Комментарии 325
Ещё чего.
Пост не читай — комментарий к посту пиши? Зато вы первый, ага.
Пост читал. Не согласен. Комментарии нужны почти везде, кроме геттеров, сеттеров и getItemByID.
Зачем они нужны? Аргументируйте, пожалуйста, свои высказывания.
После таких вот XP техник без комментариев я потрачу до 5 раз больше времени на разбор действий кода, чем с комментариями. До 10% функций кода рискуют быть непонятыми вследствие их костыльности или неочевидности.
И это позволяет быстро локализовтаь эти 10% костыльных и не очивидных мест в коде, которыми необходимо занятся в первую очередь. Там и коментарий можно поставить с пометкой // TODO…
Комментарии todo не нужны, поскольку их специально практически никто не do.
Не надо говорить за всех, пожалуйста.
Я, например, вообще предпочитаю сначала написать общую структуру программы в виде комментариев todo, а потом уже реализовывать. Какие-то todo остаются «на потом», конечно.
Я, например, вообще предпочитаю сначала написать общую структуру программы в виде комментариев todo, а потом уже реализовывать. Какие-то todo остаются «на потом», конечно.
Я тоже так раньше делал, вот только потом понял что таким образом очень плохо контролируется что уже реализовано, а что случайно осталось «на потом». Намного лучше писать костяк будущего кода сразу вызовами несуществующих пока функций — таким образом сохраняется принцип «сначала написать общую структуру» и никогда не забудется написать что-то важное (код просто не скомпилируется).
Вот хочется, чтобы он скопиллировался;)
Критичные TODO можно написать так:
Менее критичные так:
А совсем «на потом» так:
Критичные TODO можно написать так:
#error TODO! implement this feature
Менее критичные так:
#warning TODO! implement this feature
А совсем «на потом» так:
// TODO! implement this feature
Если то, что Вы отметили как "#error" должно препятствовать компиляции — то какой смысл такое писать? Не лучше ли сразу написать вызов будущего метода — и меньше писанины, и задел на будущее.
По поводу "#warning" — согласен, до этого вполне могут дойти руки, потому что «надо сделать чтобы проект собирался без ворнингов!» — этим руководствуются многие.
А "// TODO" — полностью бесполезная вещь — забудете и не сделаете никогда (ну разве что ваша IDE эти штуки умеет собирать и показывать в одном месте — но даже в этом случае вряд ли до них дойдут руки).
По поводу "#warning" — согласен, до этого вполне могут дойти руки, потому что «надо сделать чтобы проект собирался без ворнингов!» — этим руководствуются многие.
А "// TODO" — полностью бесполезная вещь — забудете и не сделаете никогда (ну разве что ваша IDE эти штуки умеет собирать и показывать в одном месте — но даже в этом случае вряд ли до них дойдут руки).
В моей среде разработки TODO и FIXME подсвечиваются особым цветом.
Для того чтобы не помнить о всех TODO есть специальная владка где задания разделены на проект, текущий файл и скоп:
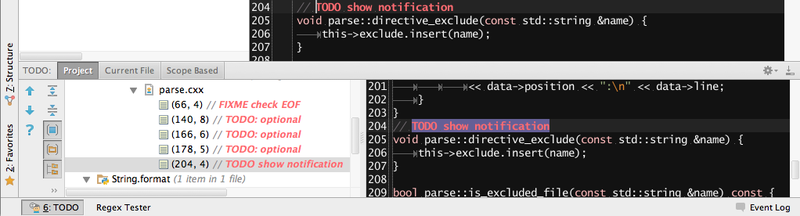
Для того чтобы не помнить о всех TODO есть специальная владка где задания разделены на проект, текущий файл и скоп:
www.rau.su/observer/N07_96/7_14.HTM
TL;DR: Если вы вместо TODO занимались чем-то другим, есть немалая вероятность, что это что-то другое оказалось важнее.
TL;DR: Если вы вместо TODO занимались чем-то другим, есть немалая вероятность, что это что-то другое оказалось важнее.
Лучше называть методы нормально и код писать понятно, а тотальное комментирование приводит к наплевательскому отношению к их написанию.
В итоге получаем уродцев с автогенерированными комментариями типа
//Builds the Ext
public void BuildExt()
и так постоянно
Зато блин покрытие комментариями 100%, только это блин мусор. А натыкаясь на мусор перестаёшь видеть действительно стоящие комментарии.
В итоге получаем уродцев с автогенерированными комментариями типа
//Builds the Ext
public void BuildExt()
и так постоянно
Зато блин покрытие комментариями 100%, только это блин мусор. А натыкаясь на мусор перестаёшь видеть действительно стоящие комментарии.
Лучший комментарий — это тест.
Function InitClient(someArguments, &error=Null) {
//Логика работы: 1. Старт сокета, 2. соединение, 3. хендшейк
//Входящие параметры: тратата
//Возврат: Объект типа ClientConnection; Null в случае какой-то ошибки, error содержит описание ошибки
// 1. Старт сокета
Code Code Code
// 2. Соединение
Code Code Code
// 3. Хендшейк
Code Code Code
} //Конец InitClient
В таком случае я могу понять логику в 1 строке, пропуская весь код функции. Если всё грамотно сделано, то сокращает анализ кода
//Логика работы: 1. Старт сокета, 2. соединение, 3. хендшейк
//Входящие параметры: тратата
//Возврат: Объект типа ClientConnection; Null в случае какой-то ошибки, error содержит описание ошибки
// 1. Старт сокета
Code Code Code
// 2. Соединение
Code Code Code
// 3. Хендшейк
Code Code Code
} //Конец InitClient
В таком случае я могу понять логику в 1 строке, пропуская весь код функции. Если всё грамотно сделано, то сокращает анализ кода
Сколько строчек кода в функции? Можно отрефакторить и вынести код в три метода с понятными названиями.
Иногда рефакторить вредно — когда операция идет на неявно связанных объектах единожды в программе, но при этом используется весьма много параметров, у вас получится еще большая каша.
А иногда просто функция сложная и состоит из этапов. Удобно вам иметь одну функцию, которая делает что надо и разбита по пунктам, или лучше иметь InitClient(Arg){return InitClient_Step3(InitClient_Step2(InitClient_Step1(Arg)))}
А иногда просто функция сложная и состоит из этапов. Удобно вам иметь одну функцию, которая делает что надо и разбита по пунктам, или лучше иметь InitClient(Arg){return InitClient_Step3(InitClient_Step2(InitClient_Step1(Arg)))}
Мне второй вариант нравится больше, но разумеется не в таком виде.
Хотя целесообразность наличия такого метода с именно такой функциональностью под вопросом, но для этого нужно контекст знать.
Connection InitClient(args) {
var socket = CreateSocket(args);
var connection = CreateConnection(socket);
connection.StartHandshake();
}Хотя целесообразность наличия такого метода с именно такой функциональностью под вопросом, но для этого нужно контекст знать.
А если вам надо ещё и ошибки обрабатывать? Ваш код превратится в nested hell. Такие случаи лучше разбивать на отдельные фунции и связывать через одну цепочку вызовов с Either. На Scala это будет как-то так
А каждая из функций будет что-то типа
При таком подходе чётко видно какие функции в каком порядке выполняются, каждая функция отвечает за одну задачу и ошибки удобно обрабатывать. Исполнение остановится на первой встреченной ошибке и вернёт сообщение об этом.
def startServer(): Either[String, Server] = {
for {
conf <- loadConfig().right
sever <- startServer(conf).right
_ <- addListeners(server).right
_ <- addHooks(server).right
_ <- logServerSetup(server).right
_ <- verifyServer(server).right
} yield server
А каждая из функций будет что-то типа
def startServer(conf: ServerConfig) = {
try {
val server = new Server(conf)
server.start()
Right(server)
} catch {
case e: ServerException => Left("Failed to start server " + e)
}
При таком подходе чётко видно какие функции в каком порядке выполняются, каждая функция отвечает за одну задачу и ошибки удобно обрабатывать. Исполнение остановится на первой встреченной ошибке и вернёт сообщение об этом.
[off]«Какой кошмар ваш Scala»[/off]
Именно по этой причине я и ввожу переменную по ссылке &error — для возврата ошибки
Именно по этой причине я и ввожу переменную по ссылке &error — для возврата ошибки
Э… то есть если сервер не стартовал, то приложение ругается в код, но продолжает доблестно работать?
Нет, если сервер не стартовал, то функции addListeners, addHooks и т.п. не запускаются вообще, а вызывающему возвращается ошибка в виде Left(error). Вызывающий уже обработает это, в соответствии с бизнес-логикой.
Преимущество в том, что нормальный процесс весь в одном месте, а обработка ошибок вся в одном, но другом, месте. Примерно того же можно добиться бросая некрасивые исключения отовсюду и только ловя их в одном месте. Но это просто некрасиво.
Преимущество в том, что нормальный процесс весь в одном месте, а обработка ошибок вся в одном, но другом, месте. Примерно того же можно добиться бросая некрасивые исключения отовсюду и только ловя их в одном месте. Но это просто некрасиво.
Почему бы такие функции не вынести в объект?
Скажем так, в куче языков просто объект с функциями — весьма нетривиально и\или весьма нестандартно. Этим вы внесете еще большую путаницу. Ну а необходимость выделять под одноразовую «не-reusable» задачу класс — это известный холивар. Я сторонник не городить ООП там, где можно и проще обойтись функциональным программированием.
В добавок, 99% моей текущей деятельности на PoSH, в котором весьма геморройно выглядят любые введения ООП от имени пользователя
В добавок, 99% моей текущей деятельности на PoSH, в котором весьма геморройно выглядят любые введения ООП от имени пользователя
Ну согласитесь, если набор функция оперирует множеством переменных, на 2-3 экрана, ее нужно разбить на методы. Потом оказывается, что эти функции будут работать каждая с 3+ переменными. Безусловно удобнее будет выделить подобное в класс, или переменные вынести в существующий класс.
Это все, если конечно пишешь в ООП стиле, не процедурном
Это все, если конечно пишешь в ООП стиле, не процедурном
Полностью согласен, если язык предусматривает введение классов.
Если же это скриптовый язык типа PoSH, то сама операция создания класса и его объекта вызовет лютый баттхерт, а коллеги не смогут прочитать код, так как введение класса в языке, который в большинстве своем используется для маленьих простых програм — очень редкое и невиданное явление
Если же это скриптовый язык типа PoSH, то сама операция создания класса и его объекта вызовет лютый баттхерт, а коллеги не смогут прочитать код, так как введение класса в языке, который в большинстве своем используется для маленьих простых програм — очень редкое и невиданное явление
Видимо, вы никогда не разбирались в больших проектах. Встретить комментарий — большая радость, уменьшает количество работы и времени для добавления фичи ил правки бага.
Мы говорим о комментировании кода. Нет никакой разницы большой проект или маленький, это уже вопрос проектирования.
Ну а вообще, я только лишь хотел аргументированное мнение от Lamaster, он уже второй комментарий делает пустые заявления.
Ну а вообще, я только лишь хотел аргументированное мнение от Lamaster, он уже второй комментарий делает пустые заявления.
Оо да. На моём веку было много случаев, когда именно в больших проектах комментарии не соответствовали действительности. Потому что код изменился, а комментарий остался.
Так что есть комментарий или нет — а в код смотреть надо. Особенно в больших и старых проектах.
Так что есть комментарий или нет — а в код смотреть надо. Особенно в больших и старых проектах.
Ваше утверждение ничуть не потиворечит созержанию поста. Автор предлагает решение взамен комментариев, которое работает даже лучше них. Понятное дело, что если никто не трудился над понятностью и чистотой кода, то встретить хотя бы комментарий — это просто счастье. Вопрос в том, как писать код сейчас, чтобы при его поддержке не приходилось так же «радоваться».
Ну вот видите, прочитали пост и после этого написали комментарий по делу. Более того, я с вами даже в чем-то согласен. Сам стараюсь писать предельно понятный код(очевидные имена переменных, методов и классов, лаконичные методы, выполняющие одну задачу), но при этом стараюсь еще и дополнять код комментариями. Тем более, что пишу на C# и XML комментарии помогают при использовании методов из других классов.
Всеми руками за! Сам работаю с проектом (livestreet), для примера есть файлы, где на 110 строк только 20 строк кода. Поэтому работа начинается с удаления комментариев — тогда становится возможным читать код, а не комментарий что $sCurrentAction это переменная, которая хранит текущий экшн, и принимает строковые значения.
Ну в публичных CMS это оправдано, тут уровень понимания пользователя может весьма варьироваться.
в публичных CMS есть документация. Не нужно запихивать её в файлы с кодом (пример комментария выше — реален).
Серьёзно, я в первый раз столкнулся с Livestreet и обилие комментариев только мешает разбираться с кодом. Тем более большинство комментариев просто копирует название функций/переменных.
Серьёзно, я в первый раз столкнулся с Livestreet и обилие комментариев только мешает разбираться с кодом. Тем более большинство комментариев просто копирует название функций/переменных.
Не знаю как livestreet, но многие решения генерируют техническую документацию именно из комментариев к коду.
Некоторые IDE могут сворачивать комментарии.
Некоторые IDE могут сворачивать комментарии.
>>многие решения генерируют техническую документацию именно из комментариев к коду.
И это очень плохо. В результате получается документация, которая «как бы есть».
Свернуть комментарии — идея хорошая — но это доп действия ручками. к тому же всё равно остайтся как минимум забитая строка, на том месте. Это всё читаемость не улучшает.
В результате, читать такой код, всё равно что читать книгу, где через каждую строчку серым шрифтом идёт пересказ выше сказанного.
И это очень плохо. В результате получается документация, которая «как бы есть».
Свернуть комментарии — идея хорошая — но это доп действия ручками. к тому же всё равно остайтся как минимум забитая строка, на том месте. Это всё читаемость не улучшает.
В результате, читать такой код, всё равно что читать книгу, где через каждую строчку серым шрифтом идёт пересказ выше сказанного.
>>многие решения генерируют техническую документацию именно из комментариев к коду.
И это очень плохо. В результате получается документация, которая «как бы есть».
С какого перепугу «как бы есть»? Если разработчик ленивый и не документировал как следует код — это его проблемы и проблемы его квалификации. Если уж смог написать прототип метода, потрать еще 2-3 минуты и напиши к нему коментарий, из которого сгенерируется документация. Эти коменарии и есть по сути написание документации.
Плохой разработчик и код напишет, который «как бы есть».
Вот вам пару примеров «как бы есть», AFNetworking, Facebook iOS SDK. Да вооще любая зрелая и уважающая себя open source библиотека для iOS подробно документирует в коде все свои API, чего уже говорить про код самой Apple.
И понятие «читаемости» у вас какое-то специфическое, даже «забитая строка» ее ухудшает…
Обьясняю
/**
* Абстрактный класс экшена.
*
* От этого класса наследуются все экшены в движке.
* Предоставляет базовые метода для работы с параметрами и шаблоном при запросе страницы в браузере.
*
* @package engine
* since 1.0
*/
abstract class Action extends LsObject {
/**
* Список зарегистрированных евентов
*
* var array
*/
protected $aRegisterEvent=array();
/**
* Список параметров из URL
* /action/event/param0/param1/../paramN/
*
* var array
*/
protected $aParams=array();
/**
* Список совпадений по регулярному выражению для евента
*
* var array
*/
protected $aParamsEventMatch=array('event'=>array(),'params'=>array());
/**
* Объект ядра
*
* var Engine|null
*/
protected $oEngine=null;
/**
* Шаблон экшена
* see SetTemplate
* see SetTemplateAction
*
* var string|null
*/
protected $sActionTemplate=null;
/**
* Дефолтный евент
* see SetDefaultEvent
*
* var string|null
*/
protected $sDefaultEvent=null;
/**
* Текущий евент
*
* var string|null
*/
protected $sCurrentEvent=null;
/**
* Имя текущий евента
* Позволяет именовать экшены на основе регулярных выражений
*
* var string|null
*/
protected $sCurrentEventName=null;
/**
* Текущий экшен
*
* var null|string
*/
protected $sCurrentAction=null;
/**
* Конструктор
*
* param Engine $oEngine Объект ядра
* param string $sAction Название экшена
*/
/**
* Абстрактный класс экшена.
*
* От этого класса наследуются все экшены в движке.
* Предоставляет базовые метода для работы с параметрами и шаблоном при запросе страницы в браузере.
*
* @package engine
* since 1.0
*/
abstract class Action extends LsObject {
/**
* Список зарегистрированных евентов
*
* var array
*/
protected $aRegisterEvent=array();
/**
* Список параметров из URL
* /action/event/param0/param1/../paramN/
*
* var array
*/
protected $aParams=array();
/**
* Список совпадений по регулярному выражению для евента
*
* var array
*/
protected $aParamsEventMatch=array('event'=>array(),'params'=>array());
/**
* Объект ядра
*
* var Engine|null
*/
protected $oEngine=null;
/**
* Шаблон экшена
* see SetTemplate
* see SetTemplateAction
*
* var string|null
*/
protected $sActionTemplate=null;
/**
* Дефолтный евент
* see SetDefaultEvent
*
* var string|null
*/
protected $sDefaultEvent=null;
/**
* Текущий евент
*
* var string|null
*/
protected $sCurrentEvent=null;
/**
* Имя текущий евента
* Позволяет именовать экшены на основе регулярных выражений
*
* var string|null
*/
protected $sCurrentEventName=null;
/**
* Текущий экшен
*
* var null|string
*/
protected $sCurrentAction=null;
/**
* Конструктор
*
* param Engine $oEngine Объект ядра
* param string $sAction Название экшена
*/
Ну это явно написано под автокомплит любимой IDE разработчика или под генерирование документации, как я и говорил.
Используйте IDE вроде PHPStorm и вы по-другому будете смотреть на такие комментарии(аннотации).
Используйте IDE вроде PHPStorm и вы по-другому будете смотреть на такие комментарии(аннотации).
Поддерживаю. Раз. Два.
Это стандартная практика, это — признак хорошего кода. Ничего плохого в этом нет.
Любая современная IDE скажет только спасибо за такие коментарии и с радостью отобразит их в удобочиатемом виде (хотя что неудобного в обычном виде...) в окне документации.
Любой более-менее продвинутый текстовый редактор (sublime text 2, например), имеет кучу средств навигации по коду «в обход» этих коментариев.
Могу только придумать одну ситуацию, когда это тяжело читать — в текстовом редакторе типа Notepad'а, без какой-либо подсветки синтаксиса, и когда код, по какой-то необъяснимой причине, нужно читать от корки до корки, как страницы в книге, как роман. Тогда да, ваши аргументы уместны.
Это стандартная практика, это — признак хорошего кода. Ничего плохого в этом нет.
Любая современная IDE скажет только спасибо за такие коментарии и с радостью отобразит их в удобочиатемом виде (хотя что неудобного в обычном виде...) в окне документации.
Любой более-менее продвинутый текстовый редактор (sublime text 2, например), имеет кучу средств навигации по коду «в обход» этих коментариев.
Могу только придумать одну ситуацию, когда это тяжело читать — в текстовом редакторе типа Notepad'а, без какой-либо подсветки синтаксиса, и когда код, по какой-то необъяснимой причине, нужно читать от корки до корки, как страницы в книге, как роман. Тогда да, ваши аргументы уместны.
Так еще и в результате вот такая красота получается: cocoadocs.org/docsets/AFNetworking/1.2.1/
НЛО прилетело и опубликовало эту надпись здесь
Эти библиотеки (AFNetworking, FB SDK) скорее комментируют свой API чтобы собрать из этого appledoc'и.
Свернуть комментарии — идея хорошая — но это доп действия ручками.Зачастую в IDE есть и автоматическое сворачивание регионов определённого типа.
Полностью согласен, лучше уделить время понятному коду.
Но например неплохо комментировать различного рода формулы, не создавать же класс на каждую формулу.
Так же насчет doc комментирования, его очень хорошо использовать в классах, которые по определению реюзабельны, эти комментарии подхватывают многие IDE и выдают понятный пользователю автокомплит.
Но например неплохо комментировать различного рода формулы, не создавать же класс на каждую формулу.
Так же насчет doc комментирования, его очень хорошо использовать в классах, которые по определению реюзабельны, эти комментарии подхватывают многие IDE и выдают понятный пользователю автокомплит.
Создавайте отдельную функцию на каждую неявную формулу/регулярное выражение. Это значительно улучшит понимание кода.
Согласитесь, checkMail($mail) читается гараздо лучше, чем
preg_match('/^([0-9a-zA-Z]([-.w]*[0-9a-zA-Z])*@([0-9a-zA-Z][-w]*[0-9a-zA-Z].)+[a-zA-Z]{2,9})$/si', $subject, $regs)
Согласитесь, checkMail($mail) читается гараздо лучше, чем
preg_match('/^([0-9a-zA-Z]([-.w]*[0-9a-zA-Z])*@([0-9a-zA-Z][-w]*[0-9a-zA-Z].)+[a-zA-Z]{2,9})$/si', $subject, $regs)
Ну тут можно функцию то не городить. А сохранить сам регехп в переменную с именем checkMailRegExp и уже его проверить. А вообще регехп бы статической константой вынести глобально. Чтоб в проекте не было 10 разных валидаций. Я больше люблю разруливать такие вещи говорящими переменными нежели функциями. Если нужна будет какая то более сложная обработка то уже функция отдельная, опять же лучше в каком то паке утилов завести что консистентность проверок поддержать.
Можно и так — суть в том что можно обойтись без комментария.
Единственная проблема в вашем решении в том, что если регекспа станет не хватать, то прийдётся во всём коде переделывать на функцию.
Единственная проблема в вашем решении в том, что если регекспа станет не хватать, то прийдётся во всём коде переделывать на функцию.
Да, и не так уж это и сложно. Я пришёл к выводу что бритва Оккама работает очень хорошо. Делать надо минимум. Если вы точно знаете что такая более сложная чем регехп обработка будет, то можно сразу функцию заводить. В противном случае нет. Не так уж и долго найти все ссылки на константу и во всех местах на функцию заменить, совсем не сложно. Зато не будет ненужных уровней абстракции. За последние пару лет разработки я понял что всего на перёд всё равно не предусмотришь, а в 10-15 местах заменить одно на другое не проблема, особенно когда ide рефакторинг хорошо поддерживает.
Это проблему решает лишь отчасти. Тут, имхо, нужен комментарий, указывающий как проверяется адрес почты и почему именно так. И если «как» кому-то может показаться избыточным (типа, ты что не впитал навык чтения PCRE с молоком матери?), то «почему так» тут явно напрашивается.
Вообще придерживаюсь принципа: комментируй как это сделано, а не что с.делано.
Ещё недавно видел вот такую штуку и мне прям понравилось:
Сразу понятно что и как.
Иногда вместо обновления приватной переменной изнутри класса дёргаю внешний сеттер, тогда тоже пишу коммент что сеттер дёрнут намеренно. Или геттер с ленивой инициализацией. Этидва случая конечно попахивают, но иногда для простоты и балланса между горой ненужного кода и простотой применяю.
Т.е. если код может быть прочтён двояко, и может быть заподозрена ошибка то пишем коммент.
А вообще с постом согласен, тупы хоменнтариев дублирующих написанное быть не должно.
Ещё недавно видел вот такую штуку и мне прям понравилось:
if (equation > 0) {
doSmth();
} else if (equation < 0) {
doSmthElse();
} else {
// комментарий о том что случай с равенством нулю не забыт,
// обработка не требуется.
}Сразу понятно что и как.
//fallthrough всегда пишу когда применяю.Иногда вместо обновления приватной переменной изнутри класса дёргаю внешний сеттер, тогда тоже пишу коммент что сеттер дёрнут намеренно. Или геттер с ленивой инициализацией. Этидва случая конечно попахивают, но иногда для простоты и балланса между горой ненужного кода и простотой применяю.
Т.е. если код может быть прочтён двояко, и может быть заподозрена ошибка то пишем коммент.
А вообще с постом согласен, тупы хоменнтариев дублирующих написанное быть не должно.
Подождите, вы пишите код, которым описываете, как вы это сделали. А потом описываете в комментарии как это сделали?
Серьезно, имя функции, переменных, класса, анотации — неужто этого не достаточно? Нет, было время, мне нравилось писать хитросделанные фунции и формулы, которые не с первого получаса поймёшь — но блин, мы же продукт делаем, а не заковыристостью кода хвастаемся!
Серьезно, имя функции, переменных, класса, анотации — неужто этого не достаточно? Нет, было время, мне нравилось писать хитросделанные фунции и формулы, которые не с первого получаса поймёшь — но блин, мы же продукт делаем, а не заковыристостью кода хвастаемся!
Подождите, вы пишите код, которым описываете, как вы это сделали
не понял мысли.
Я пишу коммент если можно допустить небольшую некрасивость, но с одним комментом понятную, нежели городить новый уровень абстракции.
Блин, тег code херню какую то делает. source надо использовать
if (equation > 0) {
doSmth();
} else if (equation < 0) {
doSmthElse();
} else {
// комментарий о том что случай с равенством нулю не забыт,
// обработка не требуется.
}>>Вообще придерживаюсь принципа: комментируй как это сделано, а не что с.делано.
На самом деле, если бы вы в примере не оставили бы комментарий — на читабельность это не повлияло бы. Вы ведь не в пустоту код пишите — тесты пробегают, пользователи не нервничают — значит всё ок.
