Комментарии 72
Жалею, что кончились времена, когда гугль не знал русской морфологии: выдача шла абсолютно точно по поисковому запросу. Нынче надо кавычки колдовать, да и то не помогает.
// ПАРАНОЙЯ
Зато нынче Гугл ищет сам даже то, что еще не успели у него спросить. Особенно Гугл-новости на Андроиде — показывают новости по темам, которые «могут» тебя заинтересовать. Скоро Гугл будет мягко управлять нашим мышлением, подсказывать нам, куда мы «могли бы захотеть» пойти, что сделать, за кого проголосовать, что купить…
// КОНЕЦ ПАРАНОЙИ
Зато нынче Гугл ищет сам даже то, что еще не успели у него спросить. Особенно Гугл-новости на Андроиде — показывают новости по темам, которые «могут» тебя заинтересовать. Скоро Гугл будет мягко управлять нашим мышлением, подсказывать нам, куда мы «могли бы захотеть» пойти, что сделать, за кого проголосовать, что купить…
// КОНЕЦ ПАРАНОЙИ
Угу, меня всегда умиляет, особенно если пишешь точную фразу. Казалось бы ищи ее да показывай в первую очередь. Ан нет, навервху всякий [проплаченный/сеонутый?] шит. Берешь фразу целиком в кавычки — сразу находит, что надо…
Это если угадал, в противном случае может вообще ничего не найти.
Так ничто же не мешает показать поиск по точной фразе просто выше остального, верно?
выдача шла абсолютно точно по поисковому запросу
Справедливости ради, точные результаты — если они вообще есть — обычно ранжируются выше, чем «похожие». Сколько раз убеждался, что после добавления кавычек в любой форме (вокруг фразы, вокруг слов) выдача совсем не улучшается — просто выясняется, что точных результатов вообще нет.
В целом, выдача похожих результатов и «чтение мыслей» почти всегда идут на пользу. Например, ищешь "* sucks" (поиск резких отрицательных отзывов), и если Гугл не находит таких результатов, то показывает "* reviews" или что-нибудь типа этого. Мелочь, а приятно.
DuckDuckGo же!
Вам определенно поможет эта опция:
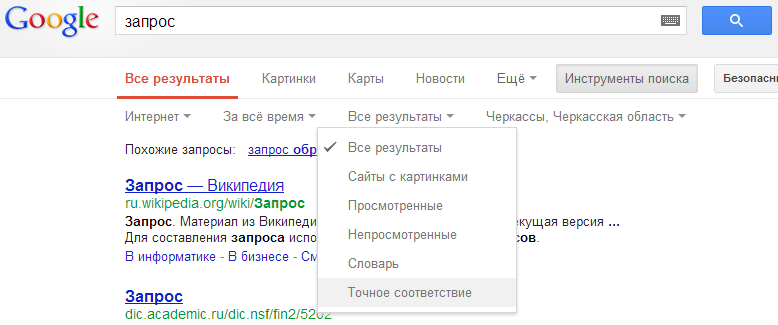

в таких случаях мне помогает intext оператор.
intext:«Ваша фраза»
intext:«Ваша фраза»
| Морфология у Google организована «правильнее»
А почему это правильнее? Ну хранят они сто тыщ миллионов словоформ, а при запросе добавляют веер синонимов, ну дает это в каких-то случаях вроде бы лучший результат, но вот лучше ли это для построения всяких сложных семантических связей, и что лучше подходит корпусу русского языка, и это все еще с перспективой развития?..
Мне почему-то казалось что такая организация индекса проистекает как раз из желания лучше соответствовать языку, а не экономией. Да и вообще про экономию байтиков — как-то смешно не верится.
А почему это правильнее? Ну хранят они сто тыщ миллионов словоформ, а при запросе добавляют веер синонимов, ну дает это в каких-то случаях вроде бы лучший результат, но вот лучше ли это для построения всяких сложных семантических связей, и что лучше подходит корпусу русского языка, и это все еще с перспективой развития?..
Мне почему-то казалось что такая организация индекса проистекает как раз из желания лучше соответствовать языку, а не экономией. Да и вообще про экономию байтиков — как-то смешно не верится.
НЛО прилетело и опубликовало эту надпись здесь
Мне почему-то казалось что такая организация индекса проистекает как раз из желания лучше соответствовать языку, а не экономией.
