
В этой главе речь пойдёт о способах объединения внешнего и внутреннего мониторинга. На что обратить внимание при выстраивании системы, какие при этом есть ограничения. Как не упустить мелочи и получить возможность обозревать картину не только снизу вверх, но и сверху вниз.
Содержание
Глава 1. Управление вашим IT окружением: четыре вещи, которые вы делаете неправильно
Глава 2. Устранение практики управления по отдельным участкам в IT-менеджменте
Глава 3. Соединяем всё в единый цикл управления ИТ
Глава 4. Мониторинг: взгляд за пределы ЦОД
Глава 5: Превращаем проблемы в решения
Глава 6: Унифицированное управление на примерах
Глава 4: Мониторинг: взгляд за пределы ЦОД
ИТ уже вышло за пределы наших собственных датацентров и практически каждая организация имеет один или два сервиса, выведенные на аутсорсинг. Хотя у нас, возможно, всегда будут свои домашние средства для мониторинга и управления, нам надо понимать, что в большинстве случаев, мониторинг должен продолжаться за пределами нашего ЦОД. Это относится и к размещению удалённых сервисов и к более точному пониманию того, что на самом деле испытывают наши пользователи при работе с такими сервисами.
Мониторинг технических счетчиков по сравнению с ощущениями конечного пользователя (EUE)
Традиционный подход в ИТ мониторинге я называю «изнутри – наружу (или шиворот-навыворот)». Он начинается в центре обработки данных и постепенно перемещается к конечному пользователю. На рисунке 4.1 показано как типичная система мониторинга начинается с бэкэнда: сервера СУБД, приложений, веб-серверы, серверы облаков и так далее. Наиболее разумный довод в пользу такой структуры заключается в том, что мы имеем наилучший контроль за оборудованием, установленным в нашем датацентре. Если внутри датацентра всё работает хорошо, то есть все основания полагать, что конечные пользователи, пользующиеся сервисами датацентра, должны быть вполне счастливы.
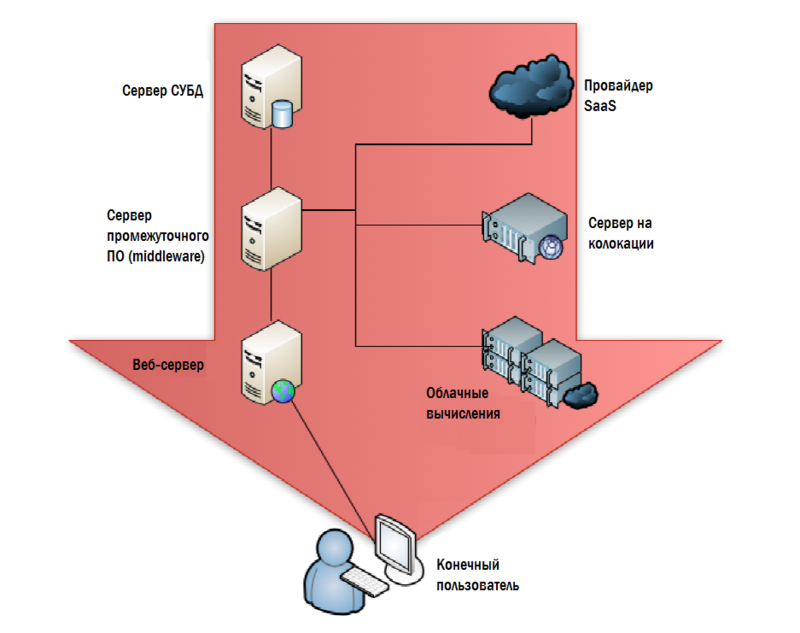
Рисунок 4.1: Мониторинг со стороны центра обработки данных.
Большинство SLA основаны на данном подходе. Мы прописываем в них определённое значение доступности сервиса, устанавливаем пороговые цифры для метрик, информация для которых собирается в датацентре: утилизация CPU, сети, дисков и т.д. Нам также интересны низкоуровневые параметры: время ответа на запросы, время ответа диска, задержки на сети и так далее.
Есть что-то глубоко неверное в исходных предпосылках данного подхода: если вам при строительстве достался прекрасный кирпич, не факт, что вы из него сумеете построить дом, который не развалится. Другими словами, то, что при своей работе ощущают конечные пользователи не является простой суммой технических метрик датацентра. Если ЦОД хорошо работает, то и пользователи обычно довольны, но это не всегда так.
