в принципе, такое позволяет). То есть, сценарий такой: пользователь скачивает инсталлятор, устанавливает приложение. Работает. Подмечает, что, скажем, в воскресение приложение слабозагружено и потому некоторое небольшое падение его производительности некритично, но в то же время класс выполняемых им задач вполне типичен. Тогда пользователь запускает в воскресение (сам или по расписанию) инсталлятор, заходит в пункт «Modify» и там кликает по кнопке «Collect profiling information»). Спустя, скажем, сутки эдак в 4 утра, останавливает сбор профилирующей информации и давит «Recompile». Скорее всего, его попросят приостановить работу приложения, ну ничего, зато спустя пару минут пользователь получает приложение с возросшей производительностью.
Для всего этого не нужна виртуальная машина и компиляция в байткод. И для упрощения разработки нового языка архитектура, аналогичная JVM и .NET, тоже не строго обязательна. см. документацию к LLVM, оставлю тут из неё несколько картинок:

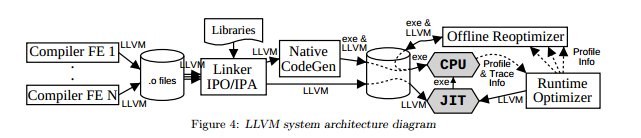
Более того, если вас всё же не пугает наличие более высокоуровневых оптимизаций в составе инсталлятора, то в его опциях в привычном разделе «Modify» сможет появится пункт в стиле «Recompile with profiling information», в идеале, необходимую профилирующую информацию вы сможете собирать даже не останавливая приложения (семлирующий профайлер, в принципе, такое позволяет). То есть, сценарий такой: пользователь скачивает инсталлятор, устанавливает приложение. Работает. Подмечает, что, скажем, в воскресение приложение слабозагружено и потому некоторое небольшое падение его производительности некритично, но в то же время класс выполняемых им задач вполне типичен. Тогда пользователь запускает в воскресение (сам или по расписанию) инсталлятор, заходит в пункт «Modify» и там кликает по кнопке «Collect profiling information»). Спустя, скажем, сутки эдак в 4 утра, останавливает сбор профилирующей информации и давит «Recompile». Скорее всего, его попросят приостановить работу приложения, ну ничего, зато спустя пару минут пользователь получает приложение с возросшей производительностью.
Для всего этого не нужна виртуальная машина и компиляция в байткод. И для упрощения разработки нового языка архитектура, аналогичная JVM и .NET, тоже не строго обязательна. см. документацию к LLVM, оставлю тут из неё несколько картинок:


VM производит еще оптимизации, собирая статистику о работе программы. Таким образом открываются возможности динамической оптимизации тех кусков кода, которые часто выполняются. Чем компилятор обеспечить не может.
Динамическую в смысле «всё время и полностью автоматически» — да, не может. Однако вопрос — а зачем ему это? Если для того, чтобы указать в документации, что он так может — то грош этому цена. Если для увеличения производительности — то в этом нет необходимости. Во-первых, как я описал выше, возможна компиляция кода с учётом этой самой статистики, которую можно осуществлять, скажем, по расписанию, хоть каждую ночь. Во-вторых, если переход к компилируемому варианту повышает производительность даже несмотря на отказ от вкусно называющихся технологий, то ровно это и надо сделать. Динамическая оптимизация на то и динамическая, что выполняется во время работы приложения — а сам анализ, необходимый для этой оптимизации, тоже занимает время.
Фатальный недостаток scala, с точки зрения $CompanyName, — то, что она написана не в $CompanyName и не подконтрольна $CompanyName.
Зачастую $CompanyName = M$, как в оригинале.
«Фатальный недостаток» — саркастическое описание.
Зачастую $CompanyName = M$, как в оригинале.
«Фатальный недостаток» — саркастическое описание.
Ну я не писал, о том, что .NET технология будущего, я привел его как пример, современного мультипарадигменного языка. Ну и я думаю, что вы зря относитесь к ,NET, C# и F# так предвзято.
На мой взгляд, C# не хватает лишь встроенных средств метапрограммирования. Всё остальное, включая инфраструктуру вокруг языка — более чем достойно.
Рефлексия же есть. Как вы используете ``метапрограммирование``?
Рефлексия не заменяет макросы.
зачем оно нужно?
Макросы? Ответ на этот вопрос не поместится в комментарий. Если вы серьезно хотите разобраться, то посмотрите на то, как они используются в тех языках, где они есть.
Короткий и не слишком внятный ответ: за тем же, зачем нужно ООП. Это дополнительный уровень абстракции, который позволяет вынести повторяющиеся паттерны в коде в одно место.
Короткий и не слишком внятный ответ: за тем же, зачем нужно ООП. Это дополнительный уровень абстракции, который позволяет вынести повторяющиеся паттерны в коде в одно место.
Давайте я влезу со своими пятью копейками.
Я описывал одно из возможных применений макросов на scala. И это лишь одно из применений. (если будете читать код, помните, что написан он давно — сейчас он скорее всего будет работать, но точно есть способы написать это лучше и лаконичнее).
Еще есть множество применений, совершенно не похожих на это. Например в ReactiveMongo требуется всего 1 сточка кода чтобы задать способ преобразования между классом любой сложности и его BSON представлением, после чего можно сохранять в базу и получать из базы уже типизированные объекты, а не бесформенные BSON. И вся эта радость проверяется на этапе компиляции и работает совершенно прозрачно для тех, кто знает scala.
Макросы в такой интерпретации — оперирование AST на этапе компиляции, причем без плагинов компилятора и прочих извращений — все на самом языке.
Я описывал одно из возможных применений макросов на scala. И это лишь одно из применений. (если будете читать код, помните, что написан он давно — сейчас он скорее всего будет работать, но точно есть способы написать это лучше и лаконичнее).
Еще есть множество применений, совершенно не похожих на это. Например в ReactiveMongo требуется всего 1 сточка кода чтобы задать способ преобразования между классом любой сложности и его BSON представлением, после чего можно сохранять в базу и получать из базы уже типизированные объекты, а не бесформенные BSON. И вся эта радость проверяется на этапе компиляции и работает совершенно прозрачно для тех, кто знает scala.
Макросы в такой интерпретации — оперирование AST на этапе компиляции, причем без плагинов компилятора и прочих извращений — все на самом языке.
Поэтому макросы нерекомендуют почти всегда использовать а рефлексия основа инструментария для большого колличества систем. Так как четко определенна, гарантии и работает в рантайме.
«Макросы не рекомендуют использовать» — это вы на основании опыта C/C++? В нем макросы действительно не рекомендуют использовать, т.к. они там работают на уровне токенов, плохо сынтегрированы с остальным языком (вплоть до того, что токен препроцессора и токен компилятора — это не одно и то же), и в целом очень убоги.
В тех ЯП, где макросы изначально делались как мощный инструмент — разнообразные Лиспы, или тот же D — такой проблемы нет, и никто не рекомендует их не использовать.
В тех ЯП, где макросы изначально делались как мощный инструмент — разнообразные Лиспы, или тот же D — такой проблемы нет, и никто не рекомендует их не использовать.
И тем не менее в C/C++ макросы популярная вешь, не смотря на их не достатки :)
плюсовые макросы это хардкор, реальный хардкор, и весьма полезная штуковина в прямых руках:
habrahabr.ru/post/199496/
habrahabr.ru/post/199496/
В Clojure макросы рекомендуют использовать только в крайних случаях, когда функций уже реально не хватает.
Так как четко определенна, гарантии и работает в рантайме
С каких это пор механизм A считается лучше механизма B только потому, что первый работает в рантайме, а второй — статический? Если уж сравнивать так, то я скорее решил бы наоборот. Статический анализ — путь к надёжности, простоте и автоматизации труда программиста, а не динамический.
Я имею ввиду макросы, как в Nemerle, которые фактически позволяют вводить новые синтаксические конструкции в язык. Рефлексия не то — она медленная, она многословная.
А как же T4 Templates?
Чего действительно не хватает — так это нормальной поддержки сторонних инструментов со стороны IDE.
Чего действительно не хватает — так это нормальной поддержки сторонних инструментов со стороны IDE.
В C# все относительно неплохо с метапрограммированием. Есть много инструментов для этого — Reflection, Expression, Emit, CodeDom, T4. Да, они пересекаются между собой, и вообще они как-то сбоку и кривоваты. Но уже на них можно многое делать.
Ну и Project Roslin уже на подходе (http://msdn.microsoft.com/en-us/vstudio/hh500769.aspx или habrahabr.ru/post/129833/)
Ну и Project Roslin уже на подходе (http://msdn.microsoft.com/en-us/vstudio/hh500769.aspx или habrahabr.ru/post/129833/)
Часто сталкивался с тем, что подобные мнения высказывают люди, которые не имеют ни малейшего представления о предмете высказывания, либо их мнение сформировано на основе стереотипов прошлого. Правда в том, что если вы действительно хорошо в чем-то разбираетесь, то скорее будете это защищать. Если вы в чем то разбираетесь плохо, то велика вероятность, что вы выступите агрессивно против этого. Поэтому по статистике (взятой с потолка) большая часть отрицательных мнений связана с незнанием матчасти, а не с реальным положением дел.
