JRE позволяет абстрагироваться от конкретной платформы, делая написание кросс-платформенного кода намного проще. Конечно до идеала Write once, run anywhere не дотягивает, но жизнь облегчает существенно.
С изобилием framework'ов и полнотой собственной стандартной библиотеки, мысль о том, что программа запускается на вполне конкретном железе, постепенно отходит на второй план. В большинстве случаев это оправдано, но иногда жизнь вносит свои коррективы.
Подавляющее большинство современных процессоров имеют кэш-память для хранения часто используемых данных. Кэш-память делится на блоки (Сache line). Механизмы реализующие Cache coherence обеспечивают синхронизацию кэш-памяти между ядрами процессора(ов) в компьютерной системе.
Термин false sharing означает доступ к разным объектам в программе, разделяющим один и тот же блок кэш-памяти. False sharing в многопотоковом приложении, когда в одном блоке оказываются переменные модифицируемые из разных потоков, ведет к снижению производительности и увеличению нагрузки на Cache coherence механизмы. Подробно о том как это происходит, можно прочесть в статье на эту тему.
Многопотоковое приложение, потоки, на каждой итерации, берут предыдущее значение из своей ячейки общего массива, проводят вычисления и складывают результаты обратно.
Проверим что jvm не внесла лишних оптимизаций:
Если globalArray не сделать volatile, то jvm не будет читать каждый раз из памяти:
В реальной жизни, когда расчетый метод будет нетривиальным, такой оптимизации может и не случиться.
Создаем новый проект в VTune Amplifier:
Создаем и запускаем Generic Exploration analysis. В summary видим:
CPI — 2.100, при нормальном для расчетных задач 1 и менее. Переходим во view Hardware issues:
Присутствует Contested access, означающий что данные записанные одним потоком, читаются другим потоком и при этом потоки выполняются на разных ядрах/CPU.
То есть ячейки массива globalArray попали в один cache line.
Для того чтобы избежать этой ситуации, разнесем ячейки в памяти на величину cache linе. В Intel i5 размер cache line составляет 64 байта. Меняем строчку
на
Почему не i * 8? Потому что в случае массивов, первым элементом после заголовка объекта идет длина (поле length). При операциях доступа к элементам, jvm может считывать это поле для проверки допустимости индекса.
Запускаем повторный анализ в Vtune:
CPI — 0.586, Contested access ушел, Пропорционально с CPI изменилось и время работы, с 13.7 до 4.5 секунд.
Тестирование проводилось на однопроцессорной машине, в случае многопроцессорной конфигурации, накладные расходы на синхронизацию кэш-памяти будут еще больше.
Естественно, такая же проблема может возникнуть и при доступе к полям объектов. Но поскольку минимальный размер объекта (c одним полем) в hostpot jvm 16 байт, то проблема будет встречаться реже. Способ избежать false sharing для объектов с помощью наследования можно посмотреть в исходниках jmh, в реализации BlackHole'ов. Как один из вариантов — не создавать оптом объекты для всех потоков, а разнести этот процесс во времени.
Тестирование проводилось на машине с процессором Intel Core i5 3.3 GHz, 64bit JDK 1.7.0_21, Intel Vtune Amplifier XE 2013 Update 11 (build 300544) Evaluation license, Windows 7 64bit.
PS. Не стоит воспринимать цифры производительности приведенные в статье буквально. Результаты в большой степени будут зависеть от внешних факторов, например от того как OS совместно с jvm распределят потоки по ядрам процессора(ов). Но если создается нечто высокопроизводительное, то такие особенности целевых платформ стоит учитывать.
С изобилием framework'ов и полнотой собственной стандартной библиотеки, мысль о том, что программа запускается на вполне конкретном железе, постепенно отходит на второй план. В большинстве случаев это оправдано, но иногда жизнь вносит свои коррективы.
Подавляющее большинство современных процессоров имеют кэш-память для хранения часто используемых данных. Кэш-память делится на блоки (Сache line). Механизмы реализующие Cache coherence обеспечивают синхронизацию кэш-памяти между ядрами процессора(ов) в компьютерной системе.