Очевидно, что отслеживать ключевые параметры работы датацентра крайне важно, но это не единственные вещи, которые необходимо мониторить и измерять. Сейчас в индустрии бытует мнение, что нам необходимы прямые измерения того, что испытывает пользователь. По факту, «ощущения конечного пользователя» или EUE стали общеупотребительным термином в продвинутых кругах ИТ-менеджеров.
Можно привести и другой пример. Предположим, вы приходите в ресторан: ваш стейк, похоже, не прожарен, вам принесли не тот гарнир и официант хамит. А менеджер, который стоит на кухне, думает, что всё в порядке: стейк горячий, овощи тоже, а официант улыбается ему каждый раз, когда менеджер его(её) видит. Он думает только о кухонном бэкэнде, и ничего знает о ваших неоправдавшихся ожиданиях. В ресторанах эта проблема решается тем, что менеджер периодически выходит в зал и спрашивает гостей, всё ли в порядке? Именно так мониторятся EUE: вместо того, чтобы оценивать метрики нашей внутренней кухни, надо выходить в наше нагромождение кубиклов – в смысле, ресторан – и самим проверять, что там творится.
Как EUE позволяет сделать SLA лучше
Вы устанавливаете метрики для тех значений, которые в EUE, на самом деле, будут весьма отличаться: какое количество секунд необходимо для завершения такой-то транзакции и так далее. Если эта метрика не соответствует реальному положению дел, вы можете начать разбираться в деталях инфраструктуры, почему это не так. И нам снова надо нарисовать на картинке традиционный датацентр. Но при этом вместо использования метрики ‘время выполнения запроса' или еще какой-то чисто технической, мы возьмём метрику 'восприятие пользователя’ и используем ее для устранения неполадок, когда пользователь считает, что у нас что-то работает не так. Рисунок 4.2. показывает, как мониторинг EUE переворачивает нашу модель.

Рисунок 4.2: Мониторинг EUE.
У вас по-прежнему есть пороговые значения и другие ограничения, но они все выставлены на исторически сложившиеся уровни, при которых выполнялись EUE. Как показано на рис. 4.3., неработающий EUE — это ваша стартовая точка, с которой необходимо начинать разбираться в более глубоких и технических уровнях измерений, по которым можно установить, что составляет проблему конечного пользователя.

Рисунок 4.3: Отслеживание причины плохого EUE.
В реальной жизни возникшая проблема EUE не всегда сопровождается ощутимыми изменениями в бэкэнде. Время ответа сервера СУБД уменьшается на миллисекунду или две, что приводит к тому, что серверу приложений надо дополнительные полсекунды на обработку транзакций, что влечет за собой замедление на секунды сервера фронтэнда, отображающего следующую страницу информации, и в итоге пользовательское приложение отрабатывает на две секунды больше. Помножьте эти пару секунд на длительность рабочего дня, и вы обнаружите, что потерян час или больше, а пользователь вынужден говорить многим клиентам компании: «Извините, что так долго, компьютер что-то тормозит сегодня». На рис. 4.3., помечены красными флажками медленно отвечающие сервер СУБД и сервис облачных вычислений. По раздельности ни на одном из них не срабатывает тревога, но их совместная работа, вызывает проблему, заметную для конечного пользователя. Обычно небольшая флуктуация на сервере СУБД не вызывает срабатывания тревоги — к плохому EUE приводит целый каскад событий. Одно мы точно знаем: если EUE начинает отклоняться от ожидаемого – это повод начать расследование причин. Поскольку мы ищем источник проблемы, а не просто занимаемся обычным мониторингом, то будем более внимательно смотреть на небольшие отклонения в работе инфраструктуры.
Возможность измерять EUE позволяет вам создать более реалистичные SLA. Вместо того, чтобы говорить вашим пользователям «Мы гарантируем ответ системы на запрос в течение 2 секунд» вы скажете «Такая-то транзакция займёт не более 3 секунд времени для обработки». Это значит, что пользователь может эти вещи измерить сам: «Нажимаем ввод и считаем — один, два, три…о, получилось!». SLA такого типа устанавливают рамки, соотносимые с пользователем и понятные ему. Они знают, когда система стала работать медленно, потому что они измеряют те же самые вещи, что и вы.