использовать несколько подходов одновременно
Что-то значит у Perl и его подходом Tim Toady не сложилось.
НЛО прилетело и опубликовало эту надпись здесь
Проблема в том чтобы во всем многообразии подходов и языков выбрать именно то что подойдет для решения задачи НЕ ПРОБОВАВ ранее этих подходов. Кто сможет сходу определить какая технология подойдет в конкретном случае, не изучив все технологии подряд?
Есть например задачи где достаточно DOS-а, но сейчас уже никто не начинает проекты под ДОС. Ибо технологии, прогресс… «2+2» просчитать проще в Windows7/8 нежели в ДОСе т.к. под них проще найти компиляторы, калькуляторы и т.д.
Есть например задачи где достаточно DOS-а, но сейчас уже никто не начинает проекты под ДОС. Ибо технологии, прогресс… «2+2» просчитать проще в Windows7/8 нежели в ДОСе т.к. под них проще найти компиляторы, калькуляторы и т.д.
Автор просто не осилил ФП. Называть монадные трансформеры хаком, а код на Си (который по сути — одна здоровенная монада IO) — красивым? Это что-то за пределами логики.
Ну серьезно. Те же stateful приложения на pure fp — это уже действительно за гранью.
Мне кажется, что основной посыл — использовать тот инструмент, который лучше всего подходит для решения конкретной задачи.
Мне кажется, что основной посыл — использовать тот инструмент, который лучше всего подходит для решения конкретной задачи.
А что со stateful? FRP красивее и проще поддерживать, чем ворох взаимодействующих между собой объектов с непредсказуемыми побочнными эффектами, за которыми с ростом приложения становится невозможно уследить. Побочные хорошо формализуются, разница лишь в том, что в императивных языках они встроены непосредственно в язык, а в Хаскеле инкапсулированы в отдельные монады, несущие состояние (State, ST, STM, IO). Это действительно позволяет сделать код более надежным и проще рассуждать о нем.
Я соглашусь, однако, с тем, что порог вхождения несколько выше для функционального программирования, т. к. требует определенного уровня аналитического мышления, который не у всех есть (из-за чего существует такая страшная вещь, как PHP).
С основным посылом про инструмент под задачу тоже спорить не буду, но мое убеждение, что эти инструменты нужно строить поверх парадигмы ФП, так как еще ни один род деятельности не пострадал от толковой формализации, вносимой математикой, а ФП — это именно оно, именно тот порядок в программировании, которого там не хватало.
Я соглашусь, однако, с тем, что порог вхождения несколько выше для функционального программирования, т. к. требует определенного уровня аналитического мышления, который не у всех есть (из-за чего существует такая страшная вещь, как PHP).
С основным посылом про инструмент под задачу тоже спорить не буду, но мое убеждение, что эти инструменты нужно строить поверх парадигмы ФП, так как еще ни один род деятельности не пострадал от толковой формализации, вносимой математикой, а ФП — это именно оно, именно тот порядок в программировании, которого там не хватало.
Не холивари ради, хочу узнать: вы реализовывали что-то серьезное с большим количеством состояний на чистом функциональном языке? Если да, то что именно?
Что считать критерием серьезности? Доводилось работать над простенькими веб-сервисами и сетевой компьютерной игрой, но ничего серьезного.
Что считать серьёзным? Участвовал в проекте со snap-framework + postgresql + redis. Работа с состоянием проблемой не была, на моей памяти, ни разу.
Ну и по этому поводу могу добавить (несколько утрированно, но всё же), что да, забабахать глобальную переменную проще, чем обдумывать, как бы там воткнуть общее состояние, вставить IO, где придётся, тоже проще, чем думать, как бы разделить IO и чистые функции, но вот недостаток ли то, что глобальные переменные с IO просто так, где попало, не вставить, это ещё большой вопрос. Есть плюсы и минусы, конечно.
код на Си по сути — одна здоровенная монада IOС точки зрения функционального подхода вы совершенно правы. К сожалению, это не имеет никакого отношения к реальному миру, с реальными последовательными коммандами процессору и тем, как происходит работа с IO.
Зря человека заминусовали. При наличии правильных инструментов (а как минимум в хаскеле и скале они есть) и определенном взгляде на вещи (приходит с опытом) ФП подход оказывается зачастую более лаконичным и декларативным и всегда более управляемым.
Не спорю, сложно повернуть свой мозг таким образом после первого опыта с не-фп стилями, но как только ты это увидел…
Не спорю, сложно повернуть свой мозг таким образом после первого опыта с не-фп стилями, но как только ты это увидел…
what have been seen cannot be unseen.Я просто оставлю это здесь cl.ly/image/0C3u3X1m0g0C, по-моему, отличительное преимущество Scala'ы как раз в том, что можно быть где-то посередине.
Постоянно выходят статьи с названием в стиле “Монадный подход к решению такой-то-уже-решенной-задачи”.Помните статьи на тему: «Как организовать цикл на XSLT»? Из той же серии. Правда, монады — это, может быть — попытка построить теорию. А вот какой смысл в трудночитаемых декларативных циклах на принципе рекурсии? На идею чистой декларативности накладывается весьма «шумная» XML-обвязка.
НЛО прилетело и опубликовало эту надпись здесь
Здесь, говоря об инструментах (ЯП и их парадигмах), почему-то забыли о тех, кто ими пользуется (программистах). А ведь они, люди, важнее всего.
Программа — это изложение мыслей. И у каждого человека свой образ мышления. Кому-то удобнее облекать свои мысли в форму объектов и сообщений. Кому-то — в функции, монады, предикаты или даже списки.
Так что помимо пригодности инструмента для решения задач, нужно ещё помнить об умениях. Умения куда полезнее теорий в нашем программистском деле. Вполне может так получиться, что используя не самый «пригодный» для задачи инструмент, мастер сделает дело быстрее и лучше, чем «понимающий» программист, использующий «самый подходящий» инструмент.
Программа — это изложение мыслей. И у каждого человека свой образ мышления. Кому-то удобнее облекать свои мысли в форму объектов и сообщений. Кому-то — в функции, монады, предикаты или даже списки.
Так что помимо пригодности инструмента для решения задач, нужно ещё помнить об умениях. Умения куда полезнее теорий в нашем программистском деле. Вполне может так получиться, что используя не самый «пригодный» для задачи инструмент, мастер сделает дело быстрее и лучше, чем «понимающий» программист, использующий «самый подходящий» инструмент.
Мне, как руководителю разработки, разнообразие языков и инструментов всегда на руку. Но, я, как не программист, применяю другие мерки. Эффективность, простота поддержки, скорость разработки, цена часа программиста. Другими словами, я отлично вижу недостатки php, но он решает свои задачи. Я понимаю, что Java это возможно уже архаично, но столько талантливых исполнителей с которыми приятно работать.
Думаю, стоит перестать относится к вашему языку программированию, как к святыне и идолу. Это просто инструмент. Лопатой проще копать, косой — косить. Совковой лопатой кидать, а штыковой копать. Есть задача, есть условия и реалии окружающего мира, есть ресурсы.
Развивать стоит все из этих инструментов, а эволюция и законы жизни сами сделают свое дело.
Но, я все равно запасаюсь попкорном, думаю, битвы в комментариях снова будут интересными.
Думаю, стоит перестать относится к вашему языку программированию, как к святыне и идолу. Это просто инструмент. Лопатой проще копать, косой — косить. Совковой лопатой кидать, а штыковой копать. Есть задача, есть условия и реалии окружающего мира, есть ресурсы.
Развивать стоит все из этих инструментов, а эволюция и законы жизни сами сделают свое дело.
Но, я все равно запасаюсь попкорном, думаю, битвы в комментариях снова будут интересными.
Пожалуйста, исследуйте еще компонентно ориентированое программирование, до сих пор непонятно, это ООП или нет.
Я всегда путаюсь в терминологии, но мне казалось, что функциональное программирование — это типа как Haskell. А то, что здесь имеется в виду, называется процедурным программированием как противоположность ООП. Хотя может я и ошибаюсь.
Вопрос о курице и яйце, что было раньше, функция или объект…
перфокарта!
Да-да-да, холивар. Посмотрите на математическую логику есть элементы множества (объекты), а есть термы (функции).
Забыли главное, правила и логика. Первыми были правила: дедукция, индукция, алгоритм…
Забыли главное, правила и логика. Первыми были правила: дедукция, индукция, алгоритм…
Безусловно, функция.
Примеры самых первых функций:
mov, add, inc — встроенные.
call — внешние.
Объект — сложная структура, к которой пришли через массив, содержащий как переменные, так и функции.
Примеры самых первых функций:
mov, add, inc — встроенные.
call — внешние.
Объект — сложная структура, к которой пришли через массив, содержащий как переменные, так и функции.