К тому же очень часто такой комент должен звучать как
//Тут надо вроде ещё проверку сделать, но этот случай маловероятен, PM сказал забить.
На самом деле, если бы вы в примере не оставили бы комментарий — на читабельность это не повлияло бы. Вы ведь не в пустоту код пишите — тесты пробегают, пользователи не нервничают — значит всё ок.
К тому же очень часто такой комент должен звучать как
//Тут надо вроде ещё проверку сделать, но этот случай маловероятен, PM сказал забить.
//Тут надо вроде ещё проверку сделать, но этот случай маловероятен, PM сказал забить.
Вот такой зло как раз. У нас, слава всем богам, есть время разработчиков когда они выполняют поддержание кода и инструментов в порядке, и не отчитываются за это время ни перед кем. В такое время это и делается. А мой вариант показывает что не забыли это обработать. Он не маловероятен, он вполне вероятен, только действие не требуется. И не сразу это очевидно. Когда придумывал, думал что понадобится действие. Написал последний елс. Потом попробовал внести в один из ифов также равенство, тоже не круто. Вот и выделил отдельно. И всегда понятно будет почему так, и при чтении руки ни у кого не зачешутся поправить.
Вот такой зло как раз. У нас, слава всем богам, есть время разработчиков когда они выполняют поддержание кода и инструментов в порядке, и не отчитываются за это время ни перед кем. В такое время это и делается. А мой вариант показывает что не забыли это обработать. Он не маловероятен, он вполне вероятен, только действие не требуется. И не сразу это очевидно. Когда придумывал, думал что понадобится действие. Написал последний елс. Потом попробовал внести в один из ифов также равенство, тоже не круто. Вот и выделил отдельно. И всегда понятно будет почему так, и при чтении руки ни у кого не зачешутся поправить.
Ок, давайте рассмотрим
b = $('.someDiv');
if (b.html() == "")
b.html(«Привет»);
*тут код продолжается*
— Ваш вариант:
b = $('.someDiv');
if (b.html() == "")
b.html(«Привет»);
else {
/*тут ничего делать не надо, просто так конструкцию написал*/
}
*тут код продолжается*
Может быть лучше просто не писать конструкции, если их не нужно использовать?
Если же код неочевиден — то очевидно нужно его изменить.
b = $('.someDiv');
if (b.html() == "")
b.html(«Привет»);
*тут код продолжается*
— Ваш вариант:
b = $('.someDiv');
if (b.html() == "")
b.html(«Привет»);
else {
/*тут ничего делать не надо, просто так конструкцию написал*/
}
*тут код продолжается*
Может быть лучше просто не писать конструкции, если их не нужно использовать?
Если же код неочевиден — то очевидно нужно его изменить.
Да пишите, кто же против то. Вам же код поддерживать. Я говорил о случае когда мы по некому условию разбиваем всё доступное пространство входных данный на некоторые большие области и их специфично обрабатываем. Классической ошибкой в таких штуках является потерять границы. И часто при дебаге и чтении кода на таких местах заостряется внимание. Тут просто сразу дана подсказка что это не ошибочно забыто а сознательно не обработано. Мне это помогает. И, если вы не заметили, не рекомендую всегда так писать. Но в некоторых местах такая штука бывает полезна. Мы код пишем чтоб писать его и поддерживать.
>>Мы код пишем чтоб писать его и поддерживать.
А мы — чтоб он работал :)
Если без шуток — каждый комментарий — это напоминание о том, что код попахивает (например — каждая область if содержит по сотне строк). И тут есть два пути:
1) оставить комментарий
2) исправить код
Естественно это всё не про анотации.
А мы — чтоб он работал :)
Если без шуток — каждый комментарий — это напоминание о том, что код попахивает (например — каждая область if содержит по сотне строк). И тут есть два пути:
1) оставить комментарий
2) исправить код
Естественно это всё не про анотации.
Вовсе не каждый. Как минимум комментарии нужны, чтобы объяснять почему выбран конкретный вариант в рамках предметной области. Скажем «используем ньютоновскую механику, релятивистскими эффектами можно пренебречь — это эмулятор морского корабля, а не космического :)» или «проверяем валидность мыла „интуитивно“, извращенцы, знающие RFC наизусть — не наша ЦА»
Вам не кажется, что в код стоит лезть с некой определённой целью? Скажем — определить откуда растут ноги у ошибки, провести рефакторинг и так далее. Т.е., грубо говоря «какую формулы мы выбрали» — должна рассказывать спецификация к проекту (юзер стори, сценарии поведения пользователя и так далее). А код — должен просто это реализовывать. Так зачем спецификацию запихивать в код?
Ошибка может быть из-за того, что релятивистские эффекты не учитываем или учитываем их криво. Вот чтобы разобраться в «или» нужна документация к коду.
И далеко не все проекты достаются с отдельной документацией, даже если она когда-то была. Зачем плодить сущности сверх необходимого, если можно документировать код прямо в коде комментариями?
И далеко не все проекты достаются с отдельной документацией, даже если она когда-то была. Зачем плодить сущности сверх необходимого, если можно документировать код прямо в коде комментариями?
Потому что это:
1) Экранирует принципы реализации от не-программистов (например от физиков и математиков, маркетологов и так далее)
2) Мешает разбераться в коде (честно — я ту формулу не с первого раза пойму, даже если будет приписано что это за формула. Так что просто так копаться точно не буду)
3) комментарий не изменяется вместе с кодом. Точнее должен — но часто о нём забывают. В результате Вы офигиваете от того, что релятивистские эффекты не учитываются на скоростях близких к С, потом офигиваете от того, что они таки учитываются (вопреки комментарию).
1) Экранирует принципы реализации от не-программистов (например от физиков и математиков, маркетологов и так далее)
2) Мешает разбераться в коде (честно — я ту формулу не с первого раза пойму, даже если будет приписано что это за формула. Так что просто так копаться точно не буду)
3) комментарий не изменяется вместе с кодом. Точнее должен — но часто о нём забывают. В результате Вы офигиваете от того, что релятивистские эффекты не учитываются на скоростях близких к С, потом офигиваете от того, что они таки учитываются (вопреки комментарию).
Жесть какая-то. Тогда надо к каждому IF писать ELSE с комментарием «не, я не забыл про этот случай — просто ничего не надо делать». Ну чтобы уже наверняка! А то мало ли кто заподозрит…
Кому-то жесть, а кому-то… Согласен, что нужна «золотая середина».
Лично я не вижу ничего плохого прописать явно какую-то пустую или тупиковую ветку алгоритма с комментарием "//do nothing", чтобы потом вспомнить, что там действительно «nothing to do». Естественно, делать так повсеместно не призываю:)
Одно время я параноил и расставлял return без параметров в функциях, которые не должны ничего возвращать. Тем самым я подчеркивал, что функция действительно дописана, а я не просто отвлекся от кода и забыл дописать:). Сейчас от этого отошел, но это и есть — поиск «золотой середины»:)
Лично я не вижу ничего плохого прописать явно какую-то пустую или тупиковую ветку алгоритма с комментарием "//do nothing", чтобы потом вспомнить, что там действительно «nothing to do». Естественно, делать так повсеместно не призываю:)
Одно время я параноил и расставлял return без параметров в функциях, которые не должны ничего возвращать. Тем самым я подчеркивал, что функция действительно дописана, а я не просто отвлекся от кода и забыл дописать:). Сейчас от этого отошел, но это и есть — поиск «золотой середины»:)
В упор не понимаю зачем сама ветка ELSE существует. Самый нормальный способ — добавить юнит тест наподобие ifEquationIsZeroDoNothingBecause… Но если так и прет дописать комментарий, то можно сделать его перед первым IF. Сама ветка ELSE вообще ни к селу ни к городу. По поводу вашего return без параметров — вы просто набрались опыта и поняли, что это бесполезная практика. А другие разработчики, которые с вами работали, одобряли эту практику?
Я не понимаю, почему тесты так упорно противопоставляются комментариям в коде. Одно другому не мешает!
Что касается «избыточной ветки ELSE».
Case1. Программист дочитал до этого ELSE и подумал (как Вы, например) «нафига здесь эта пустую ничего не означающая ветка?» — это мысль на доли секунды, такой риторический вопрос, ответ на который дан в комментарии; код читается дальше с мимолетным ощущением собственной крутости «а я и так все понял бы, без этой тупиковой ветки!»:)
Case2. Программист в поисках ошибки добирается до IF и не видит обработки ветки ELSE. Задумывается, начинает смотреть, а что означает эта другая отсутствующая ветка с точки зрения входных данных, даже находит заботливо подготовленный старшим товарищем unit-тест, запустив который, убеждается, что зря параноил. 5 минут тоже не так много в масштабе вселенной, но… против долей секунды в Case1 — неприлично много.
Имхо,
тесты отвечают на вопрос «оно все еще работает?», а комментарии отвечают на вопрос «почему оно работает?».
Это лишь мое скромное мнение, сформированное за 20 лет программирования:)
Что касается «избыточной ветки ELSE».
Case1. Программист дочитал до этого ELSE и подумал (как Вы, например) «нафига здесь эта пустую ничего не означающая ветка?» — это мысль на доли секунды, такой риторический вопрос, ответ на который дан в комментарии; код читается дальше с мимолетным ощущением собственной крутости «а я и так все понял бы, без этой тупиковой ветки!»:)
Case2. Программист в поисках ошибки добирается до IF и не видит обработки ветки ELSE. Задумывается, начинает смотреть, а что означает эта другая отсутствующая ветка с точки зрения входных данных, даже находит заботливо подготовленный старшим товарищем unit-тест, запустив который, убеждается, что зря параноил. 5 минут тоже не так много в масштабе вселенной, но… против долей секунды в Case1 — неприлично много.
Имхо,
тесты отвечают на вопрос «оно все еще работает?», а комментарии отвечают на вопрос «почему оно работает?».
Это лишь мое скромное мнение, сформированное за 20 лет программирования:)
Вы так увлеклись выдумыванием странных кейсов, что забыли про мой основной вопрос: «Зачем ветка ELSE, если комментарий можно поставить перед первым или последним IF?».
Почему оно работает вам должны говорить имена классов, переменных, методов и комментарии в том случае, когда вы не в силах выразить сложность задумки простым и понятным кодом.
Почему оно работает вам должны говорить имена классов, переменных, методов и комментарии в том случае, когда вы не в силах выразить сложность задумки простым и понятным кодом.
Николай,
я не призываю в каждом случае фанатично ставить пустые ветки ELSE:)
На самом деле, наличие такой ветки больше вписываются в Ваше мировоззрение — все-таки «else {}» — это код, который «говорит сам за себя»;)
Я говорю лишь то, что не вижу ничего зазорного в том, чтобы использовать такую конструкцию, если по смыслу окружения могут закрасться сомнения — вот и все!
p.s. Я реально не вижу смысла в продолжении этой ветки дискуссии, чтобы не превращать обсуждение в балаган, что настойчиво пытаются сделать два товарища далее по тексту:). Предмета для спора просто нет:)
я не призываю в каждом случае фанатично ставить пустые ветки ELSE:)
На самом деле, наличие такой ветки больше вписываются в Ваше мировоззрение — все-таки «else {}» — это код, который «говорит сам за себя»;)
Я говорю лишь то, что не вижу ничего зазорного в том, чтобы использовать такую конструкцию, если по смыслу окружения могут закрасться сомнения — вот и все!
p.s. Я реально не вижу смысла в продолжении этой ветки дискуссии, чтобы не превращать обсуждение в балаган, что настойчиво пытаются сделать два товарища далее по тексту:). Предмета для спора просто нет:)
На самом деле действительно вставка ветки else выглядит несколько сомнительным приемом. Его хотя бы нужно было тоже закомментировать с фразой типа «вдруг когда нибудь придется обрабатывать и ноль». Информативность в плане того, что обработка ноля не баг, а фича не уменьшается, но эффективность кода может понизиться в некоторых трансляторах.
Не так. В коде из примера любой новый программист вначале будет считать, что он обнаружил ошибку («да тут же не обрабатывается случай, когда equation == 0 !»). Именно для этого и написан комментарий.
А во, ещё практика. Иногда я в коде закладки делаю своеобразные, // guid
И в отдельном файле что помечено какими гуидами. Удобно задумать например какой то рефакторинг, держать его в голове пару недель и расставлять в коде такие метки с местами которым стоит уделить внимание. Потом банальным поиском по проекту элементарно находится. Гуит у меня в ide одним хоткеем ставится.
Пришёл к выводу что это лучше чем всякие системы закладок на код. Потому что команда у нас работает с разными ide + элементарн работать с такими метками даже в блокноте, никогда не рассинхронизируются. В общем счастье одно.
И в отдельном файле что помечено какими гуидами. Удобно задумать например какой то рефакторинг, держать его в голове пару недель и расставлять в коде такие метки с местами которым стоит уделить внимание. Потом банальным поиском по проекту элементарно находится. Гуит у меня в ide одним хоткеем ставится.
Пришёл к выводу что это лучше чем всякие системы закладок на код. Потому что команда у нас работает с разными ide + элементарн работать с такими метками даже в блокноте, никогда не рассинхронизируются. В общем счастье одно.
На мой взгляд, комментарии как намерения обязательно должны присутствовать, в коде или в документации. Если их нет, то ошибочный код будет неотличим. Затем, идею прочитать легче в тексте, чем разбирать в не очень приспособленном для этого языке. Пример идеи: поставить перед текстом "#", если это hex-строка и реализация; что прочитать легче?
var color = $("#color").val().toUpperCase(), cL = color.length;
for(var i in cL)
if(cL[i] < '0' && cL[i] > 'F') //найден не hex-символ
break;
document.body.style.backgroundColor = (color.charAt[0] !='#' && i < cL ?'':'#') + color;
Имхо в идеале- вынести в отдельный метод с соответствующим названием. А уже этот метод нормально прокомментировать.
Но суть в том что комментарии придётся читать только если нужно выяснить как он там работает, а не просто в момент когда встречаешь его вызов.
Т.е. что-то типа «PrepareColorValue»(название можно придумать и получше чем у меня), а что там внутри нужно будет смотреть только когда надо действительно разобраться что там такое
Но суть в том что комментарии придётся читать только если нужно выяснить как он там работает, а не просто в момент когда встречаешь его вызов.
Т.е. что-то типа «PrepareColorValue»(название можно придумать и получше чем у меня), а что там внутри нужно будет смотреть только когда надо действительно разобраться что там такое
Вот видите, какую вы ужастную реализацию сделали, что её и понять то с первого раза сложно.
Вынесите код в функции, избавтесь от неочевидных конструкций типа color.charAt[0] !='#' && i < cL ?'':'#' и комментарии станут не нужны.
Самая большая проблема коментов в том, что после изменения кода — комментарии автоматически не меняются
Вынесите код в функции, избавтесь от неочевидных конструкций типа color.charAt[0] !='#' && i < cL ?'':'#' и комментарии станут не нужны.
Самая большая проблема коментов в том, что после изменения кода — комментарии автоматически не меняются
if(cL[i] < '0' && cL[i] > 'F') //найден не hex-символКакой смешной код. Между '0' и 'F' ещё много чего находится.
Это и есть иллюстрация того, что идея описывается цельнее, чем код, который имеет допуски, которые в данном случае работают — нужно лишь отличать hex-коды от слов, в которых не встречается ни тех 7 знаков, ни многих других (если подробнее, то наличие ошибочного знака с тем же успехом не даст результата, что и отсутствие "#").
Правильное решение — вынести проверку в отдельный метод: скажем,
Код сам себя успешно комментирует, и это допустимо почти в любой ситуации. Ну все примеры, которые народ приводил, все поголовно используют комментарии там, где можно использовать инкапсуляцию.
Согласен, что иногда комментариев не избежать, но уж, имхо, точно не в случае с пустым ELSE. Тудухи — в тудухи, если вы на своих проектах забиваете на тудухи, то это проблема не тудух, а ваших проектов.
CharIsHexSymbol(c) {
return c > '0' && c < 'F';
}
Код сам себя успешно комментирует, и это допустимо почти в любой ситуации. Ну все примеры, которые народ приводил, все поголовно используют комментарии там, где можно использовать инкапсуляцию.
Согласен, что иногда комментариев не избежать, но уж, имхо, точно не в случае с пустым ELSE. Тудухи — в тудухи, если вы на своих проектах забиваете на тудухи, то это проблема не тудух, а ваших проектов.
Хоть и плюсанул ваш коммент, но, имхо, тут всё же необходим комментарий, объясняющий почему столь странная (по крайней мере для ASCII-based кодировок) проверка выбрана. Зачастую комментарии служат лишь средством записи контракта (это понятие несколько шире чем сигнатура обычно). В данном случае либо в комментарии а-ля *doc напрашивается описание для функции типа «Argument MUST not to match to PCRE /[:-@]/» или «надеюсь, не найдется идиота, который в поле для ввода шестнадцатиричного числа будет набирать некоторые знаки препинания и прочей типографики» (типичный случай, почему у меня в коде присутсвуют комментарии на двух языках :( )для самой проверки. Во втором случае функцию можно было бы называть CharIsNeralytHexDigit, но опять же для понимания того, что значит «nearly» нужно будет в код заглядывать, а название CharIsBetween0AndF выглядит совсем тупо — типичный случай, когда код лучше инкапсуляции.
Или ещё пример, когда комментарии крайне желательны: Реализуем функцию сортировки. С точки зрения вызывающего кода всё равно как мы её реализуем, потому именуем её тупо sort(array) — что делает функция определено. Решаем реализовать её пузырьковым методом — как нам донести это для читателей кода без комментариев? Переименовать именно в «пузырьковую сортировку»? Так могут возникнуть мысли, что в использовании именно её есть некий сакральный смысл, что мы ограничены, скажем, в памяти, а не в процессоре. Оставить всё как есть? Так можем допустить ошибку в реализации и читающему код не будет понятно баг это или фича, а то он просто не опознает в ней именно пузырьковую.
Или ещё пример, когда комментарии крайне желательны: Реализуем функцию сортировки. С точки зрения вызывающего кода всё равно как мы её реализуем, потому именуем её тупо sort(array) — что делает функция определено. Решаем реализовать её пузырьковым методом — как нам донести это для читателей кода без комментариев? Переименовать именно в «пузырьковую сортировку»? Так могут возникнуть мысли, что в использовании именно её есть некий сакральный смысл, что мы ограничены, скажем, в памяти, а не в процессоре. Оставить всё как есть? Так можем допустить ошибку в реализации и читающему код не будет понятно баг это или фича, а то он просто не опознает в ней именно пузырьковую.
Вы абсолютно правы, собственно, именно это и имел в виду Макконнелл, говоря про комментирование намерений. Но в данном топике народ старательно путает намерения и реализацию.
Что касается сортировки… Мне лично кажется, что если в ситуации допустимо использование нескольких сортировок, лучше воспользоваться каким-то паттерном, наподобие композита. Читающему код будет понятно, что в каждом конкретном вызове композитного сортировщика выполняется какая-то сортировка, а какая именно — будет отлично видно в названии класса-сортировщика.
В случае если мы вдруг при живом квиксорте решили воспользоваться пузырьком, конечно, комментарий следует написать, но именно как описание некоего магического знания: «Здесь мы проседаем по памяти». Потому как в противном случае (вместо названия писать суть в комментарии) придется писать комментарий на каждый вызов этой сортировки.
Что касается сортировки… Мне лично кажется, что если в ситуации допустимо использование нескольких сортировок, лучше воспользоваться каким-то паттерном, наподобие композита. Читающему код будет понятно, что в каждом конкретном вызове композитного сортировщика выполняется какая-то сортировка, а какая именно — будет отлично видно в названии класса-сортировщика.
В случае если мы вдруг при живом квиксорте решили воспользоваться пузырьком, конечно, комментарий следует написать, но именно как описание некоего магического знания: «Здесь мы проседаем по памяти». Потому как в противном случае (вместо названия писать суть в комментарии) придется писать комментарий на каждый вызов этой сортировки.
Канонический ответ: зависит от кода и области применения. Вот сейчас как раз читаю код коллеги — реализация некого анализа на основе normalized cross-correlation на CUDA. Даже с учетом того, что я знаю идею и формулы, сложно было бы уследить за извивами мысли без комментариев.
Если работаете с каким-либо мат.аппаратом, то лучше перебдеть.
Если работаете с каким-либо мат.аппаратом, то лучше перебдеть.
Проблема черезмерного комментирования и написания все-в-одном методов очень свойственна, почему то, именно Инженерам, т.е. тем кто больше работает с мат. аппаратом а не реализацией. И часто такой код трудно поддерживать без рефакторинга, даже если он и неплохо документирован.
Ну декомпозицией кода в таких решениях, можно и навредить, я уже представляю класс из 300 методов или 300 классов по одному методу, как больше нравится.
Ну, как говорится, сделай все максимально просто но не проще чем это возможно. Само собой я не говорю о тех вариантах где это навредит.
А мне когда то пришлось работать с функцией на 2500 строк. Поверте, лучше 300 отдельных методов.
Человек привык работать с абстрациями. Мы говорим — «дойди до остановки и сядь на автобус до стадиона» — не уточняя, как именно идти (скорость, длина шага), какой остановки(обычно это понятно в контексте) и что это вообще такое, и как выглядит стадион.
Человек привык работать с абстрациями. Мы говорим — «дойди до остановки и сядь на автобус до стадиона» — не уточняя, как именно идти (скорость, длина шага), какой остановки(обычно это понятно в контексте) и что это вообще такое, и как выглядит стадион.
Ну просто получается такая ситуация: выносить, скажем так, «одноразовый» код в отдельные методы так же не лучшая практика.
Нужно грамотно выдержать баланс между декомпозицией, реюзабельными методами и комментариями, но это уже дело немалого опыта.
Нужно грамотно выдержать баланс между декомпозицией, реюзабельными методами и комментариями, но это уже дело немалого опыта.
Если код одноразовый, то грамотный компилятор соберет все «одноразовые» методы в одну функцию. Даже без явного inline.
выносить, скажем так, «одноразовый» код в отдельные методы так же не лучшая практика.
Вы зря считаете что код выносится в методы только для уменьшения
Особенно полезны комментарии к математике в шейдерах или граф\физ движках: там ради оптимизации в пару тактов может так формула измениться, что саппортер глаза сломает, пока поймет по коду. Один только dot(a,a) вместо pow(length(a),2) чего стоит, и это далеко не сложный пример.
Аналогичная ситуация по коду на assember-е и некоторым скриптам на bash-e. Такой недокументированный код мы между собой называем write-only:)
Хмм, иногда целые языки программирования называют write-only… ;)
Но если вы сами работаете с ассемблером — то не проще ли научиться такой код читать? Хотя комментарии вроде «здесь мы используем флаг Carry, полученный 6 команд назад» вполне могут пригодиться: слишком большой риск, что при редактировании кто-нибудь его испортит.
Да что уж тут! Давайте запишем в корпоративных стандартах, что в команде программистов должны быть только гении, да чтоб еще и мысли друг друга могли читать через время и расстояние. И действительно, о чем мы тут спорим?:)
С комментариями, опять же по моей практике и по моему скромному мнению, значительно больше шансов, что никто ничего не испортит:)
С комментариями, опять же по моей практике и по моему скромному мнению, значительно больше шансов, что никто ничего не испортит:)
Недавно на Хабре был опрос. 16% сказали, что они могут быстро разобраться в любом чужом коде. Может быть, существование write-only языков, всё-таки, несколько преувеличено?
А чтобы с комментариями никто ничего не испортил, тут уж точно надо уметь читать мысли — причём из будущего. Чтобы понять, что придёт в голову будущему редактору, что для него будет очевидным, а что — тоже очевидным, но при этом неправильным?
Разве что комментарий типа «у этого блока вход такой-то, выход такой-то, меняет то-то, делает то-то, других побочных эффектов не имеет. Write-only, хотите изменить поведение — переписывайте заново». Если программа разбита на подобные блоки, то шансы, что её не испортят, слегка повышаются.
А чтобы с комментариями никто ничего не испортил, тут уж точно надо уметь читать мысли — причём из будущего. Чтобы понять, что придёт в голову будущему редактору, что для него будет очевидным, а что — тоже очевидным, но при этом неправильным?
Разве что комментарий типа «у этого блока вход такой-то, выход такой-то, меняет то-то, делает то-то, других побочных эффектов не имеет. Write-only, хотите изменить поведение — переписывайте заново». Если программа разбита на подобные блоки, то шансы, что её не испортят, слегка повышаются.
А чтобы с комментариями никто ничего не испортил, тут уж точно надо уметь читать мысли — причём из будущего. Чтобы понять, что придёт в голову будущему редактору, что для него будет очевидным, а что — тоже очевидным, но при этом неправильным?
Решается путем чтения своих мыслей при написании кода :)
Так мысли-то говорят, что вновь пришедшие программисты будут умнее нас — так что то, что очевидно мне, будет тем более очевидно и им. Зачем тогда комментарии?
Умнее-то они может и будут, но вот контекст совпадать совсем необязательно будет. Наверное, основная задача комментариев — это именно передача контекста. Что мы придумали видно и так в коде, но вот почему мы придумали именно так и что имели в виду на самом деле (чтобы читатель кода точно знал «это не баг, это фича») нужно документировать.