В идеале, вы будете знать о снижении работоспособности системы до того, как это узнает пользователь, или весьма близко к тому, ведь у вас есть инструмент для измерения процессов с точки зрения пользователей.
Как это делается: Синтетические транзакции, отслеживание транзакций и прочее
Данный вид мониторинга не всегда прост. Конечно, не так сложно разместить агентов мониторинга на компьютеры конечных пользователей, но что делать с веб-приложением, где конечные пользователи, на самом деле — это внешние клиенты вашей компании? Они будут совсем не в восторге от предложения установить у себя агентское ПО для мониторинга, причём только для того, чтобы у вас была возможность измерять производительность вашего приложения.
Вместо этого современные системы мониторинга полагаются на способы отслеживания транзакций. В этом случае, мониторинг компонентов на вашем конце позволяет вам видеть, как конкретная транзакция проходит по всей системе с точным измерением времени от её начала до завершения. Это может быть сделано на различных уровнях детализации. Например, инструментарий, который позволяет выполнять профилирование производительности программного обеспечения, может выполнять очень подробное отслеживание информации через индивидуальные программные модули. На уровне системного управления, который находится чуть выше, вы можете отслеживать только время начала и конца транзакции.
Часто такой подход в определении реального состояния системы может быть выполнен вставкой в неё синтетических транзакций. Система мониторинга притворяется клиентом, помещает в систему транзакции, причем результат не будет вносить никаких изменений в данные и будет проигнорирован. Это даёт возможность системе мониторинга более подробно понимать действительное время исполнения различных операций. Такой подход проиллюстрирован на рис.4.4
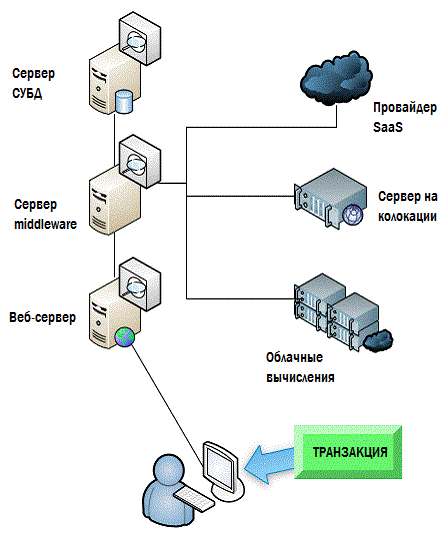
Рисунок 4.4: Использование отслеживания транзакций для мониторинга EUE.
Существует большое количество вариаций данных способов, а также специализированное ПО, с помощью которого это всё можно реализовать. Подводя краткий итог, хотелось бы сказать, что надо всегда помнить, что вся эта деятельность направлена на измерение только одной вещи: EUE. С этой точки зрения, вы не пытаетесь понять в каком состоянии у вас производительность системы, либо найти главный источник проблемы. Вы просто пытаетесь понять, а существует ли проблема вообще.
Мониторинг сверху вниз: от EUE до корня всего зла
EUE считается диагностикой крайне высокого уровня; она просто сообщает – «что-то пошло не так», но что конкретно — не говорит. Чтобы понять причины, вам надо вернуться в традиционную систему мониторинга, которую вы всегда знали и любили, только на этот раз, вы уже не будете смотреть в пустое место: вы будете искать источник гарантированно существующей проблемы.
Кстати, это ещё не тот момент, когда надо расчехлять специальное ПО – мы обсуждали это в предыдущих главах. Вы по-прежнему намерены использовать систему мониторинга, позволяющее видеть всё на «одном стекле». Однако, это совершенно не обязательно означает некоторую оболочку, объединяющую специализированный инструментарий, оно обозначает систему мониторинга, которая позволяет видеть каждую из ваших систем. Если у вас есть правильное понимание того, какова должна быть работоспособность на уровне каждого компонента, то такая система может быстро подсказать вам, где находится проблема. И вот лишь теперь можно достать специализированный инструмент и заняться решением частной проблемы – опять же, со знанием того, где находится проблема, и что компонент, на который вы смотрите, действительно является ее источником.