Лисп-машины существовали ещё до этого вашего 8086.
И не надо отождествлять объекты в С++ с ООП вообще.
И не надо отождествлять объекты в С++ с ООП вообще.
Функция. LISP появился в 1958. Даже раньше, чем стековые машины.
Создайте класс с состоянием и поведением, соблюдая инкапсуляцию данных. Настоящий ООП класс. А теперь попробуйте реализовать для хранения экземпляров этого класса паттерн репозиторий. Как будете доставать инкапсулированные данные из объекта для записи их в хранилище? Вот тут начинаются танцы с бубном.
Если хотите без хаков то паттерн Memento, если с хаками катит, то любой ОРМ вам смапит приватное состояние. Где бубны?
Паттерн Memento призывает к нарушению абстракции. Наш класс уже делает предположение, что его объекты будут хранить и расширяет свой интерфейс для этого. Это ни что иное как хак. Через рефлекшн читать — тоже хак, еще и работает медленно :)
Если обьекту надо хранить данные, то почему предположние о том, что он будет что-то хранить это хак?
Объекту самого себя хранить не надо! Это репозиторию надо хранить где-то этот объект, чтобы восстановить его состояние, например, после перезапуска приложения.
Если объект сам себя хранит, то это уже паттерн Active Record, который нарушает SRP, как и Memento.
Если объект сам себя хранит, то это уже паттерн Active Record, который нарушает SRP, как и Memento.
>Объекту самого себя хранить не надо! Это репозиторию надо хранить где-то этот объект, чтобы восстановить его состояние, например, после перезапуска приложения.
Если архитектурой системы предусмотрено, что объект будет где-то храниться, то для этого изначально создается интерфейс «хранимый (serializable) объект», который и реализуют все классы, предназначенные для хранения, поэтому ничто никуда не «расширяется», а реализуется в строгом соответствии с архитектурой.
А ваш пример «сначала сделали, а потом осознали, что его нужно будет хранить» — из области «сначала делаем, потом думаем».
Если архитектурой системы предусмотрено, что объект будет где-то храниться, то для этого изначально создается интерфейс «хранимый (serializable) объект», который и реализуют все классы, предназначенные для хранения, поэтому ничто никуда не «расширяется», а реализуется в строгом соответствии с архитектурой.
А ваш пример «сначала сделали, а потом осознали, что его нужно будет хранить» — из области «сначала делаем, потом думаем».
Мой пример как раз о том, что бесприкословное соблюдение принципов ООП не позволяет эффективно решить задачу. В реальной жизни появляются конвенции, типа реализации всеми сущностями вспомогательных интерфейсов, пометки классов атрибутом Serializable и прочие сделки с дьяволом. Это жизнь :)
Не вижу сделки с дьяволом. Еще раз: архитектура предполагает хранение определенного подмножества объектов — делаем эти объекты «хранимыми». Ни инкапсуляция, ни другие принципы ООП здесь не нарушаются.
Архитектура предполагает нарушение SRP, как по мне. Но если вы считаете, что совмещение в одном классе бизнес логики и вспомогательной логики для хранения — это одна ответственность, то мы друг друга не поймем. Видимо, у меня обостренное понимание чистого кода, другого объяснения просто не нахожу)
Хранить объект, реализующий в себе бизнес-логику? Хм… Уже одно это меня немного настораживает :)
В моем понимании хранению подлежат либо чистые классы-модели, не несущие в себе какой-либо логики (тогда читать/восстанавливать их состояние можно простыми геттерами/сеттерами), либо «продвинутые» модели, содержащие некую логику, но затрагивающую исключительно их собственные данные, но тогда сериализация/десереализация вполне является частью такой логики. А вот хранить объекты, реализующие бизнес-логику — это как-то… не знаю даже.
Видимо, у нас действительно очень разное понимание чистого кода и архитектуры.
В моем понимании хранению подлежат либо чистые классы-модели, не несущие в себе какой-либо логики (тогда читать/восстанавливать их состояние можно простыми геттерами/сеттерами), либо «продвинутые» модели, содержащие некую логику, но затрагивающую исключительно их собственные данные, но тогда сериализация/десереализация вполне является частью такой логики. А вот хранить объекты, реализующие бизнес-логику — это как-то… не знаю даже.
Видимо, у нас действительно очень разное понимание чистого кода и архитектуры.
То есть у объекта появляется две ответственности — какая-то основная логика и сериализация/десреиализация себя?
А ваш пример «сначала сделали, а потом осознали, что его нужно будет хранить» — из области «сначала делаем, потом думаем».К сожалению, это практически стандартный пример из реальной жизни. Обычно из области «заказчику вдруг захотелось»…
Memento это не паттерн сохранения данных, это паттерн предоставляения данных.
Когда вы говорите про нарушение SRP, вы всегда указывайте что вы под этим имеете ввиду. Есть как минимум десяток вариантов:
1. Хранение данных отдельная респонсибилити, поэтому в класе не может быть еще респонсибилити поведенения
2. Или храниене данных это не отдельная респонсибилити, но обьедениение двух поведений считаеться нарушением SRP
3. Или как в практиках DDD, у ентити респосибилити это обслуживание одной бизнес сущьности. Тоесть все что связано с этим обслуживание не нарушает SRP.
Если вы говрите про SRP как одно из первых двух, то это ваши проблемы, и я не смогу вас переубедить. Если же вы согласны на третее определение, то как только вы почитаете чем отличаеться Memento и Active Record, вы поймете что не правы.
Когда вы говорите про нарушение SRP, вы всегда указывайте что вы под этим имеете ввиду. Есть как минимум десяток вариантов:
1. Хранение данных отдельная респонсибилити, поэтому в класе не может быть еще респонсибилити поведенения
2. Или храниене данных это не отдельная респонсибилити, но обьедениение двух поведений считаеться нарушением SRP
3. Или как в практиках DDD, у ентити респосибилити это обслуживание одной бизнес сущьности. Тоесть все что связано с этим обслуживание не нарушает SRP.
Если вы говрите про SRP как одно из первых двух, то это ваши проблемы, и я не смогу вас переубедить. Если же вы согласны на третее определение, то как только вы почитаете чем отличаеться Memento и Active Record, вы поймете что не правы.
Если следовать принципам DDD и SOLID, то часть системы, содержащая бизнес логику вообще ничего не должна знать о способе хранения. Это должны быть обычные POCO (в случае С#) классы.
Реализуя паттерн Memento в этой части архитектуры, мы делаем предположение: Ага, наш ЯП не позволяет реализации репозитория извлечь инкапсулированные данные из POCO объекта. Поможем ему в этом, предоставив данные в виде Memento.
То есть слой бизнес логики «помогает» слою хранения данных. Он делает предположение о реализации хранилища. Хотя не должен, если мы следуем принципам DI и SRP.
Реализуя паттерн Memento в этой части архитектуры, мы делаем предположение: Ага, наш ЯП не позволяет реализации репозитория извлечь инкапсулированные данные из POCO объекта. Поможем ему в этом, предоставив данные в виде Memento.
То есть слой бизнес логики «помогает» слою хранения данных. Он делает предположение о реализации хранилища. Хотя не должен, если мы следуем принципам DI и SRP.
>То есть слой бизнес логики «помогает» слою хранения данных. Он делает предположение о реализации хранилища.
Не обязательно.
Лень рисовать, попробую на словах. Упрощенно:
1. Имеем класс-контроллер, реализующий бизнес-логику. Он ничего не знает ни про классы-данные, ни про реализацию хранилища (БД, файлы, сеть, и т.д.).
2. Имеем набор классов-данных, умеющих себя сериализовать самостоятельно (в текст, в json, в бинарный массив, и т.д.). Они не содержат бизнес-логики, они ничего не знают про хранилище.
3. Имеем класс хранилища, который на вход принимает сериализованный объект (т.е. текст, json, бинарный массив, и т.д.) и сохраняет его одному ему известным способом (в БД, в файл, в сеть, и т.д.). Он ничего не знает ни про бизнес-логику, ни про внутреннее устройство классов-данных.
Вопрос: кто кому «помогает», кто какие «предположения» делает, и где нарушаются принципы ООП?
Не обязательно.
Лень рисовать, попробую на словах. Упрощенно:
1. Имеем класс-контроллер, реализующий бизнес-логику. Он ничего не знает ни про классы-данные, ни про реализацию хранилища (БД, файлы, сеть, и т.д.).
2. Имеем набор классов-данных, умеющих себя сериализовать самостоятельно (в текст, в json, в бинарный массив, и т.д.). Они не содержат бизнес-логики, они ничего не знают про хранилище.
3. Имеем класс хранилища, который на вход принимает сериализованный объект (т.е. текст, json, бинарный массив, и т.д.) и сохраняет его одному ему известным способом (в БД, в файл, в сеть, и т.д.). Он ничего не знает ни про бизнес-логику, ни про внутреннее устройство классов-данных.
Вопрос: кто кому «помогает», кто какие «предположения» делает, и где нарушаются принципы ООП?