Тогда 80% комментариев к проекту должны жить вне кода, в большом документе сопровождения. Где перечисляются не классы с интерфейсами, а общие концепции и их взаимосвязи. Возможно, с указанием их отражения в архитектуре. Ведь это и есть контекст проекта. Только… кто ж его писать и поддерживать-то будет?
Вот комментарии и должны минимизировать необходимость такой документации :)
Я думаю, что наоборот :) Контекст — штука глобальная. Даже такие мелкие решения, как «захватывать/освобождать массивы каждый раз или повторно их использовать», не очень понятно, где описывать — их влияние может распространяться на несколько файлов. А в глобальном контексте местечко для описания найдётся сразу.
Извините, упустил слово «общие». А если контекст локальный? Вот выбрал я «пузырек» для сортировки — где не самое лучшее место как в самой реализации сортировки описать почему я его выбрал? Может я просто других методов не знаю, может минимизировал свои усилия, а может минимизировал потребление памяти.
За pow(length(a),2) — выгонять из проекта, пока не исправится. Выглядит оно заметно сложнее, чем dot(a,a), а выполняется в 10 раз дольше. Любой, кто работает с компьютерной геометрией, увидит и поймёт скаляный квадрат вектора, вообще не затрачивая усилий — это же идиома!
А более сложный пример можете привести? Если можно, без комментариев :)
А более сложный пример можете привести? Если можно, без комментариев :)
Никто в здравом уме и не пишет возведение в степень для квадрата, но ведь и руки не отвалятся если рядом с чем-то вроде dot(a,a) писать // length(a)^2, а лучше кончную цель вычисления или формулу.
Вот простой пример с dot:
Шейдерист по профилю с первого взгляда узнает восстановление третей компоненты tangent-space normal, но часто бывает, что код надо надо саппортить программисту более широкого профиля и простейший комментарий с формулой тут был пригодился.
А вот пример показательного шейдерного кода без комментариев (© unigine):
Вот простой пример с dot:
n.z = sqrt(saturate(1.0f - dot(n.xy,n.xy)));Шейдерист по профилю с первого взгляда узнает восстановление третей компоненты tangent-space normal, но часто бывает, что код надо надо саппортить программисту более широкого профиля и простейший комментарий с формулой тут был пригодился.
А вот пример показательного шейдерного кода без комментариев (© unigine):
float4 q2 = q0 * (2.0f / dot(q0,q0));
q0 *= scale;
float4 qq0 = q0 * q2 * 0.5f;
float3 q0x = q0.xxx * q2.yzw;
float3 q0y = q0.yyz * q2.zww;
float3 q1x = q1.xxx * q2.wzy;
float3 q1y = q1.yyy * q2.zwx;
float3 q1z = q1.zzz * q2.yxw;
float3 q1w = q1.www * q2.xyz;
float4 row_0 = float4(qq0.w + qq0.x - qq0.y - qq0.z,q0x.x - q0y.z,q0x.y + q0y.y,q1w.x + q1x.x - q1y.x + q1z.x);
float4 row_1 = float4(q0x.x + q0y.z,qq0.w + qq0.y - qq0.x - qq0.z,q0y.x - q0x.z,q1w.y + q1x.y + q1y.y - q1z.y);
float4 row_2 = float4(q0x.y - q0y.y,q0x.z + q0y.x,qq0.w + qq0.z - qq0.x - qq0.y,q1w.z - q1x.z + q1y.z + q1z.z);
Весело у вас :)
Сначала, увидев .yzw, я подумал, что речь идёт о тензорах 4^3 (потом понял, что ошибся). Потом ещё надо было догадаться, что умножение покоординатное. В итоге получилось что-то вроде возведения в квадрат матрицы поворота на малый угол со сдвигом. Хотя, наверное, у этой формулы есть более строгий физический или геометрический смысл.
Сначала, увидев .yzw, я подумал, что речь идёт о тензорах 4^3 (потом понял, что ошибся). Потом ещё надо было догадаться, что умножение покоординатное. В итоге получилось что-то вроде возведения в квадрат матрицы поворота на малый угол со сдвигом. Хотя, наверное, у этой формулы есть более строгий физический или геометрический смысл.
Конечно же я вырвал кусок кода из контекста, чтобы эффект был заметнее. =) На самом деле по имени файла, дефайнам и пр. видно, что это скиннинг с Dual Quaternions, q0 и q1 это кватернионы соседних двух костей, а row_* формируют результирующую Modelview матрицу для вертексов. Но, ей Богу, если будет подозрение на ошибку в этом месте, то головная боль обеспечена.
P.S. К чести автора кода (тов. frustum из Unigine), он отлажен и работает идеально. Но все же пример показателен.
P.S. К чести автора кода (тов. frustum из Unigine), он отлажен и работает идеально. Но все же пример показателен.
Не похоже, чтобы q0 и q1 были независимы (что такое «соседние кости», я не знаю). q1 попадает только в столбец сдвига, а q0 явно отвечает за поворот… вычисляется матрица для чего-то вроде (q0*v+q1)*Inverse(q0). В первый раз такое вижу. Когда писал сам, то использовал q0*v*Inverse(q0)+VShift. Надо будет посмотреть, в чём преимущество ввода вектора сдвига под скобку. А то вдруг кватернионы снова понадобятся (в своём проекте я отказался от них лет семь назад, в пользу матриц).
А вообще, это интересный пример. Здесь самым полезным комментарием (после глобального — «преобразуем кватернионы в матрицу») будет как раз «что сделано», а не «как сделано» — явно расписанные формулы перед вычислением row_0, row_1, row_2. Тогда читатель сможет, во-первых, убедиться, что формулы соответствуют теории (а если не соответствуют — внести нужные изменения), а во-вторых — проследить, где какой член этой формулы вычисляется, и правильно ли он достаётся.
Процитирую Макконнелла:
«Вопрос о том, стоит ли комментировать код, вполне обоснован. При плохом выполнении комментирование является пустой тратой времени и иногда причиняет вред. При грамотном применении комментирование полезно.
Основная часть критически важной информации о программе должна содержаться в исходном коде. На протяжении жизни программы актуальности исходного кода уделяется больше внимания, чем актуальности любого другого ресурса, поэтому важную информацию полезно интегрировать в код.
Хороший код сам является самой лучшей документацией. Если код настолько плох, что требует объемных комментариев, попытайтесь сначала улучшить его.
Комментарии должны сообщать о коде что-то такое, чего он не может сообщить сам — на уровне резюме или уровне цели.
Некоторые стили комментирования заставляют выполнять много нудной канцелярской работы. Используйте стиль, который было бы легко поддерживать»
«Вопрос о том, стоит ли комментировать код, вполне обоснован. При плохом выполнении комментирование является пустой тратой времени и иногда причиняет вред. При грамотном применении комментирование полезно.
Основная часть критически важной информации о программе должна содержаться в исходном коде. На протяжении жизни программы актуальности исходного кода уделяется больше внимания, чем актуальности любого другого ресурса, поэтому важную информацию полезно интегрировать в код.
Хороший код сам является самой лучшей документацией. Если код настолько плох, что требует объемных комментариев, попытайтесь сначала улучшить его.
Комментарии должны сообщать о коде что-то такое, чего он не может сообщить сам — на уровне резюме или уровне цели.
Некоторые стили комментирования заставляют выполнять много нудной канцелярской работы. Используйте стиль, который было бы легко поддерживать»
Это всё хорошо, пока вы пользуетесь чем-то вроде блокнота или vi. В нормальных IDE комментарии вроде JavaDoc помогают избежать подглядывания в код вызываемых методов, а в случае с пхп и phpDoc и вовсе единственный способ дать IDE знать, какой тип у параметров и возвращаемых значений.
www.gunsmoker.ru/2010/07/blog-post_31.html
Весьма похожая статья бородатых годов. Вы, случаем, не ею вдохновлялись?
Весьма похожая статья бородатых годов. Вы, случаем, не ею вдохновлялись?
Допустим ситуация — кусок кода или какое-то хитросплетение методов и асинхронных колбеков, и вроде даже код написан с соблюдением всех правил, но очень тяжело понять. Или вы видите какой-то кусок кода, который на первый взгляд не нужен, но есть подозрение, что тут какой-то побочный эффект. И не нужно говорить «код говно», «код говно» это очень даже реальный случай, который нужно нередко поддерживать или рефакторить, но для начала нужно понять что хотел сделать автор.
Так вот в такой ситуации, неужели не возникнет мысли «Автор, блин, мудила, не мог пару строк коментариев написать что ли! Без ста грамм не разобраться!»
Коментарии нужны, хорошие коментарии нужны, не пишите больше статей с таким заголовком :)
Ну а документация исходного кода — отдельная история.
Пример iOS документация, сделанная с помощью коментариев в .h файлах и headerdoc. Ведь именно эта документация отображается в Xcode и на сайте iOS Developer. Или аналог headerdoc'а — appledoc. Яркие примеры проектов с такой документацией — AFNetworking и Facebook iOS SDK.
Даже если вы пишите код для внутреннего проекта, рано или поздно в команду прийдут новые разработчики. Вы конечно можете сказать «иди читай код, он у нас говорящий», а можете снабдить все API подробной документацией (с помощью коментариев), как это принято в мире open source, да и не только.
Так вот в такой ситуации, неужели не возникнет мысли «Автор, блин, мудила, не мог пару строк коментариев написать что ли! Без ста грамм не разобраться!»
Коментарии нужны, хорошие коментарии нужны, не пишите больше статей с таким заголовком :)
Ну а документация исходного кода — отдельная история.
Пример iOS документация, сделанная с помощью коментариев в .h файлах и headerdoc. Ведь именно эта документация отображается в Xcode и на сайте iOS Developer. Или аналог headerdoc'а — appledoc. Яркие примеры проектов с такой документацией — AFNetworking и Facebook iOS SDK.
Даже если вы пишите код для внутреннего проекта, рано или поздно в команду прийдут новые разработчики. Вы конечно можете сказать «иди читай код, он у нас говорящий», а можете снабдить все API подробной документацией (с помощью коментариев), как это принято в мире open source, да и не только.
Код говорящий? — пусть новичок читает.
Код говорящий, новичок не умеет читать? — не умеющий читать тот язык, на котором пришел работать, не нужен проекту.
Код не говорящий? Переписываем код, потому что он говно.
Код не говорящий, но его переписать понятнее нельзя (потому как хитрая оправданная оптимизация, например) — тогда и начинаем думать о комментировании.
Выше цитата из Макконела где-то о том же.
Код говорящий, новичок не умеет читать? — не умеющий читать тот язык, на котором пришел работать, не нужен проекту.
Код не говорящий? Переписываем код, потому что он говно.
Код не говорящий, но его переписать понятнее нельзя (потому как хитрая оправданная оптимизация, например) — тогда и начинаем думать о комментировании.
Выше цитата из Макконела где-то о том же.
Автор поста, видимо, никогда не участвовал в больших проектах или не развивал один проект на протяжении длительного времени (пробовали возвращаться к своему коду через 10 лет? Не возникало вопроса «какой дурак это написал?»?)
Глубоко убежден, что комментарии необходимы. Особенно необходимы при написании интерфейсов (классов, библиотек). Огромный плюс, если комментарии стандартизированы, например, в формате doxygen.
Глубоко убежден, что комментарии необходимы. Особенно необходимы при написании интерфейсов (классов, библиотек). Огромный плюс, если комментарии стандартизированы, например, в формате doxygen.
>Не возникало вопроса «какой дурак это написал?»?)
Я думаю у любого программиста всегда возникает такой вопрос по поводу своего кода :), вне зависимости от комментариев, если у него есть профессиональный рост.
>Глубоко убежден, что комментарии необходимы. Особенно необходимы при написании интерфейсов (классов, библиотек). Огромный плюс, если комментарии стандартизированы, например, в формате doxygen.
Но, насколько я понял, в данном топике обсуждаются именно комментарии к коду, а не аннотации, которые несомненно полезны.
Лично я не могу придумать такой пример где комментарий нельзя заменить на более грамотный код. (без крайностей конечно, для исключений нужно и действовать исключительно)
Я думаю у любого программиста всегда возникает такой вопрос по поводу своего кода :), вне зависимости от комментариев, если у него есть профессиональный рост.
>Глубоко убежден, что комментарии необходимы. Особенно необходимы при написании интерфейсов (классов, библиотек). Огромный плюс, если комментарии стандартизированы, например, в формате doxygen.
Но, насколько я понял, в данном топике обсуждаются именно комментарии к коду, а не аннотации, которые несомненно полезны.
Лично я не могу придумать такой пример где комментарий нельзя заменить на более грамотный код. (без крайностей конечно, для исключений нужно и действовать исключительно)
Практически любая оптимизация, когда проектное решение отличается от того, что 99% программистам приходит в голову сразу, требует документирования. Именно в комментарии нужно ответить на вопрос потомков: а почему он сделал так через задницу, а не просто и понятно в лоб? Предвосхитите этот вопрос и не портите себе карму в будущем:))
Может быть проще и правильнее предвосхитить этот вопрос тестом? Если вы знаете о какой-то ситуации, из-за которой код написат так как написан, то воспроизведите ее в тестах. Это не даст вашим «потомкам» на скорую руку поправить «якобы баг» в вашем творении. А если вы такую ситуацию не можете воспроизвести, то может быть и не стоит так код писать. Исключительно редко на моей практике попадались такие ситуации, в основном из-за дефектов во внешнем коде. Вот тогда комментарий с линкой на проблему очень даже полезен.
Я за тесты, также как и за комментарии! Надеюсь, Вы не считаете, что одно другому мешает?:)
А если вы такую ситуацию не можете воспроизвести, то может быть и не стоит так код писать.
Тесты прежде всего фиксируют поведение, но они не объясняют почему оно такое.
Это смотря как вы пишете тесты. Многие используют структуру тестов, которая полностью описывает как раз суть сценария, объясняя ПОЧЕМУ код должен себя так вести. Но естественно не описывают КАК это сделано в коде, то есть его структуру.
Для меня поведение кода — это его входы и выходы (включая побочные эффекты). А вот, например, сложности (как по «тактам», так и по памяти) в поведение не входит — это свойства поведения, но не его суть. Именования и тесты раскрывают суть, но не раскрывают свойства. В общем случае. Бывают, конечно, исключения типа «необходимо, чтобы на конкретной программно-аппаратной платформе время исполнения не превышало N микросекунд», но мы же не об этом говорим?
Но, насколько я понял, в данном топике обсуждаются именно комментарии к коду, а не аннотации, которые несомненно полезны.
Многие восприняли этот топик как «нет коментариям вообще!», в том числе нет и аннотациям. Собственно у топика и заголовок такой.
Посмотрите пару веток выше, там как раз идет обсуждение, нужны ли аннотации (по большому счету — специализированные коментарии). Некоторые выступают даже против такого вида коментирования.
А примеры могут быть.
Допустим приходится общаться с сервером, а у его архитектуры есть какая-то необычная особенность, вот есть и все, в силу каких-то архитектурных решений она там давно поселилась и никуда деваться не собирается.
Из-за этой особенности в коде клиента, приходится делать какой-то вызов, который трудно понять, как правильно и красиво ты его не реализуй.
Простой коментарий вроде «особенности архитектуры сервера, см. вики, страница такая-то» съэкономит массу времени и нервов.
Странно, что никто ещё не вспомнил про книгу «Чистый код». Про коментарии там написано достаточно подробно.
Ок, согласен код должен быть понятным, это просто без вариантов, но по моему в данном конкретном случае листинг увеличился раза в 3, эт норм?
Посмотрел петпрожект автора на гитхабе. Быдлокодер еще тот, еще других взялся учить.
Не согласен, он высказал проблему, которая совсем не однозначна, зато очевидна. Или давайте код всех кто за и против сравнивать.
Простите, а для того, чтобы поднять проблему и подтолкнуть к её обсуждению в комментариях — обязательно иметь 150 идеальных проектов на Гитхабе? По-моему, каждый имеет право инициировать дискуссию.
Я даже не представляю, как работал бы со многими Open Source проектам, если бы авторы не комментировали свой код.
Совет автора топика, по крайней мере, выглядит довольно странным.
Совет автора топика, по крайней мере, выглядит довольно странным.
Может вы смешиваете, комментирование API и комментирование кода. Для многих open source проектов документация API (а не кода внутри) гораздо важнее самого кода, потому что это то, что они «продают» для конечного потребителя и оно должно выглядеть отлично. В принципе как и документация к сложному продукту. Вопрос же о комментариях внутри кода.
Выносить поголовно единожды используемые переменные в константы… Зачем?
Только засорять код. Они ведь нигде не используются, кроме как внутри метода. Если нужно получить доступ к быстрому их изменению, то достаточно объявить их в начале метода.
Только засорять код. Они ведь нигде не используются, кроме как внутри метода. Если нужно получить доступ к быстрому их изменению, то достаточно объявить их в начале метода.
Константы следует выносить на видное место хотя бы ради того, чтобы подчеркнуть, что какая-то цифирь оказалась захардкожена в программу! А в комментарии необходимо указать, почему выбрано именно такое значение, какие значения возможны еще и как программа будет работать при установке этих других значений. Поверьте, это существенно облегчит жизнь Вашим последователям.
Справедливо.
Однако в данном конкретном случае, разве это не очевидно?
Вот, к примеру, я работаю над Meridian. Там все константы API для VK вынесены в отдельный класс, потому что другие значения там просто неприемлемы. А тут — обычный каркас, показанный скорее для разработчика, что не желает копаться в документации.
Хотя, может я и не прав.
Однако в данном конкретном случае, разве это не очевидно?
Вот, к примеру, я работаю над Meridian. Там все константы API для VK вынесены в отдельный класс, потому что другие значения там просто неприемлемы. А тут — обычный каркас, показанный скорее для разработчика, что не желает копаться в документации.
Хотя, может я и не прав.
>> Однако в данном конкретном случае, разве это не очевидно?
Предметом обсуждения, имхо, является не данный конкретный случай, все-таки, а общий подход.
Знаете, я иногда на проводимых мной собеседованиях прошу кандидата написать несложную программу за ограниченное время. Задачи, как правило просты и их сложно не решить, но меня интересует, как человек оформит это свое простое решение, понимая, что сразу после того, как оно будет представлено, оно отправится в помойку, а еще и времени мало. Для меня очень показательно, если человек в любом случае аккуратно оформляет код, называет переменные и функции осмысленно и проч.
Также и «в данном конкретном случае». Если не задумываешься об этом на маленьких проектах, то в большие никто не пустит:)
Предметом обсуждения, имхо, является не данный конкретный случай, все-таки, а общий подход.
Знаете, я иногда на проводимых мной собеседованиях прошу кандидата написать несложную программу за ограниченное время. Задачи, как правило просты и их сложно не решить, но меня интересует, как человек оформит это свое простое решение, понимая, что сразу после того, как оно будет представлено, оно отправится в помойку, а еще и времени мало. Для меня очень показательно, если человек в любом случае аккуратно оформляет код, называет переменные и функции осмысленно и проч.
Также и «в данном конкретном случае». Если не задумываешься об этом на маленьких проектах, то в большие никто не пустит:)
Хвала Роберту Мартину и его книге «The Clean Coder: A Code of Conduct for Professional Programmers», втолковавшей мне, что комментарии должны содержать намерения кода. С тех пор, как я стал применять это простое правило, вникать в свои же собественные листинги стало куда проще.
Не подскажете, ее еще не перевели на русский?
Перевод есть: www.books.ru/books/idealnyi-programmist-kak-stat-professionalom-razrabotki-po-1549243/?show=1
Кстати, книгу прочёл после упоминания её в чьих-то комментариях на Хабре :)
Кстати, книгу прочёл после упоминания её в чьих-то комментариях на Хабре :)
На мой взгляд необходимость в комментариях серьезно зависит от языка и сути программы.
Неоткомментированная логика на ассемблере и неоткомментированный UI на С# — все-таки разные вещи.
Неоткомментированная логика на ассемблере и неоткомментированный UI на С# — все-таки разные вещи.
Старенький пост в тему: habrahabr.ru/post/97320/
НЛО прилетело и опубликовало эту надпись здесь
Почему не надо?
Перечитайте еще раз на цитату Макконела orionll
Константы, в отличие от комментариев — это код. Со всеми вытекающими. Это значит, что коду больше внимания. Это значит, что имя константы устаревает гораздо реже. Лично я вообще не помню, чтобы они устаревали, т.к. IDE прекрасно справляются по переименованию константы. Комментарии не компилируются. И не переименовываются во всех местах с помощью каких-то технических средств.
Да и самое главное — язык программирования — это в первую очередь язык. Ваша задача — выразить замысел требований на языке программирования.
Если код читается плохо, надо учиться что-то с кодом делать, чтобы он читался лучше. Код для программиста должен стать родным языком. Ни ЮМЛ, ни комментарии. С чего вдруг программисты когда-то решили, что комментарии так нужны? Похоже, что это были либо программисты, для которых язык программирования не родной, либо уже такой язык программирования, не позволяющий кратко/емко выражать мысли. Приходится мысли дублировать на естественном языке, разжевывая, что делает код, или даже цель/намерение кода.
Перечитайте еще раз на цитату Макконела orionll
Константы, в отличие от комментариев — это код. Со всеми вытекающими. Это значит, что коду больше внимания. Это значит, что имя константы устаревает гораздо реже. Лично я вообще не помню, чтобы они устаревали, т.к. IDE прекрасно справляются по переименованию константы. Комментарии не компилируются. И не переименовываются во всех местах с помощью каких-то технических средств.
Да и самое главное — язык программирования — это в первую очередь язык. Ваша задача — выразить замысел требований на языке программирования.
Если код читается плохо, надо учиться что-то с кодом делать, чтобы он читался лучше. Код для программиста должен стать родным языком. Ни ЮМЛ, ни комментарии. С чего вдруг программисты когда-то решили, что комментарии так нужны? Похоже, что это были либо программисты, для которых язык программирования не родной, либо уже такой язык программирования, не позволяющий кратко/емко выражать мысли. Приходится мысли дублировать на естественном языке, разжевывая, что делает код, или даже цель/намерение кода.
Комментарии нужны хотя бы чтобы выразить замысел требований на естественном языке. Иначе человек, читающий код, не может быть уверен, что код их реализует.
Код надо (в идеале) писать так, чтобы он выражал требования. А не реализацию. И правильно писали, что вместо комментариев эти требования прекрасно выражаются еще и тестами, если кодом не удается.
Суть поста, насколько я понял, и того, что я думаю — не в том, что надо запретить комментарии, а в том, чтобы определить куда стремиться и что хорошо, что плохо. Комментарии — это плохо. И их надо писать, когда уже не осталось других способов. Комментарии — это худший способ улучшить читаемость.
Чтобы немного сместить взгляд, представьте себе, что такое функция и что такое класс в другом русле. Тут где-то было и в комментариях к другим постам, что не имеет смысла выносить код в функцию, который используется один раз. Это механический способ рефакторинга, когда вы следуете DRY. Но можно кроме механики, ввести другой критерий. Допустим, вы написали довольно длинное полотно — код функции. Далее, хотите поставить комментарии на какие-то куски, объясняя, что они делают или как. Именно в этот момент, когда рука потянется комментировать, этот кусок и становится кандидатом для получения названия. И комментарий — по сути название новой функции. Тогда ваш код станет легко читать, как и комментированный. С той разницей, что смысл выражен в коде, а не в комментариях.
Всё это конечно спорно и требует чувства баланса. Языки программирования к сожалению не идеальны. Или я таких не знаю. Сила выражения мыслей на языке программирования зависит от языка, очевидно. Например, на Си, где нет эксепшинов, даже маленькое действие в методе превратится в много проверок и выходов. Но в С#, на котором сейчас работаю, действительно можно неплохо выразить мысль, без никаких дополнительных комментариев.
Суть поста, насколько я понял, и того, что я думаю — не в том, что надо запретить комментарии, а в том, чтобы определить куда стремиться и что хорошо, что плохо. Комментарии — это плохо. И их надо писать, когда уже не осталось других способов. Комментарии — это худший способ улучшить читаемость.
Чтобы немного сместить взгляд, представьте себе, что такое функция и что такое класс в другом русле. Тут где-то было и в комментариях к другим постам, что не имеет смысла выносить код в функцию, который используется один раз. Это механический способ рефакторинга, когда вы следуете DRY. Но можно кроме механики, ввести другой критерий. Допустим, вы написали довольно длинное полотно — код функции. Далее, хотите поставить комментарии на какие-то куски, объясняя, что они делают или как. Именно в этот момент, когда рука потянется комментировать, этот кусок и становится кандидатом для получения названия. И комментарий — по сути название новой функции. Тогда ваш код станет легко читать, как и комментированный. С той разницей, что смысл выражен в коде, а не в комментариях.
Всё это конечно спорно и требует чувства баланса. Языки программирования к сожалению не идеальны. Или я таких не знаю. Сила выражения мыслей на языке программирования зависит от языка, очевидно. Например, на Си, где нет эксепшинов, даже маленькое действие в методе превратится в много проверок и выходов. Но в С#, на котором сейчас работаю, действительно можно неплохо выразить мысль, без никаких дополнительных комментариев.
