Комментарии 169
У rebase есть одна хорошая вещь — он может squash'ить коммиты, т.е. объединять несколько в один.
Однажды это меня здорово спасло, когда коллега запушил файлы с виндовыми окончаниями строк вместо юниксовых (т.е. весь файл считался измененными и невозможно было понять, что же поменялось).
Однажды это меня здорово спасло, когда коллега запушил файлы с виндовыми окончаниями строк вместо юниксовых (т.е. весь файл считался измененными и невозможно было понять, что же поменялось).
Да, про интерактивный режим ребейза стоит написать отдельную статью )) Тут я рассматривал rebase именно как механизм слияния изменений. Вообще его возможности богаче.
А что скажите об autocrlf = true
Просто сам спасаюсь именно этой настройкой, но думаю вдруг чего упустил.
Просто сам спасаюсь именно этой настройкой, но думаю вдруг чего упустил.
Прекрасная настройка, но проблема в том, что коммит уже был сделан, когда мы обнаружили, что у коллега она не включена.
.gitattributes хорошая штука. Можно указать какие переносы строк в каких файлах использовать. Правда это все 100% работает если Вы используете git (а не JGit — насколько я помню там еще эта штука не поддерживается — поправьте, если уже да). Разница между настройкой и .gitattributes в том, что файлик находится в репозитории и там уже тяжело ошибиться. При коммите он насильственно будет использовать нужные переводы строк, что собственно и нужно. Ошибиться довольно тяжело.
Не слышал, спасибо за инфу.
А что, она помогает пост-фактум, после коммита?
А что, она помогает пост-фактум, после коммита?
Хорошая вещь. Но мне нужно было поправить пост-фактум.
Сделал коммит с исправлением окончаний строк, потом засквошил коммиты коллеги и свой в один.
Сделал коммит с исправлением окончаний строк, потом засквошил коммиты коллеги и свой в один.
Можно было сделать через filter-branch.
Расскажите, если не трудно?
Я не большой эксперт в filter-branch, в основном нахожу ответы на SO. Окончания фиксятся примерно так: stackoverflow.com/a/1060828/259946 (лично не проверял)
Она не всегда спасает. Вот тут сказано почему stackoverflow.com/questions/2333424/distributing-git-configuration-with-the-code/2354278#2354278
Из собственного опыта скажу что git blame <имя_файла> на виндовой машине будет говорит, что изменения not commited. Поскольку в репозитории юниксовые, а на винде виндовые и он думает что файл изменился. И поэтому надо прописывать git blame HEAD <имя_файла>. Также при мерджах возникает конфликт, но после вызова mergetool сразу говорит, что разрешён. Почему так еще не разобрался…
Из собственного опыта скажу что git blame <имя_файла> на виндовой машине будет говорит, что изменения not commited. Поскольку в репозитории юниксовые, а на винде виндовые и он думает что файл изменился. И поэтому надо прописывать git blame HEAD <имя_файла>. Также при мерджах возникает конфликт, но после вызова mergetool сразу говорит, что разрешён. Почему так еще не разобрался…
Отличная статья! Все расписано очень внятно и доходчиво, спасибо.
наконец-то есть что-то годное про rebase на русском чтобы дать почитать вместо того чтобы объяснять снова :)
Для чего перебазировать фиче-бранчи? Только ради эстетического удовольствия или есть еще какой-то в этом сакральный смысл?
Что бы сливаться без конфликтов, простым FF
Вы лукавите.
Допустим у вас в master есть изменения файла A и в ветке feature-1 есть N изменений этого же файла, и причем где-то в ближе к ветвлению есть конфликтующие изменения, то конфликты вы будете разрешать для этого файла >=N раз. Для сравнения с merge — 1 раз. А если не дай бог вы ошибетесь при разрешении конфликтов где-то в начале…
Для того чтобы сливаться без конфликтов есть rerere.
Допустим у вас в master есть изменения файла A и в ветке feature-1 есть N изменений этого же файла, и причем где-то в ближе к ветвлению есть конфликтующие изменения, то конфликты вы будете разрешать для этого файла >=N раз. Для сравнения с merge — 1 раз. А если не дай бог вы ошибетесь при разрешении конфликтов где-то в начале…
Для того чтобы сливаться без конфликтов есть rerere.