1 и 2 пункт вместе представляют собой классический процедурный подход, в котором данные отделяются от поведения. «Правильное ООП» подразумевает оперирование сущностями реального мира, которые сочетают в себе поведение и состояние. Мы говорим о разных вещах )
«Оперирование сущностями реального мира» — это принцип, ориентированный на новичков, помогающий им понять саму сущность ООП и азы ООД. Это ни в коем случае не «единственно правильное ООП».
Спасибо, прояснили, что такое «процедурный подход» в применении к ООП… Мне всегда казалось, что к нему дизайн реальных систем постепенно и приходит…
> Если следовать принципам DDD и SOLID, то часть системы, содержащая бизнес логику вообще ничего не должна знать о способе хранения. Это должны быть обычные POCO (в случае С#) классы.
Паттерн Memento как раз и отвязывает бизнес логику от знания о способе хранения. Memento вообще не говорит именно о том что данные предоставляються для хранения, данные вполне могут использоваться где угодно, например в аудите.
Если хотите доказать обратное, давайте ссылки на доказательства.
П.С. И бизнес классы получаються самые что не есть обычные POCO.
П.П.С. Как только вы согласитесь что Мементо не нарушает SRP, мы можем перейти к доказательству что мапинг при помощи рефлекшена, это просто реализация Мементо, а не какие-то там бубны.
Паттерн Memento как раз и отвязывает бизнес логику от знания о способе хранения. Memento вообще не говорит именно о том что данные предоставляються для хранения, данные вполне могут использоваться где угодно, например в аудите.
Если хотите доказать обратное, давайте ссылки на доказательства.
П.С. И бизнес классы получаються самые что не есть обычные POCO.
П.П.С. Как только вы согласитесь что Мементо не нарушает SRP, мы можем перейти к доказательству что мапинг при помощи рефлекшена, это просто реализация Мементо, а не какие-то там бубны.
Представьте, что у вас есть класс из сторонней библиотеки. И класс этот не предоставляет свои данные и не реализует паттерн Memento, потому что ему это не надо для работы. И Serializable он не помечен. Это обычный POCO класс.
Если захотите хранить его объекты, как будете это делать? Только рефлекшн-костылями.
Если захотите хранить его объекты, как будете это делать? Только рефлекшн-костылями.
Представьте, что у вас есть функция из сторонней библиотеки. И функция эта не предоставляет расширения своей логики. Это обычная функция. Если захотите модифицировать лоику, как будете это делать? Разве что IL реврайтинг.
Если обьект задизайнен так чтобы не показывать свои данные, то он так задизайнен. Значит автор обьекта готов показывать только тот контракт который показан. Очевидно же. Именно под этот юзкейс заточена реализация, протестированна и потдерживаеться. Все остальное придумки. Вы же не ожидаете что ООП обьект автоматически начнет работатть в Ремотинге? Или то что обьект станет транзакционным, или будет генерить евент стримы.
В том же DDD есть течения кторые вообще отказываються показывать данные. Тоесть ентити содержит только методы! И да, обьект и продолжает оставаться POCO, и продолжает укладываться в парадигму ООП.
Если обьект задизайнен так чтобы не показывать свои данные, то он так задизайнен. Значит автор обьекта готов показывать только тот контракт который показан. Очевидно же. Именно под этот юзкейс заточена реализация, протестированна и потдерживаеться. Все остальное придумки. Вы же не ожидаете что ООП обьект автоматически начнет работатть в Ремотинге? Или то что обьект станет транзакционным, или будет генерить евент стримы.
В том же DDD есть течения кторые вообще отказываються показывать данные. Тоесть ентити содержит только методы! И да, обьект и продолжает оставаться POCO, и продолжает укладываться в парадигму ООП.
Так и я о том. Если класс заранее не подразумевает хранение своих экземпляров, то пристроить хранение «сбоку» (соблюдая принцип открытости-закрытости), уже проблематично.
Вы перечитайте, что вы пишете :) Да, использовать что-то не по назначению — проблематично. Ювелирным молоточком проблематично забить гвоздь-сотку. Отверткой проблематично закрутить болт. Сканером проблематично пользоваться как копиром. Класс, не предназначенный дизайном для хранения, проблематично хранить.
Одно мне только непонятно: почему вас это так удивляет? ;)
Одно мне только непонятно: почему вас это так удивляет? ;)
А POCO/POJO — это, случайно, не аналог DTO — по крайней мере в части отсутствия поведения кроме геттеров/сеттеров?
Проблема терминологии. В контексте ORM POCO — это классы, не обремененные дополнительной логикой хранения. Хотя, в случае EF, это не так — фреймворк вынуждает все данные предоставлять в виде свойств, причем виртуальных. Иначе EF не сможет реализовать проксирование объектов, автоматический трекинг, ленивую загрузку и т.д. Так что EF POCO это не настоящее POCO :)
Скорее ровно наоборот. В PO*O часто стараются поместить всю бизнес-логику, четко разделив приложение на малосвязанные слои. Модель не знает вообще ни о чем, кроме бизнес-объектов и бизнес-процессов, в частности она не подозревает, что может где-то храниться, что может что-то подгрузить из хранилища. Ей доступны только операции типа new и delete для других классов и объектов модели, когда того требует бизнес-логика. Что не нужно на данном уровне абстракции тщательно инкапсулировано — в частности никаких геттеров/сеттеров для переменных. Никаких save и load, никаких serialize и unserialize, даже никаких флагов «грязности». Когда один объект модели получает управление, то он действует в предположении что всё что ему может понадобится (только классы и объекты модели) уже находится в памяти и он может добраться по ссылкам, не обращаясь ни к каким сущностям типа хранилищ или контроллеров. А хранилища при сохранении (оно вне модели) делают что-то типа снэпшота, а при загрузке восстанавливаются из него.
Да, кстати, можно докопаться на тему, что совмещение данных и поведения в одном классе само по себе сильно смахивает на нарушение SRP;-)
Будет ли нарушением абстракции требование к классу иметь способы (метод/конструктор/фабрика — это уже детали) создания Memento-объекта (м.б. он же DTO) и восстановления из него?
Слава богу, что вы не можете прочитать нечто инкапсулированное.
Никаких танцев с бубном. Ни один внешний объект не вправе потребовать у другого объекта предоставления каких-либо данных, которые изначально защищены. Для этого и существует инкапсуляция.
Для того, чтобы сохранить объект, вам нужно:
а) от репозитория — сказать, что именно вы хотите хранить;
б) от объекта — предоставить то, что нужно хранить.
Итого, репозиторию нужно знать, даст ли ему объект доступ к тем данным, которые он просит. Соответственно, он должен быть уверен, что объект обладает интерфейсом для получения этих данных. Значит, объект, который можно сохранить, должен этот интерфейс реализовывать.
Вы же хотите, чтобы некий абстрактный репозиторий имел возможность сохранять то, что захочет, нарушая принцип инкапсуляции — один из краеугольных принципов ООП. Если короче, вы хотите, чтобы ООП не было ООП. И это желание считаете минусом ООП.
Если короче — вы пытаетесь позвонить на арбуз и услышать в ответ «привет!».
Никаких танцев с бубном. Ни один внешний объект не вправе потребовать у другого объекта предоставления каких-либо данных, которые изначально защищены. Для этого и существует инкапсуляция.
Для того, чтобы сохранить объект, вам нужно:
а) от репозитория — сказать, что именно вы хотите хранить;
б) от объекта — предоставить то, что нужно хранить.
Итого, репозиторию нужно знать, даст ли ему объект доступ к тем данным, которые он просит. Соответственно, он должен быть уверен, что объект обладает интерфейсом для получения этих данных. Значит, объект, который можно сохранить, должен этот интерфейс реализовывать.
Вы же хотите, чтобы некий абстрактный репозиторий имел возможность сохранять то, что захочет, нарушая принцип инкапсуляции — один из краеугольных принципов ООП. Если короче, вы хотите, чтобы ООП не было ООП. И это желание считаете минусом ООП.
Если короче — вы пытаетесь позвонить на арбуз и услышать в ответ «привет!».
Все так. И предоставление объектом прямого доступа к данным для реализации хранения тоже будет являться нарушением инкапсуляции.
предоставление объектом прямого доступа к данным для реализации хранения тоже будет являться нарушением инкапсуляции
Нельзя нарушить инкапсуляцию, если её нет. Вы можете как использовать инкапсуляцию, если вам нужно что-либо сокрыть, так и не использовать её, если вам нужно расширить интерфейс. Прямой доступ к данным — это по сути те же геттеры/сеттеры. Соответственно, открывая доступ к свойствам, вы просто расширяете интерфейс (в широком смысле этого слова, а не в конкретной реализации сущностей «интерфейс» в различных ЯП).
Будучи чистыми, ФП-языки игнорируют возможности и ограничения, которые предоставляет физическая платформа…
Странное заявление. Программа — это модель, абстракция. В ней можно и нужно пренебрегать несущественными для решения конкретной задачи моментами.