Во-первых, именно в идеале. Никто от ошибок не застрахован. Во-вторых, рука должна тянуться написать комментарий прежде всего, когда чувствуешь неочевидность данного подхода и/или возможные проблемы. В таких ситуациях комментарии должны быть аргументом принятого технического решения, передавать не только «что» и «как», но и «почему именно это и именно так».
А вот здесь не о чем спорить. Всё так. Я и писал: это пост о том, к чему надо стремиться. Не всё можно сделать без комментариев отлично читаемым. Было бы прекрасно, если бы так получилось.
Другое дело, что часто программисты идеалом считают именно комментированный код. Т.е. стремятся не в ту сторону.
Другое дело, что часто программисты идеалом считают именно комментированный код. Т.е. стремятся не в ту сторону.
Я уверен, что нельзя так сделать и даже не стоит к этому стремиться. Стремиться нужно к золотой середине между самодокументируемостью кода и не «само» (не забывая про другие виды документации как проектной, так и пользовательской). «Само» в кавычках потому, что, чисто формально, комментарии — это часть кода программы… Они обрабатываются транслятором, пускай и путем игнорирования до конца комментария. Так и, например, именование функций и переменных трансляторами, как правило, на определенных этапах игнорируется.
Вообще, мне кажется, не только можно, но и нужно так говорить. Хотя бы потому, что есть две точки зрения:
1. Не важно как написан код, любой код считаем идентичным, если он выполняется правильно.
2. Код от кода сильно отличаются в плане читаемости, поддержки и т.д.
Если мы принимаем второе, то «куда стремиться» — это практика улучшения кода. Формально да, и комментарии — часть кода. У нас цель — улучшить читаемость и облегчить поддержку кода. Есть разные способы улучшения кода. Так комментарии — самый последний и самый худший. Можно код, например, упростить. Я вот недавно проект переписывал. Люди потратили на него два человеко-года. Я написал заново за 2 месяца (именно заново, не брал оттуда ни одной глупейшей идеи) и в итоге кода стало в 10 раз меньше. 40 000 строк против 4000. Думаю, мой код гораздо читабельнее, хотя бы в силу того, что с меньшим объемом надо разбираться.
А можно было бы разобраться с их кодом и покрыть комментариями. На самом деле причина переписывания была в том, что тот код невозможно было развивать никак. Хотя не костыли, а весь по задумкам автора на абстракциях и паттернах. Комментарии тому коду никак бы не помогли. Ну разобрались бы другие люди как работает. А изменять код все равно не возможно.
Код, по моему, надо рассматривать во многих срезах одновременно. И механический рефакторинг (DRY) и читабельность. Т.е. писать его или рефакторить так, чтобы он читался и в нем были видны намерения. В общем случае это невозможно. Для любых ситуаций. Для этого комментарии — как подстраховка. И тут не золотая середина нужна. Тут нужен золотой минимум для комментариев. Не имея критериев для улучшения кода, вы и не сможете улучшать.
Вот, мои критерии. Все они в разных плоскостях и надо смотреть на каждый и стремиться к улучшению каждого.
1. Размер кода. Есть некоторая корреляция между краткостью и поддерживаемостью, читаемостью. Грубая оценка. Но если код слишком большой для небольшой задачи, должны возникать подозрения.
2. DRY. Заметил на глаз, без какого-то анализа, что что-то повторяется (дежавю), надо разбираться, почему так получилось. Есть кандидаты на вынос в отдельный метод, в базовый класс и т.д.
3. Вынос логических кусков в отдельный метод. Та самая читаемость. Если хочется кусок прокомментировать — лучше дать ему имя, сделать отдельным методом. Тут нужен баланс. Так делать не всегда нужно. Вынос куска кода, который используется один раз, не требуется по DRY. Но и не нарушает этот принцип. Но вынос отдельного куска в отдельный метод — это также создание нового имени. Нарушение бритвы Оккама. Создание новой «сущности», а значит дополнительная смысловая нагрузка на читателя кода. Комментарии, кстати, ничем не лучше. Это тоже дополнительная нагрузка. Таким образом, надо всегда смотреть, насколько выгодно будет с т.з. читаемости выносить метод. Дело в его названии. Чтобы уменьшить смысловую нагрузку, имя в идеале должно быть уже известным и понятным читателю. Чтобы ему не надо было открывать метод.
4. Всё должно выражаться по возможности средствами языка программирования. Работа программиста – это работа переводчика. Если вы переводите с китайского на английский, то нечего там оставлять куски еще и на русском, которые вы не сумели перевести. Это говорит о вас, как о плохом переводчике. При этом средства языка программирования – я подразумеваю его родную семантику и синтаксис. Например – отражение в дотнете – архиплохая вещь. Иногда нужна, но она уже выходит за пределы языка. Когда вы говорите «корова», вы передаете смысл, а не считаете количество букв «О» и в каком порядке они идут. Язык – это средство передачи смысла, а не способ в нем самом искать глубокий смысл. Если представлять язык программирования – как язык, а не как конструктор для конструкций в виде стимпанка, то станет яснее, что такое кратко, точно и без искажений выразить мысль – требование заказчика.
5. Писать нужно как можно декларативнее. Вообще, по-моему, в императивности и декларативности языков есть немного лукавство. Даже в самом декларативном языке вы описываете также и логику и задаете направлении работы программы. Известный пример с вычислением квадратного корня. Декларативно задать программу – это указать, что квадрат искомого числа будет равен исходному. Но особо никакой язык эту задачу не решит, не имея аппарата исследования функций. Далее, вы в декларативном стиле на более низком уровне абстракции уже декларируете, что такое метод Ньютона. А в совокупности, это уже императивная программа.
Также и в императивном, особенно в ООП языке – вы можете большую часть кода выразить декларативно. Методы с ветвлениями, циклами и зашитым порядком инструкций – императивные. Классы, их связи – декларативные. Сами методы, даже если они внутри императивные, являются декларацией. Т.е. название метода – это декларация того, что вы хотите сделать. Когда вы пишете вызов метода – вы декларируете, что хотите некоторое действие и вам не важно, как оно выполнится. Как – это внутри того метода. Теперь, если ваш метод, не смотря на то, что он имеет какой-то последовательный код, он частично состоит из вызовов других методов. И вот, стремиться надо в ту сторону, чтобы методы читались целиком и не было желания у читателя заглядывать еще дальше внутрь вызовов. Опять встает вопрос баланса. Не стоит код превращать в балаган названий, скрывая все его конструкции. Где-то они всё равно будут и в совокупности, код это не упростит.
1. Не важно как написан код, любой код считаем идентичным, если он выполняется правильно.
2. Код от кода сильно отличаются в плане читаемости, поддержки и т.д.
Если мы принимаем второе, то «куда стремиться» — это практика улучшения кода. Формально да, и комментарии — часть кода. У нас цель — улучшить читаемость и облегчить поддержку кода. Есть разные способы улучшения кода. Так комментарии — самый последний и самый худший. Можно код, например, упростить. Я вот недавно проект переписывал. Люди потратили на него два человеко-года. Я написал заново за 2 месяца (именно заново, не брал оттуда ни одной глупейшей идеи) и в итоге кода стало в 10 раз меньше. 40 000 строк против 4000. Думаю, мой код гораздо читабельнее, хотя бы в силу того, что с меньшим объемом надо разбираться.
А можно было бы разобраться с их кодом и покрыть комментариями. На самом деле причина переписывания была в том, что тот код невозможно было развивать никак. Хотя не костыли, а весь по задумкам автора на абстракциях и паттернах. Комментарии тому коду никак бы не помогли. Ну разобрались бы другие люди как работает. А изменять код все равно не возможно.
Код, по моему, надо рассматривать во многих срезах одновременно. И механический рефакторинг (DRY) и читабельность. Т.е. писать его или рефакторить так, чтобы он читался и в нем были видны намерения. В общем случае это невозможно. Для любых ситуаций. Для этого комментарии — как подстраховка. И тут не золотая середина нужна. Тут нужен золотой минимум для комментариев. Не имея критериев для улучшения кода, вы и не сможете улучшать.
Вот, мои критерии. Все они в разных плоскостях и надо смотреть на каждый и стремиться к улучшению каждого.
1. Размер кода. Есть некоторая корреляция между краткостью и поддерживаемостью, читаемостью. Грубая оценка. Но если код слишком большой для небольшой задачи, должны возникать подозрения.
2. DRY. Заметил на глаз, без какого-то анализа, что что-то повторяется (дежавю), надо разбираться, почему так получилось. Есть кандидаты на вынос в отдельный метод, в базовый класс и т.д.
3. Вынос логических кусков в отдельный метод. Та самая читаемость. Если хочется кусок прокомментировать — лучше дать ему имя, сделать отдельным методом. Тут нужен баланс. Так делать не всегда нужно. Вынос куска кода, который используется один раз, не требуется по DRY. Но и не нарушает этот принцип. Но вынос отдельного куска в отдельный метод — это также создание нового имени. Нарушение бритвы Оккама. Создание новой «сущности», а значит дополнительная смысловая нагрузка на читателя кода. Комментарии, кстати, ничем не лучше. Это тоже дополнительная нагрузка. Таким образом, надо всегда смотреть, насколько выгодно будет с т.з. читаемости выносить метод. Дело в его названии. Чтобы уменьшить смысловую нагрузку, имя в идеале должно быть уже известным и понятным читателю. Чтобы ему не надо было открывать метод.
4. Всё должно выражаться по возможности средствами языка программирования. Работа программиста – это работа переводчика. Если вы переводите с китайского на английский, то нечего там оставлять куски еще и на русском, которые вы не сумели перевести. Это говорит о вас, как о плохом переводчике. При этом средства языка программирования – я подразумеваю его родную семантику и синтаксис. Например – отражение в дотнете – архиплохая вещь. Иногда нужна, но она уже выходит за пределы языка. Когда вы говорите «корова», вы передаете смысл, а не считаете количество букв «О» и в каком порядке они идут. Язык – это средство передачи смысла, а не способ в нем самом искать глубокий смысл. Если представлять язык программирования – как язык, а не как конструктор для конструкций в виде стимпанка, то станет яснее, что такое кратко, точно и без искажений выразить мысль – требование заказчика.
5. Писать нужно как можно декларативнее. Вообще, по-моему, в императивности и декларативности языков есть немного лукавство. Даже в самом декларативном языке вы описываете также и логику и задаете направлении работы программы. Известный пример с вычислением квадратного корня. Декларативно задать программу – это указать, что квадрат искомого числа будет равен исходному. Но особо никакой язык эту задачу не решит, не имея аппарата исследования функций. Далее, вы в декларативном стиле на более низком уровне абстракции уже декларируете, что такое метод Ньютона. А в совокупности, это уже императивная программа.
Также и в императивном, особенно в ООП языке – вы можете большую часть кода выразить декларативно. Методы с ветвлениями, циклами и зашитым порядком инструкций – императивные. Классы, их связи – декларативные. Сами методы, даже если они внутри императивные, являются декларацией. Т.е. название метода – это декларация того, что вы хотите сделать. Когда вы пишете вызов метода – вы декларируете, что хотите некоторое действие и вам не важно, как оно выполнится. Как – это внутри того метода. Теперь, если ваш метод, не смотря на то, что он имеет какой-то последовательный код, он частично состоит из вызовов других методов. И вот, стремиться надо в ту сторону, чтобы методы читались целиком и не было желания у читателя заглядывать еще дальше внутрь вызовов. Опять встает вопрос баланса. Не стоит код превращать в балаган названий, скрывая все его конструкции. Где-то они всё равно будут и в совокупности, код это не упростит.
Вынос куска кода, который используется один раз, не требуется по DRY. Но и не нарушает этот принцип.
Формально нарушает — два раза придется писать название метода.
Работа программиста – это работа переводчика.Понравилась аналогия, но она скорее защищает комментарии. Хороший переводчик с помощью примечаний (комментариев) передает не только смысл, но и контекст, которым читатель вероятно не обладает. Культурный, философский, юридический или ещё какой — не суть. Первый пришедший в голову пример — в английском есть слово «sheriff», которого в русском нет (ну или не было пускай даже в пассивном словаре значительной части, если не большинства, русскоговорящих относительно недавно), переводчик может писать «глава полицейского управления округа в США (как правило выборная должность)» каждый раз, может слово «заимствовать», не раскрывая понятия («формально в русском языке слово давно есть кому надо посмотрят в БСЭ»), а может дополнительно дать ему один раз определение в примечаниях, да ещё желательно с фразой «здесь», поскольку у слова «шериф» несколько значений и в контексте современных США оно означает несколько другую сущность, чем в контексте средневековой Англии.
НЛО прилетело и опубликовало эту надпись здесь
судя по минусам вообще всем людям, которые против комментариев, такое ощущение, что здесь собрались враги языков программирования )))
Язык программирования — это язык. Выражая логику и смысл на нем, Вы, кроме этого, не дублируете свою работу. На нем в любом случае должна быть выражена логика, чтобы программа заработала. Кроме того, выражая на нем то, что вы задумали, полнее, вы еще и даете возможность компилятору эту логику проверять. Смысл (требования) — это всегда ограничения. Вы можете выбирать общий тип, для бОльшей гибкости и меньших ограничений, например, указатель на сырую память, передавая там число — возраст человека. И напишете комментарий, что там возраст. Это не утрирование, а доведение до крайности идеи с комментариями. А можете создать типы, точно ограничивающие данные, поведение, как и в требованиях. Последний подход — и есть выражение смысла в коде. Компилятор тогда будет с его (допустим) статической типизацией работать с высоким КПД и выдавать надежный машинный код. Смысл комментариев на этом фоне просто теряется.
То, что Вы проще понимаете человеческий язык… Не совсем верно. Вы думаете кучей языков, кроме естественного. Например, математика. Представьте себе школьную задачу — бросание камня под углом к горизонту. Естественным языком решение звучало бы так: ну примерно, как кажется, метров на 20-30. Язык же формул позволяет выдать точный ответ.
Естественные языки очень плохо подходят вообще для думать. Вы, когда думаете, еще и кучу всего моделируете, в том числе интуитивно используете математику.
Ну это лирика. Действительно, требования чаще всего выражаются естественным языком. Поэтому я и писал, что языки программирования не идеальны. Не близки к естественному, точнее, не одинаково близки. Будем ждать будущих языков.
Но из этого и не следует, что не нужно пытаться приблизить код к естественному языку, а надо писать говнокод и покрывать его комментариями, чтобы люди поняли.
Язык программирования — это язык. Выражая логику и смысл на нем, Вы, кроме этого, не дублируете свою работу. На нем в любом случае должна быть выражена логика, чтобы программа заработала. Кроме того, выражая на нем то, что вы задумали, полнее, вы еще и даете возможность компилятору эту логику проверять. Смысл (требования) — это всегда ограничения. Вы можете выбирать общий тип, для бОльшей гибкости и меньших ограничений, например, указатель на сырую память, передавая там число — возраст человека. И напишете комментарий, что там возраст. Это не утрирование, а доведение до крайности идеи с комментариями. А можете создать типы, точно ограничивающие данные, поведение, как и в требованиях. Последний подход — и есть выражение смысла в коде. Компилятор тогда будет с его (допустим) статической типизацией работать с высоким КПД и выдавать надежный машинный код. Смысл комментариев на этом фоне просто теряется.
То, что Вы проще понимаете человеческий язык… Не совсем верно. Вы думаете кучей языков, кроме естественного. Например, математика. Представьте себе школьную задачу — бросание камня под углом к горизонту. Естественным языком решение звучало бы так: ну примерно, как кажется, метров на 20-30. Язык же формул позволяет выдать точный ответ.
Естественные языки очень плохо подходят вообще для думать. Вы, когда думаете, еще и кучу всего моделируете, в том числе интуитивно используете математику.
Ну это лирика. Действительно, требования чаще всего выражаются естественным языком. Поэтому я и писал, что языки программирования не идеальны. Не близки к естественному, точнее, не одинаково близки. Будем ждать будущих языков.
Но из этого и не следует, что не нужно пытаться приблизить код к естественному языку, а надо писать говнокод и покрывать его комментариями, чтобы люди поняли.
Это ещё и хуже для программирования, что думаем на куче языков :) То есть задача программирования, вернее подзадача документирования кода, усложняется. С кучи языков нужно перевести на один, с довольно ограниченными средствами передачи смысла, а потом читатель кода должен перевести это опять на кучу языков. Почему ему не намекнуть комментарием «здесь я думаю языком математики, а здесь языком физики» раз в ЯП для этого средств нет?
Понимаете, задача документирования в идеале вообще не должна стоять. Код — это язык и это же документация. Заблуждение изначально, по моему мнению, конечно, в том, что когда-то решили, что код — это материальный объект. Что-то вроде дома или автомобиля. А документация — это чертежи, по которому его делают.
А вот и не правильно. Код — это тоже чертежи. Кто-то вдалбливает в голову на уровне подсознания, наверное, в ВУЗах, что так правильно с инженерной т.з. (и все себя в касках представляют деволоперами, конструкторское бюро еще есть). Когда как это не стройка, это не создание конструкций. Это перевод. Поэтому два перевода с языка заказчика держать глупо, неправильно принципиально. Еще интересно, когда еще и делают двойной перевод. Т.е. когда вначале рисуют схемы и пишут документацию, а потом с нее делают перевод уже на язык программирования.
Ладно, напишу ка я на примере ниже. Вроде ж просто всё и примеры можно приводить, как отказываться от комментариев.
А вот и не правильно. Код — это тоже чертежи. Кто-то вдалбливает в голову на уровне подсознания, наверное, в ВУЗах, что так правильно с инженерной т.з. (и все себя в касках представляют деволоперами, конструкторское бюро еще есть). Когда как это не стройка, это не создание конструкций. Это перевод. Поэтому два перевода с языка заказчика держать глупо, неправильно принципиально. Еще интересно, когда еще и делают двойной перевод. Т.е. когда вначале рисуют схемы и пишут документацию, а потом с нее делают перевод уже на язык программирования.
Ладно, напишу ка я на примере ниже. Вроде ж просто всё и примеры можно приводить, как отказываться от комментариев.
Так комментарии (кроме всяческих *doc и аннотаций) не должны содержать перевод с языка заказчика. Они должны содержать оригинал на языке заказчика. Человек открывает код и видит, что хотел заказчик, а что получил. И далеко не всегда первое «что» можно выразить достаточно кратко, чтобы использовать в виде имени метода или переменной.
А давайте в код ещё цитаты с башорга постить. Ну чтоб веселее было читать. И фотки симпатичных сотрудниц.
Вам не кажется, что код должен содержать код? А для документации, требований и так далее — есть немного другие места?
У нас требования заказчика, даже к небольшой части функционала — это хорошая такая вики страничка с макетами. Как Вы это вообще в коде представляете? Я уж молчу, что пожелание заказчика исполняет весь код вцелом, а не некая конкретная функция
Вам не кажется, что код должен содержать код? А для документации, требований и так далее — есть немного другие места?
У нас требования заказчика, даже к небольшой части функционала — это хорошая такая вики страничка с макетами. Как Вы это вообще в коде представляете? Я уж молчу, что пожелание заказчика исполняет весь код вцелом, а не некая конкретная функция
Не кажется. Код должен содержать информацию, облегчающую его чтение. Комментарии — один из способов эту информацию передать. Пускай даже ссылкой на вики :)
Или вы при именовании методов или классов называете их типа p7_12 чтобы ни в коем случае не допустить просачивания смысла требований в код? А кому надо зачем-то узнать что в терминах домена код делает откроет ТЗ на пункте 7.12? «Кодировать» же почти синоним «шифровать». Если вы скажите, что я бросаюсь в крайность, то я вам отвечу тем же.
Или вы при именовании методов или классов называете их типа p7_12 чтобы ни в коем случае не допустить просачивания смысла требований в код? А кому надо зачем-то узнать что в терминах домена код делает откроет ТЗ на пункте 7.12? «Кодировать» же почти синоним «шифровать». Если вы скажите, что я бросаюсь в крайность, то я вам отвечу тем же.
Знаете, как то довелось читать «войну и мир» Там есть главы, где дворяне общаются на смеси русского и французкого. Я французкого, кстати, не знаю. Так вот, половину страницы занимали сноски-переводы. И знаете — это нифига не упрощало чтение. Книга, написанная целиком на простом и понятном языке читается напорядок лучше книги, написанной непонятным языком, но напичканной сносками/комментариями
Моя идея в том — что всю информацию можно передать кодом. По крайней мере, если мы гооврим не о машинных кодах или об ассемблере.
Моя идея в том — что всю информацию можно передать кодом. По крайней мере, если мы гооврим не о машинных кодах или об ассемблере.
Простите, а вы термины в коде пишете по-русски?
А с чего вы взяли, что понятным может быть только русский язык? Как раз мешанину из транслитирации и английского языка тяжело читать
Понятным обычно может быть только родной язык разработчика, особенно в части сложных прикладных терминов.
Если для вас родной язык английский — вам проще, поздравляю.
Если для вас родной язык английский — вам проще, поздравляю.
Знаете, чуть меньше года назад, я пришёл в английский проект, который занимается миникридитованием. Т.е. куча прикладных терминов + устоявшиеся в команде выражения. Естественно — все документы и общение на английском (мой уровень — в районе среднего). И знаете — ничего, привык. Иногда на рабочие темы на английском было проще говорить чем на русском.
Так что я думаю ваша теория в корне не верна.
Так что я думаю ваша теория в корне не верна.
Я неправильно выразился, конечно, не родной язык разработчика. Я говорил о языке прикладной области.
В DDD есть такое понятие — ubiquitous language, общий язык. Вот когда понятия из этого языка (например, lease) однозначно выразимы в коде — наступает счастье. А когда у вас общий язык составлен из понятий на русском, у вас начинаются развлечения (обременитель? залогодатель? паника!).
В DDD есть такое понятие — ubiquitous language, общий язык. Вот когда понятия из этого языка (например, lease) однозначно выразимы в коде — наступает счастье. А когда у вас общий язык составлен из понятий на русском, у вас начинаются развлечения (обременитель? залогодатель? паника!).
Для этого существует код-ревью. Чтобы давать по ушам за неправильное именование, и приучать к правильному.
Дело не в неправильном именовании, а в том, что разработчик, глядя в русскоязычную доменную модель и англоязычный код, не может сопоставить одно с другим без дополнительных подсказок. И дальше остается только вопрос, куда именно вносить эти подсказки.
нет. Сколько у вас в работе часто встречающихся узко специфических терминов? 10, 15? Очень врядли больше. Сколько надо времени, чтоб их заучить? Да практически не сколько. Ну наткнётесь вы в коде на функцию getLeaseAmount — Если вы не вчера из деревни приехали, то как минимум get и Amount уже знакомы. Lease — спросите у гугла или товарища.
Зато в разговорах с англоязычными товарищами не будет проблем.
Зато в разговорах с англоязычными товарищами не будет проблем.
Во-первых, по решению — несколько сотен. Во-вторых, проблема в том, как не перепутать близкие по значению специальные термины.
Вот есть Charge — это обременение или начисление? А если в прикладной модели есть и то, и другое?
(не говоря уже о том, что сложнее в обратную сторону — понять, как называется класс, который реализует русскоязычный термин из прикладной модели. Вот есть юридическое лицо (в противовес физическому) — как понять, как будет называться соответствующая ему сущность в коде?)
Вот есть Charge — это обременение или начисление? А если в прикладной модели есть и то, и другое?
(не говоря уже о том, что сложнее в обратную сторону — понять, как называется класс, который реализует русскоязычный термин из прикладной модели. Вот есть юридическое лицо (в противовес физическому) — как понять, как будет называться соответствующая ему сущность в коде?)
Моя идея в том — что всю информацию можно передать кодом.
Тогда имена должны полностью её передавать, то есть быть по сути комментариями, ограниченные только синтаксисом (подчеркивания вместо пробелов, исключение знаков препинания и т. п.), что читаемость не повысит. У нас задача не просто передать информацию, а передать её в максимально удобном для потребления в виде, ограничиваясь разумными ресурсами.
Забавно, что я когда писал про примечания переводчика тоже вспоминал «Войну и мир», но с другими чувствами — положительными.
Кстати, насчет языка комментариев. Взаимодействуя с иностранцами мы пришли к тому, что если английский в совершенстве не знаешь, то лучше писать комментарии на родном языке, описывающие, что должна делать та или иная сущность, стараясь не использовать сленга и сокращений, сложносочиненных предложений, соблюдать правила и т. п. В общем облегчать задачу перевода (машинного или «школьного» — не суть). Потом тот, кто английский знает хорошо, сможет перевести на него без труда (изменяя комментарии в коде), и переименовать сущности если их название безграмотно на английском получилось изначально. Это удобнее чем разбирать неграмотные названия и комментарии на английском, сам его толком не зная — двойная безграмотная трансляция получается, а такой метод сводит её кк максимум одной — англофон может плохо перевести нормальный немецкий или русский в вид понятный даже тем, кто с английский не очень дружит.
