Комментарии 25
… но у меня так и не получилось заставить этот способ работать.
Вот на этих словах заканчивается 95% всех HA-проектов.
Если вы не смогли автоматизировать процесс восстановления — это уже все что угодно, но не HA.
Это не для восстановления, это для автоматического подключения новый ноды к кластеру.
А официальная документация, вполне черным и достаточно по белому, об этом говорит:
PS: К автору статьи тоже относится, не вводите в заблуждение пожалуйста. Ноды самостоятельно прекрасно восстанавливаются, будучи подключены единожды к кластеру, при прочих равных.
А официальная документация, вполне черным и достаточно по белому, об этом говорит:
Set this to cause clustering to happen automatically when a node starts for the very first time. The first element of the tuple is the nodes that the node will try to cluster to. The second element is either disc or ram and determines the node type.PS: К автору статьи тоже относится, не вводите в заблуждение пожалуйста. Ноды самостоятельно прекрасно восстанавливаются, будучи подключены единожды к кластеру, при прочих равных.
Действительно, перепроверил, ноды отлично восстанавливаются после перезапуска сервера. Спасибо, дополню.
ок, теперь положите сеть между двумя нодами трехнодового кластере на минуту, затем верните обратно.
все еще отлично восстанавливаются?
все еще отлично восстанавливаются?
Поднял трехнодовый кластер, уронил сеть на 2 минуты

, включил сеть

перезапустил ноду

Запустил тестовое приложение, коннект нормальный, данные пишет, синхронизация отрабатывает.
Вывод: нельзя чтобы падала сеть.

, включил сеть

перезапустил ноду

Запустил тестовое приложение, коннект нормальный, данные пишет, синхронизация отрабатывает.
Вывод: нельзя чтобы падала сеть.
> Вывод: нельзя чтобы падала сеть.
Ха-ха.
Кстати, вот вам еще пара тестов:
— уроните одну ноду, потом вторую, потом поднимите первую, а затем вторую.
— уроните первую ноду, потом поднимите ее через какое-то время и тут же положите вторую, а затем поднимите ее.
Разумеется, тесты надо проводить, все это время помещая сообщения в очереди, желательно, с большой задержкой извлекая их после помещения.
Подсказки:
— в первом тесте на третьем шаге первая нода у вас тупо не поднимется без второй.
— во втором тесте вы потеряете на четвертом шаге, когда поднимете вторую ноду, те сообщения, которые легли в очереди после падения первой ноды, но не успели извлечься потребителями до момента падения второй.
И, вообще, чтобы в общем обрисовать ситуацию, отмечу несколько моментов:
— на свежеподнятой (например, после падения) ноде все очереди переключаются в ведомое состояние и сбрасывают свое содержимое (даже если на ведущих очередях на другой ноде каких-то сообщений нет)
— запись на диск содержимого персистентных очередей идет без каких-либо гарантий, т.е. никакого ACID
— по-умолчанию, разные ноды кластера не синхронизируют содержимое очередей, потому, при восстановлении упавшей ноды сообщения, прилетевшие на живую после падения первой, существуют только на одной ноде и на свежеподнятую не будут реплицированы. т.е. реплицируется между нодами только входящий поток сообщений, но не содержимое очередей. В последних версиях синхронизация появилась, но она не гарантирует вам, что автоматически она будет работать правильно.
Вот такие вот пироги.
Ха-ха.
Кстати, вот вам еще пара тестов:
— уроните одну ноду, потом вторую, потом поднимите первую, а затем вторую.
— уроните первую ноду, потом поднимите ее через какое-то время и тут же положите вторую, а затем поднимите ее.
Разумеется, тесты надо проводить, все это время помещая сообщения в очереди, желательно, с большой задержкой извлекая их после помещения.
Подсказки:
— в первом тесте на третьем шаге первая нода у вас тупо не поднимется без второй.
— во втором тесте вы потеряете на четвертом шаге, когда поднимете вторую ноду, те сообщения, которые легли в очереди после падения первой ноды, но не успели извлечься потребителями до момента падения второй.
