Комментарии 77
Это прекрасно. Вот только и данные в каждом дата-центре должны быть идентичны. А это не всегда возможно.
Как невозможно? :) очень даже возможно.
Puppet_ом раскладываем файл зон.
Есть раздел общий а есть раздел уникальный для каждого ДЦ.
Puppet_ом раскладываем файл зон.
Есть раздел общий а есть раздел уникальный для каждого ДЦ.
Насколько я понял al1k — речь идет о данных в контексте UGC, исходный код и БД.
Чем лучше чем Round-robin DNS?
причем тут данные и RR? это на столько разные вещи… тут же говорится о форонтах и отказоустойчивом автоматичсеком решении, что бы по ночам спать спокойно.
в RR NS будет отдавать IP «выключенного» сервера и клиенты не смогут приконектиться к серверу.
В моей схеме через минуту все уже «переедут» на рабочие сервера.
В моей схеме через минуту все уже «переедут» на рабочие сервера.
Что касается сессий: пользователь всегда попадает на один и тот же сервер?
GSLB намного более гибкий.
В идеальном мире клиент не должен сам решать, куда идти.
В идеальном мире клиент не должен сам решать, куда идти.
Не совсем уверен в: «Если падает дата-центр в течении минуты все клиенты уйдут на работающие площадки»
То что у DNS указан TTL 1min — провайдеры могут его игнорировать. Или я не прав?
То что у DNS указан TTL 1min — провайдеры могут его игнорировать. Или я не прав?
не прав
Прав. Точнее DNS кэш сервер провайдера может «залипнуть», а то и вовсе быть настроен криворуким админом. Не сказал бы, что это очень частая ситуация, но имеет место быть с некоторой регулярностью.
Многие операторы к слову говоря занижают специально TTL если оно слишком большое. Этим точно балуется билай. Видимо чтобы избавить себя от лишьних звонков в тех поддержку.
Во всех случаях с которыми сталкивался я ситуация была как раз обратная. На стороне провайдера TTL домена не срабатывал и записи в кэше не обновлялись. Причем проблема выявляется только в одном случае — домен клиента переежает на сервер с другим IP. Если бы этого не было, ни кто бы и не узнал, что проблема вообще есть.
Так что уменьшенный TTL на стороне провайдера это в принципе даже хорошо.
Так что уменьшенный TTL на стороне провайдера это в принципе даже хорошо.
Да некоторые кеширующие сервера игнорируют TTL, но их очень мало. может 1-2%
Мы используем немного другую схему, но, в целом, суть та же — TTL на записи 5 минут, в случае падения одного ДЦ запись меняется.
Через пять минут после переключения я на своем haproxy вижу 0, редко-редко когда появится 1-2.
Вывод: подавляющее большинство провайдеров TTL обрабатывают правильно.
Через пять минут после переключения я на своем haproxy вижу 0, редко-редко когда появится 1-2.
Вывод: подавляющее большинство провайдеров TTL обрабатывают правильно.
чтото мне кажется что многие клиенты не воспринимают '$TTL 60; 1 minutes' как должное.
это какие? примеры в студию.
у нас более 600к клиентов, которые сидят на очень разных броузерах/клиентах и ни одной жалобы не было.
у нас более 600к клиентов, которые сидят на очень разных броузерах/клиентах и ни одной жалобы не было.
Что жалоба до вас не дошла еще не показатель, что проблемы нет. Просто если человек переходит на сайт и этот сайт не его, он просто закроет страницу и очень маловероятно, что что-то напишет (письмом долго да и нужный адрес написано на сайте который не открывается).
Другое дело, когда сайт пытается открыть человек являющийся владельцем этого сайта. И вот тут да, он обязательно достучится до технической поддержки и целью выяснить, какого же хрена сайт не пашет. Могу это утверждать исходя из опыта работы у одного достаточно известного регистратора-хостера.
Другое дело, когда сайт пытается открыть человек являющийся владельцем этого сайта. И вот тут да, он обязательно достучится до технической поддержки и целью выяснить, какого же хрена сайт не пашет. Могу это утверждать исходя из опыта работы у одного достаточно известного регистратора-хостера.
ооооочень маленький процент… можно игнорировать.