Термин false sharing означает доступ к разным объектам в программе, разделяющим один и тот же блок кэш-памяти. False sharing в многопотоковом приложении, когда в одном блоке оказываются переменные модифицируемые из разных потоков, ведет к снижению производительности и увеличению нагрузки на Cache coherence механизмы. Подробно о том как это происходит, можно прочесть в статье на эту тему.
Инструментарий
- hsdis plugun для дизассемблирования jit кода.
- Intel® VTune™ Amplifier XE 2013 для профайлинга и получения CPU счетчиков.
Пример
Многопотоковое приложение, потоки, на каждой итерации, берут предыдущее значение из своей ячейки общего массива, проводят вычисления и складывают результаты обратно.
Скрытый текст
public class SArray {
// если не сделать volatile jvm оптимизирует
private static volatile long globalArray[] = new long[512];
public static class MThread implements Runnable {
private int aPos;
private long iterations;
public MThread(long iterations, int aPos) {
this.aPos = aPos;
this.iterations = iterations;
}
@Override
public void run() {
for(long l = 0; l < iterations; ++l) {
++globalArray[aPos];
}
System.out.printf("A:TID:%d, count: %d\n",
Thread.currentThread().getId(), globalArray[aPos]);
}
}
private static final int THREAD_COUNT =
Runtime.getRuntime().availableProcessors();
private static final long ITERATIONS = 1870234052L;
public static void main(String[] args) throws Throwable {
Thread[] threads = new Thread[THREAD_COUNT];
long smillis = System.currentTimeMillis();
for(int i = 0; i < THREAD_COUNT; ++i) {
threads[i] = new Thread(new MThread(ITERATIONS, i));
}
for(Thread t: threads) {
t.start();
}
for(Thread t: threads) {
t.join();
}
System.out.printf("Total iterations on %d threads: %d, took %d ms\n",
THREAD_COUNT,
ITERATIONS, System.currentTimeMillis() - smillis);
}
}
Проверим что jvm не внесла лишних оптимизаций:
java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,SArray$MThread::run
-XX:PrintAssemblyOptions=intel -cp target\falseshare-1.0-SNAPSHOT.jar SArray
Скрытый текст
0x0000000002350540: mov r11d,DWORD PTR [r13+0xc]
0x0000000002350544: mov r10d,DWORD PTR [r8+0x70] ;*getfield aPos
; - SArray$MThread::run@15 (line 18)
0x0000000002350548: mov r9d,DWORD PTR [r12+r10*8+0xc]
; implicit exception: dispatches to 0x00000000023505dd
0x000000000235054d: cmp r11d,r9d
0x0000000002350550: jae 0x0000000002350599 ;*laload
; - SArray$MThread::run@19 (line 18)
0x0000000002350552: shl r10,0x3
; >>>>
; счетчик увеличивается в памяти
0x0000000002350556: inc QWORD PTR [r10+r11*8+0x10]
;*goto
; - SArray$MThread::run@27 (line 17)
0x000000000235055b: add rbx,0x1 ; OopMap{r8=Oop r13=Oop off=127}
;*goto
; - SArray$MThread::run@27 (line 17)
0x000000000235055f: test DWORD PTR [rip+0xfffffffffddefa9b],eax # 0x0000000000140000
;*goto
; - SArray$MThread::run@27 (line 17)
; {poll}
0x0000000002350565: cmp rbx,QWORD PTR [r13+0x10]
0x0000000002350569: jl 0x0000000002350540 ;*ifge
Если globalArray не сделать volatile, то jvm не будет читать каждый раз из памяти:
Скрытый текст
0x00000000021e0592: add rbx,0x1 ;*ladd
; - SArray$MThread::run@25 (line 17)
; >>>>
; значение считано 1 раз и в цикле только пишется в массив
0x00000000021e0596: add r8,0x1 ;*ladd
; - SArray$MThread::run@21 (line 18)
0x00000000021e059a: mov QWORD PTR [r11+rcx*8+0x10],r8
; OopMap{r11=Oop r13=Oop off=127}
;*goto
; - SArray$MThread::run@27 (line 17)
0x00000000021e059f: test DWORD PTR [rip+0xfffffffffe24fa5b],eax # 0x0000000000430000
;*goto
; - SArray$MThread::run@27 (line 17)
; {poll}
0x00000000021e05a5: cmp rbx,r10
0x00000000021e05a8: jl 0x00000000021e0592 ;*ifge
В реальной жизни, когда расчетый метод будет нетривиальным, такой оптимизации может и не случиться.