В остальном же согласен. Парадигмы вполне можно совмещать так, чтобы пользоваться их преимуществами и не впадать в крайности.
Если исходить из всего абзаца статьи, то, думаю, имелась ввиду ситуация, когда для реализации программной модели вместо простого абстрагирования от реальной модели (т.е. отбрасывания ненужных деталей при сохранении базовой структуры реальной модели) создаётся абсолютно другая модель (т.е. полное переколбашивание реальной модели под мозг разработчика).
По-моему у автора чисто человеческое — не понял до конца идеи, и давать их говном поливать, пытаясь еще зацепить тех кто понял.
Сложно согласиться по поводу крайностей. Сила в DSL! Любая область имеет свой язык иначе ее невозможно было изучать. Математика, например, описывает и физические процессы, и симуляции, и алгоритмы и т.п. Причем умудряется строить трансъязыковые переходы без проблем. Так, что программирование по-хорошему еще не зрело, потому что мы пытаемся найти универсальный язык для всех задач, а не изучить все задачи и построить на их базе язык.
А мне, вот, товарищи, кажется, то будущее совсем не за языками программирования. Мне кажется что будущее за инструментами разработки. Текст хорош для описания последовательности действий, но современные программы это уже далеко не просто последовательности. В них присутствует компоновка и связи, которые гораздо удобнее было бы проводить не копируя текст туда-обратно, а перетаскивая блоки.
Еще один недостаток современного программирования — попытка свести к минимуму число понятий. У вас есть только объекты и функции — делайте с ними что хотите. Это, конечно, хорошо, когда ты только начинаешь обучение — меньше чего запоминать, но это сродни молотку со встроенной отверткой, кусачками, и зубилом. С помощью него, конечно, можно сделать многое, но лучше бы все эти функции были разделены на отдельные инструменты — было бы быстрее.
И из предыдущего параграфа следует следующий бич текстового программирования — с ростом числа понятий усложняется язык и компилятор. Становится сложнее изучать язык. Кроме того, не все логические конструкции можно лаконично описать текстом.
Вот и получается что гораздо умнее было бы не пытаться развивать то, что уже практически в тупике, а перескочить на следующий уровень — взглянуть на вещи по новому. Среда разработки, абстрагированная от языков программирования и позволяющая выполнять то же самое, но без привязки к синтаксису и работающая на более высоких понятиях стала бы, блин, спасением.
Еще один недостаток современного программирования — попытка свести к минимуму число понятий. У вас есть только объекты и функции — делайте с ними что хотите. Это, конечно, хорошо, когда ты только начинаешь обучение — меньше чего запоминать, но это сродни молотку со встроенной отверткой, кусачками, и зубилом. С помощью него, конечно, можно сделать многое, но лучше бы все эти функции были разделены на отдельные инструменты — было бы быстрее.
И из предыдущего параграфа следует следующий бич текстового программирования — с ростом числа понятий усложняется язык и компилятор. Становится сложнее изучать язык. Кроме того, не все логические конструкции можно лаконично описать текстом.
Вот и получается что гораздо умнее было бы не пытаться развивать то, что уже практически в тупике, а перескочить на следующий уровень — взглянуть на вещи по новому. Среда разработки, абстрагированная от языков программирования и позволяющая выполнять то же самое, но без привязки к синтаксису и работающая на более высоких понятиях стала бы, блин, спасением.
И вывод автора статьи гениален) Поддерживаю.
Вывод автора статьи примерно так же гениален, как совет «Лучше быть богатым и здоровым, чем бедным и больным».
За какой это «реальностью» надо наблюдать? Где она, та параллельная вселенная, в которой веб-фреймворки и системы распознавания образов существуют в виде реальных объектов? В качестве примера: сейчас я пишу генератор статичных сайтов. У меня в голове есть не одна модель — десятки. Любая из них применима к «окружающему миру». Но я выберу ту, которая мне больше нравится, и реализую на том языке программирования, который мне больше нравится (и они с большой вероятностью подойдут друг другу). Такая вот «эгоцентрическая» методология.
Разумеется, это не работает при наличии жёстких требований к результату. Но очень часто образцового «мира», под который должна подходить модель, попросту нет.
И только наблюдая за реальностью мы можем избавиться от тех религиозных заблуждений, которые в действительности ограничивают нас.
За какой это «реальностью» надо наблюдать? Где она, та параллельная вселенная, в которой веб-фреймворки и системы распознавания образов существуют в виде реальных объектов? В качестве примера: сейчас я пишу генератор статичных сайтов. У меня в голове есть не одна модель — десятки. Любая из них применима к «окружающему миру». Но я выберу ту, которая мне больше нравится, и реализую на том языке программирования, который мне больше нравится (и они с большой вероятностью подойдут друг другу). Такая вот «эгоцентрическая» методология.
Разумеется, это не работает при наличии жёстких требований к результату. Но очень часто образцового «мира», под который должна подходить модель, попросту нет.
Ну, распознаванием образов в реальном мире занимаются люди, здесь и надо копать :)
А насчет фреймворка, боясь попасть под минусы, скажу что плохо то понятие, которое не находит отражения в реальном мире. Веб-фреймворки зло :) Не существует их аналога в реальном мире потому, что корень зла лежит не в самих фреймворках, а вообще во всей софтвеерной архитектуре. Прежде чем хаять меня прочитайте еще один абзац :)
Когда зарождалась архитектура софта и веба, никто не думал о том, что компьютеры смогут стать отражением и дополнением реального мира. Компьютеры были вычислительными машинами. Все развивалось от необходимости решения вычислительных задач. Сейчас уже мало кто использует компьютер для рассчетов — в основном люди обмениваются материалами, узнают информацию и развлекаются. Вот и получается что задачи поменялись, а старое наследие осталось. Сейчас мы ваяем скульптуры гвоздём.
Я глубоко уверен что можно построить софтвеерную систему так, чтобы все её составляющие имели отражение в реальном мире. Мало того, я долго занимался этим вопросом и, если интересно, могу сказать как это возможно.
А насчет фреймворка, боясь попасть под минусы, скажу что плохо то понятие, которое не находит отражения в реальном мире. Веб-фреймворки зло :) Не существует их аналога в реальном мире потому, что корень зла лежит не в самих фреймворках, а вообще во всей софтвеерной архитектуре. Прежде чем хаять меня прочитайте еще один абзац :)
Когда зарождалась архитектура софта и веба, никто не думал о том, что компьютеры смогут стать отражением и дополнением реального мира. Компьютеры были вычислительными машинами. Все развивалось от необходимости решения вычислительных задач. Сейчас уже мало кто использует компьютер для рассчетов — в основном люди обмениваются материалами, узнают информацию и развлекаются. Вот и получается что задачи поменялись, а старое наследие осталось. Сейчас мы ваяем скульптуры гвоздём.
Я глубоко уверен что можно построить софтвеерную систему так, чтобы все её составляющие имели отражение в реальном мире. Мало того, я долго занимался этим вопросом и, если интересно, могу сказать как это возможно.
Я глубоко уверен что можно построить софтвеерную систему так, чтобы все её составляющие имели отражение в реальном мире. Мало того, я долго занимался этим вопросом и, если интересно, могу сказать как это возможно.
Очень интересно. (Чёрт, как-то криво звучит.)
Я когда-то писал статейку про структуру программы, максимально приближенную к реальной жизни: habrahabr.ru/post/192900/
Но с тех пор я немного расширил своё представление обо всём этом.
Программу можно представить в виде комнаты, в которой работает несколько человек. (каждый работник — это расширеное представление потока). Работники общаются между собой с помощью сообщений — когда работник хочет чтобы кто-то другой что-то сделал он оставляет ему сообщение. А тот обрабатывает поступающие сообщения по-очереди или исходя из каких-то приоритетов.
У каждого рабочего есть своё рабочее место, и к вещам (объектам), находящимся в нём, имеет доступ только он. Однако в комнате могут стоять и общедоступные предметы.
У каждой комнаты есть босс, который отвечает за взаимодействие с системой. Так же он ответственен за закрытие комнаты.
А вот что касается ОС:
Работники работают в комнате, а комнаты находятся в здании. Так вот здание — это как-раз отражение операционной системы в реальном мире. Выглядит это примерно так:
Представьте пользователя, как человека, сидящего за компьютером на крыше небоскреба. У него есть мышь, клавиатура и монитор. Провода от них идут через пол на самый верхний этаж-пентхауз. Этот этаж — огромная комната — основная в операционной системе. Работники этой комнаты отвечают за различные драйвера и аппаратуру в целом. Их задача — преобразовать сигнал от различного аппаратного обеспечения в универсальную форму.
Далее, на этаже ниже пентхауза, находятся служебные комнаты. Их задача — предоставить нижним этажам (с обычными комнатами) возможность совместного использования ресурсов системы.
На примере изображения:
В нижних комнатах имеются окна, которые они хотели бы отобразить. Окон много, видеобуфер — один.
