Комментарии 22
Хорошо, а как тогда решить эту задачу? Какие инструменты правильные? Что делать? Как жить?
Жить надо в удовольствие, делать лучше всего то, что нравится, правильные инструменты — это те, которые подходят, а задачу с сентиментным анализом лучше всего решать через потоковую обработку. Насколько я знаю, мой бывший коллега в итоге так и оставил скрипты для анализа независимыми друг от друга, а спереди просто поставил скрипт для диспетчеризации твитов и контроля за ошибками. Вроде, полёт нормальный. По крайней мере, это должно работать, пока очередной высокий менеджер не услышит яркую презентацию про Hadoop и не захочет его снова внедрить :)
Storm спроектирован для такого типа задач.
Можно попробовать с Эрлангом заморочиться
Можно попробовать с Эрлангом заморочиться
Stream Computing, в более общем плане если говорить. IBM Infosphere Streams, или Storm и Kafka как писали выше.
К сожалению, в последние годы стремительного прогресса в сфере технологий обработки и хранения данных грань между правильными и неправильными инструментами постепенно исчезает. Документацию никто не читает, специалистов на все стартапы не хватает, маркетинг тоже играет не маловажную роль (привет OpenStack), а потом это уже превращается в «легаси». Другие видят как это вроде бы успешно работает и тоже подхватывают на лету (привет NoSQL).
И возразить при этом нечего, зачастую аргументов против «как в фейсбуке» не хватает.
И возразить при этом нечего, зачастую аргументов против «как в фейсбуке» не хватает.
Согласен. При правильном подходе очень ценная работа должна быть аналитика и архитектора проекта, которые смогут грамотно определить в каком месте какие технологии нужно использовать и каких специалистов нужно привлекать.
P.S.: Я в данном случаи пошёл другим путём, сменил технологии на те, которые мне больше нравятся и стал заниматься только теми проектами, куда логично применять эти технологии. Вроде и саморазвитие, и при этом стал больше заниматься консультациями, т.к. могу на опыте оценить необходимость применения.
P.S.: Я в данном случаи пошёл другим путём, сменил технологии на те, которые мне больше нравятся и стал заниматься только теми проектами, куда логично применять эти технологии. Вроде и саморазвитие, и при этом стал больше заниматься консультациями, т.к. могу на опыте оценить необходимость применения.
В случае с Hadoop-ом, документацию не только не читают, но и не пишут. К сожалению, технология очень и очень непростая, и некоторые аспекты остаются непонятными даже после прочтения длинных руководств. Ситуация осложняется ещё и тем, что многие участки кода (вплоть до MapReduce API) часто переписываются, что делает долговременную качественную документацию бесполезной.
Тем не менее, есть надежда, что в какой-то момент всё это устаканится, и разработчики начнут думать не просто, как это сделать (например, как обеспечить безопасность доступа к данным), а как сделать это красиво. Тогда, как мне кажется, и вопросов о правильности инструмента для конкретной задачи станет на порядок меньше.
Тем не менее, есть надежда, что в какой-то момент всё это устаканится, и разработчики начнут думать не просто, как это сделать (например, как обеспечить безопасность доступа к данным), а как сделать это красиво. Тогда, как мне кажется, и вопросов о правильности инструмента для конкретной задачи станет на порядок меньше.
2 года работаю c Hadoop, не могу согласиться, что документация по Hadoop плохая. Отличное описание языков программирования Hive, Pig. Много достойных книг по этой технологии. Да, есть небольшие пробелы, но они отлично находятся на stackoverflow. Если бы меня попросили сравнить документацию на MS SQL и Hadoop, я бы выбрал Hadoop.
Ну, смотрите. Возьмём самый базовый пример, с которого многие начинают знакомство с Hadoop — задание MapReduce. Вбиваем в Гугль «hadoop mapreduce» и попадаем на страницу официального руководства с… примером устаревшего API. При этом даже мне, знающему, что искать, пришлось долго порыться, чтобы найти пример использования нового интерфейса. А если на официальную документацию нельзя рассчитывать, то на какую можно? Apache, Cloudera, Hortonworks — никто из них не уделаяет внимания поддержанию качества, актуальности и согласованности своих документов. Например, Cloudera активно рекоммендует использовать свой менеджер, но при этом половина примеров написана для базовой версии Hadoop и с менеджером не работает. В книгах такие детали тоже не описывают, так что многие вещи приходится просто делать наугад и затем проверять.