НЛО прилетело и опубликовало эту надпись здесь
Так а что, не тормозит разве маленькое время устаревание загрузку страниц в браузере? Он же должен все время днс-резолвинг повторять.
Есть конторы, считающие ttl ~ 60 секунд признаком fast flux'а, а его, в свою очередь, признаком ботнета. На этой почве можно попасть в неприятную ситуацию. Это первый минус.
Второй — при желании запустить DNSSec, придется подписывать несколько зон.
Второй — при желании запустить DNSSec, придется подписывать несколько зон.
> Есть конторы, считающие ttl
какие? можно поточнее?
какие? можно поточнее?
Если мне склероз не изменяет, то тот же спамхаус.
Низкий TTL сам по себе конечно не означает fast flux, но является предметом для пристального внимания. Тот же ICANN советует минимальное значение — 30 минут.
Низкий TTL сам по себе конечно не означает fast flux, но является предметом для пристального внимания. Тот же ICANN советует минимальное значение — 30 минут.
Clarifications to the DNS Specification
tools.ietf.org/html/rfc2181#page-10
tools.ietf.org/html/rfc2181#page-10
8. Time to Live (TTL)
The definition of values appropriate to the TTL field in STD 13 is
not as clear as it could be, with respect to how many significant
bits exist, and whether the value is signed or unsigned. It is
hereby specified that a TTL value is an unsigned number, with a
minimum value of 0, and a maximum value of 2147483647. That is, a
maximum of 2^31 — 1. When transmitted, this value shall be encoded
in the less significant 31 bits of the 32 bit TTL field, with the
вот момент выключения dns


Кстати, хочу заметить, что если глубина просмотра типичного пользователя — 1-2 страницы (бывают и такие сайты), то такой график может быть и при TTL=1day. Если же пользователь сидит на сайте, то современный браузер, насколько я понимаю, сам кэширует IP-адрес домена, причем плюет на настройки устаревания зоны (поправьте меня, если я ошибаюсь). По крайней мере, я помню, как приходилось несколько раз закрывать+открывать браузер даже после dns flush-а на локальной машине (даже Ctrl+F5 не помогало, только переоткрытие). Может быть, конечно, браузер умный и, видя, что IP-адрес перестал отвечать, быстренько сделает DNS-запрос за новым адресом, но что-то я в этом сомневаюсь (опять же — поправьте меня, если это не так).
По сему — реквестую чистый эксперимент у тех, кто пользуется методом топика:
1. Заходим на сайт.
2. Переключаем DNS.
3. Продолжаем ходить по сайту тем же браузером.
4. Смотрим, через какое время «отпустит» (если вообще отпустит).
По сему — реквестую чистый эксперимент у тех, кто пользуется методом топика:
1. Заходим на сайт.
2. Переключаем DNS.
3. Продолжаем ходить по сайту тем же браузером.
4. Смотрим, через какое время «отпустит» (если вообще отпустит).
делали следующее в разных броузерах. 2 сервера фронта на балансировке с ТТЛ 60. ходим по сайту. то.се. отключаем 1 сервер. максимум через минуту работа восстанавливается. тестили из локалки, и снаружи.
потом делали под реальной нагрузкой. примерно 1к запросов в сек. просто отключали ДНС на одном фронте. 3 фронта под балансировкой. через минуту почти все юзеры перетекают на работающие сервера. остаются 1-2 запроса, но это для нас приемлимо.
все, что нам надо это автоматическое переключение при отказе. нас это устраивает.
если есть желание можно провести эксперимент. мощности есть. пишите в личку.
потом делали под реальной нагрузкой. примерно 1к запросов в сек. просто отключали ДНС на одном фронте. 3 фронта под балансировкой. через минуту почти все юзеры перетекают на работающие сервера. остаются 1-2 запроса, но это для нас приемлимо.
все, что нам надо это автоматическое переключение при отказе. нас это устраивает.
если есть желание можно провести эксперимент. мощности есть. пишите в личку.
Ну как вам не стыдно, зачем же вот так сразу в личку. :)
По делу: вот это уже пошла экспериментальная информация, это хорошо. Есть 2 мысли:
1. Напишите здесь, пожалуйста, адрес сайта, на котором организована такая схема. Каждый сможет сам протестить, что к чему, даже без вашего участия — просто ра своем фаерволе перекроет тот или иной фронт+днс, и вам не придется ДЦ отключать.