Допустим видим такой кусок кода:
Здесь без комментария и правда не разберешься, зачем этот код. Но присмотревшись, видим, что почему-то смысл происходящего описан только в комментарии. Когда как имена переменных ни о чем не говорят. Меняем ситуацию. Также переименовываем и в комментарии, чтобы не устарел
Замечаем, что простое переименоваие сделало вторую фразу в комментарии бессмысленной. Убираем
В принципе уже можно удалять и весь комментарий. И так понятно по переменной, что мы ищем и код не слишком большой, чтобы понять смысл. Но смотрим дальше. Нам надо найти сумму. С чего вдруг у нас обход массива от первого элемента до последнего? А почему не наоборот? Похоже тут лишняя информация. Замысел у нас короче — просто найти сумму. Переделываем.
Уже понятно, что мы складываем элементы (пирожки), просто. В не волнующем нас порядке. Уже лучше. Но все таки складывание — что-то лишнее. Находим метод суммы и пользуемся им:
Вот здесь уже никто не упрекнет, что строка императивная и расписывает как делать, а не говорит что. Пример, конечно, вымышленный. Но улучшение кода внутри методов, для C#, не намного отличается. Там есть еще Linq, так что не только сумму можно найти. Если же в языке, допустим, нет такого средства, то тот кусок кода точно также можно было представить:
или если массив является полем:
// // Далее мы ищем сумму пирожков во всех корзинках. Массив a[] содержит число пирожков в каждой корзинке
int c = a.Length();
int s = 0;
for (int i = 0; i < c; i++)
{
s += a[i];
}
Здесь без комментария и правда не разберешься, зачем этот код. Но присмотревшись, видим, что почему-то смысл происходящего описан только в комментарии. Когда как имена переменных ни о чем не говорят. Меняем ситуацию. Также переименовываем и в комментарии, чтобы не устарел
// Далее мы ищем cумму пирожков во всех корзинках. Массив pattyCountsInBaskets[] содержит число пирожков в каждой корзинке
int pattySum = 0;
for (int i = 0; i < pattyCountsInBaskets.Length(); i++)
{
pattySum += pattyCountsInBaskets[i];
}
Замечаем, что простое переименоваие сделало вторую фразу в комментарии бессмысленной. Убираем
// Далее мы ищем cумму пирожков во всех корзинках.
int pattySum = 0;
for (int i = 0; i < pattyCountsInBaskets.Length(); i++)
{
pattySum += pattyCountsInBaskets[i];
}
В принципе уже можно удалять и весь комментарий. И так понятно по переменной, что мы ищем и код не слишком большой, чтобы понять смысл. Но смотрим дальше. Нам надо найти сумму. С чего вдруг у нас обход массива от первого элемента до последнего? А почему не наоборот? Похоже тут лишняя информация. Замысел у нас короче — просто найти сумму. Переделываем.
int pattySum = 0;
foreach (int puttyCount in pattyCountsInBaskets)
{
pattySum += puttyCount;
}
Уже понятно, что мы складываем элементы (пирожки), просто. В не волнующем нас порядке. Уже лучше. Но все таки складывание — что-то лишнее. Находим метод суммы и пользуемся им:
int pattySum = pattyCountsInBaskets.Sum();
Вот здесь уже никто не упрекнет, что строка императивная и расписывает как делать, а не говорит что. Пример, конечно, вымышленный. Но улучшение кода внутри методов, для C#, не намного отличается. Там есть еще Linq, так что не только сумму можно найти. Если же в языке, допустим, нет такого средства, то тот кусок кода точно также можно было представить:
int pattySum = Sum(pattyCountsInBaskets);
или если массив является полем:
int pattySum = pattyCountsInBasketsSum();
Еще. Реальный пример из жизни. Пришел мне код. Правда писал не профессиональный разработчик. Но вот такой код, весь зеленый, так покрыт комментариями:
Разберем первую строку. Просто меняю имя переменным и комментарий сразу становится бессмысленным повторением кода:
Если еще ввести некоторые элементы языка для повышения читаемости, то:
И т.д. Обычно комментарии всегда можно выкосить. Они показывают то, о чем должен говорить сам код.
PS. Не знаю, почему так жутко раскрашивается текст C#
for (int i = 0; i < UBOUND_1; i++) // i - Month Dimension, UBOUND_1 - Upper Bound of Month Dimension
{
for (int j = 0; j < UBOUND_2; j++) // j - ......., UBOUND_2 - .......
{
for (int k = 0; k < UBOUND_3; k++) // k - ......, UBOUND_3 - ......
{
if (k > 3)
{
s += a[i, j, k];
}
}
}
}
Разберем первую строку. Просто меняю имя переменным и комментарий сразу становится бессмысленным повторением кода:
for (int monthIndex = 0; monthIndex < monthCount; monthIndex++) // monthIndex - Month Dimension, monthCount - Upper Bound of Month Dimension
Если еще ввести некоторые элементы языка для повышения читаемости, то:
enum Month: int
{
January = 0,
February = 1,
March 2,
.....
}
foreach (var month in Enum.GetValues(typeof(Month))
И т.д. Обычно комментарии всегда можно выкосить. Они показывают то, о чем должен говорить сам код.
PS. Не знаю, почему так жутко раскрашивается текст C#
Кто Вам рассказал такую чушь? Давайте вы преведёте пример кода, который невозможно оставить без комментария (не анотации), а я попробую привести вам контраргумент
Математические или физические расчеты по «нешкольным» (а зачастую и по школьным) формулам. При переводе «многоэтажных» формул в «функционально-линейный вид», свойственный мэйнстримовым ЯП, они теряют, как минимум, визуальную узнаваемость, а могут быть вообще неизвестны тому, кто их читает.
Вариант с функцией
m1 = F / (G * (m2 / pow(R, 2)) // Используем следствие закона всеобщего тяготения НьютонаВариант с функцией
calcM1ByConsequenceOfNewtonsLawOfUniversalGravitation чур не предлагать.m1 = getMassFromForcePlanetMassAndRadius(force, planetMass, radius);
function getMassFromForcePlanetMassAndRadius(force, planetMass, radius) {
return force / (G * (planetMass / pow(Radius, 2))
}
Согласитесь, в таком виде код более читаем. Только не надо ныть на тему длины названия функции — не в блокноте чай работаем.
Самое интересное в том, что следствий из закона Ньютона может быть больше чем одно, так что программисту прийдётся поломать голову, если он увидит такой коммент.
Более того, такой вариант подталкивает к различным абстракциям и уменьшению зависимостей — у вас вполне могут быть функции для расчёта массы в инерционных и неинерционных системах отсчёта, которые легко править в зависимости от принятой в ситеме точности расчётов. В вашем же случае Вы, скореее всего, получите раскиданые по коду формулы, с потерявшими актуальность коментариями.
function getMassFromForcePlanetMassAndRadius(force, planetMass, radius) {
return force / (G * (planetMass / pow(Radius, 2))
}
Согласитесь, в таком виде код более читаем. Только не надо ныть на тему длины названия функции — не в блокноте чай работаем.
Самое интересное в том, что следствий из закона Ньютона может быть больше чем одно, так что программисту прийдётся поломать голову, если он увидит такой коммент.
Более того, такой вариант подталкивает к различным абстракциям и уменьшению зависимостей — у вас вполне могут быть функции для расчёта массы в инерционных и неинерционных системах отсчёта, которые легко править в зависимости от принятой в ситеме точности расчётов. В вашем же случае Вы, скореее всего, получите раскиданые по коду формулы, с потерявшими актуальность коментариями.
Код-то читаем. Но понять из него, почему считается именно по этой формуле — невозможно.
public class Planet
{
private readonly IPhysics physics;
private readonly double mass;
private readonly double radius;
public Planet (IPhysics physics, double mass, double radius)
{
if (physics == null) throw new AgumentNullException ("physics");
if (mass <= 0) ...
if (radius <= 0) ...
this.physisc = physics;
this.mass = mass;
this.radius = radius;
}
...
public double CalulcateImpulse (double force)
{
return this.physics.CalculateImpulse (force, this.mass, this.radius);
}
}
internal class NewtonPhysics : IPhysics
{
...
public double CalulcateImpulse (double force, double mass, double radius)
{
return force / (G * (mass / Math.Pow(radius, 2));
}
}
А теперь скажите мне, сколько операций вам понадобится, чтобы определить, что выдаст
BTW, я из кода вообще не понимаю физический смысл расчетов. И это очень показательно.
planet.CalculateImpulse(1).BTW, я из кода вообще не понимаю физический смысл расчетов. И это очень показательно.
А скажите мне сначала зачем вам знать что выдаст
planet.CalculateImpulse(1)? Мы именно для того пишем программы, чтобы за нас на подобное отвечал компьютер. Вам лишь важно знать, что при вызове planet.CalculateImpulse(1) будет возвращён импульс планеты для силы 1. Если вам нужно проверить, что CalculateImpulse считается верно, то вам нужно будет написать тест для интерисующей вас физики (IPhysics) — в данном случае у нас только одна реализация и нам нужно будет написать тест для NewtonPhysics.CalulcateImpulse. В виду того, что метод Planet.CalulcateImpulse тривиален, его вообще можно не тестировать (при условии, что тест для NewtonPhysics.CalulcateImpulse написан).А скажите мне сначала зачем вам знать что выдаст planet.CalculateImpulse(1)?
Чтобы понимать, как работает программа. Не числовое значение, нет — алгоритм расчета.
Понимать как работает программа и алгоритм расчёта это две разные задачи. Для понимая работы программы вам не нужно знать внутренние алгоритмы расчёта — достаточно видеть что рассчитывается импульс планеты и потом это значение где-то применяется.
Для понимания алгоритма расчёта физики вам нужно будет посмотреть на класс NewtonPhysics из названия которого следует, что это реализация расчёта Ньютоновской физики. Там есть метод CalulcateImpulse, название которого говорит, что здесь происходит расчёт импульса. Смотрим — там формула. Почему именно такая? Ну вот тут уже нужно вспоминать/гуглить теорию расчёта импульса ньютоновской физики — наши названия можно использовать как ключевые слова, лезем в гугл и вбиваем слова «Расчёт импульса Ньютоновская физика».
Ваш вариант комментария:
Отсюда тоже непонятно почему именно такая формула — нужно точно также идти читать теорию (если не помнишь). Но только в нашем случае мы вынесли часть, которая скорее всего будет использована в других расчётах (не только планет) и разъединили классы вычислений и планеты тем самым подготовив их к тестированию и расширению другими физическими теориями.
Для понимания алгоритма расчёта физики вам нужно будет посмотреть на класс NewtonPhysics из названия которого следует, что это реализация расчёта Ньютоновской физики. Там есть метод CalulcateImpulse, название которого говорит, что здесь происходит расчёт импульса. Смотрим — там формула. Почему именно такая? Ну вот тут уже нужно вспоминать/гуглить теорию расчёта импульса ньютоновской физики — наши названия можно использовать как ключевые слова, лезем в гугл и вбиваем слова «Расчёт импульса Ньютоновская физика».
Ваш вариант комментария:
Используем следствие закона всеобщего тяготения Ньютона
Отсюда тоже непонятно почему именно такая формула — нужно точно также идти читать теорию (если не помнишь). Но только в нашем случае мы вынесли часть, которая скорее всего будет использована в других расчётах (не только планет) и разъединили классы вычислений и планеты тем самым подготовив их к тестированию и расширению другими физическими теориями.
Ваш вариант комментария:
Это не мой вариант комментария.
Но только в нашем случае мы вынесли часть, которая скорее всего будет использована в других расчётах (не только планет) и разъединили классы вычислений и планеты тем самым подготовив их к тестированию и расширению другими физическими теориями.
А это было нужно?
А это было нужно?
Что? Возможность тестирования? Ну, это уже вам решать — зависит от вашего уровня как разработчика, от наличия требований к качественному коду, необходимостью его модификации в будущем. В общем, тут можно долго перечислять, но лучше почитать зачем нужны юнит тесты.
Возможность модификации.
(потому что еще нужно показать, что предыдущий вариант кода был менее тестируемым, чем предлагаемый вами)
(потому что еще нужно показать, что предыдущий вариант кода был менее тестируемым, чем предлагаемый вами)
Возможность модификации в нетривиальных программах подразумевает тестируемость. А для этого нужно писать юнит-тесты. А иначе как проверить что ваши изменения не поломали весь другой код, который использует эту функцию?
Я уже не говорю о других приемуществах DI, о которых я советую почитать в замечательной книге Dependency Injection in .NET от Mark Seemann
Я уже не говорю о других приемуществах DI, о которых я советую почитать в замечательной книге Dependency Injection in .NET от Mark Seemann
Возможность модификации в нетривиальных программах подразумевает тестируемость.
Я не очень понимаю, что у вас что подразумевает.
Я же хочу сказать, что возможность модификации (точнее — расширения) может быть не нужна; а что касается тестируемости, то еще нужно выяснять, насколько в реальности какой из вариантов был тестируемым.
И спасибо, Симана я тоже читал, не ново. Вот только не надо путать преимущества DI с преимуществами IoC (оно же DIP из SOLID).
А вот тут как раз главное заблуждение. Код не должен давать понимание, почему мы реализуем именно такое решение. Вы ведь маркетинговые иследования не прикрепляете к коду, чтоб обосновать сценарии поведения пользователей?
Задача программиста — просто воплотить в жизнь заданную модель. Воплотить её точно согласно спецификации, без дополнительных упрощений или упущений.
Задача программиста — просто воплотить в жизнь заданную модель. Воплотить её точно согласно спецификации, без дополнительных упрощений или упущений.
Часто приходится принимать решения в них не отраженные. И да, комментарий в стиле «прости тот, кто читает код — так менеджер приказал написать» вполне допустимы и даже необходимы.
Простите, что? Менеджер приказал так написать? Ну мы ведь понимаем что это просто хреновая отговорка?
Знаете, инженеру надо обладать некой долей смелости. Например — послать куда подальше менеджера, который говорит как писать. Или взять на себя смелость обьявить рефакторинг, если код уже сильно воняет.
А вот как раз из-за трусости перед криком начальства (для хорошего спеца увольнение не страшно) как раз и получаются комментарии «я хотел сделать по другому, но меня заставили». Это просто значит что Вы не верите себе самому, и не готовы взять на себя ответственность.
Знаете, инженеру надо обладать некой долей смелости. Например — послать куда подальше менеджера, который говорит как писать. Или взять на себя смелость обьявить рефакторинг, если код уже сильно воняет.
А вот как раз из-за трусости перед криком начальства (для хорошего спеца увольнение не страшно) как раз и получаются комментарии «я хотел сделать по другому, но меня заставили». Это просто значит что Вы не верите себе самому, и не готовы взять на себя ответственность.
Код не должен давать понимание, почему мы реализуем именно такое решение.
Должен. Даже если это понимание сводится к «смотри требования, п 2.6».
Особенно тогда, когда на первый взгляд написанное кажется бредом (а так часто бывает).
Мы удивительно единодушны в этом топике :)
Именно установка о том, что «а, я опишу коментом, если чё непонятное будет» и ведёт к бредовому коду — потому что программист не напрягается заранее о DI и SRP принципах и фигачит всё в процедурном стиле, когда надо было в ООП.
DI, SRP и прочий умные буквы относится несколько к другому измерению чем процедурный стиль или ООП. В процедурном стиле так же не приветствуются, например, захардкоженные зависимости, заведомо, создающие проблемы, или наличие более одной ответственности у процедуры.
(Не надо, пожалуйста, упоминать в одном предложении DI и SRP, это ведет к адской путанице.)
Вы путаете «непонятно, что» и «непонятно, зачем». Именование показывает что, код показывает как, но показать, зачем можно только требованиями в том или ином виде.
Вы путаете «непонятно, что» и «непонятно, зачем». Именование показывает что, код показывает как, но показать, зачем можно только требованиями в том или ином виде.
А, по-моему, хуже:
— В месте вызова не видно как считается, пускай это мелочь и если нас это заинтересовало, то заглянем в тело
— В теле функции что за формула и откуда она взялась непонятно, а преобразование имен её компонентов от классического вида в контекстному (причем не очень верное, R — в формуле расстояние, а не радиус) эту непонятность ещё больше усложняет.
— Откуда-то взялась планета как исходный параметр, вообще задача стояла как определение массы космических объектов по силе их воздействия на космический корабль. Планеты в формулу если и входят, то как результат. Ну и вообще не помешало бы иметь функцию не сильно от контекста зависящую.
— Сильно режет глаз повторение одних и тех же слов.
Если уж идти по вашему пути, то код должен выглядеть примерно так:
Так более-менее вопросов нет и Google ссылку на статью вики первой выдает по запросу
Вообще говоря, я бы первоначальный код изменил как-то так
Имхо, это самый читаемый вариант из всех, которые есть в треде, плюс нормальная IDE позволит очень долго в код функции не заглядывать.
— В месте вызова не видно как считается, пускай это мелочь и если нас это заинтересовало, то заглянем в тело
— В теле функции что за формула и откуда она взялась непонятно, а преобразование имен её компонентов от классического вида в контекстному (причем не очень верное, R — в формуле расстояние, а не радиус) эту непонятность ещё больше усложняет.
— Откуда-то взялась планета как исходный параметр, вообще задача стояла как определение массы космических объектов по силе их воздействия на космический корабль. Планеты в формулу если и входят, то как результат. Ну и вообще не помешало бы иметь функцию не сильно от контекста зависящую.
— Сильно режет глаз повторение одних и тех же слов.
Если уж идти по вашему пути, то код должен выглядеть примерно так:
object_mass = getObjectMass(force, self_mass, distance);
function getObjectMass(force, subject_mass, distance)
{
return getFirstMassUsingNewtonsLawUniversalGravitation(force, subject_mass, distance);
}
function getFirstMassUsingNewtonsLawUniversalGravitation(F, m2, R)
{
return F / (G * (m2 / pow(R, 2));
}
Так более-менее вопросов нет и Google ссылку на статью вики первой выдает по запросу
NewtonsLawUniversalGravitationВообще говоря, я бы первоначальный код изменил как-то так
object_mass = getFirstMass(force, distance, self_mass);
/**
* Return mass of first object from force, distance and mass
* of second object using Newton's law of universal gravitation
*
* @param double F Graviton force between objects
* @param double R Distance between objects
* @param double m2 Mass of second object
*
* @return double Mass of first object
*/
function getFirstMass(F, R, m2)
{
return F / (G * (m2 / pow(R, 2));
}
Имхо, это самый читаемый вариант из всех, которые есть в треде, плюс нормальная IDE позволит очень долго в код функции не заглядывать.
Давайте проще. Зачем вообще пишутся функции? Повторное использование кода и абстракция. То есть, если Вы написали функцию, она должна именоваться таким образом, что бы не вызывать желания заглянуть в её код.
Именно тут любители комментариев и начинают городить проблему. Действительно, зачем делать нормальное именование функции, если можно написать комментарий? «Получить первую массу» — ?! АА, да, там комментарий есть.
Но вот пройдёт пара циклов разработки, и мы сталкиваемся с интересной штукой — универсальное название функции не мешает нам изменить её код таким образом, чтоб он возвращал уже совсем не то, что описанно в комментарии (А вы читаете комментарии к знакомым участкам кода?). Вот тут то новички (которые ещё не выучили что делает функция «вернуть первую массу») и офигеют…
Именно тут любители комментариев и начинают городить проблему. Действительно, зачем делать нормальное именование функции, если можно написать комментарий? «Получить первую массу» — ?! АА, да, там комментарий есть.
Но вот пройдёт пара циклов разработки, и мы сталкиваемся с интересной штукой — универсальное название функции не мешает нам изменить её код таким образом, чтоб он возвращал уже совсем не то, что описанно в комментарии (А вы читаете комментарии к знакомым участкам кода?). Вот тут то новички (которые ещё не выучили что делает функция «вернуть первую массу») и офигеют…
она должна именоваться таким образом, что бы не вызывать желания заглянуть в её код.
Ограничения синтаксиса языка (допустимый алфавит и длина идентификатор) и просто разумные требования на длину идентификаторов (хотя бы чтобы просто можно было видеть вызов функции целиком без горизонтального скроллинга) ограничивают нас в желании передать читателю кода всё что хочется. Более того, есть ещё понимание, что во многих случаях ему вся информация и не нужна Комментарии типа того, что в моем последнем варианте создают три уровня погружения читателя кода в функцию:
— строка
object_mass = getFirstMass(force, distance, self_mass); по-моему вполне информативна сама по себе чтобы понимать, что функция возвращает и на основании чего. Дублировать информацию как в случае getMassFrom<b>ForcePlanetMass</b>And<b>Radius</b>(force, planetMass, radius); не считаю необходимым.— Второй уровень (*doc комментарии) позволяет при необходимости получить более развернутое и понятное описание того что, из чего и как делает функция без изучения её тела. В современных IDE даже без открытия файла с функцией, просто тултип выскочит при наведении мышки или нажатия хоткея. В простых редакторах достаточно ознакомления с *doc блоком.
— И только если нам нужно детально ознакомиться (поиск ошибок, оптимизация, модификация логики) с логикой работы функции, нам нужно открывать (в случае IDE) файл с ней и изучать тело.
Проблема в том, что и «нормальное» (содержащее полную спецификацию) название функции никак не мешает изменить её код таким образом, чтоб он возвращал уже совсем не то, что описанно в
Таким способом вы закрыли возможность юнит тестирования планеты. С таким же успехом вы можете весь код написать в Main и будет всё ок, т.к. судя по всему, программа тривиальная и нечего тут вообще думать о коментариях и SOLID принципах.
Чем я её закрыл и чем нарушаю (если нарушаю) SOLID?
можно тестировать хоть до посинения — у неё нет внешних зависимостей кроме параметров. А когда она оттестирована, то нет смысла заменять её на стаб — это повлечет больш проблем в случае изменений в коде. Тесты будут проходить со стабом, когда по идее они проходить уже не должны будут.
function getFirstMass(F, R, m2)
{
return F / (G * (m2 / pow(R, 2));
}
можно тестировать хоть до посинения — у неё нет внешних зависимостей кроме параметров. А когда она оттестирована, то нет смысла заменять её на стаб — это повлечет больш проблем в случае изменений в коде. Тесты будут проходить со стабом, когда по идее они проходить уже не должны будут.
Вы плохо уяснили себе что такое юнит тесты и путаете их с интеграционным тестированием.
В любом случае, ваш вариант приемлем только если getFirstMass объявлена как private, т.к. только так вы можете гарантировать, что она более нигде не используется. В противном случае должна быть возможность её изоляции.
В любом случае, ваш вариант приемлем только если getFirstMass объявлена как private, т.к. только так вы можете гарантировать, что она более нигде не используется. В противном случае должна быть возможность её изоляции.
Я хорошо уяснил, хотя бы потому, что написал, что необходимости заменять её нет. Как нет, например, необходимости стабировать детерминированные функции стандартной библиотеки ЯП.
А про private, гарантии и изолированность я что-то не понял. Во-первых, это функция, а не метод (можно переписать её как метод объекта, моделирующего сущность «второе тело», «сила» или даже «дистанция», но пока необходимость этого ни из чего не следует). Во-вторых, зачем нам гарантировать, что она ниоткуда не вызывается? Наоборот она написана для использования в любых контекстах — нужно посчитать массу планеты по солнцу — пожалуйста, нужно наоборот — тоже, можно считать массу двух кораблей, можно двух звезд, можно галактики и пылинки. Объясните, от кого и зачем её изолировать?
А про private, гарантии и изолированность я что-то не понял. Во-первых, это функция, а не метод (можно переписать её как метод объекта, моделирующего сущность «второе тело», «сила» или даже «дистанция», но пока необходимость этого ни из чего не следует). Во-вторых, зачем нам гарантировать, что она ниоткуда не вызывается? Наоборот она написана для использования в любых контекстах — нужно посчитать массу планеты по солнцу — пожалуйста, нужно наоборот — тоже, можно считать массу двух кораблей, можно двух звезд, можно галактики и пылинки. Объясните, от кого и зачем её изолировать?
НЛО прилетело и опубликовало эту надпись здесь
Аналогия с духами очень даже хороша.
А вот читать лишь комментарии и не смотреть код просто невозможно, ибо комментарии часто врут и ещё чаще недоговаривают. Скорее уж надо взять за правило смотреть только код, а комментарии вообще не читать. Чего их читать, если это по-любому ненадёжный источник информации?
А вот читать лишь комментарии и не смотреть код просто невозможно, ибо комментарии часто врут и ещё чаще недоговаривают. Скорее уж надо взять за правило смотреть только код, а комментарии вообще не читать. Чего их читать, если это по-любому ненадёжный источник информации?
Код тоже ненадежный источник информации. Мы видим, что есть, но не видим, что должно быть. А тот, кто не синхронизирует комментарии с кодом из-за лени, ещё вероятней не будет синхронизировать именование функций/методов и их внутреннюю логику, поскольку это требует дополнительных действий.
МкКоннел с вами не согласен :)
Он как раз говорит о том, что код единственное, что всегда будет, даже когда нет ни ТЗ, ни тестов, ничего другого.
Комментарии это как документация — отличная вещь, но очень легко может разойтись с кодом (Вася изменил код, но забыл поправить комментарии). Именно это и есть основное преимущество самодокументирующегося кода. Другое дело, что Вася может забыть поправить название — но именно то, что название обычно одна строчка выгоднее отличается от комментариев (которых обычно приходиться писать пару строк с объяснением алгоритма) — больше вероятность, что Вася это поправит либо сделает изменения в рамках того, что описывает название метода.
Он как раз говорит о том, что код единственное, что всегда будет, даже когда нет ни ТЗ, ни тестов, ничего другого.