Недавно у нас был интересный случай. Мы долгое время искали способ соединить Oracle и Hive/Impala через ODBC. Всё, что выдавал Google либо просто не работало, либо стоило много денег и всё равно не работало (по крайней мере так, как было нужно нам). И совершенно случайно в одной из рассылок user group заметили упоминание про Cloudera ODBC Driver. Попробовали — отработал на отлично. Но ни до, ни после этого случая найти упоминание про этот драйвер через поисковик так и не удалось. Т.е. если бы не рассылка и стечение обстоятельств, драйвер мы бы так и не нашли.
Недавно у нас был интересный случай. Мы долгое время искали способ соединить Oracle и Hive/Impala через ODBC. Всё, что выдавал Google либо просто не работало, либо стоило много денег и всё равно не работало (по крайней мере так, как было нужно нам). И совершенно случайно в одной из рассылок user group заметили упоминание про Cloudera ODBC Driver. Попробовали — отработал на отлично. Но ни до, ни после этого случая найти упоминание про этот драйвер через поисковик так и не удалось. Т.е. если бы не рассылка и стечение обстоятельств, драйвер мы бы так и не нашли.
Я больше занимаюсь Pig and Hive — возможно там лучше ситуация. ODBC драйвер тоже искал для MS SQL. Как вам производительность ODBC для Oracle? Быстро работает?
Пока тестируем, но вроде неплохо. Правда, мы больше рассчитываем на Impala, чем на Hive — пока она себя показала быстрее и… адекватнее, что ли. Impala — это, в смысле, Cloudera Impala. Ещё Hortonworks ведёт в этом направлении работы, обещая стократное ускорение SQL запросов по сравнению с Hive, но им ещё далеко до завершения.
На Hadoop, либо никак (для большинства алгоритмов), ещё работает замечательная библиотека машинного обучения Mahout. Как она это делает с помощью MR — загадка.
Скорее всего такие алгоритмы работают через цепочку (а вернее даже направленный граф) MR заданий — это значительно расширяет возможности парадигмы. По идее, хороший толчок развитию Mahout должен дать переход на MR2 и YARN вообще. Конечно, если это когда-нибудь всё-таки случится :)
Цепочка MR jobs с передачей промежуточных данных через HDFS между jobs. Это очень похоже на использование временных таблиц в SQL, когда вы сохраняете результаты работы одного скрипта, чтобы потом отправить эти данные следующему блоку кода SQL.
Спасибо за разъяснения. Есть какая-то книга (или хотя бы статья), где собраны типы задач, встречающиеся в высоконагруженных системах и способы решения этих типовых задач?
Вот немножко в другую степь (хотя рядом) — Интел рассказывает как в пределах одной машины правильно параллелить разные типы задач. Это не то же самое, что задачи в распределённой системе, но кое-какие паттерны и выводы почерпнуть можно.
Возможно вам поможет цикл книг POSA: Pattern-Oriented Software Architecture. Там их аж 5 томов — думаю, что найдете то, что вам нужно.
Мне кажется, здесь надо плясать не от нагруженности систем, а от области применения. В этой статье я писал про обработку больших данных, а ведь распределённые системы могут проектироваться и с другими целями: где-то упор делается на надёжное хранение, и тогда первостепенными становятся вопросы репликации и высокой доступности; где-то на надёжности выполнения распределённых задач, и тогда на первый план выходят надёжность доставки сообщений и соблюдение happens-before отношений; где-то важней всего производительность, и тогда всё упирается в низкоуровневые библиотеки и протоколы передачи данных. Соответсвенно, и способы решения таких типичных задач нужно искать в литературе из этой области.
Лично я предпочитаю подсматривать идеи в готовых системах. Например, в своё время понравилась архитектура Твиттера — очень прагматичная, и главное, можно быть уверенным, что это работает. Если вас интересует именно литература и именно «в целом», без конкретной области, то я бы посоветовал почитать что-нибудь про внутренности того же Hadoop — в нём решено множество типичных задач, причём зачастую несколькими способами (см., например, планировщики задач).