2. То, что браузеры переключаются — это ок. Хотелось бы еще второй момент выяснить — как часто они делают днс-запросы «ненужные», когда все работает штатно? А то на среднем сайте по исследованиям гугла — порядка 5 доменов задействовано, и если к каждому из них каждую минуту каждый пользователь будет за ip-адресом ломиться, работа сайта замедлится, лишний пинг добавится.
По делу: вот это уже пошла экспериментальная информация, это хорошо. Есть 2 мысли:
1. Напишите здесь, пожалуйста, адрес сайта, на котором организована такая схема. Каждый сможет сам протестить, что к чему, даже без вашего участия — просто ра своем фаерволе перекроет тот или иной фронт+днс, и вам не придется ДЦ отключать.
2. То, что браузеры переключаются — это ок. Хотелось бы еще второй момент выяснить — как часто они делают днс-запросы «ненужные», когда все работает штатно? А то на среднем сайте по исследованиям гугла — порядка 5 доменов задействовано, и если к каждому из них каждую минуту каждый пользователь будет за ip-адресом ломиться, работа сайта замедлится, лишний пинг добавится.
по 1 вопросу светить как то не хотелось…
по второму: не броузер а dns client получив список ns от root-dns сервера дергает ваш. поел перогоже откза дергает другой, т.к. не получил никакой A записи.
А вот когда получил держит ее в кеше TTL секунд :) и процесс повторяется.
по второму: не броузер а dns client получив список ns от root-dns сервера дергает ваш. поел перогоже откза дергает другой, т.к. не получил никакой A записи.
А вот когда получил держит ее в кеше TTL секунд :) и процесс повторяется.
> Напишите здесь, пожалуйста, адрес сайта, на котором организована такая схема.
очень не хочется хабраэффекта. сайт боевой. расчитан под определенную нагрузку.
===
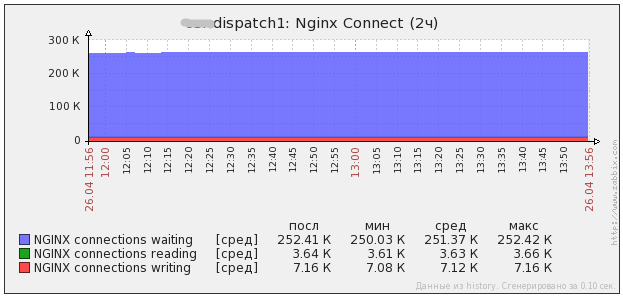
вот как выглядит нагрузка на одном боевом проекте. в среднем 300 rps. в пиках доходит до 1000 rps. собственно можно увидеть нагрузку фронтов и нагрузку DNS серверов на них. если хочется, я могу выключить один из серверов (погасить там DNS) на полчасика и мы увидим перетекание нагрузки. потом его включу и нагруз опять перераспределится.
Запросы на фронты
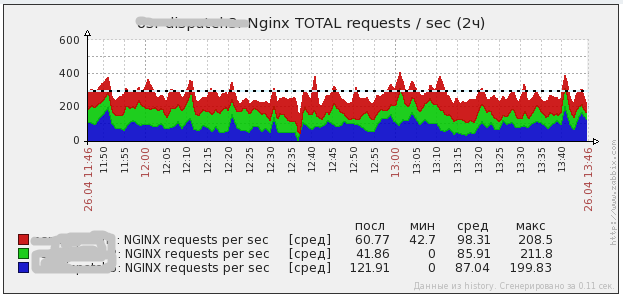
Траффик
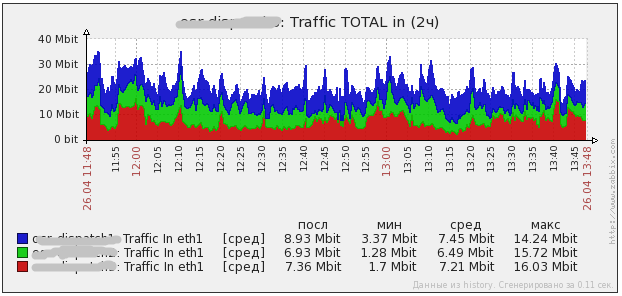
BIND
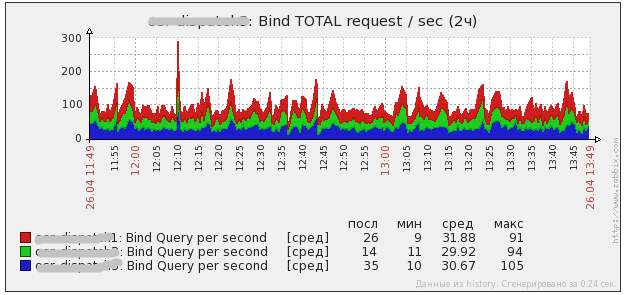
NGINX на 1 фронте
очень не хочется хабраэффекта. сайт боевой. расчитан под определенную нагрузку.