Русский язык (как впрочем и любой другой буквенный) — величина непостоянная и зависит от настроения пользователя. Поэтому руководствоваться правилами — ну никак не подпадает под «желание лучше соответствовать языку». Гугл правильно сделал, что вместо написания «правил» стал собирать статистику использования слов в похожих контекстах. Оно хоть и даёт корявый результат на первых порах (привет google translate и его смешные переводы миль в километры и долларов в рубли), но с накоплением базы выдаёт результат ближе к реальности, а не к неким «правилам».
1. вы увидели некие артефакты у яндекса, но на выдачу они же не влияют? Собственно я не увидел почему сжатый словарь чем-то хуже.
Байку про купить и покупать можно обьяснить просто тем что вносились изменения позже и решили старое решение не трогать.
2. вы не нашли артефакты у гугла, но это доказывает что их нет
Я собственно не увидел реального сравнения результатов выдачи где один из поисковиков был бы однозначно хуже из-за проблем с морфологией.
Байку про купить и покупать можно обьяснить просто тем что вносились изменения позже и решили старое решение не трогать.
2. вы не нашли артефакты у гугла, но это доказывает что их нет
Я собственно не увидел реального сравнения результатов выдачи где один из поисковиков был бы однозначно хуже из-за проблем с морфологией.
Из статьи:
Сказать, что у Google лучше выдача чем у Яндекса только на основе морфологии, тоже самое что оценивать интеллект по высоте лба. Цель статьи была в развеивании убеждения о том, что морфология в Google организована хуже чем в Яндексе.Из комментария к статье:
Я собственно не увидел реального сравнения результатов выдачи где один из поисковиков был бы однозначно хуже из-за проблем с морфологией.;)
Очень часто ищешь по конкретной форме слова конктретную статью, не помня сайта, и тут вот яндекс лажает. вполне себе кейс
НЛО прилетело и опубликовало эту надпись здесь
Без обид, ни в чей адрес: «Работать может и медведь, а вот искать надо уметь».
Т.е. кто-то не согласен со мной и не считает, что у каждого свои предпочтения в поисковиках и методах поиска? Не понимаю, за что минус.
p.s.
Эх, печально. Не лень человеку было не только минусануть за что-то комментарий (пояснять своё несогласие не в моде у таких), так ещё и в профиль зайти, карму слить. Ребят, откуда столько злости?
p.s.
Эх, печально. Не лень человеку было не только минусануть за что-то комментарий (пояснять своё несогласие не в моде у таких), так ещё и в профиль зайти, карму слить. Ребят, откуда столько злости?
В итоге нам понадобиться
Не стыдно в статье про русский язык писать с ошибками?
И не только здесь ошибка.
Это артефакты сжатия.
О, начались кармаминусования за то, что указываю на ошибки.
Ок, тогда поработаю ещё корректором, раз уж такое дело.
то же самое…
Это показывает то, что…
P.S. И не надо говорить, что о подобных ошибках следует указывать в личку — пусть другие тоже видят.
Ок, тогда поработаю ещё корректором, раз уж такое дело.
тоже самое что оценивать интеллект
то же самое…
Это показывает, то что подсветка
Это показывает то, что…
P.S. И не надо говорить, что о подобных ошибках следует указывать в личку — пусть другие тоже видят.
Сначала плюсанул Вашу позицию, а потом задумался: что видят-то?
В тексте автор исправит ошибку, значит увидят только комментарий, что ошибка была.
И что тут поучительного? Почему эта ошибка поучительна, а другая, у соседнего комментатора — нет? Для поучительных ошибок есть специальные сайты.
Получается, что комментарий остается просто чтобы потешить самолюбие или в качестве доказательства, что комментатор был в чем-то круче автора.
Пусть не смущают «наезды» про самолюбие, это я просто рассуждаю вслух, без реальных претензий.
В тексте автор исправит ошибку, значит увидят только комментарий, что ошибка была.
И что тут поучительного? Почему эта ошибка поучительна, а другая, у соседнего комментатора — нет? Для поучительных ошибок есть специальные сайты.
Получается, что комментарий остается просто чтобы потешить самолюбие или в качестве доказательства, что комментатор был в чем-то круче автора.
Пусть не смущают «наезды» про самолюбие, это я просто рассуждаю вслух, без реальных претензий.
Плохой с Вас корректор — пропустили «не много», которое должно писаться слитно с том случае.
Первое, что приходит в голову, так это то, что вы нашли примеры, когда Яндекс заменил глагол в вашем запросе, не по правилу морфологии, а с учетом контекста, что собственно верно в данном случае, т.е. контекст значимее морфологии одного слова из запроса.
Попробуйте ввести в поиск любой из перечисленных глаголов один в поиск Яндекса, никаких поисков синонимов вы там не найдете.
