Комментарии 36
Почему то сразу вспомнился «Криптономикон» Стивенсона. Спасибо, очень интересно…
Очень круто. Предлагаю организовать музей современного технического искусства.
Не понимаю минусующих. Погуглите супрематизм.
забавно. а какие последствия от таких находок? есть ли возможность предсказать хоть с какой-то увеличенной долей вероятности следующее число на основе таких изысканий?
У части чисел, распределенных по определенному закону, получается, вероятность выпадания больше. Как сайд-эффект могут случаться интересные баги, например, при моделировании процессов или в каких-нибудь криптографических алгоритмах.
Скорее метод обнаружения псевдослучайностей, там где должна быть чистая случайность. Т.е. поиск фальсификаций, поиск неучтенных закономерностей и т.п.
Интересно, когда проведут масштабный эксперимент с квантовыми процессами и т.п., и мы узнаем, что живем в Матрице, нас сотрут, или дадут жить с этой мыслью и дальше? :)
Интересно, когда проведут масштабный эксперимент с квантовыми процессами и т.п., и мы узнаем, что живем в Матрице, нас сотрут, или дадут жить с этой мыслью и дальше? :)
Речь скорее не о предсказаниях (можно лишь утверждать, что с какой-то вероятностью при делении на Х оно будет выбрасывать какой-либо остаток), на мой взгляд такой метод позволяет выявлять скрытые зависимости между числами, например, если остатки часто ложатся на прямую, это жжжж неспроста.
А начнем мы со стандартного С-шного генератора rand
Если автор использовал версию rand() которая не может возвращать числа больше чем 32767, получал остаток от деления на числа порядка 100 — 1000 которые не являются степенью двойки, то он ошибся.
Например, выражение rand() % 1000 будет выдавать числа от 0 до 767 заметно чаще, чем от 768 до 999.
Тут проблема не в rand, а в его использовании.
Предлагаю первый график для rand перестроить. Взять в качестве функции (rand() << 15) ^ rand() или int a = rand(); return (a << 15) ^ a;
Вы правы, на картинке с рандом артефакт, странно, что разброс достигает ~1000 (9%), а ожидается 1/33 или 3%.
А если ксорить, это уже совсем другой генератор получается.
И, да, он похож на хороший.
Провел эксперимент, не учитывал в построении гистограмм «хвосты».
Т.е., например при делении на 1000 всё, что попадало выше 32000 игнорировалось.
Визуально картинка не изменилась, полосатая структура осталась.
Т.е., например при делении на 1000 всё, что попадало выше 32000 игнорировалось.
Визуально картинка не изменилась, полосатая структура осталась.
Если выложишь код, поможем найти ошибку.
Выложил в диалогах, могу и здесь, если еще кому интересно.
Как и предполагалось, rand не виноват.
Полосы на картинке с ним — это артефакт работы заполнителя массива с числами, максимальное из которых сравнимо с 1000
С этим алгоритмом можно у любого генератора случайных чисел оставить последние 15 бит (random() & 0x7fff) и получить аналогичную картину.
Кстати, полосы проявятся лучше, если оставить ещё меньше бит в случайном числе.