===
вот как выглядит нагрузка на одном боевом проекте. в среднем 300 rps. в пиках доходит до 1000 rps. собственно можно увидеть нагрузку фронтов и нагрузку DNS серверов на них. если хочется, я могу выключить один из серверов (погасить там DNS) на полчасика и мы увидим перетекание нагрузки. потом его включу и нагруз опять перераспределится.
Запросы на фронты

Траффик

BIND

NGINX на 1 фронте

Хабраэффекта не существует, тем более — в нишевом топике, тем более — по ссылке в коммента. :-)
Как я выше писал, график общей нагрузки может мало что показывать — важен опыт отдельного пользователя, который ходит по сайту в момент, когда один из ДЦ внезапно падает. А именно, 2 аспекта такого опыта:
1. Что происходит, когда отдельно взятый юзер ходит-ходит по сайту, а один ДЦ внезапно падает — через сколько времени юзер может продолжит хождение (выше вы писали, что проводили эксперимент, и в течение минуты он может продолжить ходить — с этим ОК, можно считать вопрос решенным).
2. Что происходит, когда отдельно взятый юзер ходит-ходит по сайту, а ДЦ никак не падает и не падает. Сколько DNS-запросов при этом генерирует юзер: если по одному на каждый домен в каждую минуту (в чем лично я сомневаюсь — см. выше мои наблюдение про сброс кэша локального резолвера, браузеры его не видят) — то это плохо (увеличивается пинг). Идеальная ситуация — браузер сам кэширует все у себя, не обращаясь к резолверу (возможно, он так и делает), и, получив однажды IP-адрес, не идет в DNS до тех пор, пока не обнаружил, что сайт вдруг перестал отвечать. Но я не знаю, далают ли так современные браузеры. Имея пример сайта, на котором реализована описанная в топике техника, это легко проверить без выключения серверов, достаточно на локальной машине перекрыть фаерволом один из ДЦ.
Таким образом, по п. 2 полной ясности пока так и нет.
Как я выше писал, график общей нагрузки может мало что показывать — важен опыт отдельного пользователя, который ходит по сайту в момент, когда один из ДЦ внезапно падает. А именно, 2 аспекта такого опыта:
1. Что происходит, когда отдельно взятый юзер ходит-ходит по сайту, а один ДЦ внезапно падает — через сколько времени юзер может продолжит хождение (выше вы писали, что проводили эксперимент, и в течение минуты он может продолжить ходить — с этим ОК, можно считать вопрос решенным).
2. Что происходит, когда отдельно взятый юзер ходит-ходит по сайту, а ДЦ никак не падает и не падает. Сколько DNS-запросов при этом генерирует юзер: если по одному на каждый домен в каждую минуту (в чем лично я сомневаюсь — см. выше мои наблюдение про сброс кэша локального резолвера, браузеры его не видят) — то это плохо (увеличивается пинг). Идеальная ситуация — браузер сам кэширует все у себя, не обращаясь к резолверу (возможно, он так и делает), и, получив однажды IP-адрес, не идет в DNS до тех пор, пока не обнаружил, что сайт вдруг перестал отвечать. Но я не знаю, далают ли так современные браузеры. Имея пример сайта, на котором реализована описанная в топике техника, это легко проверить без выключения серверов, достаточно на локальной машине перекрыть фаерволом один из ДЦ.