Откуда берётся EUE
Почему же нельзя просто использовать более тщательный подбор граничных значений в системе вашего мониторинга, отслеживающего состояние вашего бэкэнда из которого можно будет понять, что EUE отклоняется от ожидаемых значений? Причина в том, что EUE оценивает работу всей системы. База данных может работать медленнее, но при этом её поведение не сказывается на остальной части инфраструктуры. Медленно работающий маршрутизатор не обязательно приводит к ухудшению EUE, хотя в комбинации с остальными факторами может стать переломным моментом. Вот почему надо смотреть напрямую на то, как обстоят дела у конечных пользователей, а только затем искать корень всего зла.
Мониторинг с помощью агентов против мониторинга без агентов
Есть множество аргументов в пользу каждого из лучших способов мониторинга. Устанавливаете ли вы агенты? Некоторые люди так делают и считают, что агенты обеспечивают самый детальный способ предоставления информации. Другие не верят в инсталляцию агентов и, совершенно справедливо указывают, что далеко не на все элементы окружения можно в принципе установить агенты. Маршрутизаторы или сервисы, размещённые за пределами вашей ответственности, обычно не отдают никакой информации в программное обеспечение для мониторинга, либо поддерживают его с ограничениями.
В одном случае мы можем инсталлировать агенты, как это показано на рисунке 4.5
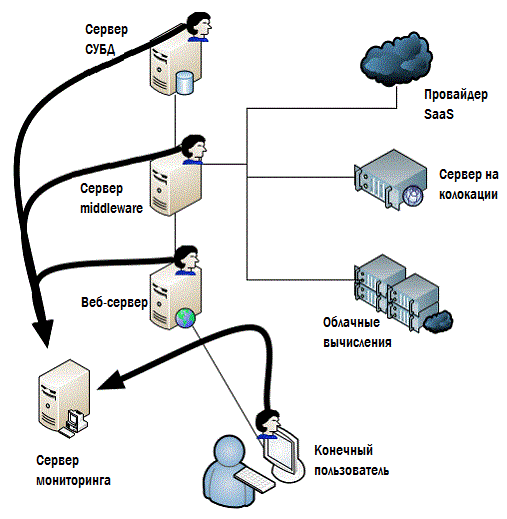
Рисунок 4.5: Мониторинг посредством агентов.
Обычно агенты возвращают информацию в централизованную систему мониторинга. В зависимости от выбранного подхода, вы можете поставить данные агенты везде, где они в принципе могут быть инсталлированы, возможно, даже на пользовательских компьютерах для точечного мониторинга (хотя обычно так стараются не делать)
Некоторые решения для мониторинга, позволят вам обойтись без установки агентов на каждой системе (возможно это и не потребуется делать везде). Как показано на рисунке 4.6, эти решения обычно используют внешние средства для оценки системной производительности.
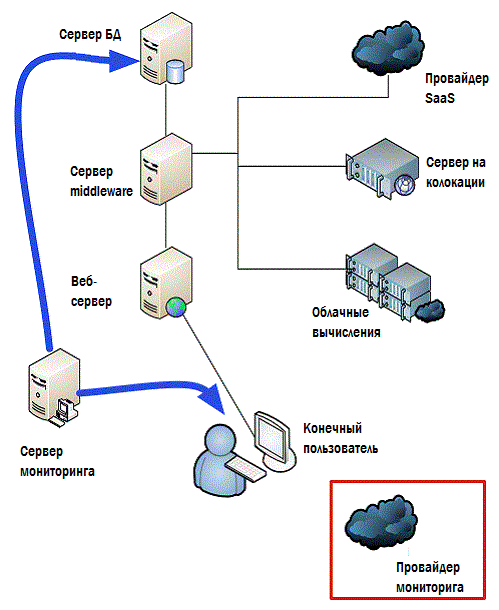
Рисунок 4.6: Безагентный мониторинг.
Может ли безагентный мониторинг собрать большое количество данных, или вообще все данные в принципе, во многом зависит от типа компонентов на вашей сети и какие технологии используются. Это является важным конкурентным моментом среди многих производителей ПО, и этому необходимо уделять пристальное внимание.
«Провайдер мониторинга» на рисунке 4.6. является моей отправной точкой, если мы говорим о современных приложениях. Вам же практически всегда придётся разворачивать гибридные системы, которые частично полагаются на агентов, а частично – на безагентный мониторинг, уже хотя бы потому, что некоторые из объектов мониторинга будут находиться за пределами вашего ЦОД.