Вот картина, для которой максимальное случайное число было 0xfff:
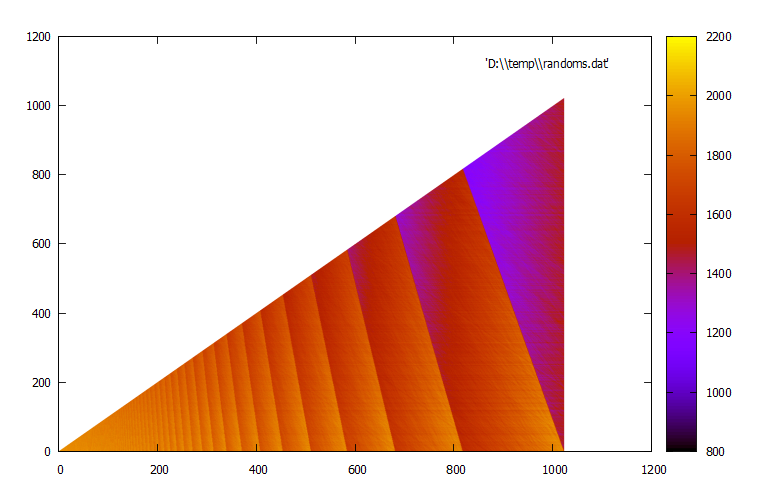
Полосы на картинке с ним — это артефакт работы заполнителя массива с числами, максимальное из которых сравнимо с 1000
for (int i = 0; i < 2000000; i++)
{
int val = rand();
for (int ix = 1; ix <= sz; ix++)
if (max_rand - val > ix) //это должно было быть отсечение "плохих" чисел рядом с 32768, но оно не работает
hists[ix - 1][val % ix] ++;
}
С этим алгоритмом можно у любого генератора случайных чисел оставить последние 15 бит (random() & 0x7fff) и получить аналогичную картину.
Кстати, полосы проявятся лучше, если оставить ещё меньше бит в случайном числе.
Вот картина, для которой максимальное случайное число было 0xfff:

А что за генератор, предоставленный Юрием Ткачевым?
правильный генератор, написанный правильными людьми, если нужны исходники, могу спросить у него разрешения
Спросите, интересно же.
По всей видимости, вот это www.codeproject.com/Articles/3068/A-Mersenne-Twister-Class
Если нужно проверить последовательность на псевдослучайность, почему бы не использовать DIEHARD?
А Вы опасный человек…
«А вот распределение произведения из двух чисел, каждое от 0 до 4000 выглядит так:..»
Не мог бы автор пояснить, диаграму чего он построил в примере, где появились полосы. Я слегка не понял.
Не мог бы автор пояснить, диаграму чего он построил в примере, где появились полосы. Я слегка не понял.
Мм, имеется в виду 16кк чисел, не так ли?
Это распределение того, что выдает rand(). Появилось мнение, что полосы — это артефакт, вызванный тем, что rand возвращает 15-битные значения и, скажем, при делении на 1000 возникает статистическая неравномерность. Но перепады значений в гистограмме существенно больше, чем этого можно было бы ожидать, в разы больше. Так что я не готов (пока) окончательно согласиться с данным утверждением.
а про 4000 — два вложенных цикла 0..4000, в обработку попадает произведение двух счетчиков этих циклов
а про 4000 — два вложенных цикла 0..4000, в обработку попадает произведение двух счетчиков этих циклов
zzeng, спасибо за статью.
А что вы думаете про биологический датчик случайных чисел, видел такие, на неком ПО. Надо мышкой возить и кнопочки на клавиатуре беспорядочно нажимать. Интересует, целесообразность таких решений.
.jpg)
А что вы думаете про биологический датчик случайных чисел, видел такие, на неком ПО. Надо мышкой возить и кнопочки на клавиатуре беспорядочно нажимать. Интересует, целесообразность таких решений.
Смешивать шум, полученный из источников, основанных на разных физических принципах — полезно. Вспомним хотя бы Marsaglia с его черно-белым шумом.
Полезно только если это часть алгоритма генерации, если же весь такой ключ будет основан только на движение мышки и нажатии на клавиатуру, появляется возможность довольно легко перехватить, подобрать алгоритм и сгенерировать такой же ключ.
Думается мне что основный смысл этого «био рандома» в «вау» эффекте пользователя и придании «защищенности персональных данных» опять же для пользователя.
Думается мне что основный смысл этого «био рандома» в «вау» эффекте пользователя и придании «защищенности персональных данных» опять же для пользователя.
НЛО прилетело и опубликовало эту надпись здесь
Довольно интересно. Я использовал последовательности вместо ГПСЧ для процедурной генерации ландшафтов, но я использовал сиракузские последовательности. Всё бы ничего, но они слишком быстро сходятся к 1 :)
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Анализируем числовые последовательности