Комментарии это как документация — отличная вещь, но очень легко может разойтись с кодом (Вася изменил код, но забыл поправить комментарии). Именно это и есть основное преимущество самодокументирующегося кода. Другое дело, что Вася может забыть поправить название — но именно то, что название обычно одна строчка выгоднее отличается от комментариев (которых обычно приходиться писать пару строк с объяснением алгоритма) — больше вероятность, что Вася это поправит либо сделает изменения в рамках того, что описывает название метода.
Я считаю комментарии частью исходного кода. В этом их плюс по сравнению с другими видами документации — они от исполняемого кода просто неотделимы. Если у нас только исполняемый код в исходном, то для самодокументации последнего нам придется вводить или множество уровней абстракций, или давать длинные (очень!) имена. Ни то, ни другое, читаемость не повышает, по-моему. Куда проще использовать короткое и говорящее в рамках текущего контекста имя, а нюансы его реализации, выходящие за обычный контекст его использования, описать в месте его объявления. Пример — в месте использования достаточно написать sort(array), а уж в объявлении sort описать в комментариях какой алгоритм сортировки используется и почему именно он. Чаще всего такая информация в месте использования (каждом!) будет лишней.
Да, но Васе потребуется поправить название тоже в минимум двух строчках (объявление и использование), причём зачастую сильно разнесенных в проекте, а то и перекомпилировать и пересобирать проект целиком. Что-то мне подсказывает, что проще изменить в одном месте комментарий.
Да, но Васе потребуется поправить название тоже в минимум двух строчках (объявление и использование), причём зачастую сильно разнесенных в проекте, а то и перекомпилировать и пересобирать проект целиком. Что-то мне подсказывает, что проще изменить в одном месте комментарий.
То что вы сейчас описали как раз явный пример проблемы внешних зависимостей (когда важно только имя Sort, а нюансы реализации для понимания метода неважны), которые решаются вполне конкретным методом — Dependency Injection.
Я согласен, что длинное название не выход, но и комментарии — тоже «костыль» в данном случае. На мой взгляд в этом случае DI наиболее правильный «инструмент».
Я согласен, что длинное название не выход, но и комментарии — тоже «костыль» в данном случае. На мой взгляд в этом случае DI наиболее правильный «инструмент».
Проблему видите только вы. Зависимость есть, а проблемы нет. Так бывает :) Вводить DI ради предположения «а вдруг когда-нибудь нам не просто нужно будет заменить реализацию сортировки, но и динамически использовать то одну, то другую» — по-моему, типичный случай преждевременной оптимизации расширяемости. Когда возникнет такая необходимость, тогда и введу. Жесткие зависимости затрудняют рефакторинг и тестирование, но слабо в целом влияют на читаемость, а вот DI читаемость затрудняет — тело функции будет содержать код к логике её работы не относящийся.
DI уменьшает связанность кода. Это необходимое условие для юнит тестов.
Если у вас не стоит и не будет стоять задача написать юнит тесты на ваш код — тогда это другое дело и можно писать как угодно, даже без комментариев, ведь отказываясь от юнит тестов вы подразумеваете, что ваш код корректен и изменять его в будущем никто не будет и, значит, смотреть и понимать его никому не нужно. Это случай тривиальных программ. Я же рассуждаю о более сложных ООП программах. Там нужно сразу закладывать DI, т.к. внедрение его постфактум та ещё задачка.
А то, что таким способом (DI, SRP) можно как правило не писать комментарии, т.к. код становится самодокументируемым — это уже полезная «плюшка». Если развернуть это предложение в обратную сторону, то самодокументированный код это предпосылка для DI и SRP, о чём примерно автор стать и пытался донести, как мне кажется.
Если у вас не стоит и не будет стоять задача написать юнит тесты на ваш код — тогда это другое дело и можно писать как угодно, даже без комментариев, ведь отказываясь от юнит тестов вы подразумеваете, что ваш код корректен и изменять его в будущем никто не будет и, значит, смотреть и понимать его никому не нужно. Это случай тривиальных программ. Я же рассуждаю о более сложных ООП программах. Там нужно сразу закладывать DI, т.к. внедрение его постфактум та ещё задачка.
А то, что таким способом (DI, SRP) можно как правило не писать комментарии, т.к. код становится самодокументируемым — это уже полезная «плюшка». Если развернуть это предложение в обратную сторону, то самодокументированный код это предпосылка для DI и SRP, о чём примерно автор стать и пытался донести, как мне кажется.
Не необходимое, а упрощающее их создание в теории. На практике же многое зависит от используемого ЯП и конкретной реализации DI, а так же тестирующего фреймворка. Иногда проще подменить файл с классом, от которого у тестируемого модуля жесткая зависимость, чем инициализировать её средствами DI-контейнера.
Никак, по-моему, самодокументируемость и DI/SRP не связаны. Мы с ними можем надавать «обфусцированные» имена сущностям, так, что никакие комментарии не помогут, а можно без них написать самодокументируемый код (в простых случаях, конечно, или этот код будет хоть и самодокументированным, но нечитаемым из-за идентификаторов на 500+ символов).
Никак, по-моему, самодокументируемость и DI/SRP не связаны. Мы с ними можем надавать «обфусцированные» имена сущностям, так, что никакие комментарии не помогут, а можно без них написать самодокументируемый код (в простых случаях, конечно, или этот код будет хоть и самодокументированным, но нечитаемым из-за идентификаторов на 500+ символов).
Код тоже ненадежный источник информации.
Вот это уже смешно!
Код — единственный надёжный источник информации! Только в коде мы видим, как есть.
А как «должно быть» — этого до конца не знает никто, включая заказчика.
от, кто не синхронизирует комментарии с кодом из-за лени, ещё вероятней не будет синхронизировать именование функций/методов и их внутреннюю логику, поскольку это требует дополнительных действий.
Ровно наоборот, синхронизовать названия переменных, функций и классов гораздо проще, ибо все современные IDE умеют делать это автоматически. При любом рефакторинге автоматически меняют все нужные названия. А вот синхронизовать комментарии никакие IDE не умеют и никогда не научатся.
Похоже, вы просто не доверяете IDE и пытаетесь вручную (в комментариях) делать ту работу, которую IDE умеют делать автоматически.
Код — единственный надёжный источник информации! Только в коде мы видим, как есть.
А как «должно быть» — этого до конца не знает никто, включая заказчика.
Мы должны принимать решения «баг или фича», то как есть, на основании чего-то. И определяющим является мнение заказчика. А без фиксации этого мнения в коде мы вполне можем якобы починив баг выпилить, по мнению заказчика, киллер-фичу его бизнеса.
Ровно наоборот, синхронизовать названия переменных, функций и классов гораздо проще, ибо все современные IDE умеют делать это автоматически. При любом рефакторинге автоматически меняют все нужные названия.
Речь не о рефакторинге, а модификациях. При рефакторинге и комментарии изменять не требуется в целом. А вот если мы модифицируем код, изменяя его поведение, то нам нужно изменить имя сущности и/или комментарии к ней. Если мы не пользуемся комментариями, то имя сущностей типа методов или функций придется менять практически при каждом изменении (мы же стараемся передать в имени всю необходимую программисту информацию о сущности? и получаем «хрупкие» имена). В случае же использования комментариев для документирования той информации которая нужна много реже краткого названия, отражающего только базовую информацию, а не нюансы, у нас больше пространство изменений не требующих переименований, а значит и помощи со стороны IDE/
Вы сейчас говорите странную вещь. Если меняются требования, то Вы считаете, что лучше, чтобы это не отражалось на именах в коде, а менять только комментарии?
Я, лично, вообще не вижу никаких проблем менять имена функциям хоть каждые полчаса. Есть только нюансы с коллективной работой. Но то — проблемы индейцев, организационные вопросы должны мало отражаться на коде и не заставлять писать говнокод. Те вопросы решаются другими путями.
А еще, есть одна мысль, которую я не сказал, но и нигде здесь не прочитал. Любая документация, отличающаяся от кода, будь-то комментарии, будь-то схемы или любые другие файлы — совсем не очевидно, что помогает вообще, если брать в перспективе. Код — единственная вещь, которая говорит, как оно на самом деле сделано. И сколько я не разбирался с чужим кодом, всегда наступал момент, когда приходилось сесть и основательно просмотреть код. Т.е. если у Вас есть документация, то читаете ее. Редко видел ее полезной. Но допустим. Эта полезность выльется в то, что Вы себе представите как оно приблизительно работает. Но с такими знаниями лезть в код и что-то менять — дико опасно. Если допустим разовое изменение и забыли, возможно такой способ подойдет. Но не помню ни разу, чтобы так всё и происходило. Если Вы сейчас потратите полдня разбираясь с каким-то модулем в коде, а не 15 минут, то в перспективе Вы эти полдня не потратили зря, Вы уже знаете этот модуль изнутри. При следующих разах Вы уже будете значительно экономить время.
Вот поэтому гораздо важнее читаемость кода.
Я, лично, вообще не вижу никаких проблем менять имена функциям хоть каждые полчаса. Есть только нюансы с коллективной работой. Но то — проблемы индейцев, организационные вопросы должны мало отражаться на коде и не заставлять писать говнокод. Те вопросы решаются другими путями.
А еще, есть одна мысль, которую я не сказал, но и нигде здесь не прочитал. Любая документация, отличающаяся от кода, будь-то комментарии, будь-то схемы или любые другие файлы — совсем не очевидно, что помогает вообще, если брать в перспективе. Код — единственная вещь, которая говорит, как оно на самом деле сделано. И сколько я не разбирался с чужим кодом, всегда наступал момент, когда приходилось сесть и основательно просмотреть код. Т.е. если у Вас есть документация, то читаете ее. Редко видел ее полезной. Но допустим. Эта полезность выльется в то, что Вы себе представите как оно приблизительно работает. Но с такими знаниями лезть в код и что-то менять — дико опасно. Если допустим разовое изменение и забыли, возможно такой способ подойдет. Но не помню ни разу, чтобы так всё и происходило. Если Вы сейчас потратите полдня разбираясь с каким-то модулем в коде, а не 15 минут, то в перспективе Вы эти полдня не потратили зря, Вы уже знаете этот модуль изнутри. При следующих разах Вы уже будете значительно экономить время.
Вот поэтому гораздо важнее читаемость кода.
Когда меняются не функциональные требования (не пользовательские сценарии), а, скажем, требования к производительности или к системе хранения, то зачем меня сигнатуры методов, если они были достаточно общими, типа sort(array) или load(id)? была у нас сортировка пузырьком, а стала каким-нибудь серобуромалиновым деревом — почему сигнатуры должны меняться? Или была загрузка данных по id из файла, а стала из БД — аналогично?
Вы когда нибудь разбирались с кодом со сложными алгоритмами обработки, о которых вы представления не имеете? Всё что у вас есть — код и «ощущение» заказчика типа «чаще всего нормально работает, но вот пару скриншотов с аномальными данными — такого не может быть потому что не может быть никогда, предыдущая команда придумала формулы, но что-то они похоже напутали, а у меня копий этих формул нет». И приходится восстанавливать эти формулы по коду, понятия не имея как оно должно быть, всё что есть «тут вроде бы нормально, а тут — нет». Вот есть в коде, например, вроде перемножение матриц, но не чисто оно, а что-то похожее и сидишь гадаешь то ли баг, то ли фича.
Или вон выше привели пример «самодокументированного» кода.
Сложно вот так вот сходу сказать, что это за формула, откуда она взялась и без ошибок ли она записана, особенно если физику не любил или не изучал.
Вы когда нибудь разбирались с кодом со сложными алгоритмами обработки, о которых вы представления не имеете? Всё что у вас есть — код и «ощущение» заказчика типа «чаще всего нормально работает, но вот пару скриншотов с аномальными данными — такого не может быть потому что не может быть никогда, предыдущая команда придумала формулы, но что-то они похоже напутали, а у меня копий этих формул нет». И приходится восстанавливать эти формулы по коду, понятия не имея как оно должно быть, всё что есть «тут вроде бы нормально, а тут — нет». Вот есть в коде, например, вроде перемножение матриц, но не чисто оно, а что-то похожее и сидишь гадаешь то ли баг, то ли фича.
Или вон выше привели пример «самодокументированного» кода.
function getMassFromForcePlanetMassAndRadius(force, planetMass, radius) {
return force / (G * (planetMass / pow(Radius, 2))
}
Сложно вот так вот сходу сказать, что это за формула, откуда она взялась и без ошибок ли она записана, особенно если физику не любил или не изучал.
Имена методов должны меняться там, где они должны. Если у Вас метод загрузки из некоторого абстракного хранилища, может БД, может файлов, может еще чего, то имя метода Load говорит только, что это загрузка. И очень странно было бы, если бы Вы подменив загрузку из базы, на загрузку из файлов, именно в этом методе изменили только аннотацию, не меняя имя. Либо имя меняется и аннотация, если есть, либо ни то ни другое. Внутри метода может быть вы делегируете работу методу LoadFromFile. Но это внутри.
По поводу Вашего примера с комментарием и физикой и всеми примерами, которые проводили, у меня свое мнение. Развожу руки. Любой из вариантов подойдет.
Во-первых, подойдет Ваш первоначальный вариант, только без комментария. Ваш комментарий говорит довольно очевидные для школьника вещи. Интересно, что за программист читает код и не знает второго закона Ньютона и закона всемирного тяготения. Даже если так, то код не обязан быть учебником по предметной области. Иначе, в коде можно еще и научить задачки решать детей.
В любой области код. Будете писать код для, например, юристов, не надо в коде расшифровывать юридические термины. Будете писать код для какой-то электроники, не нужно в коде обучать законам Кирхгофа.
Я считаю, что код не должен читать человек, который не знает языка программирования и который не знает предметной области. Код — не учебник по этим вещам. Код создает нечто новое на стыке этих известных до этого кода знаний. И если человек не обладает знаниями языка программирования (ему разжевывают в комментариях), или не имеет минимальных представлений о предметной области — то и читать код ему не зачем, чем меньше он знает о коде и где он лежит, тем лучше для кода.
Но там, в принципе, Вы сами решаете, какая публика читать будет код. Маленький комментарий может и не помешает.
Точно также я не вижу ничего плохого в том, что Вам ответили, разные варианты. Чем Вам не нравится этот пример кода функции? Читается слева направо без проблем. Имена должны быть понимаемыми. В такой последовательности выбирается:
1. Короткое понятное имя лучше длинного понятного.
2. Длинное понятное лучше (гораздо) короткого непонятного.
Поэтому, не вижу никаких проблем с длинным именем.
Хотя, я бы именно
не стал так называть. Есть разные т.з. на формальные параметры. Часто считается, что они вообще локальные и извне их не видно. И да, скорее всего будут передаваться либо числами константами в каком-то порядке, либо внешними переменными с другими именами.
Но все же, я считаю, что лучше сократить имя:
Т.е. имена параметров уже говорят из чего будет производиться вычисление. И если не числа хардкодом передавать в вызовах, а называть адекватно переменные, код будет читаться.
По поводу Вашего примера с комментарием и физикой и всеми примерами, которые проводили, у меня свое мнение. Развожу руки. Любой из вариантов подойдет.
Во-первых, подойдет Ваш первоначальный вариант, только без комментария. Ваш комментарий говорит довольно очевидные для школьника вещи. Интересно, что за программист читает код и не знает второго закона Ньютона и закона всемирного тяготения. Даже если так, то код не обязан быть учебником по предметной области. Иначе, в коде можно еще и научить задачки решать детей.
В любой области код. Будете писать код для, например, юристов, не надо в коде расшифровывать юридические термины. Будете писать код для какой-то электроники, не нужно в коде обучать законам Кирхгофа.
Я считаю, что код не должен читать человек, который не знает языка программирования и который не знает предметной области. Код — не учебник по этим вещам. Код создает нечто новое на стыке этих известных до этого кода знаний. И если человек не обладает знаниями языка программирования (ему разжевывают в комментариях), или не имеет минимальных представлений о предметной области — то и читать код ему не зачем, чем меньше он знает о коде и где он лежит, тем лучше для кода.
Но там, в принципе, Вы сами решаете, какая публика читать будет код. Маленький комментарий может и не помешает.
Точно также я не вижу ничего плохого в том, что Вам ответили, разные варианты. Чем Вам не нравится этот пример кода функции? Читается слева направо без проблем. Имена должны быть понимаемыми. В такой последовательности выбирается:
1. Короткое понятное имя лучше длинного понятного.
2. Длинное понятное лучше (гораздо) короткого непонятного.
Поэтому, не вижу никаких проблем с длинным именем.
Хотя, я бы именно
function getMassFromForcePlanetMassAndRadius(force, planetMass, radius)
не стал так называть. Есть разные т.з. на формальные параметры. Часто считается, что они вообще локальные и извне их не видно. И да, скорее всего будут передаваться либо числами константами в каком-то порядке, либо внешними переменными с другими именами.
Но все же, я считаю, что лучше сократить имя:
function getBodyMass(gravityForce, planetMass, distanceFromBodyToPlanetCentre)
Т.е. имена параметров уже говорят из чего будет производиться вычисление. И если не числа хардкодом передавать в вызовах, а называть адекватно переменные, код будет читаться.
Я считаю, что код не должен читать человек, который не знает языка программирования и который не знает предметной области. Код — не учебник по этим вещам. Код создает нечто новое на стыке этих известных до этого кода знаний. И если человек не обладает знаниями языка программирования (ему разжевывают в комментариях), или не имеет минимальных представлений о предметной области — то и читать код ему не зачем, чем меньше он знает о коде и где он лежит, тем лучше для кода.
Весьма и весьма спорное мнение. Код, конечно, не должен быть учебником предметной области, но считать, что все её должны знать на уровне не меньшем, чем сам автор, несколько опрометчиво, по-моему. И, немаловажно, что в конструкциях языка суметь её разглядеть тоже не каждый сможет. Код не учебник, но и чтение кода не викторина и не экзамен.
Плюс проблемы перевода, когда заказчик и исполнитель общаются на одном языке, а в коде употребляется другой. Получается и автор, и читатели должны не просто предметной рбластью владеть, но и уметь переводить в обе стороны.
Для таких вещей вот как раз и есть документация. Это не документация по коду. А какая-то вводная, курс молодого бойца по предметной области для программистов.
Программисты — это такие люди, которые как бы обязаны знать предметную область. Только таких программистов почти нет. Не учат программированию со смежными специальностями. Я закончил физ-мат, физик, поэтому может удивительно, что люди закон всемирного тяготения не знают, хоть он и из школьного курса.
Т.е. как переводчик, он должен знать язык, с которого переводит. Знание программирования недостаточно. Иначе такой программист может писать программы только для программистов.
Как выход из ситуации — программист должен иметь хорошую математическую и другие базы, чтобы уметь быстро вникнуть в предметную область.
Это в идеале и может быть мои знания в этом устарели. Может быть уже ничего и знать не должен, а уметь на стартаптусовках пиариться ))
Программисты — это такие люди, которые как бы обязаны знать предметную область. Только таких программистов почти нет. Не учат программированию со смежными специальностями. Я закончил физ-мат, физик, поэтому может удивительно, что люди закон всемирного тяготения не знают, хоть он и из школьного курса.
Т.е. как переводчик, он должен знать язык, с которого переводит. Знание программирования недостаточно. Иначе такой программист может писать программы только для программистов.
Как выход из ситуации — программист должен иметь хорошую математическую и другие базы, чтобы уметь быстро вникнуть в предметную область.
Это в идеале и может быть мои знания в этом устарели. Может быть уже ничего и знать не должен, а уметь на стартаптусовках пиариться ))
Э… Я в крайности не бросаюсь. Почти в каждом (здесь) комментарии писал: комментарии — худшее средство (или последнее средство) улучшения читаемости кода. Т.е. запасное, на всякий самый плохой случай. Но если код не читается даже при применении всех техник или если его нельзя делать читаемым ввиду оптимизации, то комментарии пишутся. Комментариев должно быть как можно меньше. Но только за счет хорошего кода. А не принципиально не писать.
Еще есть комментарии, которые просто дублируют код :) Для тех, кто не знает данный ЯП, наверное
Один совет только может быть — всего должно быть в меру.
Можно почитать С. Макконнелл «Совершенный код», 764 — 797 стр., всё хорошо написано.
Можно почитать С. Макконнелл «Совершенный код», 764 — 797 стр., всё хорошо написано.
Отдельно надо отметить, что когда вы пишите что-то совсем не стандартное(или что-то сложное), надо документировать не каждую строку, но каждое изменение действия.
Так, к примеру, я шизел, когда разбирал как вычисляются столкновение двух тел.
из видимого — изменяются скорости.
Но когда я полез в код…
Сперва вычисляется с какой энергией происходит столкновение, потом вычисляется какая из этой энергии тратится не на изменение скоростей: на нагрев, деформацию и что-то еще, до конца так и не разобрался (но в состояние объекта это все не уходит), и только потом оставшаяся энергия собственно и переводится в изменение координат.
Если бы каждый блок изменений был бы подписан, у меня на анализ функции ушло бы минут двадцать. А так я потратил на это три-четыре часа.
Так, к примеру, я шизел, когда разбирал как вычисляются столкновение двух тел.
из видимого — изменяются скорости.
Но когда я полез в код…
Сперва вычисляется с какой энергией происходит столкновение, потом вычисляется какая из этой энергии тратится не на изменение скоростей: на нагрев, деформацию и что-то еще, до конца так и не разобрался (но в состояние объекта это все не уходит), и только потом оставшаяся энергия собственно и переводится в изменение координат.
Если бы каждый блок изменений был бы подписан, у меня на анализ функции ушло бы минут двадцать. А так я потратил на это три-четыре часа.
Иногда код читают люди, которым лень/нет времени разбираться. Им комментарии очень помогают. Особенно если комментарии выполнены в стиле JDK: четыре страницы человеческого текста документации на три строчки кода. Когда дочитаешь документацию, что там написано в коде будет уже самоочевидно.
Такой объем коментариев, что даже не знаю, прочтут ли эти строчки.
Автора полностью поддерживаю. В моем любимом obj-c написанию кода без коментариев способствует наличие имен у аргументов метода, например
А вообще идея автора была уже описана в замечательной книге Clean Code, всем рекомендую.
Автора полностью поддерживаю. В моем любимом obj-c написанию кода без коментариев способствует наличие имен у аргументов метода, например
[theCar openDoor:kLeftDoor withKey:momsKey howFast:kVerySlow];, где openDoor:withKey:howFast: — селектор, он же имя метода. Такой код в разы читабельней класической нотации funcName(arg1,arg2,arg3), тк не нужно дергать IDE чтобы узнать, зачем нужен каждый аргумент, при плохом наименовании переменных.А вообще идея автора была уже описана в замечательной книге Clean Code, всем рекомендую.
Насчёт javadoc'ов: как бы мы жили без документации на стандартную java-библиотеку? А ведь она оформлена в виде javadoc'а. Для меня это образец подхода к документированию, и я стремлюсь ему следовать.
И вообще чувстствуется, что автор — не читатель, автор — писатель. Дали бы ему в зубы 100000 строк без единого комментария — посмотрел бы я на него.
И вообще чувстствуется, что автор — не читатель, автор — писатель. Дали бы ему в зубы 100000 строк без единого комментария — посмотрел бы я на него.
Про документирование API и библиотечного кода для публичного использования — это отдельная песня. И часто документируют его потому, что в исходники по идее может даже не быть возможности заглянуть и разобраться. Плюс много людей должны быстро понимать для чего создан какой-то класс, функция или метод. К вашему внутреннему коду далеко не всегда предъявляются такие же требования, поэтому детальное документирование излишне для большей части проектов. Особенно для внутренних реализаций, которые склонны к частым изменениям.
Начали за здравие… итд.
Примеры в статье хорошие, вполне. Но код, где сигнатуры не описаны- это вряд ли хороший индустриальный код. Даже если он не является публичным, еще не известно, сколько человек после вас будут его допиливать. Да и автору кода придется возвращаться к нему снова и снова. И это еще не все.
Здесь проблема более глубокая. Установки вида «мы будем писать комментарии всегда, кроме случаев А, Б, В, а тот ли это случай или не тот, мол, на усмотрение девелопера» — это методологически неправильные установки при определенных условиях. Кто работал в команде, где много джуниоров, думаю, понимают, о чем я говорю. Код там не только требует изрядных рефакторингов, непонятен, а когда он еще и плохо документирован, единственное спасение тут заставлять комментировать абсолютно все интерфейсы, public методы итд…
Примеры в статье хорошие, вполне. Но код, где сигнатуры не описаны- это вряд ли хороший индустриальный код. Даже если он не является публичным, еще не известно, сколько человек после вас будут его допиливать. Да и автору кода придется возвращаться к нему снова и снова. И это еще не все.
Здесь проблема более глубокая. Установки вида «мы будем писать комментарии всегда, кроме случаев А, Б, В, а тот ли это случай или не тот, мол, на усмотрение девелопера» — это методологически неправильные установки при определенных условиях. Кто работал в команде, где много джуниоров, думаю, понимают, о чем я говорю. Код там не только требует изрядных рефакторингов, непонятен, а когда он еще и плохо документирован, единственное спасение тут заставлять комментировать абсолютно все интерфейсы, public методы итд…
Сигнатуры — тоже код. Аннотации — тоже комментарии и на них распространяются те же аргументы. Как думаете, насколько информативно такое комментирование?