Если вы несколько раз меняете один и тот же файл, одно и то же место — то такие коммиты лучше squash-ить.
Да проблема о которой вы говорите, есть и решается она rerere и squash-ем. Merge в данном случае позволяет слиться быстрее — это факт.
Да проблема о которой вы говорите, есть и решается она rerere и squash-ем. Merge в данном случае позволяет слиться быстрее — это факт.
Не обязательно в моей ветке менять одни и те же строки, достаточно в разных ветках эти строки поменять. В моем случае (я .NET программист) очень большую проблему представляют файлы проектов Visual Studio, т.к. студия добавляет файлы практическое случайное место в проект. А решать конфликты в .proj файлах ну очень неприятно.
Т.е. я не хочу сквошить коммиты из-за какого-то там файла проекта, который по большому счету вообще не нужен. И rerere на нем плохо работает:(
Т.е. я не хочу сквошить коммиты из-за какого-то там файла проекта, который по большому счету вообще не нужен. И rerere на нем плохо работает:(
вы будете разрешать для этого файла >=N раз
Почему больше N? Разве не 1..N?
Действительно, может оказаться так, что конфликты в одном и том же месте придется разрешать несколько раз. Но есть большая вероятность, что они окажутся проще, чем при merge.
Без мержей, а не конфликтов.
Конфликты могут быть в обоих случаях.
Конфликты могут быть в обоих случаях.
Если Вы отребейзили фиче-ветку от мастера, то она вливается в мастер без конфликтов. Я писал об этом
Но, по большому счету, основной смысл в ребейзе — поддерживать порядок в графе ревизий.
Эстетический порядок? А зачем?
когда одновременно есть десяток-два веток становится сложно в этом ориентироваться. И не всегда все ветки вливаются в мастер, периодически фичи вливаются в фичи, особенно если над одной большой задачей работает несколько разработчиков.
Я бы не сказал, что дело только в эстетике. Ретроспективный анализ кода. Подготовка кода к слиянию. На мой взгляд отребейзенная ветка гораздо удобнее для этого. Вообще ребейз — не замена merge — вы после ребейза все равно делаете merge по fast-forward или без него, rebase — способ подготовить ваши изменения к этой операции. Помните, что отребейзенная ветка содержит в себе самый актуальный код, так как будто вы только что ее создали и внесли свои изменения, это позволяет протестировать ваши изменения до слияния их в мастер на самой актуальной кодовой базе. Убедил?
Да, я ждал этого комментария. С ссылкой наголо martinfowler.com/bliki/SemanticConflict.html
Дело в том, что в случае rebase все коммиты из фиче-бранча, кроме последнего (иногда и он) теряют свой смысл, кроме как «посмотреть».
Т.е. теряется смысл контроля версий.
В исходной статье коммиты C' и D' будут в лучшем случае в немного некорректном состоянии. Т.е. на них нельзя будет откатиться (отсюда появилась потребность в no-ff мерджах). К тому же, возможно придется добавить коммит F, который будет разрешать семантические конфликты.
Дело в том, что в случае rebase все коммиты из фиче-бранча, кроме последнего (иногда и он) теряют свой смысл, кроме как «посмотреть».
Т.е. теряется смысл контроля версий.
В исходной статье коммиты C' и D' будут в лучшем случае в немного некорректном состоянии. Т.е. на них нельзя будет откатиться (отсюда появилась потребность в no-ff мерджах). К тому же, возможно придется добавить коммит F, который будет разрешать семантические конфликты.
Большое спасибо за ссылку, к сожалею не могу сейчас почитать — отложил в закладки. Не пойму, почему на них нельзя откатиться? Можно. Код не будет работать? Да возможно. Семантический конфликт? Это за пределами системы контроля версий.
Теряется смысл контроля версий из-за семантического конфликта? А часто вы деплоите приложение из тематической ветки? :) Вы рассматриваете именно конфликтные ситуации — в случае если изменения в разных модулях например — то всего этого нет, так?
А семантический конфликт разве не возможен при обычном merge? Не было такого что после подливания мастера ваш код ломался? Ну там функцию в api выпили например в мастере. Rebase — физический уровень манипуляции коммитами, он не защищает и не провоцирует семантические конфликты.