Таким образом, по п. 2 полной ясности пока так и нет.
> Таким образом, по п. 2 полной ясности пока так и нет.
готов проэксперементировать. скажите что и как сделать?
готов проэксперементировать. скажите что и как сделать?
Ну я вроде бы писал, что сделать: дать ссылку на сайт, где реализуется описанная в посте схема. Больше ничего не требуется.
440hz напишите еще, пожалуйста: может быть, у вас был опыт в вопросе habrahabr.ru/post/177145/#comment_8222453? Я бы в личку написал, но, к сожалению, у вас в профиле конвертик не показывается… надеюсь, что упоминание 440hz сработает, и вам придет письмо-уведомление.
в приват отписал
в среднем 300 rps
Это динамика+статика? Чисто динамика?
А какая разница динамика или статика?
Динамика — показатель эффективности работы бэкэнда.
Статика — показатель эффективности работы nginx.
300 rps на чисто статических сайтах банальная себе такая величина, ибо да, nginx хорош. 300 rps динамики, да еще на развесистой бизнес логике, да еще с одного сервера, может быть очень хорошим показателем. Поэтому характер нагрузки имеет значение.
Статика — показатель эффективности работы nginx.
300 rps на чисто статических сайтах банальная себе такая величина, ибо да, nginx хорош. 300 rps динамики, да еще на развесистой бизнес логике, да еще с одного сервера, может быть очень хорошим показателем. Поэтому характер нагрузки имеет значение.
вот. отключение одного сервера.
видно, что на втором графике траф перераспределяется на другие сервера.

видно, что на втором графике траф перераспределяется на другие сервера.

У нас состоялась небольшая переписка с rukhem в привате — выкладываю ее тут, она дает некоторую дополнительную информацию к топику. Может быть, конечно, это повтор, но вроде в чистом виде не обсуждалось пока.
Так-так… то есть, получается, схема, когда в 2 ДЦ стоят 2 NS-сервера, отдающие IP-адреса «своего» ДЦ, в «чистом виде» для организации fallback-ДЦ не работает? И запросы будут идти равномерно и в тот, и в другой ДЦ, а не только «в самый первый»? Тогда получается, что нужно строго следить за синхронностью данных (даже асинхронная репликация тут не подойдет, только синхронная), потому что один и тот же клиент может попадать то в один ДЦ, то в другой.
В этой связи техника, когда IP-адрес на NS-сервере «вручную» переключается при сбое одного из ДЦ, выглядит лучше. Т.е. оба NS-сервера выдают IP в одном и том же ДЦ, а когда он падает, админ бородой переключает IP-адрес, и NS-серверы начинают выдавать IP в другом ДЦ.
Пусть у меня 2 ДЦ, соответственно, 2 NS-сервера: ns-04.example.com и ns-03.example.com, при этом ns-04 (и его ДЦ) — основной. По идее, надо тогда прописать в список NS-серверов для домена такой порядок:
ns-04.example.com
ns-03.example.com
чтобы клиенты брали первый NS-сервер в списке. Но на практике многие регистраторы сортируют NS-серверы по алфавиту (в моем случае это не подходит), так что данный порядок установить не получается:
— nic.ru для доменов в зоне COM точно так сортирует (для зоны ru — не сортирует)
— philsdomains — то же самое, в каком порядке ни задавай, все равно оказывается по алфавиту
— godaddy — пока еще точно не знаю, данные обновляются.
Вопрос — что делать в этом случае. Можно ли как-то на своей стороне задать этот порядок, чтобы не завязываться за особенности регистраторов?
Опрашивайте root сервер. он будет выдавать список ваших ns серверов round robbin.
так что заморачиваться на тему сортировки имхо не стоит.
Так-так… то есть, получается, схема, когда в 2 ДЦ стоят 2 NS-сервера, отдающие IP-адреса «своего» ДЦ, в «чистом виде» для организации fallback-ДЦ не работает? И запросы будут идти равномерно и в тот, и в другой ДЦ, а не только «в самый первый»? Тогда получается, что нужно строго следить за синхронностью данных (даже асинхронная репликация тут не подойдет, только синхронная), потому что один и тот же клиент может попадать то в один ДЦ, то в другой.