Попробуйте ввести в поиск любой из перечисленных глаголов один в поиск Яндекса, никаких поисков синонимов вы там не найдете.
Ещё Яндекс совершенно произвольно игнорирует любую часть запроса.
Стоит мне, например, в запросе поставить галочку «в Санкт-Петербурге», как я получаю совершенно нерелевантную простыню ссылок, по которым кроме слов «санкт петербург» к моему запросу не относится вообще ничего. «Плюсики» не спасают. Недавний пример — кроме первой ссылки к основному слову запроса («кмп201уп1а») не относится ни одна страница вплоть до … я даже не знаю, до какой. Устал листать.
Стоит мне, например, в запросе поставить галочку «в Санкт-Петербурге», как я получаю совершенно нерелевантную простыню ссылок, по которым кроме слов «санкт петербург» к моему запросу не относится вообще ничего. «Плюсики» не спасают. Недавний пример — кроме первой ссылки к основному слову запроса («кмп201уп1а») не относится ни одна страница вплоть до … я даже не знаю, до какой. Устал листать.
А можно узнать откуда вы взяли такие цифры? В частности 500.000 слов в русском языке, по 75 словоформ на слово, средняя длина слова 10 символов? По-моему, они явно преувеличены.
Не поленился, открыл девелоперскую консоль:
Подсчет, конечно, грубый, но порядок цифр дает. До 10 символов в среднем не дотягивает.
$('.content').text().split(' ')
Array[688] // 688 слов, значит
$('.content').text().length
4983 // символов в тексте с пробелами
4983 - 688
4296 // символов в тексте без пробелов
4296 / 687
6.244186046511628
Подсчет, конечно, грубый, но порядок цифр дает. До 10 символов в среднем не дотягивает.
Вот тебе и морфология. 
Моя внутренняя морфология, вообще, прочитала как «человечество ведут к половому счастью»
Так а при чем тут морфология? Вы написали слово которое не существует в русском языке, а гугль просто не смог вычислить, что именно вы имели в виду.
Сравните в выдачей: goo.gl/THU51 Яндекс тоже исправил слово на уголовному, но при этом на 5ой позиции есть нужный вариант. В выборке Гугла на первой странице этого замечено не было.
вставлю свои 5 копеек: Поголовное счастье от Yahoo
Вообще теперь часто им пользуюсь, когда устаю от гугла и яндекса
Вообще теперь часто им пользуюсь, когда устаю от гугла и яндекса
Я тоже хотел было это сказать, что, дескать, слово введено с ошибкой, ближайшее релевантное слово к нормализованному и есть «поголовный», которое все-таки есть в словаре Гугла, как и слово «поголовному», и что морфология имеет отношение к словообразованию и, соответственно, исправлению ошибок,… бла-бла-бла. Но сделал коррекцию на аудиторию хабра и на ее внимательность. Поэтому не стал озвучивать очевидные вещи. А на других форумах, вы правы, я обязательно бы это сделал.


Здравствуйте, все-таки у вас статья не про морфологию, а про поисковые расширения (query expansion). И вроде яндекс не скрывает — периодически рассказывает на конференциях и про то и про другое, как оно устроено, как улучшается.
Очевидно, поисковые расширения (в общем смысле — синонимы) менее точны, чем морфология.
Для того, чтобы сравнивать что-либо по сниппетам необходимо сначала убедиться, что поисковые системы хотя бы подсвечивают одинаково то, что действительно используют на поиске.
Можно даже статистически — по количеству и разнообразию подсвечиваемых форм, отличных от исходной на какой-нибудь выборке запросов.
Гугл вроде расширения почти не подсвечивает — в основном морфологию, поэтому вы и не наблюдаете «артефакты». Причины отличия выдачи — тоже не очевидный вопрос, т.к. непонятно — это из-за разного ранжирования, или из-за расширений.
В итоге получается, что вы делаете выводы, отталкиваясь от неверных предположений и на основе выборки из трех запросов про клизмы :).
Очевидно, поисковые расширения (в общем смысле — синонимы) менее точны, чем морфология.
Для того, чтобы сравнивать что-либо по сниппетам необходимо сначала убедиться, что поисковые системы хотя бы подсвечивают одинаково то, что действительно используют на поиске.
Можно даже статистически — по количеству и разнообразию подсвечиваемых форм, отличных от исходной на какой-нибудь выборке запросов.
Гугл вроде расширения почти не подсвечивает — в основном морфологию, поэтому вы и не наблюдаете «артефакты». Причины отличия выдачи — тоже не очевидный вопрос, т.к. непонятно — это из-за разного ранжирования, или из-за расширений.