То что теряется старая ветка легко поправимо — если после ребейза сломалась ветка, а вам надо срочно сделать демонстрацию заказчику — можно сделать git reset --hard на коммит E (на него указывает ORIG_HEAD и его можно увидеть в git log --all. Ребейз можно отложить. Я не говорю о том, что мол rebase — золотая пуля. Это просто инструмент который может быть полезен.
Если делать ребейз периодически то фикс семантики можно делать не только в конце — а деплоиться на промежуточные версии (на мой взгляд) бессмысленно. Смысл системы контроля версий на мой взгляд не теряется. И кстати а «посмотреть» разве не входит в задачи scm? Code review, например, провести вполне можно.
Все ваши утверждения верны, тут вопрос в отношении к этим фактам и стилю работы с кодом, а также задачами, которые в каждом конкретном случае вы ставите перед scm.
Теряется смысл контроля версий из-за семантического конфликта? А часто вы деплоите приложение из тематической ветки? :) Вы рассматриваете именно конфликтные ситуации — в случае если изменения в разных модулях например — то всего этого нет, так?
А семантический конфликт разве не возможен при обычном merge? Не было такого что после подливания мастера ваш код ломался? Ну там функцию в api выпили например в мастере. Rebase — физический уровень манипуляции коммитами, он не защищает и не провоцирует семантические конфликты.
То что теряется старая ветка легко поправимо — если после ребейза сломалась ветка, а вам надо срочно сделать демонстрацию заказчику — можно сделать git reset --hard на коммит E (на него указывает ORIG_HEAD и его можно увидеть в git log --all. Ребейз можно отложить. Я не говорю о том, что мол rebase — золотая пуля. Это просто инструмент который может быть полезен.
Если делать ребейз периодически то фикс семантики можно делать не только в конце — а деплоиться на промежуточные версии (на мой взгляд) бессмысленно. Смысл системы контроля версий на мой взгляд не теряется. И кстати а «посмотреть» разве не входит в задачи scm? Code review, например, провести вполне можно.
Все ваши утверждения верны, тут вопрос в отношении к этим фактам и стилю работы с кодом, а также задачами, которые в каждом конкретном случае вы ставите перед scm.
То что семантический конфликт за пределами контроля версий это понятно, то что их может не быть — это понятно. Но при ребейзе будут плодиться коммиты «fix after rebase», а мердж позволяет решить их перед коммитом (--no-commit).
Мы активно практиковали подход с ребейзом, когда использовали меркуриал, т.к. там картина с мерджами выглядит еще ужасней. Но в нем нет ORIG_HEAD. Как-то я целый день (8 часов) сидел и пытался запушить свои изменения и меня постоянно кто-нибудь опережал (над проектом работало около 15 человек). После каждой попытки появлялся коммит из разряда «fix after rebase».
Я не говорю деплоить промежуточные коммиты. К примеру такая ситуация: сделал ребейз, решил конфликты (физические и семантические). Пошел на код ревью, тебе там несколько коммитов ближе к HEAD запороли и сказали, что их нужно переделать по другому. Иду, откатываюсь на последний успешно проревьювенный коммит… опять правлю семантические конфликты (для этого коммита они могут быть другими).
Мы активно практиковали подход с ребейзом, когда использовали меркуриал, т.к. там картина с мерджами выглядит еще ужасней. Но в нем нет ORIG_HEAD. Как-то я целый день (8 часов) сидел и пытался запушить свои изменения и меня постоянно кто-нибудь опережал (над проектом работало около 15 человек). После каждой попытки появлялся коммит из разряда «fix after rebase».
Я не говорю деплоить промежуточные коммиты. К примеру такая ситуация: сделал ребейз, решил конфликты (физические и семантические). Пошел на код ревью, тебе там несколько коммитов ближе к HEAD запороли и сказали, что их нужно переделать по другому. Иду, откатываюсь на последний успешно проревьювенный коммит… опять правлю семантические конфликты (для этого коммита они могут быть другими).
Простите, но зачем зачем плодить коммиты «fix after rebase»? Коммит — это не что-то высеченное в камне.
Заребейзил, прогнал тесты, исправил семантические несоответствия, каждое исправление закоммитил в отдельный коммит.
После чего rebase -i, и fixup-им эти исправления в те места истории ветки, где они должны были быть. При этом все коммиты из истории окажутся в согласованном состоянии.