В этой связи техника, когда IP-адрес на NS-сервере «вручную» переключается при сбое одного из ДЦ, выглядит лучше. Т.е. оба NS-сервера выдают IP в одном и том же ДЦ, а когда он падает, админ бородой переключает IP-адрес, и NS-серверы начинают выдавать IP в другом ДЦ.
Вы сами поняли что написали?
Странный вопрос. Собственно, есть 2 схемы организации «отказоустойчивости» с использованием DNS (в обоих случаях TTL=1min):
1. Когда есть 2 ДЦ, в каждом их них свой NS-сервер, выдающий IP в своем ДЦ — ровно то, что описано в топике. Минус этого способа — трафик идет в оба ДЦ, если оба работают, и нельзя сделать так, чтобы трафик шел только в один из ДЦ (основной), в то время как второй (резервный) простаивал бы и ждал, когда упадет первый. Это накладывает жесткие условия, например, на организацию репликации БД и вообще на синхронизацию данных, а то один и тот же клиент будет попадать то в первый ДЦ, то (через минуту) во второй, и начнет удивляться, чего это у него данные разные.
2. Когда есть 2 ДЦ, но на NS-серверах прописаны только IP первого из них (основного). Когда основной ДЦ падает, кто-то переключает IP-адрес на NS-серверах, и трафик начинает идти в резервный ДЦ. Минус тут — должен быть этот «кто-то». Правда, он и так должен в большинстве случаев быть (хотя бы чтобы назначить реплику новым мастером), но все равно, 2 операции хуже, чем одна.
1. Когда есть 2 ДЦ, в каждом их них свой NS-сервер, выдающий IP в своем ДЦ — ровно то, что описано в топике. Минус этого способа — трафик идет в оба ДЦ, если оба работают, и нельзя сделать так, чтобы трафик шел только в один из ДЦ (основной), в то время как второй (резервный) простаивал бы и ждал, когда упадет первый. Это накладывает жесткие условия, например, на организацию репликации БД и вообще на синхронизацию данных, а то один и тот же клиент будет попадать то в первый ДЦ, то (через минуту) во второй, и начнет удивляться, чего это у него данные разные.
2. Когда есть 2 ДЦ, но на NS-серверах прописаны только IP первого из них (основного). Когда основной ДЦ падает, кто-то переключает IP-адрес на NS-серверах, и трафик начинает идти в резервный ДЦ. Минус тут — должен быть этот «кто-то». Правда, он и так должен в большинстве случаев быть (хотя бы чтобы назначить реплику новым мастером), но все равно, 2 операции хуже, чем одна.
Теперь понятно.
1, Вопрос с репликацией данных решаем.
В предложенной мной схеме данные во всех ДЦ должны быть одинаковы — это если хотите требование такое.
2. «кто-то» кто будет переключать что-то вручную ЗЛО, все должно работать автоматически.
А что когда кто-то переключит вручную в этот момент реплика догонится волшебным образом? :)
1, Вопрос с репликацией данных решаем.
В предложенной мной схеме данные во всех ДЦ должны быть одинаковы — это если хотите требование такое.
2. «кто-то» кто будет переключать что-то вручную ЗЛО, все должно работать автоматически.
А что когда кто-то переключит вручную в этот момент реплика догонится волшебным образом? :)
НЛО прилетело и опубликовало эту надпись здесь
Route53 failover (вместе с health-check'ами их же) — штука хорошая, да. А вот мастер-мастер с двумя датацентрами ИМХО на практике не работает, увы (разве что в вырожденных случаях, когда у нас очень-очень мало записи идет в БД).
поставил TTL 1;
2 недели — полет нормальный.
2 недели — полет нормальный.
Вопрос по статье. Предположим, у меня есть example.com с NS-записью, содержащей 2 DNS-сервера: ns1.example.com и ns2.example.com. Первый DNS-сервер находится в первом ДЦ и отдает IP-адрес для example.com из своего ДЦ, второй, соответственно, во втором (и отдает тоже IP-адрес из своего ДЦ). Время устаревания A-записи для example.com у ns1 и ns2 установлено равным 1 минуте. Все, как в статье.
Теперь предположим, что первый ДЦ ложится. Соответственно, клиентам при запросе example.com становится доступен только ns2, но не ns1.