Мониторинг того, что вам не принадлежит
Оборудование, находящееся за пределами нашего офиса и/или ответственности является тем местом, где обычный мониторинг не работает. Маловероятно, что Amazon будет вам передавать детальную статистику по работоспособности их Elastic Compute Cloud (EC2), вряд ли Microsoft сделает то же самое в отношении своей Windows Azure. SalesForce.com не собирается пересылать вам значения времени ответов СУБД или параметры утилизации центральных процессоров своих вебсерверов. Даже хостинговая компания, где вы размещаете ваши сервера не собирается показывать вам детальную информацию о процентном соотношении потерянных пакетов на своих маршрутизаторах и прочую статистику со своей инфраструктуры.
Но, вообще-то, эти цифры важны для вас. Если у вас есть приложение, зависящее от компонентов облачных вычислений, серверов, вынесенных на колокацию, решений SaaS или любого другого аутсорсного компонента, тогда работоспособность этих компонентов повлияет на производительность ваших приложений и ваше EUE. Короче говоря, если у Amazon будут проблемы с производительностью, у ваших пользователей будет то же самое. И вот тут на сцену выходит гибридный мониторинг. На рисунке 4.7 показано, что он имеет вид некоторого внешнего приложения мониторинга, собирающего ключевую информацию по производительности от большинства провайдеров аутсорсных услуг по «облачным компонентам». Собираемые данные показаны красными линиями, данные которые передаются на вашу центральную консоль мониторинга – зеленым.
Много из того, что я перечислял в предыдущих главах, начинает собираться в одну картину:
- Вам нужны ваши внутренние системы и внешние компоненты, отображаемые в едином представлении. Нет способа работать с вашими подсистемами как с системой, если у вас нет возможности собрать все составные части в единое пространство мониторинга.
- Ключевым конкурентным свойством для гибридных сервисов мониторинга является количество внешних компонентов, которые могут контролироваться. Удостоверьтесь, что выбираемое вами решение в состоянии мониторить всё, что у вас есть, в том числе сервисы и оборудование, находящееся на аутсорсинге.
- Становится важным отслеживание ожиданий пользователя EUE, потому что могут быть большие флуктуации между внешними сервисами и вашим использованием их. Например, вам совершенно не нужно быть в курсе, отвечает ли медленно Azure во время периодов, когда пользователи не используют этот сервис. Вам необходимо обращать на него внимание, и получать извещения о его состоянии только, если ваши пользователи испытывают проблемы во время работы с ним.

Рисунок 4.7: Гибридный мониторинг.
На самом деле, данный способ мониторинга внешних, вынесенных на аутсорсинг компонентов, является ключевым моментом, потому что большинство организаций чувствует, что они не могут полагаться на облачные вычисления. «Как мы этим будем управлять?»,-задают они себе вопросы,-«Как мы это будем мониторить?». Помимо безопасности данных, это, возможно самый серьёзный вопрос, возникающий, когда компании начинают рассматривать добавления «облаков» в их портфель ИТ-решений. Их можно мониторить именно таким образом: использованием специализированных сервисов мониторинга, добавляющих «облако» на ваш единый контрольный экран. Подобные инструмены помещают компоненты, вынесенные за пределы компании на тот же уровень контроля, что и локальные компоненты, и позволяют вам мониторить их сходным образом.
Интересен путь, которые выбирают некоторые вендоры при разработке архитектуры подобных решений. Многие из них продают локальные решения, которые во многом похожи на то, что нарисовано на рис. 4.7. В действительности они выполняют мониторинг облачных компонентов на стороне провайдера, но при этом отправляют эту информацию к вам; затем их решение собирает данные с вашего локального оборудования и представляет информацию в консолидированном виде.
Но это не единственный способ. На рис. 4.8. приведена схема выносного (hosted) решения для мониторинга, в котором ваша внутренняя информация о производительности пересылается в облако (показано синими линиями), затем в облаке производится объединение с информацией о работоспособности ваших облачных компонентов (красные линии) и отображается в едином представлении на веб-портале или еще каким-то другим способом.

Рисунок 4.8: Внешний, гибридный мониторинг.
Это достаточно интересная модель, снимающая с вас большую часть ответственности за мониторинг, что позволяет вам сконцентрироваться на сервисах, предоставляемых пользователям. Но не следует думать, что она будет правильной моделью для любой организации, хотя, как вариант, её рассматривать стоит.