Заребейзил, прогнал тесты, исправил семантические несоответствия, каждое исправление закоммитил в отдельный коммит.
После чего rebase -i, и fixup-им эти исправления в те места истории ветки, где они должны были быть. При этом все коммиты из истории окажутся в согласованном состоянии.
Почитал про fixup, спасибо за наводку!
>Заребейзил, прогнал тесты, исправил семантические несоответствия, каждое исправление закоммитил в отдельный коммит.
Вы предлагаете после каждого ребейзнутого коммита прогонять тесты? Допустим у меня в ветке N коммитов, как узнать к какому из них нужно прилепить каждое изменение? Если фикс затрагивает несколько коммитов? Т.е. сделать в N раз больше работы и стресса? Т.к. каждый конфликт — это большой стресс.
Ладно, fixup — это хорошо. Но как объяснить это джуниору?
>Коммит — это не что-то высеченное в камне.
В git — да, в Hg — нет:(
Вы предлагаете после каждого ребейзнутого коммита прогонять тесты? Допустим у меня в ветке N коммитов, как узнать к какому из них нужно прилепить каждое изменение? Если фикс затрагивает несколько коммитов? Т.е. сделать в N раз больше работы и стресса? Т.к. каждый конфликт — это большой стресс.
Ладно, fixup — это хорошо. Но как объяснить это джуниору?
>Коммит — это не что-то высеченное в камне.
В git — да, в Hg — нет:(
НЛО прилетело и опубликовало эту надпись здесь
Все нормальные плагины к Mercurial, нацеленные на изменение истории коммитов работают только с той историей, которая никуда из локальной машины не ушла… После pull'a с твоей машины кем-нибудь или push на другую менять историю нельзя…
НЛО прилетело и опубликовало эту надпись здесь
Кроме того, форс пуш не перезатирает ветку, а создает дополнительную голову, что для тех, кто хочет забрать изменения (особенно если включен аналог git pull --rebase) выливается в сплошной факап.
Нашли 3 способа решения проблемы с изменением уже запушеной истории:
— во всех репозиториях, включая оббщий делается стрип (применимо только, если вы хостите мастер-репу самостоятельно)
— делать мердж двух голов default с отбросом изменений из одной головы
— перейти на git
Нашли 3 способа решения проблемы с изменением уже запушеной истории:
— во всех репозиториях, включая оббщий делается стрип (применимо только, если вы хостите мастер-репу самостоятельно)
— делать мердж двух голов default с отбросом изменений из одной головы
— перейти на git
НЛО прилетело и опубликовало эту надпись здесь
Я тут про Hg рассуждал. В нем форс пуш работает иначе чем в git. Создается дополнительная голова и у вас становиться 2 ветки default, если у кого-то стоит On Update: Rebase или On Update: Merge то он получит факап при апдейте.
Править апстрим нужно к примеру, после таких факапов, если их случайно запушили, если в апстрим попали битые коммиты, которые крашат клиент (я не знаю как такое случается, но бывало). Да мало ли что случилось?
Править апстрим нужно к примеру, после таких факапов, если их случайно запушили, если в апстрим попали битые коммиты, которые крашат клиент (я не знаю как такое случается, но бывало). Да мало ли что случилось?
НЛО прилетело и опубликовало эту надпись здесь
Способ 4 — не править историю…
> Вы предлагаете после каждого ребейзнутого коммита прогонять тесты?
Нет, тесты прогоняем один раз после rebase. Ну да, есть конечно небольшой шанс, что fixup я сделаю не туда, и какой-то из промежуточных коммитов окажется несогласованным. Но ведь есть Code Review (и log --stat/log -p), где будет видно, если какой-то из коммитов содержит не относящийся к нему фикс.
> Допустим у меня в ветке N коммитов, как узнать к какому из них нужно прилепить каждое изменение? Если фикс затрагивает несколько коммитов?
Может у меня пока не было сложных случаев, но всегда было понятно, к какому из коммитов локальной ветки нужно применить фикс. Ведь даже в локальной ветке коммиты имеют понятный commit message, видя который можно понять, относится фикс к данному коммиту или нет. Если фикс затрагивает несколько коммитов, то либо эти несколько коммитов должны были ранее быть объединены в один, либо фикс нужно было не одним коммитом делать, а тоже несколькими. На худой конец (если в ветке много несвязанных коммитов, все используют функцию foo и в апстриме она была переименована в bar) filter-branch спасёт, хотя мне почти не приходилось к нему прибегать.