Вопрос: а вызовет ли это задержку при разрешении DNS-имен у клиентов? Ведь ОС клиента может сунуться на ns1, оттаймаутиться на нем (например, тайм-аут 5 секунд) и уж только после этого пойдет на ns2. Т.е. будет задержка в 5 секунд раз в минуту (т.к. время устаревания записи равно 1 минуте). Такое ощущение, что эта задержка ЕСТЬ, хотя я не могу добиться точного воспроизведения. Как с ней быть?
(Выставить время устаревания зоны больше 1 минуты я не могу, потому что иначе старые клиенты, которые видели ДЦ1, не переключатся быстро на использование ДЦ2. Например, если я сделаю время устаревания 1 час, то после последовательности «1. клиент сделал запрос и попал в работающий ДЦ1; 2. ДЦ1 лег» клиент получит IP-адрес ДЦ2 только через час.)
Теперь предположим, что первый ДЦ ложится. Соответственно, клиентам при запросе example.com становится доступен только ns2, но не ns1.
Вопрос: а вызовет ли это задержку при разрешении DNS-имен у клиентов? Ведь ОС клиента может сунуться на ns1, оттаймаутиться на нем (например, тайм-аут 5 секунд) и уж только после этого пойдет на ns2. Т.е. будет задержка в 5 секунд раз в минуту (т.к. время устаревания записи равно 1 минуте). Такое ощущение, что эта задержка ЕСТЬ, хотя я не могу добиться точного воспроизведения. Как с ней быть?
(Выставить время устаревания зоны больше 1 минуты я не могу, потому что иначе старые клиенты, которые видели ДЦ1, не переключатся быстро на использование ДЦ2. Например, если я сделаю время устаревания 1 час, то после последовательности «1. клиент сделал запрос и попал в работающий ДЦ1; 2. ДЦ1 лег» клиент получит IP-адрес ДЦ2 только через час.)
>Время устаревания A-записи для example.com у ns1 и ns2 установлено равным 1 минуте.
1. поставьте TTL 1; для всей зоны
Это увеличит нагрузку на dns но сильно сократит время переключения на второй ДЦ в случае падения первого.
2. пусть dns первого ДЦ (ns1) отдает NS запись только своего ДЦ
$TTL 1
;…
example.com. NS ns-dc1
ns-dc1 A ip_dc1
example.com. A ip_dc1
а dns второго dc отдает NS второго
$TTL 1
;…
example.com. NS ns-dc2
ns-dc1 A {ip_dc2}
example.com. A {ip_dc2}
>оттаймаутиться на нем (например, тайм-аут 5 секунд)
Это зависит от dns клиента. но как показывает практика 95% клиентов переключаются моментально.
Как проверить:
Рисуете графики конектов к nginx для обоих ДЦ.
В одном выключаете dns, смотрите на графики конектов к nginx :)
1. поставьте TTL 1; для всей зоны
Это увеличит нагрузку на dns но сильно сократит время переключения на второй ДЦ в случае падения первого.
2. пусть dns первого ДЦ (ns1) отдает NS запись только своего ДЦ
$TTL 1
;…
example.com. NS ns-dc1
ns-dc1 A ip_dc1
example.com. A ip_dc1
а dns второго dc отдает NS второго
$TTL 1
;…
example.com. NS ns-dc2
ns-dc1 A {ip_dc2}
example.com. A {ip_dc2}
>оттаймаутиться на нем (например, тайм-аут 5 секунд)
Это зависит от dns клиента. но как показывает практика 95% клиентов переключаются моментально.
Как проверить:
Рисуете графики конектов к nginx для обоих ДЦ.
В одном выключаете dns, смотрите на графики конектов к nginx :)
Не, графиками nginx-а мой вопрос вряд ли проверить. Задержка-то на стороне клиента (причем небольшая, всего 5 секунд, но для восприятия скорости открытия сайта это может быть критичным). Хочется именно этой задержки по возможности избежать в случае, когда одна машина включена, а другая — выключена. На второй сервер все запросы при отключении первого в итоге приходят (т.е. клиенты реально переключаются в течение 1 минуты), это я проверил.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Отказоустойчивость на базе DNS