И, вообще, чтобы в общем обрисовать ситуацию, отмечу несколько моментов:
— на свежеподнятой (например, после падения) ноде все очереди переключаются в ведомое состояние и сбрасывают свое содержимое (даже если на ведущих очередях на другой ноде каких-то сообщений нет)
— запись на диск содержимого персистентных очередей идет без каких-либо гарантий, т.е. никакого ACID
— по-умолчанию, разные ноды кластера не синхронизируют содержимое очередей, потому, при восстановлении упавшей ноды сообщения, прилетевшие на живую после падения первой, существуют только на одной ноде и на свежеподнятую не будут реплицированы. т.е. реплицируется между нодами только входящий поток сообщений, но не содержимое очередей. В последних версиях синхронизация появилась, но она не гарантирует вам, что автоматически она будет работать правильно.
Вот такие вот пироги.
Все верно но есть пара замечаний.
1. 2 ноды еще не кластер, введение 3й значительно повышает consistency (даже великому mssql нужен арбитр)
2. Кластеризация кролика (в текущем виде) не может быть гео-избыточной, вот хоть убейся, но это так.
3. Не очень понял про запись на диск, mnesia же и есть запись в RAM.
4. Зависит от типа падения. Если падение сервера — так не будет, если обрыв связи — да, split. Это решается настройкой авторитетной ноды.
1. 2 ноды еще не кластер, введение 3й значительно повышает consistency (даже великому mssql нужен арбитр)
2. Кластеризация кролика (в текущем виде) не может быть гео-избыточной, вот хоть убейся, но это так.
3. Не очень понял про запись на диск, mnesia же и есть запись в RAM.
4. Зависит от типа падения. Если падение сервера — так не будет, если обрыв связи — да, split. Это решается настройкой авторитетной ноды.
Я конечно не настоящий Erlang-сварщик, но на счет mnesia помню, что ее отдельные ноды можно конфигурировать, чтобы они реплицировали данные на диск.
1. добавление 3ей ноды в кластер rabbitmq ничего общего с понятием кворума не имеет, поскольку нормального арбитража в rabbitmq нет, как и, к слову, нормальной синхронизации (синхронизация очередей сейчас выглядит как костыль, поскольку на время синхронизации работа с очередями недоступна). И, вообще, о какой consistency может идти речь, если нет даже write consisntecy между нодами кластера?
3. Запись на диск и гарантированная запись на диск — это две большие разницы. У вас может быть disk node с persistent queues, но при этом помещение сообщения в очередь не означает, что она легла на диск, а, например, не осела в кэше.
4. Я, возможно, недостаточно знаю про rabbitmq, но про «авторитетную ноду» в контексте mirrored queues слышу впервые. Состояние ведущего/ведомого имеют сами очереди, а не ноды.
Вообще, надо просто учитывать, что rabbitmq mirrored queues защищают от падения N-1 серверов в кластере и, вообще, имеют ряд специфичных особенностей в эксплуатации. Если серверы у вас поморгают в неудачной для вас последовательности, никто вам сохранность данных не гарантирует.
Потому рассматривать mirrored queues как универсальное средство обеспечения отказоустойчивости не следует.
3. Запись на диск и гарантированная запись на диск — это две большие разницы. У вас может быть disk node с persistent queues, но при этом помещение сообщения в очередь не означает, что она легла на диск, а, например, не осела в кэше.
4. Я, возможно, недостаточно знаю про rabbitmq, но про «авторитетную ноду» в контексте mirrored queues слышу впервые. Состояние ведущего/ведомого имеют сами очереди, а не ноды.
Вообще, надо просто учитывать, что rabbitmq mirrored queues защищают от падения N-1 серверов в кластере и, вообще, имеют ряд специфичных особенностей в эксплуатации. Если серверы у вас поморгают в неудачной для вас последовательности, никто вам сохранность данных не гарантирует.
Потому рассматривать mirrored queues как универсальное средство обеспечения отказоустойчивости не следует.
Да. Новые сообщения будут синхронизироваться, старые останутся на нодах и будут отличаться. Стандартная ситуация для master-master.
Решаем проблему настройкой весов и приоритетов. Для общего понимания гуглим split-brain и CAP-теорема.
Решаем проблему настройкой весов и приоритетов. Для общего понимания гуглим split-brain и CAP-теорема.