В итоге получается, что вы делаете выводы, отталкиваясь от неверных предположений и на основе выборки из трех запросов про клизмы :).
Вот еще один артефакт в Гугле:
«Человек» не имеет словоформы «Люди».
Учитывая найденное Вами, что «Хороший» != «Лучший», можно утверждать, что в морфологии Гугля нет нулевых основ.
И это несомненно хуже, чем у Яндекса, который такие случаи разбирает.
Так что недостатки есть во обеих морфологиях.
Однако недостатки морфологии Гугла не прикрыты синонимами, как в Яндексе.
Поэтому в целом Гугл работает с русским языком хуже Яндекса, что, в общем-то, очевидно.
«Человек» не имеет словоформы «Люди».
Учитывая найденное Вами, что «Хороший» != «Лучший», можно утверждать, что в морфологии Гугля нет нулевых основ.
И это несомненно хуже, чем у Яндекса, который такие случаи разбирает.
Так что недостатки есть во обеих морфологиях.
Однако недостатки морфологии Гугла не прикрыты синонимами, как в Яндексе.
Поэтому в целом Гугл работает с русским языком хуже Яндекса, что, в общем-то, очевидно.
То что Гугл синонимы не подсвечивает не значит, что у него их нет.
Про нулевую псевдооснову, скорее всего вы правы. Но нулевая псевдооснова только в нескольких десятках слов.
Про нулевую псевдооснову, скорее всего вы правы. Но нулевая псевдооснова только в нескольких десятках слов.
Вы же требуете строгости в морфологии, значит десятки слов важны.
Ваши же примеры вообще не видны без специальных приемов отделения морфологии от синонимов.
Ведь без плюсика выдача на «сделать» и «делать» у Яндекса практически одинаковая.
А теперь получите «шел» через «идет» в Гугле.
Теперь насчет подсветки.
Вы же проверяете Яндекс через подсветку. Почему же нельзя то же делать по отношению к Гуглу?
К тому же я не утверждал, что у Гугла нет никаких синонимов. А только то, что синонимами не закрыты промахи морфологии.
Ваши же примеры вообще не видны без специальных приемов отделения морфологии от синонимов.
Ведь без плюсика выдача на «сделать» и «делать» у Яндекса практически одинаковая.
А теперь получите «шел» через «идет» в Гугле.
Теперь насчет подсветки.
Вы же проверяете Яндекс через подсветку. Почему же нельзя то же делать по отношению к Гуглу?
К тому же я не утверждал, что у Гугла нет никаких синонимов. А только то, что синонимами не закрыты промахи морфологии.
По запросу [15 людей на сундук мертвеца] «человек» в гугле вполне себе находится.
Думаю, ошибаетесь.
Задайте «15 людей на сундук мертвеца» — в кавычках в Яндексе и в Гугле.
Задайте «15 людей на сундук мертвеца» — в кавычках в Яндексе и в Гугле.
Кажется, кавычки отключают морфологию у Гугла.
Ну можно посмотреть на запрос [эволюция людей]. Там «человека» даже подсвечивается в выдаче.
Ну можно посмотреть на запрос [эволюция людей]. Там «человека» даже подсвечивается в выдаче.
Морфология здесь ни при чем.
Это как раз синонимы Гугла (эволюция людей = эволюция человека)
[Эволюция людей по Дарвину] — выдает и «Эволюцию человека», а вот [людей по Дарвину] — сразу «человек» пропадает.
Это как раз синонимы Гугла (эволюция людей = эволюция человека)
[Эволюция людей по Дарвину] — выдает и «Эволюцию человека», а вот [людей по Дарвину] — сразу «человек» пропадает.
А как Вы различаете морфологию и синонимы?
Синонимами считается то, что зависит от контекста, а морфология — то что не зависит?
Синонимами считается то, что зависит от контекста, а морфология — то что не зависит?
Можно, конечно, сослаться на Википедию, но это будет отписка.
Сошлюсь на статью, которую мы тут обсуждаем. В ней хорошо разделены морфология и синонимы.
Ну а в данном случае все просто.
Для Гугла синонимы только «эволюция людей» = «эволюция человека» целиком. Но не отдельные слова.
Сошлюсь на статью, которую мы тут обсуждаем. В ней хорошо разделены морфология и синонимы.
Ну а в данном случае все просто.
Для Гугла синонимы только «эволюция людей» = «эволюция человека» целиком. Но не отдельные слова.