В данном случае volatile применен исключительно, чтобы сбить с толку оптимизатор. Запись вида volatile long[] array, означает что семантика volatile относится к указателю на массив, а не к его элементам.
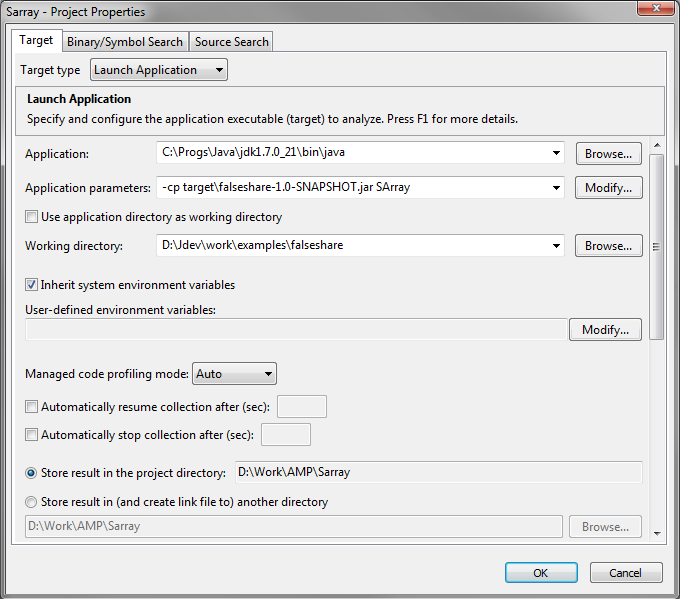
Создаем новый проект в VTune Amplifier:
Скрытый текст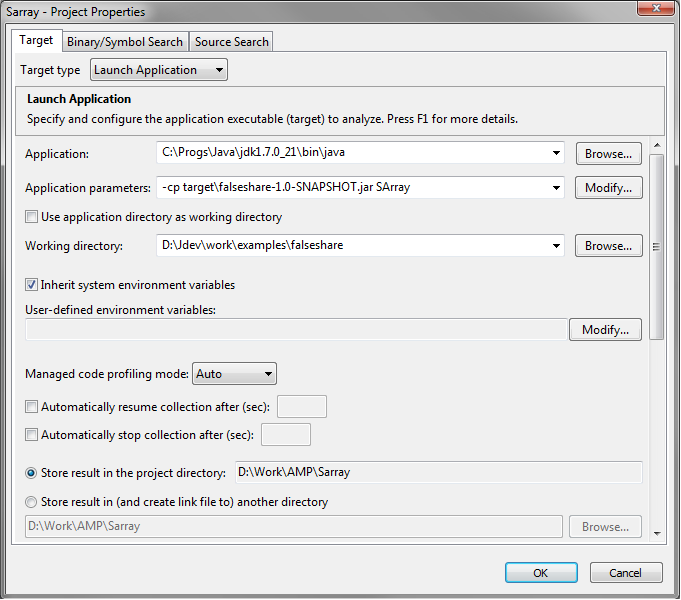
Создаем и запускаем Generic Exploration analysis. В summary видим:
Скрытый текст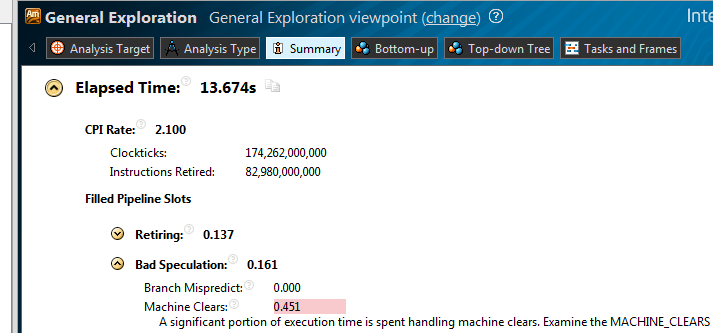
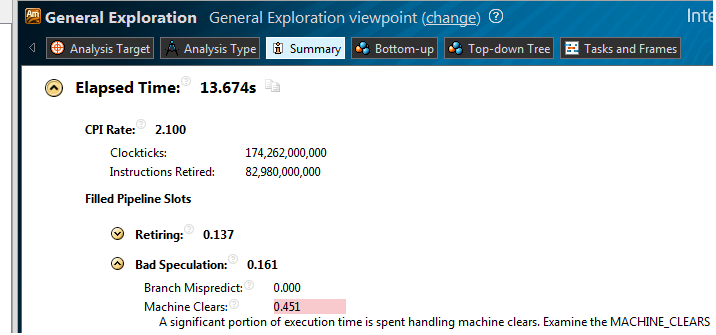
CPI — 2.100, при нормальном для расчетных задач 1 и менее. Переходим во view Hardware issues:
Скрытый текст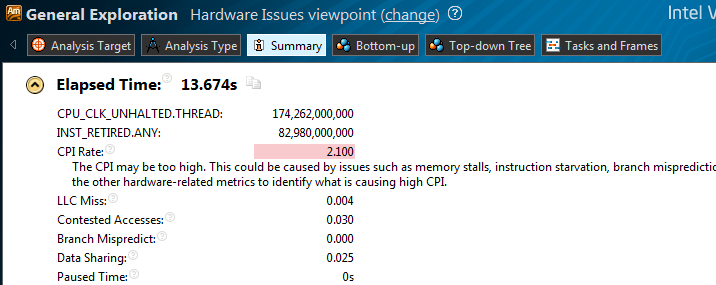
Присутствует Contested access, означающий что данные записанные одним потоком, читаются другим потоком и при этом потоки выполняются на разных ядрах/CPU.
То есть ячейки массива globalArray попали в один cache line.
Для того чтобы избежать этой ситуации, разнесем ячейки в памяти на величину cache linе. В Intel i5 размер cache line составляет 64 байта. Меняем строчку
threads[i] = new Thread(new MThread(ITERATIONS, i));
на
threads[i] = new Thread(new MThread(ITERATIONS, (i + 1) * 8));
Почему не i * 8? Потому что в случае массивов, первым элементом после заголовка объекта идет длина (поле length). При операциях доступа к элементам, jvm может считывать это поле для проверки допустимости индекса.