Лично я предпочитаю подсматривать идеи в готовых системах. Например, в своё время понравилась архитектура Твиттера — очень прагматичная, и главное, можно быть уверенным, что это работает. Если вас интересует именно литература и именно «в целом», без конкретной области, то я бы посоветовал почитать что-нибудь про внутренности того же Hadoop — в нём решено множество типичных задач, причём зачастую несколькими способами (см., например, планировщики задач).
В посте есть ряд спорных утверждений и очевидных неточностей.
Откуда столько денег? Вместо одно распределенной Oracle/Teradata DB можно купить Хадуп кластер на пол сотни машин. Ничто не мешает на этих же машинах гонять Storm, как вы упомянули в посте.
static.oschina.net/uploads/img/201303/14004621_AjkO.png
mapred.task.timeout
В общем случае, если приходится прибегать к этой property, значит что-то не так в реализации алгоритма.
проблема легко решается за счёт партиционирования на уровне приложения.Наихудшее из возможных на текущий момент решений.
Мы можем загрузить все данные в распределённую базу Oracle и работать с ними так же, как с активными. Откуда столько денег? Вместо одно распределенной Oracle/Teradata DB можно купить Хадуп кластер на пол сотни машин. Ничто не мешает на этих же машинах гонять Storm, как вы упомянули в посте.
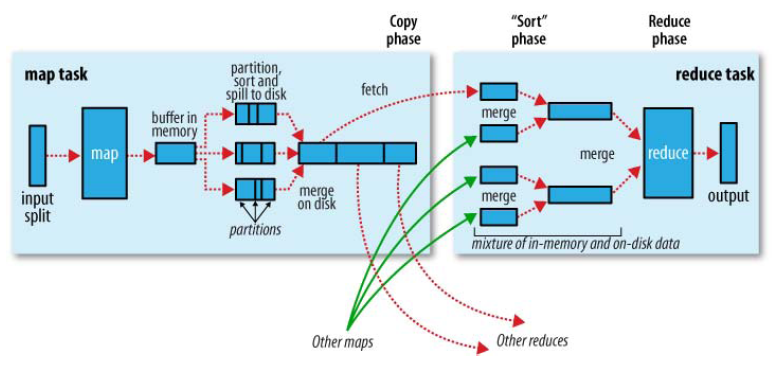
затем над каждым из них выполняется функция map, затем результаты сортируются, затем комбинируются, затем снова сортируются и наконец передаются функции reduce.Вы забыли смерджить и отсортировать данные на reducer'e. Да и не только.
static.oschina.net/uploads/img/201303/14004621_AjkO.png
{kind=link}
Hadoop через какое-то время убьёт всё задание как сбойное.Какой жестокий Хадуп :)
mapred.task.timeout
В общем случае, если приходится прибегать к этой property, значит что-то не так в реализации алгоритма.
Наихудшее из возможных на текущий момент решений.
Почему и какое решение лучше?
Откуда столько денег? Вместо одно распределенной Oracle/Teradata DB можно купить Хадуп кластер на пол сотни машин. Ничто не мешает на этих же машинах гонять Storm, как вы упомянули в посте.
Смысл всего раздела был в том, что для анализа больших объёмов, например, бизнес логов стандартные базы данных будут неэффективны, даже если это Oracle за много денег.
Вы забыли смерджить и отсортировать данные на reducer'e. Да и не только.
У меня не было цели давать глубокое техническое описание ни Hadoop, ни конкретно MapReduce. Цель статьи — дать представление о том, для чего Hadoop вообще нужен, когда он хорошо подходит, а когда лучше использовать что-нибудь другое.
Какой жестокий Хадуп :)
mapred.task.timeout
А также можно сказать Хадупу переиспользовать JVM, передавать выходные данные не через файлы, а через пайпы, и вообще настроить систему под любые нужды, но при этом вся инфраструктура Хадупа будет постоянно вставлять палки в колёса. Спрашивается, зачем тогда использовать слонёнка, если сознательно бороться с предлагаемой им парадигмой?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Вы понимаете Hadoop неправильно