Критические пределы: Когда вам надо контролировать всё
Последний важный элемент головоломки – удостовериться, что вы мониторите всё. Всё-всё-всё!!! Посмотрите на рис.4.9, с инфраструктурой, которую мы использовали во всей этой главе. Что-нибудь на ней пропущено? Если мы отслеживаем каждый из показанных компонентов, будет ли мониторинг достаточен?
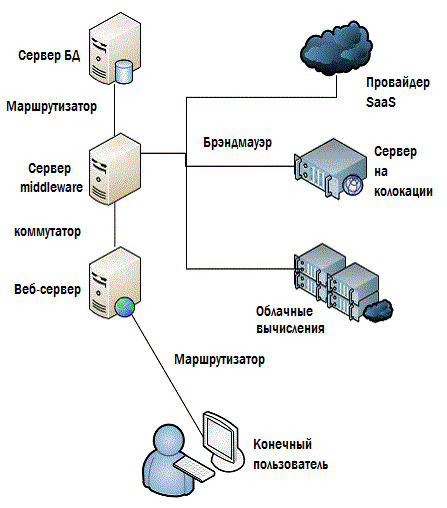
Рисунок 4.9: Всё ли здесь, что должно контролироваться?
Определённо – нет. На данной схеме есть много пропусков и в своей большей части это вещи, которые могут иметь существенное влияние на производительность. Посмотрите на рис.4.10 – здесь всё немного полнее и подробнее.
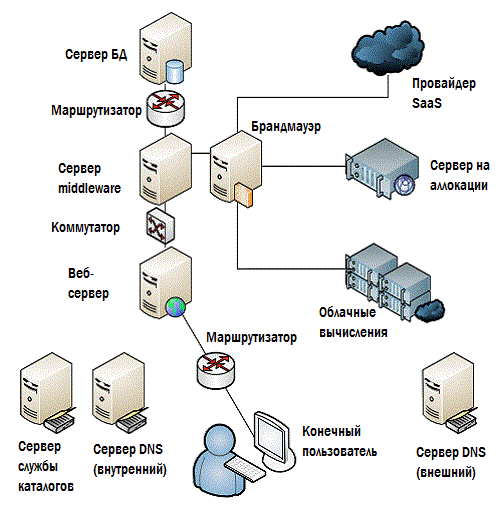
Рисунок 4.10: Удостоверьтесь в том, что вы контролируете всё.
Маршрутизаторы, коммутаторы, брэндмауэры, серверы службы каталогов, DNS – внешние и внутренние, и возможно, много чего ещё. Если ваше EUE начинает отклоняться от привычных значений, то навреное, вам уже пора искать корень зла; но вы сумеете это сделать, только если ваше решение мониторинга может видеть любую потенциальный источник проблемы.
Именно по этой причине большинство решений мониторинга в наши дни предлагают функцию автообнаружения, а кроме того всегда есть возможность самостоятельного добавления компонентов. Автообнаружение может поймать пропущенные вещи, про которые никто даже и не предполагал, что они тоже часть общей системы. Инфраструктурные элементы, такие как маршуртизаторы и коммутаторы. Зависимости между службами каталогов и DNS. Потенциальные узкие места типа файерволов и прокси-серверов. Это всё важно для нормальной работы, и необходимо, чтобы всё было собрано в единую картину, через которую будет контролироваться общее состояние системы.
Заключение
Мониторинг – это решение, которое позволяет нам управлять SLA, помогает выяснить место, где зарождается проблема, и помогает нам поддерживать системы в состоянии пригодном для выполнения бизнесом своих задач. Но традиционный мониторинг не всегда означает единственный или наилучший путь соответствия нуждам бизнеса. Что более важно, по мере того как бизнес всё чаще зависит от компонентов, находящихся за пределами своих локальных систем, традиционный мониторинг не может собрать всю необходимую информацию в единое пространство. Зато эти задачи по силам системам гибридного мониторинга. Используя комбинацию из методик традиционного мониторинга, получения данных производительности из облачных систем, а также других способов, мы можем собрать информацию о работоспособности систем в единое представление, общую панель индикаторов и целостную картину.
В следующей главе…
В следующей главе мы обратимся к фундаментальной проблеме, с которой приходится бороться каждой организации: повторяемость. Другими словами, после того как проблема решена, каким образом вы сумеете её быстрее решить, если она вдруг случается снова? Мы рассмотрим, как превратить проблемы в решения и как нам в будущем улучшить предоставление сервисов.