> Ладно, fixup — это хорошо. Но как объяснить это джуниору?
Я сам джуниор. Понадобился в работе git — пошёл, прочитал несколько идеологических статей чтобы понимать «что такое хорошо, и что такое плохо». Когда нужно какую-то конкретную задачу решить — используем поиск и читаем доки по конкретной команде. В чем проблема-то?
Нет, тесты прогоняем один раз после rebase. Ну да, есть конечно небольшой шанс, что fixup я сделаю не туда, и какой-то из промежуточных коммитов окажется несогласованным. Но ведь есть Code Review (и log --stat/log -p), где будет видно, если какой-то из коммитов содержит не относящийся к нему фикс.
> Допустим у меня в ветке N коммитов, как узнать к какому из них нужно прилепить каждое изменение? Если фикс затрагивает несколько коммитов?
Может у меня пока не было сложных случаев, но всегда было понятно, к какому из коммитов локальной ветки нужно применить фикс. Ведь даже в локальной ветке коммиты имеют понятный commit message, видя который можно понять, относится фикс к данному коммиту или нет. Если фикс затрагивает несколько коммитов, то либо эти несколько коммитов должны были ранее быть объединены в один, либо фикс нужно было не одним коммитом делать, а тоже несколькими. На худой конец (если в ветке много несвязанных коммитов, все используют функцию foo и в апстриме она была переименована в bar) filter-branch спасёт, хотя мне почти не приходилось к нему прибегать.
> Ладно, fixup — это хорошо. Но как объяснить это джуниору?
Я сам джуниор. Понадобился в работе git — пошёл, прочитал несколько идеологических статей чтобы понимать «что такое хорошо, и что такое плохо». Когда нужно какую-то конкретную задачу решить — используем поиск и читаем доки по конкретной команде. В чем проблема-то?
>Я сам джуниор. Понадобился в работе git — пошёл, прочитал
Был у нас паренек, он уволился через месяц, сказал что такой информационной нагрузки не выдерживает)
А вообще тут все дело в мотивации — если человек сам не захочет научиться git-у (или чему другому) — он не научится, хоть ты палкой его бей.
Был у нас паренек, он уволился через месяц, сказал что такой информационной нагрузки не выдерживает)
А вообще тут все дело в мотивации — если человек сам не захочет научиться git-у (или чему другому) — он не научится, хоть ты палкой его бей.
НЛО прилетело и опубликовало эту надпись здесь
. Но в нем нет ORIG_HEAD. Как-то я целый день (8 часов) сидел и пытался запушить свои изменения и меня постоянно кто-нибудь опережал (над проектом работало около 15 человек).
15 человек работающие в одной ветке? Как тут гит поможет?
Мне действительно инетересно.
Я понимаю, что вы имели в виду.
Но у новичков от вашего утверждения может создаться ложное впечатление что rebase позволяет избежать конфликтов.
Но у новичков от вашего утверждения может создаться ложное впечатление что rebase позволяет избежать конфликтов.
Чтобы «отребейзить» фиче-бранч от мастера нужно все те же конфликты решить, разве нет? А у меня бывали ситуации, когда при простом мердже в мастер конфликтов нет, а при ребейзе… есть.
Решать надо.
Не знаю как у Вас построен процесс, а у нас в мастер вливает только тимлид. Владелец ветки перед передачей на слияние ребейзит ветку от мастера и решает конфликты, если они есть. Тимлиду же остается только влить изменения (после ревью). Конфликт решить проще разработчику, нежели тимлиду.
Не знаю как у Вас построен процесс, а у нас в мастер вливает только тимлид. Владелец ветки перед передачей на слияние ребейзит ветку от мастера и решает конфликты, если они есть. Тимлиду же остается только влить изменения (после ревью). Конфликт решить проще разработчику, нежели тимлиду.
К тому-же после ребейса еще полезно будет прогнать тесты на актуальной кодовой базе, и уже потом кидать пулл реквест.
У вас тимлиду больше заняться нечем?