Вопрос на засыпку: какие из букв аббревиатуры CAP обеспечивает кластер rabbitmq?
Вероятно, AP. Да и то, соответствующим клиентом.
Нет. PT отсутствет напрочь, о чем говорится в документации, да и в комментариях выше уже упоминалось. Сеть должна работать стабильно, иначе кластеру хана.
Фактически, rabbitmq обеспечивает только availability: про pt я только что сказал, строгая же consistency отсутствеут (репликация только входящего потока данных, притом асинхронная, и гарантия записи на диск в лучших традициях монги).
При этом, если мы попытаемся сделать сетевую консистентность чуть менее слабой (строгую мы не получим все равно), включив автосинхронизацию очередей, то мы потеряем даже availability, потому что в течение синхронизации очереди недоступны ни на запись, ни на чтение.
Фактически, rabbitmq обеспечивает только availability: про pt я только что сказал, строгая же consistency отсутствеут (репликация только входящего потока данных, притом асинхронная, и гарантия записи на диск в лучших традициях монги).
При этом, если мы попытаемся сделать сетевую консистентность чуть менее слабой (строгую мы не получим все равно), включив автосинхронизацию очередей, то мы потеряем даже availability, потому что в течение синхронизации очереди недоступны ни на запись, ни на чтение.
Можете привести пример брокера сообщений (желательно такого у которого есть клиенты для .net), который покрывает указанные недостатки RabbitMQ. До этой статьи мне казалось что уж брокер построенный на языке созданным специально для отказоустойчивых приложений и с приличной историей обязан быть в рядах лучших.
Из прочих я рассматривал ZeroMQ, но судя по всему он будет обладать аналогичными недостатками.
Из прочих я рассматривал ZeroMQ, но судя по всему он будет обладать аналогичными недостатками.
Zmq ни пол раза не брокер, к сожалению. Оно скорее шустрая библиотека для ipc со всякими плюшками (подтверждение доставки, роутинг).
Из брокеров я сам работал только rabbitmq, потому с уверенностью ничего посоветовать не могу.
Я знаю, что есть еще другие реализации amqp-брокеров, но они медленнее, чем rabbitmq, при использовании persistent очередей. Возможно, как раз за счет строгого соблюдения консистентности, но это лишь моя догадка.