Я все же не очень понял, как отличить по внешним признакам, что для Гугла чем является.
На самом деле, для меня, как пользователя, это совершенно не важно.
Мне важно, что «эволюция людей» = «эволюция человека», а «люди дождя» != «человек дождя».
Ну то есть, считаются два слова в каком-то смысле взаимозаменяемыми для каждого конкретного запроса или нет.
А называются они там внутри поисковика синонимами или морфологией на результат не влияет.
На самом деле, для меня, как пользователя, это совершенно не важно.
Мне важно, что «эволюция людей» = «эволюция человека», а «люди дождя» != «человек дождя».
Ну то есть, считаются два слова в каком-то смысле взаимозаменяемыми для каждого конкретного запроса или нет.
А называются они там внутри поисковика синонимами или морфологией на результат не влияет.
И вообще, без конкретных запросов ничего не очевидно. Даже если какие-то две формы конкретного слова не связываются между собой, это не всегда вредит качеству. Иногда их наоборот не стоит связывать («альф»->«альфа»).
НЛО прилетело и опубликовало эту надпись здесь
Вопрос: а применяется нечеткий слуховой поиск у yandex и google? ;)?
Судя по тому что ты можешь набирать латинцей и с грамматическими ошибками — применяется.
Или там одна только морфология? ;) Скорее всего нет… Не везде идет четкий посик (специально набрал с ошибкой но в нечетком слуховом поиске что «посик», что «поиск» имеет одинаковое числовое представление — 745000, и тут морфологией и не пахет!)
А с точки зрения морфологии — совершенно разные слова
Судя по тому что ты можешь набирать латинцей и с грамматическими ошибками — применяется.
Или там одна только морфология? ;) Скорее всего нет… Не везде идет четкий посик (специально набрал с ошибкой но в нечетком слуховом поиске что «посик», что «поиск» имеет одинаковое числовое представление — 745000, и тут морфологией и не пахет!)
А с точки зрения морфологии — совершенно разные слова
Всё это замеры сферического коня в вакууме… Малопоказательны и малоприменимы для оценки «адекватности» русскому языку.
Если отвлечься от темы статьи и говорить о «сферическом» удовлетворении поисковой системой, то я для себя четко уяснил: надо найти по обычной фразе (разговорной) или названии на русском — бери яндекс, надо искать что-то академическое/техническое (с терминами, особенно англоязычными или фрагментами кода) — однозначно гугл. (Думаю тут дело просто в охвате индексируемых страниц/сайтов).
Если отвлечься от темы статьи и говорить о «сферическом» удовлетворении поисковой системой, то я для себя четко уяснил: надо найти по обычной фразе (разговорной) или названии на русском — бери яндекс, надо искать что-то академическое/техническое (с терминами, особенно англоязычными или фрагментами кода) — однозначно гугл. (Думаю тут дело просто в охвате индексируемых страниц/сайтов).
О факте сжатия морфологии в Яндексе и причины этого сжатия — это ваши догадки или проверенная информация от разработчиков Яндекса? Если догадки, предлагаю так и написать.
1) Во-первых, из вашей статьи пропала часть изображений, пожалуйста перезалейте на habrastorage.
2) Во-вторых, вы написали какие-то догадки того, как всё это устроено, а ничем свои предположения не подтвердили. Сослались бы на блоги, выступления представителей компаний что ли. А сравнения результатов поиска как таковых нет в вашем посте. См. пункт «в-третьих».
3) В-третьих, мне больше по душе сжатая морфология, или, скорее, те преимущества, что она даёт. Давайте попробуем загуглить редчайшее слово, которого не существует в русском языке: «белколярный». Google ничего не находит, Ядекс находит слово в форме женского рода.
2) Во-вторых, вы написали какие-то догадки того, как всё это устроено, а ничем свои предположения не подтвердили. Сослались бы на блоги, выступления представителей компаний что ли. А сравнения результатов поиска как таковых нет в вашем посте. См. пункт «в-третьих».
3) В-третьих, мне больше по душе сжатая морфология, или, скорее, те преимущества, что она даёт. Давайте попробуем загуглить редчайшее слово, которого не существует в русском языке: «белколярный». Google ничего не находит, Ядекс находит слово в форме женского рода.
У Yandex морфология что-то хромает. Много раз натыкался на то, что он при поиске очевидно пытался выделить у слова корень, но ошибался и в результате находил совсем не то, что от него ожидалось. Примерно как тут versusit.ru/google-vs-yandex автор пишет Сокольники. Yandex находит Сокол.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Чья морфология лучше? Яндекс vs Google