Служебная комната «оконный менеджер» получает с нижних этажей все выводимые окна, компонует их и преобразует в матрицу пикселей.
А пентхауз предоставляет в пользование видео-буфер, в который и записывает новый кадр оконный менеджер. После чего кадр отправляется пользователю на крышу.
Такая схема работает и со всем остальным. Например, со звуком. Вместо видео-буфера — звук, выводимый в колонки, вместо оконного менеджера — микшер, получаещий звуки от многих нижних комнат и сливающий их в один. Вместо окон — набор частот.
Одно из весомых преимуществ системы в том, что служебные комнаты можно заменять — не нравится эксплорер — поменяй на файндер :) Не нравится менеджер клавиатуры — поменяй! Это еще и значит что появилась бы конкуренция между операционными системами и между служебными «комнатами» для них. Большая модульность — больший профит.
Я глубоко уверен что толкаться нужно от сущностей реального мира, а не виртуального — это бы в разы упростило и ускорило бы и разработку и обучение онной.
Но с тех пор я немного расширил своё представление обо всём этом.
Программу можно представить в виде комнаты, в которой работает несколько человек. (каждый работник — это расширеное представление потока). Работники общаются между собой с помощью сообщений — когда работник хочет чтобы кто-то другой что-то сделал он оставляет ему сообщение. А тот обрабатывает поступающие сообщения по-очереди или исходя из каких-то приоритетов.
У каждого рабочего есть своё рабочее место, и к вещам (объектам), находящимся в нём, имеет доступ только он. Однако в комнате могут стоять и общедоступные предметы.
У каждой комнаты есть босс, который отвечает за взаимодействие с системой. Так же он ответственен за закрытие комнаты.
А вот что касается ОС:
Работники работают в комнате, а комнаты находятся в здании. Так вот здание — это как-раз отражение операционной системы в реальном мире. Выглядит это примерно так:
Представьте пользователя, как человека, сидящего за компьютером на крыше небоскреба. У него есть мышь, клавиатура и монитор. Провода от них идут через пол на самый верхний этаж-пентхауз. Этот этаж — огромная комната — основная в операционной системе. Работники этой комнаты отвечают за различные драйвера и аппаратуру в целом. Их задача — преобразовать сигнал от различного аппаратного обеспечения в универсальную форму.
Далее, на этаже ниже пентхауза, находятся служебные комнаты. Их задача — предоставить нижним этажам (с обычными комнатами) возможность совместного использования ресурсов системы.
На примере изображения:
В нижних комнатах имеются окна, которые они хотели бы отобразить. Окон много, видеобуфер — один.
Служебная комната «оконный менеджер» получает с нижних этажей все выводимые окна, компонует их и преобразует в матрицу пикселей.
А пентхауз предоставляет в пользование видео-буфер, в который и записывает новый кадр оконный менеджер. После чего кадр отправляется пользователю на крышу.
Такая схема работает и со всем остальным. Например, со звуком. Вместо видео-буфера — звук, выводимый в колонки, вместо оконного менеджера — микшер, получаещий звуки от многих нижних комнат и сливающий их в один. Вместо окон — набор частот.
Одно из весомых преимуществ системы в том, что служебные комнаты можно заменять — не нравится эксплорер — поменяй на файндер :) Не нравится менеджер клавиатуры — поменяй! Это еще и значит что появилась бы конкуренция между операционными системами и между служебными «комнатами» для них. Большая модульность — больший профит.
Я глубоко уверен что толкаться нужно от сущностей реального мира, а не виртуального — это бы в разы упростило и ускорило бы и разработку и обучение онной.
Это микроядерная архитектура ОС. Ну плюс, возможно, юникс-вей при написании пользовательских программ. Уже давно есть такие операционные системы. У них есть свои проблемы, например, сложность разработки производительных систем на основе такой модели.
Микроядерная архитектура это хорошо, но она не позволяет делать то, о чем я говорил — подмену «служебных комнат» в реальном времени. Это должно быть так же просто как переустановить программу. Как бы вам понравилось самому выбирать какую оконную систему использовать, без необходимости менять ОС?
Насчет юникс-вей ничего не могу сказать. Не имел дело. В любом случае я не говорю что такого сейчас нет. Я говорю что всё это разбито на многие куски и собрать всё это воедино мне не кажется плохой идеей. Кроме того я предлагаю ответы на вопросы что такое программа, что такое ОС и как они работают и взаимодействуют. Используя этот подход можно объяснить это даже ребенку и вообще в значительной мере упростить программирование. Вместо непонятных терминов «классы, функции, интерфейсы, наследование», которые так пугали поначалу вы получаете понятные и ребенку «модели, действия, механизмы, развитие». И вы можете доходчиво и железно объяснить почему в некоторой ситуации надо делать так а не иначе, опираясь на эту модель.
Насчет юникс-вей ничего не могу сказать. Не имел дело. В любом случае я не говорю что такого сейчас нет. Я говорю что всё это разбито на многие куски и собрать всё это воедино мне не кажется плохой идеей. Кроме того я предлагаю ответы на вопросы что такое программа, что такое ОС и как они работают и взаимодействуют. Используя этот подход можно объяснить это даже ребенку и вообще в значительной мере упростить программирование. Вместо непонятных терминов «классы, функции, интерфейсы, наследование», которые так пугали поначалу вы получаете понятные и ребенку «модели, действия, механизмы, развитие». И вы можете доходчиво и железно объяснить почему в некоторой ситуации надо делать так а не иначе, опираясь на эту модель.
но она не позволяет делать то, о чем я говорил — подмену «служебных комнат» в реальном времен
насколько я в курсе, в этом вся суть микроядра и есть — возможность замены сервисов когда необходимо.
Как бы вам понравилось самому выбирать какую оконную систему использовать, без необходимости менять ОС?
я и сейчас это могу сделать — под линукс есть миллион графических оболочек, которые вполне реально менять, не перезагружая ОС.
>Микроядерная архитектура это хорошо, но она не позволяет делать то, о чем я говорил — подмену «служебных комнат» в реальном времени. Это должно быть так же просто как переустановить программу.
Ну приехали. А в чем тогда заключается микроядерность, если не в этом? В QNX, например, можно хоть сетевой стек на лету загрузить/выгрузить, хоть даже драйвер файловой системы. В реальном времени и совершенно незаметно для остальных компонентов.
Ну приехали. А в чем тогда заключается микроядерность, если не в этом? В QNX, например, можно хоть сетевой стек на лету загрузить/выгрузить, хоть даже драйвер файловой системы. В реальном времени и совершенно незаметно для остальных компонентов.
Какие способы задания алгоритмов вы видите? Искуственный интеллект с вербальным приемником не предлагать :)
Мм, алгоритмы удобно, конечно, описывать последовательностью команд. Только команды должны быть красивые и удобные) Без ограничений, которые налагает текст. Например, вместо множества аргументов у функций, давать возможность вводить всё в окошко с параметрами, без привязки к порядку аргументов. А так же, например, позволять в этом же окошке описывать действия при ошибках выполнения функции. Можно добавлять скрытое комментирование — при нажатии на F1, к примеру, показывать рядом с сущностями иконку комментария, если таковые имеются. Математические функции должны описыватся в математической форме, примерно как в MatLab'е. Возможностей куча.
Но большее преимущество от такой среды разработки программист получил бы не в описании алгоритмов, а в установке связей. В моей практике описание каких-либо алгоритмов занимает меньше половины времени — всё остальное время уходит на создание объектов, методов, задание свойств и т.д. и прочую рутинную работу. Именно такую работу стало бы выполнять веселее :)
Но большее преимущество от такой среды разработки программист получил бы не в описании алгоритмов, а в установке связей. В моей практике описание каких-либо алгоритмов занимает меньше половины времени — всё остальное время уходит на создание объектов, методов, задание свойств и т.д. и прочую рутинную работу. Именно такую работу стало бы выполнять веселее :)
Вы, похоже, никогда не работали со всякими FBD-средами. Только там рутины ещё больше, т. к. уровень абстракции ниже.
Боже упаси. Видел я такие :)
Я говорю о другом. Я говорю об увеличеннии производительности текущего способа написания программ. Я хочу то же самое окошко с курсором, но чтобы введенные символы преобразовывались в нужные конструкции. Я хочу чтобы классы можно было компоновать перетаскиванием методов. Чтобы можно было получить разнообразные графические схемы программы.
От написания функций способом похожим на текстовый не уйдешь, однако его можно значительно проапргрейдить отойдя от чисто-текстового подхода. Всё остальное, что не относится к содержимому функций, должно компоноваться а не описываться текстом.
Я говорю о другом. Я говорю об увеличеннии производительности текущего способа написания программ. Я хочу то же самое окошко с курсором, но чтобы введенные символы преобразовывались в нужные конструкции. Я хочу чтобы классы можно было компоновать перетаскиванием методов. Чтобы можно было получить разнообразные графические схемы программы.
От написания функций способом похожим на текстовый не уйдешь, однако его можно значительно проапргрейдить отойдя от чисто-текстового подхода. Всё остальное, что не относится к содержимому функций, должно компоноваться а не описываться текстом.