Я знаю, что есть еще другие реализации amqp-брокеров, но они медленнее, чем rabbitmq, при использовании persistent очередей. Возможно, как раз за счет строгого соблюдения консистентности, но это лишь моя догадка.
Т. е. при split brain кролика «разрывает на куски». Печально.
Я не использовал rabbitmq в их «HA» конфигурациях.
Я не использовал rabbitmq в их «HA» конфигурациях.
если узел доступен получаем ответ pang
либо исправить на pong, либо исправить на не доступен
Уж простите что здесь отвечаю… Тема уж больно до боли знакомая.
Что было у нас:
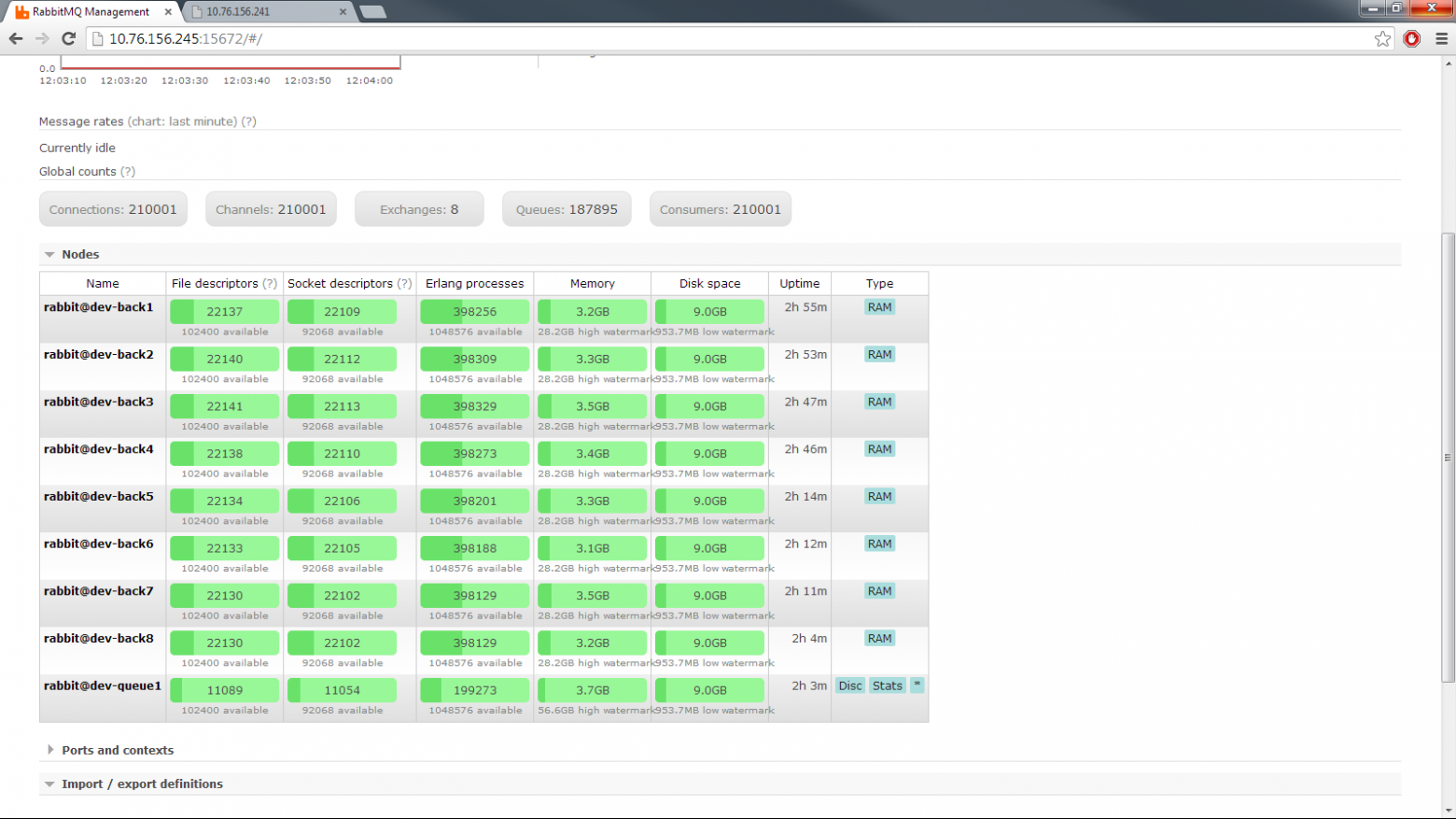
Задача организовать подписку на события для клиентов (кроссплатформенный клиент-бороузер). расчетное кол-во клиентов 1000000. Стресс задача — все клиенты (сволочи) ломятся за событиями. Собирали стенд на 1000000 одновременных коннектов. остановились на 210000 потому, что понятно, что держит и как масштабироваться и смысл лупить дальше коннекты не имеет смысла.
конфиг nginx
Собственно как все решилось. Клиент использует websocket+stomp. кролик умеет stomp из коробки. между клиентами и кроликом стоит nginx, который умеет апстримы и вебсокеты. тем самым при выпадении любой нодды клиент просто переконекчивается и живет дальше. nginx так же осуществляет балансировку по нодам кролика. nginx балансируется DNS балансировкой с ТТЛ 60, тем самым решается автоматическое исключение фронта, т.е. кластер полностью автоматизирован.
Во что уперлись. Да собственно в канал, потому, что выдать всем клиентам одновременно 1024байт (json) в таких масштабах превращается в гигабиты траффика. Мы уперлись на 1Гб в сетевухи. Инженеры могли переделать на 10Гб, но нам уже было не надо.
Что имели при тестах. Без оптимизации ОС кролик благополучно падал так, что восстановить кластер было не возможно. Выедал всю память, Уходил в своп и тю-тю… kill -9 и кластера нет. Лечилось полной остановкой, удалением mnesia кролика и пересборкой кластера ручками.
Рекомендации. Не жалейте памяти. Для кролика оно все. Считайте циферки до, чем после. Прежде чем что-то сделать — нарисуйте на бумаге и покажите знакомым. Может что посоветуют.