Запускаем повторный анализ в Vtune:
Скрытый текст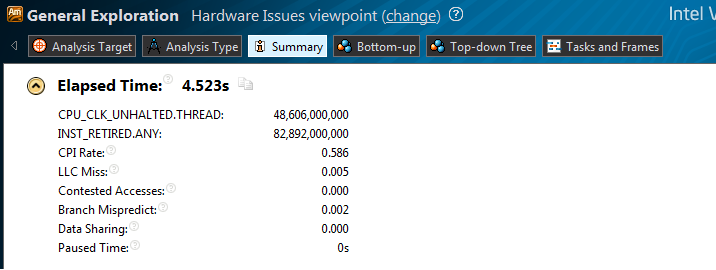

CPI — 0.586, Contested access ушел, Пропорционально с CPI изменилось и время работы, с 13.7 до 4.5 секунд.
Тестирование проводилось на однопроцессорной машине, в случае многопроцессорной конфигурации, накладные расходы на синхронизацию кэш-памяти будут еще больше.
Естественно, такая же проблема может возникнуть и при доступе к полям объектов. Но поскольку минимальный размер объекта (c одним полем) в hostpot jvm 16 байт, то проблема будет встречаться реже. Способ избежать false sharing для объектов с помощью наследования можно посмотреть в исходниках jmh, в реализации BlackHole'ов. Как один из вариантов — не создавать оптом объекты для всех потоков, а разнести этот процесс во времени.
Тестирование проводилось на машине с процессором Intel Core i5 3.3 GHz, 64bit JDK 1.7.0_21, Intel Vtune Amplifier XE 2013 Update 11 (build 300544) Evaluation license, Windows 7 64bit.
PS. Не стоит воспринимать цифры производительности приведенные в статье буквально. Результаты в большой степени будут зависеть от внешних факторов, например от того как OS совместно с jvm распределят потоки по ядрам процессора(ов). Но если создается нечто высокопроизводительное, то такие особенности целевых платформ стоит учитывать.







