Статья является пошаговым руководством по построению масштабируемого отказоустойчивого файлового хранилища, доступ к которому будет осуществлен по протоколам Samba, NFS. В качестве файловой системы, которая будет непосредственно отвечать за сохранение и масштабирование файловой шары будем использовать GlusterFS, о котором было уже достаточно написано хабрасообществом. Так как GlusterFS — часть Red Hat Storage, туториал написан для RH — like систем.

Использую версию 3.3.1, rpm-ки скачаны с официального сайта. После создания volume, клиент может получить к нему доступ несколькими способами:
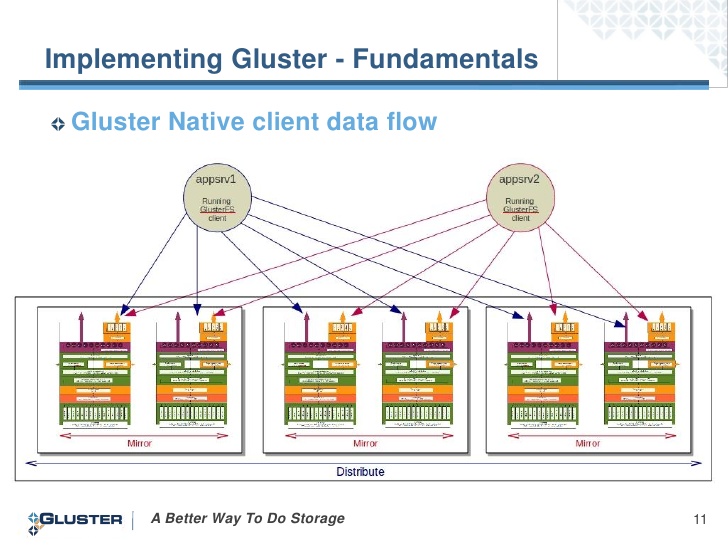
Мы будем использовать первый вариант, так как в этом случае клиент устанавливает связь со всеми серверами и при отказе сервера к которому мы монтировались, мы получаем данные с рабочих серверов:
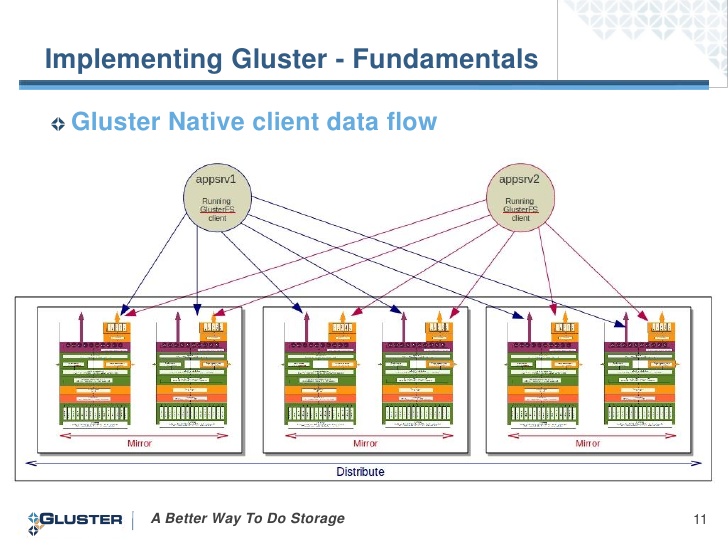
Отлично механика работы описана в этом посте. Хотелось бы добавить, что распределение нагрузки на кластер с использованием LVS в документации прописана только для сети NAT, по этому будем использовать Round Robbin DNS. Есть в стандартных репозиториях, так же как и SMB, NFS:
Допустим, у нас есть 2 ноды:
Еще необходима парочка IP, которые будут воплощать отказоустойчивость — мигрировать между серверами.
RR DNS для домена data выглядит так:
В создание volume для GlusterFS я углубляться не буду. Скажу, что нам необходимо распределенно — репликационный раздел (distributed+replicated volume). Назовём его smb. Для начала монтируем его локально для каждой ноды:
Каждый сервер в качестве опции использует свой hostname . Не забываем занести запись в /etc/fstab.
