Комментарии 53
стиль регулярных выражений: PHP
Мне кажется, что стоит уточнить как минимум как на самом сайте: PHP -> PHP (PCRE), так как, например, лично я первым делом подумал про регэкспы из перла и sed'а.
Логотип явно спёрли :)


Было бы совсем здорово, если бы этот сервис выдавал примеры строк, подходящих под регэксп.
А вообще, Regexper, имхо, нагляднее. Даже на примере с КДПВ (
А вообще, Regexper, имхо, нагляднее. Даже на примере с КДПВ (
/h[a4@](([c<]((k)|(\|<)))|((k)|(\|<))|(x))\s+((d)|([t\+]h))[3ea4@]\s+p[l1][a4@]n[3e][t\+]/i — для ленивых)Было бы совсем здорово, если бы этот сервис выдавал примеры строк, подходящих под регэксп.
Ох как не хватает когда начинаешь разбираться в чужом регэкспе. И приходится заново писать свой, а в итоге через часок мучений получался такой же, было такое. Увидев новость сразу понадеялся на эту фичу, но не тут то было :(
Есть вот такая штука:
bitbucket.org/leapfrogdevelopment/rstr/
У неё есть метод xeger(), которая умеет то, что вам надо. Насколько хорошо работает — не проверял. Думаю, что вокруг неё навернуть тривиальный web-интерфейс тоже не проблема.
bitbucket.org/leapfrogdevelopment/rstr/
У неё есть метод xeger(), которая умеет то, что вам надо. Насколько хорошо работает — не проверял. Думаю, что вокруг неё навернуть тривиальный web-интерфейс тоже не проблема.
Поиск строки подходящей под регэксп — NP-полная задача. Конечно, для большого подмножества регэкспов это сделать несложно и этого подмножества хватит за уши для регэкспов, попадающихся на практике.
К линку www добавьте, иначе облом. Спасибо за сервис. А так чтобы наоборот, составлять графы в выражение?
Есть такая интересная штука, как вербальные выражения:
/^(http)(s)?(\:\/\/)(www\.)?([^\ ]*)$/ становитсяvar tester = VerEx()
.startOfLine()
.then( "http" )
.maybe( "s" )
.then( "://" )
.maybe( "www." )
.anythingBut( " " )
.endOfLine();
habrahabr.ru/post/192920/?reply_to=6701148#comment_6700856
С момента комментария успел чуть поэкспериментировать, вроде работает прилично, даже на регулярке для проверке емэйлов. Генерит правда такой ад, что страшно делается от осознания того, каким может быть адрес :-)
С момента комментария успел чуть поэкспериментировать, вроде работает прилично, даже на регулярке для проверке емэйлов. Генерит правда такой ад, что страшно делается от осознания того, каким может быть адрес :-)
Regexper неплох (:
Да, разбор знменитого регэкспа для валидации email впечатляет:
regex101.com/r/lP7vL3
regex101.com/r/lP7vL3
Да и просто раскрашенный регексп круто выглядит. Подумываю распечатать на цветном принтере и повесить над рабочим местом :-)
разбор в www.debuggex.com/ впечатляет куда сильнее… www.debuggex.com/r/Db8mjii2FkMI2Qtv/0
Теперь намного понятнее!
Похож на www.rubular.com с дополнительными фичами. Спасибо!
Недавно обнаружил www.debuggex.com/ — по-моему, самый лучший сервис. Представляет в визуальном виде регулярку и очень помогает в их написании.
В IDEA испоьзую Regex Tester:
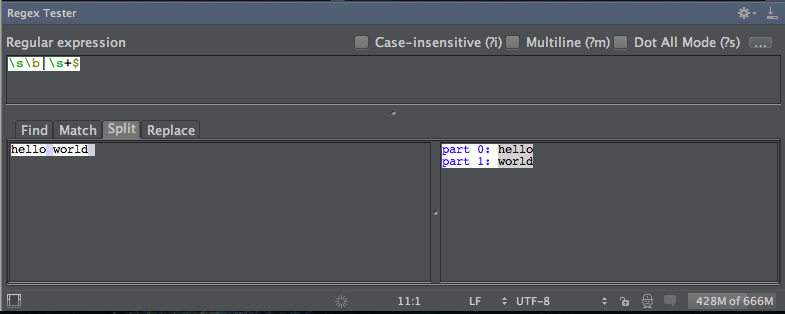

Еще есть www.pcre.ru/eval/
В общую копилку: gskinner.com/RegExr/
Туда же regexpal.com/
НЛО прилетело и опубликовало эту надпись здесь
Мне весьма понравился этот тестер: rubular.com/
Вот лучше бы Фридла почитали, чтобы вместо ужаса типа
(www\.[A-z\d\.\+\-]+) было что-то типа /(w{3}\.[-a-z\d+.]+)/i
(www\.[A-z\d\.\+\-]+) было что-то типа /(w{3}\.[-a-z\d+.]+)/i
А что быстрее работать будет «www» или w{3}? Что-то логика мне подсказывает, что второй вариант будет сопоставим по скорости только если библиотеку писали пряморукие люди.
Что-то мне подсказывает, что криворукие люди не напишут в продакшен машину регулярных выражений.
А что быстрее будет работать — честно говоря пофик, микрооптимизации меня никогда не интересовали.
А что быстрее будет работать — честно говоря пофик, микрооптимизации меня никогда не интересовали.
Подумал. Второй вариант всегда будет чуть медленнее (опять же при допущении пряморуких), т.к. будет некоторый оверхед на разбор скобок и поиск выражения в них.
Это не камень в ваш огород, просто в данном, конкретном примере w{3} выглядит как раз, как некая микрооптимизация. Причем в данном случая я не могу понять ее смысл.
Это не камень в ваш огород, просто в данном, конкретном примере w{3} выглядит как раз, как некая микрооптимизация. Причем в данном случая я не могу понять ее смысл.
Скорее это выглядит как выпендрёж, т.к. во-первых «www» слегка читабельнее, чем w{3}, а во-вторых содержит меньше символов и даже набирается быстрее xD
А вот в том, что [A-z\d\.\+\-] — это ужас, meettya полностью прав, особенно «A-z» доставляет… хотя… вдруг это хитрая оптимизация чтобы захватить символы между Z и a :-)
А вот в том, что [A-z\d\.\+\-] — это ужас, meettya полностью прав, особенно «A-z» доставляет… хотя… вдруг это хитрая оптимизация чтобы захватить символы между Z и a :-)
Отличный сервис.
Чего не хватает:
— помощи по флагам, как например в указанном ранее www.debuggex.com/
— дебаггера как в RegexBuddy, что очень помогает отлаживать выражения, а главное оптимизировать по скорости (правда такого я онлайн пока не видел).
Чего не хватает:
— помощи по флагам, как например в указанном ранее www.debuggex.com/
— дебаггера как в RegexBuddy, что очень помогает отлаживать выражения, а главное оптимизировать по скорости (правда такого я онлайн пока не видел).
На regex101.com/ правило (поиск внутри кавычек):
вылавливает только первое совпадение.
rubular.com/ и gskinner.com/RegExr/ находят все кавычковые блоки.
(?>(?<!\\)(?>"(?>\\.|[^\\"]+)+"|""|(?>'(?>\\.|[^\\']+)+')|''|(?>`(?>\\.|[^\\`]+)+`)|``))вылавливает только первое совпадение.
rubular.com/ и gskinner.com/RegExr/ находят все кавычковые блоки.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Разбор регулярных выражений