Как быть с ситуацией, когда исполнитель сделал ребейз, отправил код на ревью, его проревьювили и не форварднули по каким-либо причинам (бизнес сказал, что фичу нужно отложить, тимлид отвлекся и забыл, и т.п.). Тем временем мастер поплнился другими коммитами. Исполнителю опять нужно идти и ребазировать-решать конфликты, переключаться с текущих задач? Потом тимлиду опять нужно делать ревью, и круг повторяется.
Как быть с ситуацией, когда исполнитель сделал ребейз, отправил код на ревью, его проревьювили и не форварднули по каким-либо причинам (бизнес сказал, что фичу нужно отложить, тимлид отвлекся и забыл, и т.п.). Тем временем мастер поплнился другими коммитами. Исполнителю опять нужно идти и ребазировать-решать конфликты, переключаться с текущих задач? Потом тимлиду опять нужно делать ревью, и круг повторяется.
>> Исполнителю опять нужно идти и ребазировать-решать конфликты
А при мердже этого делать разве не надо в такой ситуации? :) Тут проблема не merge или rebase — проблема в самой ситуации. Код устаревает постоянно пока не влит в мастер. После вливания в мастер код заставляет устаревать другой код, еще не влитый в мастер. Это жизнь.
А при мердже этого делать разве не надо в такой ситуации? :) Тут проблема не merge или rebase — проблема в самой ситуации. Код устаревает постоянно пока не влит в мастер. После вливания в мастер код заставляет устаревать другой код, еще не влитый в мастер. Это жизнь.
Описываемая Вами ситуация для нашей команды экстраординарная (если для Вас это норма — искренне Вам сочувствую). Поэтому накладные расходы на повторный ребейз и ревью не нами учитываются (к тому же они весьма вероятно будут значительно меньше).
Они будут не меньше, а все те же 1..N на каждый конфликтный файл.
Я привел 2 вполне жизненных примера, сочувствие тут не уместно. Мы все живем в реальном мире.
Я привел 2 вполне жизненных примера, сочувствие тут не уместно. Мы все живем в реальном мире.
Они будут не меньше, а все те же 1..N на каждый конфликтный файл.
Это будут уже другие конфликты. И высока вероятность, что их вообще не будет.
Я не утверждаю, что затраты всегда меньше, я говорю, что они с большой вероятностью будут меньше.
Похоже, что у нас слишком разный паттерн использования гита и продолжать спор смысла нет
У меня нет «паттерна» использования гита, я его использую так, как оправданно в конкретной ситуации.
Я просто хочу донести до вас, что почти с каждым ребейзом у вас будут появляться коммиты «fix after rebase».
Я просто хочу донести до вас, что почти с каждым ребейзом у вас будут появляться коммиты «fix after rebase».
за полтора года работы по такой схеме не было ни одного такого комита. Видимо нам везет. Или что-то делаем не так ;)
Одно из двух: либо вы один на проекте, либо каждый работает над своей изолированной частью. Что в принципе одно и то же. Либо вы опять лукавите.
У вас после ребейза никогда не было семантических конфликтов? Не верю.
Самое простое что пришло на ум:
Вы пишите код, вызываете какую-то функцию.
В это время злой Вася Пупкин обнаруживает, что эту функцию никто не использует кроме него и решает ее переименовать или отрефакторить. Затем ребазирует, успешно проходит code review, его изменения попадают в мастер.
Вы заканчиваете свою фичу, рабазируете и… «fix after rebase»
У вас после ребейза никогда не было семантических конфликтов? Не верю.
Самое простое что пришло на ум:
Вы пишите код, вызываете какую-то функцию.
В это время злой Вася Пупкин обнаруживает, что эту функцию никто не использует кроме него и решает ее переименовать или отрефакторить. Затем ребазирует, успешно проходит code review, его изменения попадают в мастер.
Вы заканчиваете свою фичу, рабазируете и… «fix after rebase»
Команда у нас действительно не большая, но над одной задачей бывает работают несколько разработчиков.
О таких калечащих изменениях обычно сообщается всем и заранее. Все приблизительно в курсе, кто чем занимается, поэтому если есть необходимость что-то поменять, то об этом сообщают людям, которых это может затронуть.
Не понятно, чем в данном случае ребейз от мержа будет отличаться? Только тем, что семантический конфликт будет зарыт внутри мерж-комита, а не идти отдельным?