Ответ — ни насколько. Думаете это рафинированная ситуация? Отнюдь. При нормальном наименовании переменных, имен методов, параметров, комментировать практически везде бессмысленно.
Другое дело, что совсем иногда, когда какая-то хитрость и нельзя очевидным образом ее в коде выразить — тогда и комментируем. Понимая, что зло как раз в хитрости и вы сдаетесь, пытаясь прикрыть ее комментарием как фиговым листочком.
/// <summary>
/// Adds Person
/// </summary>
/// <param name="age">Age of Person</param>
/// <param name="phoneNumber">Phone Number of Person</param>
void AddPerson(int age, string phoneNumber)Ответ — ни насколько. Думаете это рафинированная ситуация? Отнюдь. При нормальном наименовании переменных, имен методов, параметров, комментировать практически везде бессмысленно.
Другое дело, что совсем иногда, когда какая-то хитрость и нельзя очевидным образом ее в коде выразить — тогда и комментируем. Понимая, что зло как раз в хитрости и вы сдаетесь, пытаясь прикрыть ее комментарием как фиговым листочком.
С одной стороны, действительно малоинформативно. Хотя если бы там стояло «Age of Person in days», у пользователя не возникло бы лишнего вопроса. Но когда какой-нибудь энтузиаст создания автодокументации включил соответствующие warnings на отсуствие summary, а другой энтузиаст чистого кода требует, чтобы в промежуточных версиях предупреждений не было вообще — то ничего не остаётся, как писать тысячи таких вот бессмысленных заголовков. А потом учиться не видеть их, чтобы можно было нормально читать код.
Если так, то переменная и должна назваться ageOfPersonInDays. Если в примере написали код, оставив переменную с названием age, а написал, что она в днях, то здесь и кроется ошибка программиста. В том то и зло комментариев, что они скрывают говнокод.
Язык программирования первичен и именно на нем по возможности надо выражать мысли, а не в комментариях.
Какие еще могут быть хитрости у этого метода? Иногда нужна аннотация из-за невыразительности некоторых аспектов языка. Например, это был C# и там как-то в сигнатуре нельзя указать, какой эксепшин будет.
Может быть int не подходит, т.к. отрицательные значения имеет. Опять же, смотрим на эту ситуацию и сразу думаем о коде, потом о комментариях. Если в коде, то есть uint. Если надо любое число, до секунд, с отсутствием отрицательных значений, то опять же, глупо внутри городить проверки и эксепшины и описывать их в комментарии — можно ввести специальный тип Age. То же и с телефоном.
Язык программирования первичен и именно на нем по возможности надо выражать мысли, а не в комментариях.
Какие еще могут быть хитрости у этого метода? Иногда нужна аннотация из-за невыразительности некоторых аспектов языка. Например, это был C# и там как-то в сигнатуре нельзя указать, какой эксепшин будет.
Может быть int не подходит, т.к. отрицательные значения имеет. Опять же, смотрим на эту ситуацию и сразу думаем о коде, потом о комментариях. Если в коде, то есть uint. Если надо любое число, до секунд, с отсутствием отрицательных значений, то опять же, глупо внутри городить проверки и эксепшины и описывать их в комментарии — можно ввести специальный тип Age. То же и с телефоном.
Да не о том речь же. Ваш пример понятен, но принцип единообразия — это очень важный принцип. Если у вас одни методы комментированы, другие нет — это создает нехорошие соблазны для команды.
это создает нехорошие соблазны для команды
Соблазн не писать ерунду? Или если заставлять писать ерунду, то везде?
Методы с аннотацией ни на один бит не более документированы, чем методы без аннотации, если там тупо повторение названия методов и переменных.
Мы исходим из разных положений. Вы по-умолчанию считаете, что комментарии — это хорошо. Поэтому видимо такой вывод: создает нехорошие соблазны их не писать.
Я же думаю наоборот. Иногда комментарии полезны. Ну не сверхчеловек я, точнее, не сверхпрограммист. Чтобы смысл идеально закодить, чтобы код читался как книга, был кратким, ясным, лаконичным. И вот тогда появляются комментарии — как признание своего поражения. Иногда пишу аннотацию. Но только на тот параметр, который непонятен. Например, возврат булевского значения, а имя метода и так перегружено, чтобы понять, что значит истина, что ложь. Когда редко появляется комментарий, то он становится более полезным на фоне их отсутствия. Он больше притягивает внимание. Зачем писать бесполезный мусор? Это анти-DRY. Потом, при любом рефакторинге в смысле переименования (из другого места в коде), добавления переменных, изменения интерфейсов — аннотации устаревают и вводят в заблуждение.
Недавно писал сравнительно большой проект. Он зависел не только от моего кода, но была уже БД, поэтому был местами связан с кривым кодом. Пришлось писать комментарии в местах, чтобы пояснить, почему я так нестандартно написал код.
Комментария было за всё время штук 10. Но они так быстро устаревали, еще до того, как я класс допишу. В итоге осталось штук 2 комментария.
Да, и аннотации — это еще вопрос стиля, принятого в команде. Вообще, тут не о чем спорить, писать их не так напряжно. А для библиотек для внешнего использования может быть даже соглашусь с натяжкой, что нужны. Ну там, в док-файл выгрузить, схемы построить.
Почитайте этот код: github.com/antirez/redis/blob/unstable/src/replication.c А потом представьте что он без единого комментария, а вам нужно исправить в нём багу.
Хороший код. Не знаю, зачем писали
вместо
но автору виднее.
Чтобы разобраться, надо знать предметную область… но то, в одной из первых функций не контролируется длина буфера, в который идёт копирование, видно и так. Хотя, возможно, что «64 килобайта хватит всем» там общее знание.
b[0] = '\r';
b[1] = '\n';
b += 2;
вместо
*b++='\r';
*b++='\n';
но автору виднее.
Чтобы разобраться, надо знать предметную область… но то, в одной из первых функций не контролируется длина буфера, в который идёт копирование, видно и так. Хотя, возможно, что «64 килобайта хватит всем» там общее знание.
Не очень понял вашу точку зрения относительно комментариев и примера. Вы считаете что этот код не очень хороший и его надо отрефакторить (комментарии не нужны)? Или вы считаете что и так всё понятно (комментарии не нужны)?
b[0] = '\r'; читается лучше чем *b++='\r' и работает быстрее.
Если вы нашли багу с переполнением буфера — пофиксите или зарепортите.
По поводу знания предметной области — согласен, но этого не достаточно (у вас никогда не будет такого набора знаний как у человека, который пишет код, поэтому решения, очевидные для него могут быть не очевидны для вас, и наоборот — какая-та часть кода, которую вы написали бы оптимально, автор кода написал не оптимально — возможно он просто не знает оптимальный способ, а возможно на то были причины, которые сложно определить только исходя из кода).
b[0] = '\r'; читается лучше чем *b++='\r' и работает быстрее.
Если вы нашли багу с переполнением буфера — пофиксите или зарепортите.
По поводу знания предметной области — согласен, но этого не достаточно (у вас никогда не будет такого набора знаний как у человека, который пишет код, поэтому решения, очевидные для него могут быть не очевидны для вас, и наоборот — какая-та часть кода, которую вы написали бы оптимально, автор кода написал не оптимально — возможно он просто не знает оптимальный способ, а возможно на то были причины, которые сложно определить только исходя из кода).
Вы же сказали — «представьте, что он без единого комментария», поэтому я комментариев не читал. И код при этом мне показался хорошим. По ощущениям, если знать, к чему всё это вообще относится, и какие там правила игры, то понять его было бы не сложно.
Насчет того, что лучше читается — дело вкуса. Лично мне b[0] режет глаз, особенно если b уже описан, как указатель, а не как массив (и в этом фрагменте меняется).
А в целом — проблема именно здесь: «поэтому решения, очевидные для него могут быть не очевидны для вас <...> а возможно на то были причины, которые сложно определить только исходя из кода». Чтобы в такой ситуации увидеть использовавшиеся причины, неочевидные для других, и указать в комментариях именно их (это будет самая большая возможная помощь для читателей), нужен очень высокий профессионализм.
Насчет того, что лучше читается — дело вкуса. Лично мне b[0] режет глаз, особенно если b уже описан, как указатель, а не как массив (и в этом фрагменте меняется).
А в целом — проблема именно здесь: «поэтому решения, очевидные для него могут быть не очевидны для вас <...> а возможно на то были причины, которые сложно определить только исходя из кода». Чтобы в такой ситуации увидеть использовавшиеся причины, неочевидные для других, и указать в комментариях именно их (это будет самая большая возможная помощь для читателей), нужен очень высокий профессионализм.
Эта статья по итогам прочтения книги Роберта Мартина «Чистый код»? Точнее пары первых глав.
Я уже видел подобную статью на хабре… только вот не могу вспомнить название. Может кто-нибудь вспомнит?
«Зачем дьявол придумал javadoc»: habrahabr.ru/post/97320/
Я, конечно, поплыву против течения, но для меня лично этот топик звучит примерно как
Беда в том, что как огромное количество водятлов забивает на ПДД, так и огромное количество «индусов» забивает на элементарные правила оформления кода. Когда код пишется в пределах одной конторы — да, на комментарии можно забить. Но как только вы выезжаете из двора на улицу…
«Не надо пристегиваться и устанавливать подушки безопасности»
Ведь если ездить внимательно, и соблюдать ПДД — никаких аварий не будет!
Беда в том, что как огромное количество водятлов забивает на ПДД, так и огромное количество «индусов» забивает на элементарные правила оформления кода. Когда код пишется в пределах одной конторы — да, на комментарии можно забить. Но как только вы выезжаете из двора на улицу…
Писать комменты надо, в последующем позволяет найти части кода для использования в других проектах. Обычно пишу однострочные комментарии перед ключевыми функциями: «функция изменения картинки», «функция залички файла на сервер», «функция отправки смс». Потом достаточно провести поиск текста по большому каталогу с архивами старых проектов, чтобы найти нужную функцию. Излишняя детализация комментариев в коде усложняет его чтение. Иногда, для повышения производительности, приходится изобретать нестандартные алгоритмы, которые через пару лет очень сложно разобрать. Тогда в ключевых точках алгоритма ставлю однострочные комменты, а перед самим алгоритмом описание на 2-3 строчки основных «фишек» алгоритма, которые позволят скорее понять код.
Так если функцию назвать нормально (changeImage(), uploadFile(), sendSMS()), то потом по названию «changeImage» можно точно так же найти фунцию в своём архиве. Комментарии не нужны.
А если не помните, как назвали? changeImage, или change_image, или imageChange?
Значит, понадобится 4 попытки.
Точно так же вы можете не помнить, какой написали комментарий.
Кстати, Intellij IDEA (так же как PhpStory, PyCharm, RubyMine) умеют находить функции по частичному названию, например:
Ctrl+Shift+Alt+N -> набираешь «chim» -> IDEA сама находит метод «changeImage» по нескольким буквам.
По комментариям точно никогда такого поиска не будет.
Кстати, Intellij IDEA (так же как PhpStory, PyCharm, RubyMine) умеют находить функции по частичному названию, например:
Ctrl+Shift+Alt+N -> набираешь «chim» -> IDEA сама находит метод «changeImage» по нескольким буквам.
По комментариям точно никогда такого поиска не будет.
В целом с подходом описываемом в посте согласен, но не смог дочитать пост до конца — моё изнеженное сознание не смогло переварить такого издевательства над русским языком. Прошу прощения.
Всем, кто не согласен с автором (или просто не понял что автор хотел донести) рекомендую почитать книгу Фаулера «Improving the Design of Existing Code»:

Ну только не надо тут умничать.
Вы тогда лучше на других сайтах сидите — тут люди стараются делиться более полной информацией по обсуждаемому вопросу.
«Тут» люди не любят, когда им подсовывают информацию, которая к обсуждаемому вопросу относится слабо.
Из вашего высказывания очевидно, что вы не читали эту книгу.
В статье автор немного сумбурно (на мой взгляд) пытается донести весьма важную вещь о написании SOLID кода. Наиболее удачно и понятно об этом (опять же, на мой взгляд), написал Фаулер в вышеприведённой книжке. О чём я и написал в своём комментарии для тех, кто любознателен и хочет более подробно разобраться в вопросе.
Не понимаю как это не относится к обсуждаемому вопросу. Может поясните?
В статье автор немного сумбурно (на мой взгляд) пытается донести весьма важную вещь о написании SOLID кода. Наиболее удачно и понятно об этом (опять же, на мой взгляд), написал Фаулер в вышеприведённой книжке. О чём я и написал в своём комментарии для тех, кто любознателен и хочет более подробно разобраться в вопросе.
Не понимаю как это не относится к обсуждаемому вопросу. Может поясните?
Поясню.
Во-первых, в посте ни слова про SOLID (и одного его применения), поэтому эта отсылка уже неверна.
Во-вторых, книга Фаулера — не про то, как писать код, соответствующий SOLID, а про рефакторинг, весьма узкую и специфическую дисциплину.
В-третьих, про то, про что написано в статье, существенно лучше написано у МакКоннела.
А в-четвертых, не надо отсылать к Фаулеру всех, кто не согласен с автором статьи, потому что это реальная подмена понятий.
Я вам не зря комментарием ниже задал вопрос, который вы благополучно игнорируете. Я его повторю: «в случае легаси-кода у комментариев есть преимущество перед рефакторингом: угадайте, какое?»
Во-первых, в посте ни слова про SOLID (и одного его применения), поэтому эта отсылка уже неверна.
Во-вторых, книга Фаулера — не про то, как писать код, соответствующий SOLID, а про рефакторинг, весьма узкую и специфическую дисциплину.
В-третьих, про то, про что написано в статье, существенно лучше написано у МакКоннела.
А в-четвертых, не надо отсылать к Фаулеру всех, кто не согласен с автором статьи, потому что это реальная подмена понятий.
Я вам не зря комментарием ниже задал вопрос, который вы благополучно игнорируете. Я его повторю: «в случае легаси-кода у комментариев есть преимущество перед рефакторингом: угадайте, какое?»
Во-первых, вся статья о том, что нужно более чётко следовать доктринам SOLID, т.к. в большинстве случаев (и в статье как раз об этом примеры) код с коментариями противоречит минимум SRP принципу.
Книга как раз говорит не только о том как нужно рефакторить старый код, но и зачем это делать. Но вы, видимо, не читали эту книгу и свято уверены, что поняли о чём она просто по названию. Вы неправы. И Фаулер достаточно хорошо показывает то, о чём автор пытался объяснить в статье.
Если вам претит Фаулер — ваше право. Вот только не надо пытаться свои предпочтения выдать за факты.
На ваш вопрос я могу ответить (тем, что будет сохранена и донесена информация о том, что делает код до этапа рефакторинга), но я этого не делал, т.к. считаю что вы с вашим вопросом уже отошли от темы — статья о том, как нужно писать код, а не о том, что вам досталось «в наследство» для поддержки. Мы не говорим в стиле «не можете писать SOLID, пишите хотя бы коментарии» — я с этим утверждением согласен, но мы тут говорим о том, как надо «по уму».
Книга как раз говорит не только о том как нужно рефакторить старый код, но и зачем это делать. Но вы, видимо, не читали эту книгу и свято уверены, что поняли о чём она просто по названию. Вы неправы. И Фаулер достаточно хорошо показывает то, о чём автор пытался объяснить в статье.
Если вам претит Фаулер — ваше право. Вот только не надо пытаться свои предпочтения выдать за факты.
На ваш вопрос я могу ответить (тем, что будет сохранена и донесена информация о том, что делает код до этапа рефакторинга), но я этого не делал, т.к. считаю что вы с вашим вопросом уже отошли от темы — статья о том, как нужно писать код, а не о том, что вам досталось «в наследство» для поддержки. Мы не говорим в стиле «не можете писать SOLID, пишите хотя бы коментарии» — я с этим утверждением согласен, но мы тут говорим о том, как надо «по уму».
Во-первых, вся статья о том, что нужно более чётко следовать доктринам SOLID, т.к. в большинстве случаев (и в статье как раз об этом примеры) код с коментариями противоречит минимум SRP принципу.
Это не то, о чем статья, это то, что вы в ней вычитали. Это совсем не одно и то же.
Книга как раз говорит не только о том как нужно рефакторить старый код, но и зачем это делать.
Ага. Но комментарии и SOLID тут не при чем (более того, Фаулер вообще ни разу про SOLID в этой книге не упоминает). Собственно, здесь вы и подменяете понятия.
Вот только не надо пытаться свои предпочтения выдать за факты.
Скажите, а вы читали МакКоннела? Хотя бы те 32 страницы, который у него написаны про комментирование кода?
статья о том, как нужно писать код
Нет, статья о том, когда (не) нужно комментировать код. И если вы думаете, что код комментируется только на этапе написания, то вы сильно не правы.
И да, ваш ответ неверен.
PS
Don't worry, we aren't saying that people shouldn't write comments. In our olfactory analogy, comments aren't a bad smell; indeed they are a sweet smell. The reason we mention comments here is that comments often are used as a deodorant. It's surprising how often you look at thickly commented code and notice that the comments are there because the code is bad.
[...]
A good time to use a comment is when you don't know what to do. In addition to describing what is going on, comments can indicate areas in which you aren't sure. A comment is a good place to say why you did something. This kind of information helps future modifiers, especially forgetful ones.
Это не то, о чем статья, это то, что вы в ней вычитали. Это совсем не одно и то же.
Т.е. вы теперь пытаетесь доказать мне, что моё личное мнение неверно просто потому, что оно расходиться с тем, как вы поняли эту статью? Т.е. то, что я могу неправильно понять статью это допустимо, но вы не допускаете мысли о том, что вы сами неправильно всё поняли?
Ага. Но комментарии и SOLID тут не при чем (более того, Фаулер вообще ни разу про SOLID в этой книге не упоминает). Собственно, здесь вы и подменяете понятия.
Как я уже упомянул, код напичканый комментариями в подавляющем большинстве случаев представляет собой явный пример нарушения SRP принципа и подлежит рефакторингу (к примеру, Extract Method) после которого необходимость в коментариях отпадёт сама собой.
Именно это вы и цитируете — комментарии это признаки плохого кода. Само их наличие лучше чем ничего, но это всё ещё попытка украсить плохой код (метафора про дезодорант). И появление комментариев в уже работающем коде (о чём вы упоминаете) тоже должно вас, как хорошего разработчика, насторожить — возможно, это вполне оправданно, но как правило это явный признак лени сделать сразу как надо (разнести по методам или применить другие методы рефакторинга).
Не надо оправдывать «костыли» в программе тем, что без них она бы вообще не работала и вы бы не сдали проект — все и так это понимают, но это всё равно не делает такое решение правильным.
К сожалению, я не читал предлагаемой вами книги, но я склонен допускать, что она тоже способна показать то, о чём пытался сказать автор в более понятном и развёрнутом виде. Вот только ваши «наезды» на мою точку зрения просто потому, что я указал на другую книгу мне абсолютно непонятны. У вас холивар против Фаулера чтоль?
Т.е. то, что я могу неправильно понять статью это допустимо, но вы не допускаете мысли о том, что вы сами неправильно всё поняли?
www.linorg.ru/how-to-read.html
Как я уже упомянул, код напичканый комментариями в подавляющем большинстве случаев представляет собой явный пример нарушения SRP принципа
Дался вам этот SRP… нет, не является. Комментарии в коде могут означать что угодно, от желания к излишней подробности до неудачного дизайна. Самый частый случай комментариев на моем опыте — это неудачное именование; следующий по частоте — недостаточная выразительность языка в части контрактов (попробуйте в .net без комментариев указать, какие исключения и когда бросает метод), потом — желание писать тривиальные вещи «лишь бы были комментарии», и только потом — группировка кода. И да, здесь осознанно перемешаны нужные и ненужные комментарии.
(я, естественно, не рассматриваю документирующие комментарии)
И появление комментариев в коде тоже должно вас, как хорошего разработчика, насторожить — возможно, это вполне оправданно, но как правило это явный признак лени сделать сразу как надо (разнести по методам или применить другие методы рефакторинга).
Вы знаете, что является необходимым условием для рефакторинга?
К сожалению, я не читал предлагаемой вами книги
Понятно. В этом, простите за прямоту, ваша беда. Особенно, конечно, это смешно, учитывая следующую цитату из столь любимого вами Фаулера (причем прямо из той книги, которую вы приводите): «McConnell, Code Complete [...] An excellent guide to programming style and software construction. Written before Java, but almost all of its advice applies.» Почитайте, это полезно. Внезапно узнаете, что то, что я цитирую из Фаулера — это всего лишь сокращенная (и упрощенная) версия того, что пишет МакКоннелл.
Собственно, в этом и состоит моя к вам претензия: не надо подменять понятия (комментарии vs SOLID) и книги.
www.linorg.ru/how-to-read.html
А по профилю вам 32 года… странно.
Дался вам этот SRP… нет, не является. Комментарии в коде могут означать что угодно, от желания к излишней подробности до неудачного дизайна. Самый частый случай комментариев на моем опыте — это неудачное именование; следующий по частоте — недостаточная выразительность языка в части контрактов (попробуйте в .net без комментариев указать, какие исключения и когда бросает метод), потом — желание писать тривиальные вещи «лишь бы были комментарии», и только потом — группировка кода. И да, здесь осознанно перемешаны нужные и ненужные комментарии.
(я, естественно, не рассматриваю документирующие комментарии)
А в моей практике именно такие же примеры, как и в статье — куча кода в одном методе разбито комментариями. Так что я говорю с позиции своего опыта и моя позиция, как мне кажется, совпадает с тем, о чём писал автор в статье и о чём писал Фаулер в своей книге. Вас удивляет как это так бывает, что всё не как у вас?
Вы знаете, что является необходимым условием для рефакторинга?
Причём тут это? Вы не согласны с тем, что написание коментариев в блоках кода должно вас насторожить и вы должны подумать «а не нужно ли здесь переделать код»? Ну ок, чё. Ваше право. Уровень программистов и стиль программирования у всех разный.
Понятно. В этом, простите за прямоту, ваша беда. Особенно, конечно, это смешно, учитывая следующую цитату из столь любимого вами Фаулера (причем прямо из той книги, которую вы приводите): «McConnell, Code Complete [...] An excellent guide to programming style and software construction. Written before Java, but almost all of its advice applies.» Почитайте, это полезно. Внезапно узнаете, что то, что я цитирую из Фаулера — это всего лишь сокращенная (и упрощенная) версия того, что пишет МакКоннелл.
Скажите, а где я сказал, что вы цитируете Фаулера?
Собственно, в этом и состоит моя к вам претензия: не надо подменять понятия (комментарии vs SOLID) и книги.
Ещё раз — комментарии в большинстве случаев (а особенно в тех, о чём пишется в данной статье) являются следствием нарушения SOLID принципов, а именно SRP принципа. Приведённая мною книга показывает почему так делать плохо и как это нужно исправлять. Что вас тут ещё непонятного, что вы аж попутали какие-то там понятия?
Причём тут это?
При вашем совете отрефакторить подозрительный код, конечно же.
Вы не согласны с тем, что написание коментариев в блоках кода должно вас насторожить и вы должны подумать «а не нужно ли здесь переделать код»?
Нет, не согласен.
Скажите, а где я сказал, что вы цитируете Фаулера?
Мне не нужно, чтобы вы это говорили, я и сам это знаю (а вот то, что вы не узнали цитату из приведенной вами же книги — это интересно, да).
комментарии в большинстве случаев (а особенно в тех, о чём пишется в данной статье) являются следствием нарушения SOLID принципов, а именно SRP принципа
Если бы вы написали «в большинстве случаев в моем опыте», я бы еще как-то мог согласиться. Но в общем случае — нет.
Разберем примеры в данной статье:
- // «ua.in.link.rest.server» — name of package with classes for Jersey server — нарушение SRP? Нет, просто неиспользование константы.
- // creating httpServer for url «localhost:8080» — нарушение SRP? Нет, просто дословный повтор следующей строки
- // waiting for Enter before stoping the server — нарушение SRP? Нет, просто повтор кода.
Собственно говоря, в этой статье вообще SRP не трогается, потому что
main как делала несколько вещей, так продолжает их делать, количество ответственностей кода не изменилось.(Заодно я буду рад услышать, конечно же, где в «приведенной вами книге» упоминается SRP)
Понимаете ли, Фаулер пишет (к примеру):
You've probably heard that a class should be a crisp abstraction, handle a few clear responsibilities, or some similar guideline. In practice, classes grow. You add some operations here, a bit of data there. You add a responsibility to a class feeling that it's not worth a separate class, but as that responsibility grows and breeds, the class becomes too complicated. Soon your class is as crisp as a microwaved duck.
Such a class is one with many methods and quite a lot of data. A class that is too big to understand easily. You need to consider where it can be split, and you split it. A good sign is that a subset of the data and a subset of the methods seem to go together. Other good signs are subsets of data that usually change together or are particularly dependent on each other.