Что использовали:
— CentOS release 6.5 (Final) (тюненый TCP стек и ядро под HA)
— {rabbit,«RabbitMQ»,«3.1.5»},
— {mnesia,«MNESIA CXC 138 12»,«4.5»},
— nginx version: nginx/1.4.4
— клиент sock.js stomp.js из коробки (проверяли почти во всех броузерах. все пашет именно по вебсокетам на постоянном коннекте. старые ИЕ летят по HRX по лонг-поллинг)
Резюме? Все работает почти из коробки. Немного напильника и жизнь удалась.
Что было у нас:
Задача организовать подписку на события для клиентов (кроссплатформенный клиент-бороузер). расчетное кол-во клиентов 1000000. Стресс задача — все клиенты (сволочи) ломятся за событиями. Собирали стенд на 1000000 одновременных коннектов. остановились на 210000 потому, что понятно, что держит и как масштабироваться и смысл лупить дальше коннекты не имеет смысла.

конфиг nginx
#
# Transport site
#
upstream rabbitmq {
server dev-queue1:15674 weight=5;
server dev-queue2:15674 weight=10;
server dev-back1:15674 weight=10;
server dev-back2:15674 weight=10;
server dev-back3:15674 weight=10;
server dev-back4:15674 weight=10;
server dev-back5:15674 weight=10;
server dev-back6:15674 weight=10;
server dev-back7:15674 weight=10;
server dev-back8:15674 weight=10;
}
server {
listen 80;
listen 88;
server_name 10.76.156.241 dev-front1;
access_log off;
error_log /dev/null;
root /var/www;
location /stomp/ {
proxy_pass http://rabbitmq;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_buffering off;
}
location / {
}
}
#
# end
#
Собственно как все решилось. Клиент использует websocket+stomp. кролик умеет stomp из коробки. между клиентами и кроликом стоит nginx, который умеет апстримы и вебсокеты. тем самым при выпадении любой нодды клиент просто переконекчивается и живет дальше. nginx так же осуществляет балансировку по нодам кролика. nginx балансируется DNS балансировкой с ТТЛ 60, тем самым решается автоматическое исключение фронта, т.е. кластер полностью автоматизирован.
Во что уперлись. Да собственно в канал, потому, что выдать всем клиентам одновременно 1024байт (json) в таких масштабах превращается в гигабиты траффика. Мы уперлись на 1Гб в сетевухи. Инженеры могли переделать на 10Гб, но нам уже было не надо.
Что имели при тестах. Без оптимизации ОС кролик благополучно падал так, что восстановить кластер было не возможно. Выедал всю память, Уходил в своп и тю-тю… kill -9 и кластера нет. Лечилось полной остановкой, удалением mnesia кролика и пересборкой кластера ручками.
Рекомендации. Не жалейте памяти. Для кролика оно все. Считайте циферки до, чем после. Прежде чем что-то сделать — нарисуйте на бумаге и покажите знакомым. Может что посоветуют.
Что использовали:
— CentOS release 6.5 (Final) (тюненый TCP стек и ядро под HA)
— {rabbit,«RabbitMQ»,«3.1.5»},
— {mnesia,«MNESIA CXC 138 12»,«4.5»},
— nginx version: nginx/1.4.4
— клиент sock.js stomp.js из коробки (проверяли почти во всех броузерах. все пашет именно по вебсокетам на постоянном коннекте. старые ИЕ летят по HRX по лонг-поллинг)
Резюме? Все работает почти из коробки. Немного напильника и жизнь удалась.
Спасибо за статью, особенно спасибо товарищу 440hz за полезный коментарий, так как в данный момент как раз работаю над подобной задачей
А эта упячка уже научилась не пересылать по сети лямбды?
Когда кластер разваливается от того, что на разных хостах разные версии виртуальной машины или самого кролика, ни о каком HA речи идти не может, поскольку оно не позволяет делать апгрейд без остановки.
Когда кластер разваливается от того, что на разных хостах разные версии виртуальной машины или самого кролика, ни о каком HA речи идти не может, поскольку оно не позволяет делать апгрейд без остановки.
мысль хорошая. про апгрейд даже пока не думали.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Highly Available кластер RabbitMQ