О таких калечащих изменениях обычно сообщается всем и заранее. Все приблизительно в курсе, кто чем занимается, поэтому если есть необходимость что-то поменять, то об этом сообщают людям, которых это может затронуть.
Не понятно, чем в данном случае ребейз от мержа будет отличаться? Только тем, что семантический конфликт будет зарыт внутри мерж-комита, а не идти отдельным?
Забыл. Утверждение, что владельцу ветки проще решить конфликты чем тимлиду верно только от части. Исполнитель отвечает за свои изменения, тимлид за чужие. Но голова у тимлида не резиновая и он позовёт Васю Пупкина, который сделал те изменения, с которыми конфликтуют изменения исполнителя.
Вот именно, ситуация когда разработчик не знает как правильно решить конфликт бывает гораздо реже (голова у тимлида не резиновая, тут Вы верно заметили).
Для решения конфликта тимлид наверняка привлечет разработчика ветки. Так почему бы разработчику самому не решать конфликты, без привлечения тимлида?
Для решения конфликта тимлид наверняка привлечет разработчика ветки. Так почему бы разработчику самому не решать конфликты, без привлечения тимлида?
Кстати, мне, как человеку, который часто ревьювит код проще смотреть в одном коммите, чем высматривать построчные изменения в 50 коммитах. Так видно всю картину целиком.
> Владелец ветки перед передачей на слияние ребейзит ветку от мастера и решает конфликты, если они есть.
А теперь нужно откатить одну из 15 веток, которая таким образом была замержена, потому что она вызывает проблемы :). Как вы будете это делать с таким подходом? Ведь у вас линейная история.
Прошу прощения, погорячился, «отмержить» ветку тоже достаточно легко в случае линейной истории — нужно просто удалить диапазон коммитов из ветки. Согласен.
Прошу прощения, погорячился, «отмержить» ветку тоже достаточно легко в случае линейной истории — нужно просто удалить диапазон коммитов из ветки. Согласен.
Да и когда ветка долго живет в ней копятся мердж коммиты (чтобы держать кодовую базу в ветке актуальной) — при ребейзе про состояние до ребейза можно забыть, как будто вы только что обранчевались и накоммитили в новую ветку.
А откуда в фиче-бранче копятся мерджи из master?
А вы не подливаете себе мастер, если ветка долго живет? Потом все разом мерджите? Это сложно бывает, я бы рекомендовал раз в несколько дней подмердживать мастер, чтобы потом с ума не сойти.
Стараюсь этого всячески избегать.
Почему? Вам не нужен актуальный код в вашей ветке? А если окружение поменялось и ваша ветка в нем попросту не работает?
Эм, это как так? Как моя ветка может сломаться, если ее никто не трогал?
Если у вас общее окружение (т.е. вы не одни на разработческом сервере :))), то любой рефакторинг, который затрагивает смену этого окружения, сломает вашу ветку. Например, API какого-нибудь внутреннего сервиса сменился. В master есть нужные изменения, а в вашей ветке — нет.
Т.е. у вас есть фиче-бранчи и общее окружение. Печаль.
Хорошо, в ветке Васи Пупкина есть изменения которые сломали ваше окружение, но его ветка еще не готова быть ни в вашей ветке, ни в мастере. Работа встала. Печаль.
То что вы говорите для меня вообще невероятная ситуация.
Мой рабочий компьютер и есть «разработческий сервер».
Хорошо, в ветке Васи Пупкина есть изменения которые сломали ваше окружение, но его ветка еще не готова быть ни в вашей ветке, ни в мастере. Работа встала. Печаль.
То что вы говорите для меня вообще невероятная ситуация.
Мой рабочий компьютер и есть «разработческий сервер».
И пока вы работаете в ветке вы не переключаетесь на другую ветку? Или все-таки у вас БД столько же сколько веток (или она редко меняется, или изменения непротиворечащие). А зачем вам ветки в таком случае вообще? :)
Ну, мы работаем в других условиях. У нас слишком накладно поднимать на каждом компьютере разработчика и держать в актуальном состоянии по копии всех нужных баз и, что более важно, сишных сервисов, в том числе мемкешей.
Да не обязательно апи, схема бд может поменяться например, или у вас для каждой ветки своя БД развернута?