Если вы обратите внимание, он практически не рассуждает о критериях ответственности или связности (cohesion), он просто говорит «может возникнуть такая проблема». При этом МакКоннел рассуждает о связности на протяжении нескольких страниц, выделяя шесть, что ли, видов (дизайну классов он уделяет главу). И так везде: Фаулер просто предлагает нам типизованные решения существующих проблем дизайна, но при этом (в этой книге) не предлагает нам аппарата, объясняющего эти проблемы и способы превентивной борьбы с ними.
Я поэтому и рекомендую прочитать Code Complete прежде, чем предлагать Refactoring.
Вы не согласны с тем, что написание коментариев в блоках кода должно вас насторожить и вы должны подумать «а не нужно ли здесь переделать код»?
Прежде всего я подумаю о содержании того, что собираюсь написать в нем. Если это оправдание костылю, то комментарий будет в стиле // TODO: ..., а если это будет оправданием почему вместо принципа LIFO учёта я выбрал FIFO (пускай даже банальное «так в ТЗ было»), то напишу. Вообще, стоит, как минимум, писать вещи в комментариях, которые самого заставили задуматься, которые самому показались неочевидными, потребовали поисков информации больших чем просмотр, утрируя, сигнатур функций и методов стандартных библиотек.
И, молодой человек (раз уж вы первым перешли на возраст), мой вам совет: расширяйте кругозор и пытайтесь ограничивать область применений теорий и практик — многие их авторы исходят из принципа «разумному достаточно», а вовсе не насаждают догмы. Хотя бы по литературе рекомендуемой уважаемыми вами авторами. А то, извините, вы очень напоминаете агрессивного неофита какой-то религии.
Но вы ведь всё же задумаетесь перед написанием комментария? Вот именно об этом и весь сыр-бор — для зрелого программиста написание комментария это повод немного задуматься.
Заметьте, я нигде не говорил, что комментарий это достаточный признак «плохого кода» — это уже ваши додумки. Так что, попробуйте следовать своему совету и расширять свой кругозор и не считать всех, кто младше ваш априори менее опытными и рассудительными.
Заметьте, я нигде не говорил, что комментарий это достаточный признак «плохого кода» — это уже ваши додумки. Так что, попробуйте следовать своему совету и расширять свой кругозор и не считать всех, кто младше ваш априори менее опытными и рассудительными.
Ну да, вы подстраховались использованием фразы «код напичканый комментариями в подавляющем большинстве случаев представляет собой явный пример нарушения SRP принципа и подлежит рефакторингу (к примеру, Extract Method) после которого необходимость в коментариях отпадёт сама собой». Не достаточное условие, но в большинстве случаем, да не в простом большинстве, а в подавляющем. Не «плохой код», а должен подвергнуться рефакторингу.
и в статье как раз об этом примеры
Это просто плохие примеры. Неудачно или тендензиционно подобранные не берусь судить, но весь спектр применения комментариев они не отображают.
А чисто формально вы стали не правы, упомянув про SOLID — это принципы ООП, но всё программирование им не ограничивается, есть ещё, как минимум программирование процедурное (подмножеством которого ООП является) и функциональное (с процедурным оно, скорее, пересекается).
Наглядная демонстрация того, почему автору не надо было писать этот пост: все необходимое уже сказано у МакКоннела, Фаулера (книга которого, кстати, называется не так, как вы написали) и Мартина.
(кстати, в случае легаси-кода у комментариев есть преимущество перед рефакторингом: угадайте, какое?)
(кстати, в случае легаси-кода у комментариев есть преимущество перед рефакторингом: угадайте, какое?)
Всё верно, хороший код нуждается в минимуме комментариев, необходимых в основном для генерации документации к API и, в редких случаях, для разделения на блоки длинных функций, чтобы было проще ориентироваться. Плюс, конечно, TODO. Во всех остальных случаях комментарии не нужны либо код плохой. Мне часто приходится читать чужой код. Сначала это была самописная CMS моего товарища (написанная еще в студенческие годы, и потому довольно грустная). Никакие комментарии не спасали. Теперь это плагины к фреймворкам, созданные профессиональными программистами (зачастую весьма сырые и слабо документированные). Не знаю, кто все эти люди, написавшие код, но мы неплохо понимаем друг друга без лишних комментариев.
Вот как вы в название функции сортировки объясните, ПОЧЕМУ выбрали алгоритм сортировки, потребляющий минимум памяти?
SortWithMiniumMemoryUsingBecauseOurUsersHaveNotMoneyToBuy64GbRamServer()? Вам не кажется, что такое имя функции маразмом попахивает?Если мы говорим про ООП, то я бы вынес это в отдельную зависимость (к примеру, классы MinimumMemorySorter и MaximumPerformanceSorter) и вынес бы управление какую именно реализацию отдавать для интерфейса ISorter в конфигурацию, которую уже можно было бы «заточить» под каждого клиента.
Вы сейчас какую задачу решаете? Явно не ту, которую я пытаюсь решить введением этого имени ради отказа от комментариев.
Я решаю задачу, проблематика которой и заставила написать комментарий, а именно — особенность аппаратной конфигурации. Считаю, что подобные вещи нужно описывать в конфигурации приложения, а не хардкодить с поясняющими комментариями.
Это не особенность аппаратной конфигурации, а требование ТЗ, вызванное особенностью аппаратной конфигурации (вернее её стандартностью в виде не гигантского размера оперативки). Вы почему-то решили расширить ТЗ. В личное время и за свой счёт будете расширять? Кстати, ещё и исследования провести какой из алгоритмов сортировки на конкретных данных будет показывать максимум производительности.
А вы всё особенности железа, описанные в ТЗ хардкодите? Тогда у меня для вас плохие новости — в реальной жизни ТЗ меняются. Я уже не говорю об изменении в железе. Если, конечно, вы аутсорс контора и вам выгодно, чтобы по каждому «чиху» к вам обращались и платили бабло за «поддержку» — тогда да. Но я считаю, что создать минимум один класс и интерфейс с современными IDE задача тривиальная и не повлияет на сроки проекта.
На счёт алгоритмов — ну так у вас же уже есть «SortWithMiniumMemoryUsingBecauseOurUsersHaveNotMoneyToBuy64GbRamServer»? Значит можно минимум вынести один класс. Если потом придумаете второй (быстрый, но требовательный к памяти), то добавите и для него класс.
На счёт алгоритмов — ну так у вас же уже есть «SortWithMiniumMemoryUsingBecauseOurUsersHaveNotMoneyToBuy64GbRamServer»? Значит можно минимум вынести один класс. Если потом придумаете второй (быстрый, но требовательный к памяти), то добавите и для него класс.
Грубо говоря, только те, которые не являются параметрами алгоритмов. Если алгоритму можно указать сколько памяти он может и/или должен брать (например под кэш), то это в худшем случае будет константа, ьа скорее попадет в конфиг и/или параметр командной строки.
А кроме как минимум одного класса (хотя вы говорили о двух) нужно будет ещё реализовывать управление выбором нужного класса. Да и с одним классом заказчик может косо посмотреть на исполнителя, когда прочитает в документации что-то вроде «значение sort_method в конфигурационном файле означает используемый метод сортировки, допустимое значение только „minimum_memory“. Особенно это будет интересно, если это единственное значение в конфиге и вся подсистема работы с ним (включая логику фабрик) введена (в особых случаях написана с нуля) только ради него.
А кроме как минимум одного класса (хотя вы говорили о двух) нужно будет ещё реализовывать управление выбором нужного класса. Да и с одним классом заказчик может косо посмотреть на исполнителя, когда прочитает в документации что-то вроде «значение sort_method в конфигурационном файле означает используемый метод сортировки, допустимое значение только „minimum_memory“. Особенно это будет интересно, если это единственное значение в конфиге и вся подсистема работы с ним (включая логику фабрик) введена (в особых случаях написана с нуля) только ради него.
Грубо говоря, только те, которые не являются параметрами алгоритмов. Если алгоритму можно указать сколько памяти он может и/или должен брать (например под кэш), то это в худшем случае будет константа, ьа скорее попадет в конфиг и/или параметр командной строки.
Ну, если это константа, то она не должна зависеть от внешних факторов. А в вашем случае это диктуется железом сервера. На мой взгляд это отличный пример конфигурационной зависимости.
А кроме как минимум одного класса (хотя вы говорили о двух) нужно будет ещё реализовывать управление выбором нужного класса. Да и с одним классом заказчик может косо посмотреть на исполнителя, когда прочитает в документации что-то вроде «значение sort_method в конфигурационном файле означает используемый метод сортировки, допустимое значение только „minimum_memory“. Особенно это будет интересно, если это единственное значение в конфиге и вся подсистема работы с ним (включая логику фабрик) введена (в особых случаях написана с нуля) только ради него.
Если мы говорим про программу сложности Hello Wolrd, то я с вами согласен. Но в реальных ООП системах у нас уже как правило подключён DI и управление подобной зависимостью тривиальный шаг. Если же у вас не тривиальное ООП приложение и без DI, то тут вообще не нужно думать о таких высоких материях и можно на всё забить и писать хоть даже и без комментариев.
Ну, если это константа, то она не должна зависеть от внешних факторов. А в вашем случае это диктуется железом сервера. На мой взгляд это отличный пример конфигурационной зависимости.
Почему не должна? Изменились требования изменилась и константа. В случае компилируемых языков ещё есть смысл выносить её в конфиг, чтобы не перекомпилировать приложение, но вот в случае интерпретируемых языков зачастую проще собрать все константы в один файл или каталог, чем заморачиваться с парсингом конфига.
Но в реальных ООП системах у нас уже как правило подключён DI и управление подобной зависимостью тривиальный шаг.
DI имеет разные реализации и вовсе не всех из них требуют внешних конфигов. Главное что клиенты объектов получают их извне, а не создают сами, а созданы они путем обработки конфигов или просто захардкожены на уровне выше в стэке вызовов — особо им без разницы.
Почему не должна? Изменились требования изменилась и константа. В случае компилируемых языков ещё есть смысл выносить её в конфиг, чтобы не перекомпилировать приложение, но вот в случае интерпретируемых языков зачастую проще собрать все константы в один файл или каталог, чем заморачиваться с парсингом конфига.
И вы перекомпилируете код и выкладываете на продакшн новую версию? Вы простите, но это какие-то уж совсем экзотические примеры вы придумываете. Я пишу веб сайты, и мне ваши примеры кажутся высосаными из пальца. Если у меня что-то зависит от железа, то это пишется в конфиге или в БД, а не хардкодится. Уж не знаю что вы там пишете, что может оправдать (как по мне) подобную дикость.
DI имеет разные реализации и вовсе не всех из них требуют внешних конфигов. Главное что клиенты объектов получают их извне, а не создают сами, а созданы они путем обработки конфигов или просто захардкожены на уровне выше в стэке вызовов — особо им без разницы.
Тут вы правы, но это не противоречит моему видению — DI root у приложения должен быть один и там уже определятся что и куда подставлять.
И вы перекомпилируете код и выкладываете на продакшн новую версию? Вы простите, но это какие-то уж совсем экзотические примеры вы придумываете. Я пишу веб сайты, и мне ваши примеры кажутся высосаными из пальца. Если у меня что-то зависит от железа, то это пишется в конфиге или в БД, а не хардкодится. Уж не знаю что вы там пишете, что может оправдать (как по мне) подобную дикость.
Просто выкладываю — язык интерпретируемый. Технически это никак не отличается от правки конфига. Передается между локальной машиной и сервером только один файл, вернее между ними стоит репозиторий, а передается только дифф одного файла. А как он будет называться, config.xml или config.php особой разницы не, кроме той, что второй проще и читать, и редактировать.
Не очень понимаю, зачем такие интимные подробности вообще в коде указывать. Если это необходимо, можно запихать в комментарии-спецификации этой функции.
для разделения на блоки длинных функций, чтобы было проще ориентироваться
Длинную функцию надо разбивать на несколько коротких. Там, где хочется выделить «блок» — выделяйте функцию. То, что хочется написать как комментарий к блоку — напишите как название функции.
То, что хочется написать как комментарий к блоку — напишите как название функции.
(нет, я знаю, что это дословная цитата из Фаулера, но все равно)
Именно благодаря такому совету у нас в проекте есть метод CreateFullyCompliantXxxEnvelopeWithGOSTSignedPayloadAndPresetYyyHeaders (Xxx и Yyy — названия систем, NDA).
Именно поэтому я и советовал почитать книгу полностью, т.к. короткие цитаты вырванные из контекста могут нанести вред, будучи принятыми буквально и фанатично.
Это же можно отнести к статье.
Это же можно отнести к статье.
И что?
Кто сказал, что это плохо? Комментарий был бы не короче и передавал бы столько же смысла. Но обладал бы вышеупомянутыми недостатками.
Кто сказал, что это плохо? Комментарий был бы не короче и передавал бы столько же смысла. Но обладал бы вышеупомянутыми недостатками.
Ну лично меня это раздражает, потому что слишком много ненужной информации. Мне далеко не всегда нужно знать все, что делает этот метод, мне достаточно знать, что он собирает конверт. А все остальное можно в его описание положить.
Собственно, типичное too much verbosity, совершенно классическое.
Собственно, типичное too much verbosity, совершенно классическое.
Представьте, что есть второй такой же метод с различием где-то в части «Yyy» и обычно оба вызываются в перемешку, но эта «перемешка» каждый раз разная (и простой комбинаторикой не описывается). Да ещё этот diff в ширину окна не укладывается, то есть при нормальном просмотре вы его просто не увидите.
Может вам просто стоило выделить класс XxxEnvelope, который бы отвечал за остальные операции, которых у вас в имени метода 3: PresetYyyHeaders, AddGOSTSignedPayload и CreateFullyCompliant (или просто Create/Build). Это также позволило бы вам не писать новый медод для той же логики, но без установки хедеров. А дальше можно красиво зарефакторить в шаблон Builder с вызовами наподобие: new XxxEnvelopeBuilder().withYyyHeaders().withGostSignedPayload().build();
Не, не взлетит, потому что это всегда делается вместе (нет никакого «та же логика без установки хедеров»). Собственно, проблема именно в этом — всегда надо делать все три операции.
Так я вам только внутреннюю реальзацию предложил. Остальные должны использовать интерфейс наподобие XxxEnvelopeFactory с методом createEnvelope. А какие там реализации есть на самом деле — никого не волнует в месте вызова.
Но даже если нужно будет в разных местах указанную мной цепочку кода использовать, то она все равно поприятнее выглядит чем огромный метод. А если места все же более-менее в одном классе или пакете, то выделите метод или вспомогательный класс. С его именованием проблем не возникнет, потому что он будет в достаточно узком контексте.
Но даже если нужно будет в разных местах указанную мной цепочку кода использовать, то она все равно поприятнее выглядит чем огромный метод. А если места все же более-менее в одном классе или пакете, то выделите метод или вспомогательный класс. С его именованием проблем не возникнет, потому что он будет в достаточно узком контексте.
Тогда можно не городить всю эту череду из абстракций и билдеров, а тупо оставить метод createEnvelope. Беда в том, что когда пятый раз полезешь внутрь проверять, выставляет ли он хедеры и подпись — захочется написать про это комментарий в коде. Далее по кругу.
Эта череда из абстракций и билдеров — и есть написание хорошего, понятного и читаемого кода. Мало этого, он еще легче тестируется в изоляции, потому что можно все аспекты протестировать отдельно. Но безусловно, легче просто нашарашить комментарий и все проблемы решены…
Вольная цитата: «Любую проблему в программировании можно решить введением ещё одного уровня абстракции… Кроме проблемы слишком большого числа уровней абстракций». Вот зачем вы предлагаете вводить интерфейс и фабрику, когда реализация только одна? Это та самая преждевременная оптимизация, которое зло. В данном случае оптимизация даже не читаемости, а расширяемости.
При чем тут оптимизация? В приложении вырисовалась концепция сборщика конвертов. Я хочу ее добавить в виде интерфейса в доменную модель, чтобы дать возможность ее использовать везде без привязки к реализации. Тогда работать с кодом и тестировать его гораздо проще в изоляции.
Саму же единственную реализацию я напишу и протестирую отдельно от всех, кто ее будет использовать. И, если код реализации не сможет стать прозрачным, то в заголовке класса я распишу для чего он и что умеет. Но это скорее редкое исключение.
Саму же единственную реализацию я напишу и протестирую отдельно от всех, кто ее будет использовать. И, если код реализации не сможет стать прозрачным, то в заголовке класса я распишу для чего он и что умеет. Но это скорее редкое исключение.
К сожалению, в данном конкретном случае эта череда не помогает.
Потому что по факту все равно все сведется к вопросу «как назвать и/или прокомментировать хелперный метод, который собирает конверт целиком». Что у него внутри — действительно не важно.
Потому что по факту все равно все сведется к вопросу «как назвать и/или прокомментировать хелперный метод, который собирает конверт целиком». Что у него внутри — действительно не важно.
Да уже в контексте конкретном вы его можете назвать createEnvelope. Вы же пеняли на то, что открыв метод, тяжело понять что он делает. Так вот приведенная мной строка вызова билдера и будет вашим «комментарием». А подсветить ее без перехода в метод легко — в IDEA за это отвечают Ctrl + Shift + I.
Вы же пеняли на то, что открыв метод, тяжело понять что он делает.
Нет, я пенял не на это, а на то, что сложно понять, что делает метод, не переходя в него (только по названию/справочной информации).
Так я же рассказал как это сделать в прошлом комментарии?!?
Либо я чего-то не понял, либо вы предлагаете смотреть исходники метода (не важно, что ваши средства разработки позволяют делать это без фактического перехода).
Как это неважно? Это умеет любая современная IDE, а не «моя среда разработки». А вы интересно на что будете смотреть? Не на комментарий ли к методу или внутри него? Чтобы туда заглянуть надо тоже перейти…
Visual Studio 2012 — достаточно современная IDE? она не умеет.
А вот показывать аннотации (они же документация) умеет существенно большее число IDE и плагинов.
А вот показывать аннотации (они же документация) умеет существенно большее число IDE и плагинов.
Уточняю: скажем, есть три блока по 10 строк, активно потребляют одни и те же параметры, все специфичные и отдельно не используются. Бритва Оккама: зачем плодить сущности? Это редко бывает, но бывает.
Не туда отправил. :(
В процессе комментирования ещё подумалось, что длинные названия методов вместо короткого названия и комментария (предполагается, что кратко что, как и, главное, почему именно это и как этот метод делает не изложить) нарушают так любимый многими фанатами идеального кода принцип DRY. Название этого метода приходится постоянно писать и, главное, читать.
Если такое происходит, то, скорее всего, нужно подумать а нельзя ли вынести подобные методы в отдельный класс.
Если метод один, то ничего не поделаешь — вы же не будете писать комментарии у каждого вызова метода с сокращённым, но непонятным названием?
Если метод один, то ничего не поделаешь — вы же не будете писать комментарии у каждого вызова метода с сокращённым, но непонятным названием?
Что упростит вынос методов в отдельный класс? При вызове в середине названия нужно будет точку поставить?
А метод у меня будет с коротким названием, отражающим что он делает, но скрывающем нюансы как и почему он так делает, коль скоро для вызывающего кода это не важно — это не его уровень ответственности. Просто sort(), а не sortWithMiniumMemoryUsingBecauseOurUsersHaveNotMoneyToBuy64GbRamServer(). Если кто-то заинтересуется почему сортировка тормозит, то откроет код метода (а в современных реалиях скорее наведет мышку или хоткей нажмет, и IDE в тултипе покажет *doc комментарии в адаптированном виде) и увидит, что оптимизировалось потребление памяти и по каким причинам оптимизировалось именно оно. На этапе понимания алгоритма, логики работы вызывающего кода это лишняя информация, даваа такие имена мы нарушаем по сути инкапсуляцию, завязывая вызывающий код на реализацию. Захотим потом заменить реализацию на более быструю — нам нужно будет ещё и название метода во всем проекте менять. Или название метода будет не просто ничего не говорить о деталях реализации, а будет вводить в заблуждение.
А метод у меня будет с коротким названием, отражающим что он делает, но скрывающем нюансы как и почему он так делает, коль скоро для вызывающего кода это не важно — это не его уровень ответственности. Просто sort(), а не sortWithMiniumMemoryUsingBecauseOurUsersHaveNotMoneyToBuy64GbRamServer(). Если кто-то заинтересуется почему сортировка тормозит, то откроет код метода (а в современных реалиях скорее наведет мышку или хоткей нажмет, и IDE в тултипе покажет *doc комментарии в адаптированном виде) и увидит, что оптимизировалось потребление памяти и по каким причинам оптимизировалось именно оно. На этапе понимания алгоритма, логики работы вызывающего кода это лишняя информация, даваа такие имена мы нарушаем по сути инкапсуляцию, завязывая вызывающий код на реализацию. Захотим потом заменить реализацию на более быструю — нам нужно будет ещё и название метода во всем проекте менять. Или название метода будет не просто ничего не говорить о деталях реализации, а будет вводить в заблуждение.
Вы правы в том, что давать такие названия значит привязываться к реализации. И именно это должно было вас подтолкнуть на мысль о том, что раз это особенность, то у этой особенности откуда-то «растут ноги». А растут они из внешних (по отношению к приложению) условий. А значит, это внешняя зависимость и хардкодить такие вещи по сути нарушение принципа DIP.
Понятное дело, что частенько нам не до таких тонкостей, но в рамках философствований на тему идеального кода это грешновато.
Понятное дело, что частенько нам не до таких тонкостей, но в рамках философствований на тему идеального кода это грешновато.
DIP нарушается только если у нас название (сигнатура) функции зависит от её реализации. Если не зависит, то всё в порядке с DIP — изменение реализации не потребует изменения вызывающего кода.
А растут они из внешних (по отношению к приложению) условий
Все требования заказчика являются внешними по отношению к приложению условиями. Это не означает, что они являются внешней зависимостью и требуют IoC.
Поделюсь своим любимым комментарием из исходников .Net. Мне кажется, что если комментарии и должны быть, то только такими:
Из …\ndp\fx\src\WinForms\Managed\System\WinForms\ComponentManagerBroker.cs\1305376\componentmanagerbroker.cs
Ok, this class needs some explanation…
/// <devdoc>
/// Ok, this class needs some explanation. We share message loops with other applications through
/// an interface called IMsoComponentManager. A "component' is fairly coarse here: Windows Forms
/// is a single component. The component manager is the application that owns and runs the message
/// loop. And, consequently, an IMsoComponent is a component that plugs into that message loop
/// to listen in on Windows messages. So far, so good.
///
/// Because message loops are per-thread, IMsoComponentManager is also per-thread, which means
/// we will register a new IMsoComponent for each thread that is running a message loop.
///
/// In a purely managed application, we satisfy both halves of the equation: Windows Forms
/// implements both the IMsoComponentManager and the IMsoComponent. Things start
/// to get complicated when the IMsoComponentManager comes from the COM world.
///
/// There's a wrinkle with this design, however: It is illegal to call IMsoComponentManager on a
/// different thread than it expects. In fact, it will throw an exception. That's a probolem for key
/// events that we receive during shutdown, like app domain unload and process exit. These
/// events occur on a thread pool thread, and because as soon as we return from that thread the
/// domain will typically be torn down, we don't have much of a chance to marshal the call to
/// the right thread.
///
/// That's where this set of classes comes in. We actually maintain a single process-wide
/// application domain, and within this app domain is where we keep all of our precious
/// IMsoComponent objects. These objects can marshal to other domains and that is how
/// all other user-created Windows Forms app domains talke to the component manager.
/// When one of these user-created domains is shut down, it notifies a proxied
/// IMsoComponent, which simply decrements a ref count. When the ref count reaches zero,
/// the component waits until a new message comes into it from the component manager.
/// At that point it knows that it is on the right thread, and it unregisters itself from the
/// component manager.
///
/// If all this sounds expensive and complex, you should get a gold star. It is. But, we take
/// some care to only do it if we absolutely have to. For example, If we only need the additional
/// app domain if there is no executing assembly (so there is no managed entry point) and if
/// the component manager we get is a native COM object.
///
/// So, if you're with me so far you probably want to know how it all works, probably due to some
/// nasty bug I introduced. Sorry about that.
///
/// There are two main classes here: ComponentManagerBroker and ComponentManagerProxy.
///
/// ComponentManagerBroker:
/// This class has a static API that can be used to retrieve a component manager proxy.
/// The API uses managed remoting to attempt to communicate with our secondary domain.
/// It will create the domain if it doesn't exist. It communicates with an instance of itself
/// on the other side of the domain. That instance maintains a ComponentManagerProxy
/// object for each thread that comes in with a request.
///
/// ComponentManagerProxy:
/// This class implements both IMsoComponentManager and IMsoComponent. It implements
/// IMsoComponent so it can register with with the real IMsoComponentManager that was
/// passed into this method. After registering itself it will return an instance of itself
/// as IMsoComponentManager. After that the component manager broker stays
/// out of the picture. Here's a diagram to help:
///
/// UCM <-> CProxy / CMProxy <-> AC
///
/// UCM: Unmanaged component manager
/// CProxy: IMsoComponent half of ComponentManagerProxy
/// CMProxy: IMsoComponentManager half of ComponentManagerProxy
/// AC: Application's IMsoComponent implementation
/// </devdoc>
Из …\ndp\fx\src\WinForms\Managed\System\WinForms\ComponentManagerBroker.cs\1305376\componentmanagerbroker.cs
Не пишите комментарии к коду!