Теперь правим конфигурацию Samba (на каждом сервере).
…
# Основной параметр, отвечает за кластеризацию.
# Связь с БД, которая хранит обращения пользователей (см. ссылку про механику работы )
# Папка, с конфигурационными файлами
И туда же добавим секцию самой шары:
Папка получится для общего пользования, доступ от пользователя smbcli без авторизации. Пожже создадим его и назначим права.
Тепер на одном из серверов создаем папку, в которой будем размещать некоторые конфигурационные файлы CTDB
И добавим файл:
Конфигурационный файл CTDB на каждом сервере приводим к виду:
# Файл, который исполняется каждый раз, когда нода кластера CTDB изменяет свой статус (например письмецо отправлять)
Указываем наши public adresses (на каждом сервере):
Указываем ноды кластера CTDB (на каждом сервере):
SElinux я отключаю, IPtables выглядят следующим образом (естественно, для каждого сервера):
# Вместо названия цепочек, можно укзать просто ACCEPT.
Вернемся к Samba и пользователю smbcli (на каждом сервере):
Предпоследние штрихи:
Теперь можно наблюдать
Список публичных мигрирующих IP и их приналежность к серверам получаем командой
Монтируем клиенту по протоколу SMB или NFS командами:
Из личного опыта скажу, что падения сети тестирую до сих пор, результат очень даже сносный. Обрыв соединения практически не заметен. Все обьясняет AndreyKirov
Приятного коддинга!

Каким же образом эти сервисы взаемодействуют?
GlusterFS
Использую версию 3.3.1, rpm-ки скачаны с официального сайта. После создания volume, клиент может получить к нему доступ несколькими способами:
# mount.glusterfs# mount -o mountproto=tcp,async -t nfs# mount.cifs
Мы будем использовать первый вариант, так как в этом случае клиент устанавливает связь со всеми серверами и при отказе сервера к которому мы монтировались, мы получаем данные с рабочих серверов:
CTDB
Отлично механика работы описана в этом посте. Хотелось бы добавить, что распределение нагрузки на кластер с использованием LVS в документации прописана только для сети NAT, по этому будем использовать Round Robbin DNS. Есть в стандартных репозиториях, так же как и SMB, NFS:
# yum install ctdb samba nfs-utils cifs-utils Приступим
Допустим, у нас есть 2 ноды:
gluster1, 192.168.122.100gluster2, 192.168.122.101 Еще необходима парочка IP, которые будут воплощать отказоустойчивость — мигрировать между серверами.
192.168.122.200192.168.122.201RR DNS для домена data выглядит так:
; zone file fragmentdata. 86400 IN A 192.168.122.200data. 86400 IN A 192.168.122.201В создание volume для GlusterFS я углубляться не буду. Скажу, что нам необходимо распределенно — репликационный раздел (distributed+replicated volume). Назовём его smb. Для начала монтируем его локально для каждой ноды:
# mount.glusterfs gluster1:smb /mnt/glustersmb Каждый сервер в качестве опции использует свой hostname . Не забываем занести запись в /etc/fstab.
Теперь правим конфигурацию Samba (на каждом сервере).
# vim /etc/samba/smb.conf…
[global]# Основной параметр, отвечает за кластеризацию.
clustering = yes # Связь с БД, которая хранит обращения пользователей (см. ссылку про механику работы )
idmap backend = tdb2 # Папка, с конфигурационными файлами
private dir = /mnt/glustersmb/lock И туда же добавим секцию самой шары:
[pub]path = /mnt/glustersmb/lockbrowseable = YESforce user = smbcliforce group = smbcliwritable = yesguest ok = yes guest account = smbcliguest only = yesПапка получится для общего пользования, доступ от пользователя smbcli без авторизации. Пожже создадим его и назначим права.