Подождите, но есть же всякие там Enterprise Architect, Klockwork Architect, Rational Rose и т.д. Компонуйте и таскайте, сколько душе угодно. Или Вы имеете что-то другое в виду?
Есть просто ещё одна большая проблема. 99,9 и ещё много знаков после запятой современного программирования — это не искусство и наитие. Это промышленное производство. И требования к этому процессу примерно такие же, и к инструментам его — тоже.
Есть просто ещё одна большая проблема. 99,9 и ещё много знаков после запятой современного программирования — это не искусство и наитие. Это промышленное производство. И требования к этому процессу примерно такие же, и к инструментам его — тоже.
Я имею ввиду что-то среднее между теми инструментами, которые вы привели в пример, и текстовым программированием. Описывать последовательность действий некоторой функции удобнее в текстовом режиме, или в режиме приближенном к тому. А набор классов и их связи гораздо удобнее компоновать интерфейсными способами, вроде UML.
Мне это видится примерно так:
Когда вы создаёте программу, вы создаёте класс, унаследованный от Application. Вы щелкаете на этот класс и появляется окошко с его полным содержимым. В одном поле окна содержатся свойства, в другом интерфейсные методы, в третьем события, реакции, в четвертом «способности» объектов класса (что-то вроде интерфейсов в ООП), слоты для механизмов и сами механизмы.
Посмотрев на это окошко вы решаете добавить, например, интерфейсный метод. Жмете кнопочку «добавить», и в соответствующем окошке описываете параметры метода, возвращемые значения, ошибки. После этого метод будет виден в соответствующем поле окна класса. Это значит что вся программа хранится не в текстовом виде, а в структурном.
В такой программе было бы гораздо проще разбираться и было бы проще её поддерживать. Написание программы ускорилось бы потому, что когда среда разработки знает так много о структуре вашей программы, она может оказывать гораздо более полезную помощь.
В общем и целом UML здесь не особо задействован, но из-за того, что структура программы описана логически, автоматическое построение нужных UML-схем стало бы гораздо более простой задачей.
Мне это видится примерно так:
Когда вы создаёте программу, вы создаёте класс, унаследованный от Application. Вы щелкаете на этот класс и появляется окошко с его полным содержимым. В одном поле окна содержатся свойства, в другом интерфейсные методы, в третьем события, реакции, в четвертом «способности» объектов класса (что-то вроде интерфейсов в ООП), слоты для механизмов и сами механизмы.
Посмотрев на это окошко вы решаете добавить, например, интерфейсный метод. Жмете кнопочку «добавить», и в соответствующем окошке описываете параметры метода, возвращемые значения, ошибки. После этого метод будет виден в соответствующем поле окна класса. Это значит что вся программа хранится не в текстовом виде, а в структурном.
В такой программе было бы гораздо проще разбираться и было бы проще её поддерживать. Написание программы ускорилось бы потому, что когда среда разработки знает так много о структуре вашей программы, она может оказывать гораздо более полезную помощь.
В общем и целом UML здесь не особо задействован, но из-за того, что структура программы описана логически, автоматическое построение нужных UML-схем стало бы гораздо более простой задачей.
Или я опять же ничего не понял, или Вы только что описали типичный сценарий работы с любым достаточно развитым архитектурным анализатором. Отличий от реальной жизни два:
— достаточно развитый архитектурный анализатор не встроен в IDE, хотя и может с ней общаться
— иногда быстрее написать «интерфейсный метод» руками в коде и потом обновить диаграмму классов, нежели рисовать мышкой и заполнять поля.
Все эти штуки отлично работают уже долгое время и их плюсы хорошо известны. Известны и минусы: например, если структура классов не определяется без выполнения. Вот, например, язык питон:
До выполнения этого кода мы не можем быть уверены, будет ли у класса А новый метод и если да, то какой. Для языков, которые такое позволяют, «архитектурно-классовый» подход слишком громоздкий.
— достаточно развитый архитектурный анализатор не встроен в IDE, хотя и может с ней общаться
— иногда быстрее написать «интерфейсный метод» руками в коде и потом обновить диаграмму классов, нежели рисовать мышкой и заполнять поля.
Все эти штуки отлично работают уже долгое время и их плюсы хорошо известны. Известны и минусы: например, если структура классов не определяется без выполнения. Вот, например, язык питон:
Первое, что в голову пришло
class A:
def __init__(self):
self.x=0
self.y=0
def print(self):
print(self.x,self.y)
def a_set_one(self):
self.x=1
self.y=1
def a_set_two(self):
self.x=2
self.y=2
text=input("Enter 1 or 2")
if int(text==1):
A.set=a_set_one
else:
A.set=a_set_two
a=A()
a.set()
print(a)До выполнения этого кода мы не можем быть уверены, будет ли у класса А новый метод и если да, то какой. Для языков, которые такое позволяют, «архитектурно-классовый» подход слишком громоздкий.
Это значит что вся программа хранится не в текстовом виде, а в структурном.
Попробуйте Smalltalk, в нем обычно именно такой подход и используется (плюс в образе хранится полное состояние программы).
Мне больше бы хотелось, чтобы навигация по файлам проекта не привязывалась жёстко к файловой системе.
Например, иногда удобно группировать классы по семантике (все, что касается одной фичи — в одном месте). Иногда удобно группировать классы по типу. В одной группе все сущности, в другой репозитории, в третьей модели представления.
А VS нас вынуждает пользоваться только файловой системой. Это ограничивает нас только одной группировкой.
Например, иногда удобно группировать классы по семантике (все, что касается одной фичи — в одном месте). Иногда удобно группировать классы по типу. В одной группе все сущности, в другой репозитории, в третьей модели представления.
А VS нас вынуждает пользоваться только файловой системой. Это ограничивает нас только одной группировкой.
Да :) Вот такого типа вещи и должна обеспечивать среда программирования.
XCode позволяет группировать файлы без привязки к файловой системе. Но, конечно, не так роскошно как Вы описали :)
Для этого вам нужно пояснить IDE семантику своего проекта. Пишите плагин. Для многих фреймворков такие плагины есть и структура проекта отображается в IDE вполне себе семантически.
Пример на Си не выглядит синтаксически чистым. Каноничней так:
(Вообще я бы выкинул из Си ключевое слово const, сделав все декларации таковыми по умолчанию, и оставил бы mutable.)
int f(int x) {
const int y = 2 * x;
const int z = y + 1;
return z / 3;
}
(Вообще я бы выкинул из Си ключевое слово const, сделав все декларации таковыми по умолчанию, и оставил бы mutable.)
Не знаю, сколь велико влияние ML на Хаскель, мне кажется их можно сравнивать как предка и потомка. Так вот, ML сейчас выглядит устаревшим языком. И мне совсем не хочется пересаживаться с Хаскеля обратно на SML. Даже когда активно программировал на нем, почти никогда не возникало нужды пользовался его императивными возможностями (ну, разве что приходилось пользоваться стандартной библиотекой для работы с файлами и хэш-таблицами).
Чем хороша чисто функциональная модель программирования? Тем, что императивную гадость нельзя замести под ковер, она обязательно будет торчать снаружи, например, в виде монад. Большинство задач представляются в таком виде: (1) много-много структурного описания, (2) немного побочного эффекта там-сям. Чистые языки идеальны для (1), а с (2) кое-как справляются. Если же получилось так, что всё тело программы утыкано монадами, и не видно, как он них избавиться, значит, действительно, был выбран неправильный инструмент для решения задачи.
Чем хороша чисто функциональная модель программирования? Тем, что императивную гадость нельзя замести под ковер, она обязательно будет торчать снаружи, например, в виде монад. Большинство задач представляются в таком виде: (1) много-много структурного описания, (2) немного побочного эффекта там-сям. Чистые языки идеальны для (1), а с (2) кое-как справляются. Если же получилось так, что всё тело программы утыкано монадами, и не видно, как он них избавиться, значит, действительно, был выбран неправильный инструмент для решения задачи.
почти никогда не возникало нужды пользовался его императивными возможностями
Вводом-выводом без монад тоже никогда не занимались? А асинхронным программированием? А реализацией сугубо императивных алгоритмов с прицелом на производительность? Есть ещё OCaml, кстати (с которого F# был слизан), тоже предок ML, поприятнее самого ML.
что всё тело программы утыкано монадами, и не видно, как он них избавиться, значит, действительно, был выбран неправильный инструмент для решения задачи.
По-моему, не все монады императивны, да и императивные возможности монадами не ограничиваются. Но с концепцией согласен — лопаты для ям, вилки для спагетти. Не наоборот!
Ввод-вывод в Хаскеле может осуществляться не только монадами, но и функторами, апликативными фукнторами, стрелками Клейсли. Было бы желание. Ну и сложность задачи тоже влияет.
Да и монады не так страшны. Основную роль там играет функция
что означает, что она берёт 2 аргумента — функцию
Да и монады не так страшны. Основную роль там играет функция
bind:bind :: (a -> m b) -> m a -> m b
что означает, что она берёт 2 аргумента — функцию
a -> m b, монадное значение m a и возвращает результат m b Здесь и выше под словом «монады» (и, надо полагать, у автора статьи) подразумевается не конкретно класс Monad, а любые комбинаторы, используемые для протаскивания состояния, ввода-вывода и т.п.
Не вижу ничего страшного и сложного в монадах, всего лишь попытался встать на позицию автора, которому почему-то не нравится обертывание императивности чисто функциональными инструментами. Мне действительно не приходилось писать на Хаскеле больших программ, чуть менее чем полностью состоящих из ввода-вывода, поэтому я готов допустить, что это не очень приятное занятие.
Не вижу ничего страшного и сложного в монадах, всего лишь попытался встать на позицию автора, которому почему-то не нравится обертывание императивности чисто функциональными инструментами. Мне действительно не приходилось писать на Хаскеле больших программ, чуть менее чем полностью состоящих из ввода-вывода, поэтому я готов допустить, что это не очень приятное занятие.
Для ввода-вывода использовалась SML-ная библа (императивная); впрочем, разве это ввод-вывод: засосать пачку файлов в начале работы и сериализовать состояние в конце? Еще есть вопрос построения хранилища данных — можно использовать чистые функциональные деревья, а можно императивные хэш-таблицы, которые в некоторых случаях работают несколько эффективней. Почему OCalm предок ML? Вики говорит, что наоборот. Я знаком с ним поверхностно, и мне кажется, что он почти изоморфен ML'ю, разве что модульность реализована иначе.
Нельзя сказать, что монады императивны, поскольку формально в чистом языке все его сущности по определению чисты. Это философский вопрос, как смотреть на написанный монадический код: кто-то видит изменение состояния, а кто-то — всего лишь композицию функций.
Нельзя сказать, что монады императивны, поскольку формально в чистом языке все его сущности по определению чисты. Это философский вопрос, как смотреть на написанный монадический код: кто-то видит изменение состояния, а кто-то — всего лишь композицию функций.
>Чистые языки идеальны для (1), а с (2) кое-как справляются
Да нормально они справляются. IO-код в хаскеле выглядит кривовато только по сравнению с ФП-кодом на хаскеле. Ну или с непривычки. Если же его сравнивать с императивном коде на других языках, то можно заметить что на Хаскеле и императивно неплохо пишется. И даже взаимодействие с сишными API, и работа с памятью напрямую там отлично делается.
На данный момент главный минус Хаскеля — записей нет человеческих, через это прикладной код про Employee и Department выглядит как ад.
Да нормально они справляются. IO-код в хаскеле выглядит кривовато только по сравнению с ФП-кодом на хаскеле. Ну или с непривычки. Если же его сравнивать с императивном коде на других языках, то можно заметить что на Хаскеле и императивно неплохо пишется. И даже взаимодействие с сишными API, и работа с памятью напрямую там отлично делается.
На данный момент главный минус Хаскеля — записей нет человеческих, через это прикладной код про Employee и Department выглядит как ад.
Дело в том, что функции являются фундаментальным понятием, в то время как объекты лишь содержат их.
он путает методы с функциями. сам ведь дальше пишет, про сайд-эффекты и состояния.
Как насчёт Smalltalk? Там ВСЁ объекты, методы тоже объекты, напрямую не вызываются (посылка объектам сообщений с параметрами, но если очень хочется, то можно и вызвать напрямую, только сложно представить зачем). А передача функций в качестве параметра бессмысленна, потому что очень развит механизм замыканий. Т.е. весь сишный ад с колбэками, перечислителями и прочим изящно убран именно замыканиями.
Т.е. к примеру вот так выглядит код, вытаскивающий из массива все нечётные числа:
В этом коде массиву #(1 2 3 4 5 6 7) посылается сообщение #select: c параметром, заключенным в квадратные скобки. Этот параметр не что иное, как объект класса BlockClosure — замыкание. Он конструируется так, что знает, что ему на вход будет передаваться один параметр «each».
И вот, когда экземпляр массива начнёт исполнят метод #select:, он:
1) создаст выходной пустой массив;
2) начнёт перечислять все свои элементы, передавая каждый в качестве параметра замыканию;
3) если код в замыкании возвратит true, то элемент будет добавлен в выходной массив. А там что в замыкании? Там внутренней переменной each посылается сообщение #odd, на которое нечётное число обязано ответить true, а чётное false.
На выходе получим массив #(1 3 5 7).
Я привёл достаточно простой пример, на самом деле замыкания в Смоллтоке это очень круто, там даже процессы (потоки в мировоззрении С) создаются посылкой замыканию сообщения #fork.
В общем классика, причём изящная и добротная :)
Т.е. к примеру вот так выглядит код, вытаскивающий из массива все нечётные числа:
#(1 2 3 4 5 6 7) select: [:each | each odd]
В этом коде массиву #(1 2 3 4 5 6 7) посылается сообщение #select: c параметром, заключенным в квадратные скобки. Этот параметр не что иное, как объект класса BlockClosure — замыкание. Он конструируется так, что знает, что ему на вход будет передаваться один параметр «each».
И вот, когда экземпляр массива начнёт исполнят метод #select:, он:
1) создаст выходной пустой массив;
2) начнёт перечислять все свои элементы, передавая каждый в качестве параметра замыканию;
3) если код в замыкании возвратит true, то элемент будет добавлен в выходной массив. А там что в замыкании? Там внутренней переменной each посылается сообщение #odd, на которое нечётное число обязано ответить true, а чётное false.
На выходе получим массив #(1 3 5 7).
Я привёл достаточно простой пример, на самом деле замыкания в Смоллтоке это очень круто, там даже процессы (потоки в мировоззрении С) создаются посылкой замыканию сообщения #fork.
[object1 doSomeLongHardJob] fork.
[object2 doOtherLongHardJob] fork.
В общем классика, причём изящная и добротная :)
По существу, статические анализаторы кода основаны целиком на монадах, и тем самым они отбирают у программистов бремя по написанию монадического кода, вместо того, чтобы перекладывать его на них
А можно с этого места поподробнее?
мой ответ Чемберлену Что так с ООП и ФП, и что не так с программированием ))
Дело в том, что функции являются фундаментальным понятием, в то время как объекты лишь содержат их.
На первый взгляд да. Но если копнуть чуть глубже:
1. Даже минимальная (но не пустая) функция будет оперировать чем? Правильно, переменными.
2. Объявленная, но не используемая переменная бесполезна.
3. Следовательно, минимальным элементом, «атомом» кода является данные+действие над ними.
Из чего следует, что ни данные, ни функции — не являются первичными. Это обычная дуальная пара, два полюса, не существующие по отдельности.
Ну а объект — это как раз данные + методы. В свете вышесказанного его некорректно сравнивать с функциями. В C# так и есть — «все есть объект», вы можете написать даже так: 42.ToString()
Проблема автора оригинального текста, что он буквально понимает «все». Да, оператор сложения — не объект, запятая — не объект, ну это как бы нормально) Функция (метод) в объекте — тоже не объект, но она, как я показал выше, неотделима от данных объекта.

Python и Scala просто похитили все функции, заключили их в тюрьму “объектов”
Я бы не назвал это «тюрьмой», для объектов это скорее окно
Но вы правы злоупотреблять и неоправданно применять более сложные подходы для решения простых задач, так же как и сознательно ограничивать себя простыми инструментами для решения комлексных задач, есть зло
> Наиболее ошибочным для ООП является само понятие “объекта”
> и попытка определить что-угодно через него. В конце концов, вы
> доходите до концепции “все что угодно — это объект”.
ООП это полиморфизм, инкапсуляция и наследование. «Всё — объект» это полиморфизм и это хорошо. Плохо начинаются, когда программист создаёт излишние (в рамках решения задачи) уровни абстракции.
С ООП и ФП всё хорошо (в рамках задач, в которых они появились), но Золотой Грааль программирования это гармония, баланс между ООП, ФП и прочими парадигмами написания программ, когда, обратите внимание, программист не бросается в крайности, а использует всё лучшее из миров. По моему мнению, наиболее близки (не идеальны, а лишь близки) к этому на сегодня являются Ruby и Scala.
> и попытка определить что-угодно через него. В конце концов, вы
> доходите до концепции “все что угодно — это объект”.
ООП это полиморфизм, инкапсуляция и наследование. «Всё — объект» это полиморфизм и это хорошо. Плохо начинаются, когда программист создаёт излишние (в рамках решения задачи) уровни абстракции.
С ООП и ФП всё хорошо (в рамках задач, в которых они появились), но Золотой Грааль программирования это гармония, баланс между ООП, ФП и прочими парадигмами написания программ, когда, обратите внимание, программист не бросается в крайности, а использует всё лучшее из миров. По моему мнению, наиболее близки (не идеальны, а лишь близки) к этому на сегодня являются Ruby и Scala.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Что не так с ООП и ФП