Тепер на одном из серверов создаем папку, в которой будем размещать некоторые конфигурационные файлы CTDB
# mkdir /mnt/glustersmb/lockИ добавим файл:
# touch /mnt/glustersmb/lock/lockfileКонфигурационный файл CTDB на каждом сервере приводим к виду:
# vim /etc/sysconfig/ctdbCTDB_RECOVERY_LOCK=/mnt/glustersmb/lock/lockfileCTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addressesCTDB_MANAGES_SAMBA=yesCTDB_NODES=/etc/ctdb/nodesCTDB_MANAGES_NFS=yes# Файл, который исполняется каждый раз, когда нода кластера CTDB изменяет свой статус (например письмецо отправлять)
CTDB_NOTIFY_SCRIPT=/etc/ctdb/notify.shУказываем наши public adresses (на каждом сервере):
# vim /etc/ctdb/public_addesses192.168.122.200/24 eth0 192.168.122.201/24 eth0 Указываем ноды кластера CTDB (на каждом сервере):
# vim /etc/ctdb/nodes192.168.122.100192.168.122.101SElinux я отключаю, IPtables выглядят следующим образом (естественно, для каждого сервера):
# vim /etc/sysconfig/iptables-A INPUT -p tcp --dport 4379 -j ctdb-A INPUT -p udp --dport 4379 -j ctdb-A INPUT -p tcp -m multiport --ports 137:139,445 -m comment --comment "SAMBA" -j SMB-A INPUT -p udp -m multiport --ports 137:139,445 -m comment --comment "SAMBA" -j SMB-A INPUT -p tcp -m multiport --ports 111,2049,595:599 -j NFS-A INPUT -p udp -m multiport --ports 111,2049,595:599 -j NFS-A INPUT -p tcp -m tcp --dport 24007:24220 -m comment --comment "Gluster daemon" -j ACCEPT-A INPUT -p tcp -m tcp --dport 38465:38667 -m comment --comment "Gluster daemon(nfs ports)" -j ACCEPT# Вместо названия цепочек, можно укзать просто ACCEPT.
Вернемся к Samba и пользователю smbcli (на каждом сервере):
# useradd smbcli# chown -R smbcli.smbcli /mnt/glustersmb/pubПредпоследние штрихи:
# chkconfig smbd off# chkconfig ctdb on# service ctdb startТеперь можно наблюдать
# ctdb statusNumber of nodes:2pnn:0 192.168.122.100 OK (THIS NODE)pnn:1 192.168.122.101 OKGeneration:1112747960Size:2hash:0 lmaster:0hash:1 lmaster:1Recovery mode:NORMAL (0)Recovery master:0Список публичных мигрирующих IP и их приналежность к серверам получаем командой
# ctdb ipPublic IPs on node 0192.168.122.200 node[1] active[] available[eth0] configured[eth0]192.168.122.201 node[0] active[eth0] available[eth0] configured[eth0]Монтируем клиенту по протоколу SMB или NFS командами:
# mount.cifs data:smb /mnt # mount -o mountproto=tcp,async -t nfs data:smb /mnt Из личного опыта скажу, что падения сети тестирую до сих пор, результат очень даже сносный. Обрыв соединения практически не заметен. Все обьясняет AndreyKirov
Ликбез
Узел, который принял на себя IP адрес другого, знает о старых TCP соединениях только то, что они были, и не знает «TCP squence number» соединений. Соответственно, не может их продолжить. Также как и клиент, ничего не знает о том, что соединения теперь осуществляются с другим узлом.
Для того чтобы избежать задержек связанных с переключением соединения используется следующий прием. Для понимания этого приема нужно понимать основные принципы функционирования протокола TCP.
Новый узел, получив себе ip адрес, посылает клиенту пакет с флагом ACK и заведомо неправильным «squence number» равным нулю. В ответ клиент, в соответствии с правилами работы протокола TCP, отправляет назад пакет ACK Reply с корректным «squence number». Получив корректный «squence number» узел формирует пакет с флагом RST и этим «squence number». Получив его, клиент незамедлительно перезапускает соединение.
Приятного коддинга!