Для меня главный смысл делать rebase — резолвить ситуации, когда в feature-branch нужно забрать обновленный код из мастера (например, изменилось апи, которое использует фича). Можно конечно сделать merge master в feature, но это создает такую кашу в репозитории, что иногда очень легко запутаться в происходящем. С ребейзом все куда проще.
Вот это подход — правильный. Ребазировать всегда, чтоб сделать линейную историю — нет.
Так, вроде, никто про линейную историю не говорил
Простите, что откапываю стюардессу, но тема показалась интересной.
Но ведь если с помощью rebase «резолвятся ситуации, когда в feature-branch нужно забрать обновленный код из мастера» с легкостью можно оказаться в ситуации когда все коммиты в feature-branch будут содержать семантический конфликт. Например если в мастере изменили название какого-то метода, который используется в бранче. Т.е. имхо использовать rebase в этой ситуации тоже не очень безопасно.
Но ведь если с помощью rebase «резолвятся ситуации, когда в feature-branch нужно забрать обновленный код из мастера» с легкостью можно оказаться в ситуации когда все коммиты в feature-branch будут содержать семантический конфликт. Например если в мастере изменили название какого-то метода, который используется в бранче. Т.е. имхо использовать rebase в этой ситуации тоже не очень безопасно.
Я думаю, вам будет интересно почитать эту ветку обсуждений habrahabr.ru/post/161009/?reply_to=6933652#comment_5547341 :)
Споры по поводу того, что лучше — merge или rebase, как мне кажется, не имеют смысла, потому что rebase является надстройкой над merge и, исходя из этого, не может приводить к меньшему количеству конфликтов, чем сам merge :).
С другой стороны, rebase позволяет переписать историю коммитов, сделав её более ровной.
С другой стороны, rebase позволяет переписать историю коммитов, сделав её более ровной.
потому что rebase является надстройкой над mergeЧто вы имеете ввиду?!
исходя из этого, не может приводить к меньшему количеству конфликтовЯ написал в другой ветке, что rebase ведет к большему количеству разрешений конфликтов. Хотя сами конфликты становятся меньше.
С другой стороны, rebase позволяет переписать историю коммитов, сделав её более ровной.Дак я и спрашиваю — какой в этом смысл кроме псевдо-эстетического?
rebase не является надстройкой над merge, он является надстройкой (а точнее автоматизацией) cherry-pick-ов
К сожалению иногда пикнуть несколько коммитов вручную намного легче, чем через такую «автоматизацию»
Ну а cherry-pick, в свою очередь, таки является надстройкой над merge :), хоть это и не так легко найти в коде гита.
Заодно прикольно было узнать, что один и тот же код делает как git revert, так и git cherry-pick (хотя, если подумать, это довольно логично, т.к. revert является просто cherry-pick от коммита, в котором "+" заменен на "-" :))
Заодно прикольно было узнать, что один и тот же код делает как git revert, так и git cherry-pick (хотя, если подумать, это довольно логично, т.к. revert является просто cherry-pick от коммита, в котором "+" заменен на "-" :))
/* sequencer.c */
...
static int do_pick_commit(struct commit *commit, struct replay_opts *opts)
{
...
if (!opts->strategy || !strcmp(opts->strategy, "recursive") || opts->action == REPLAY_REVERT) {
res = do_recursive_merge(base, next, base_label, next_label,
head, &msgbuf, opts);
write_message(&msgbuf, defmsg);
} else {
...
res = try_merge_command(opts->strategy, opts->xopts_nr, opts->xopts,
common, sha1_to_hex(head), remotes);
...
}
....
}
Сорри, не убедили. Вырванный из контекста кусок кода мне, к сожалению, ничего не доказывает. do_recursive_merge — просто наложение изменений на дерево проекта (наложение диффа), про try_merge_command — не могу сказать про что, некогда ковырять. Я говорил о merge как о команде гита, которая создает коммит с двумя родителями. По вашей логике patch — тоже merge. Если вы это и имели ввиду — то ок, спор чисто терминологический и мы друг друга просто недопоняли.
Если вы считаете что rebase или cherry-pick можно разложить на несколько мерджей (в моей терминологии), попробуйте это в двух словах сделать.
Если вы считаете что rebase или cherry-pick можно разложить на несколько мерджей (в моей терминологии), попробуйте это в двух словах сделать.
try_merge_command вызывает git merge с выбранной стратегией (см. спойлер).
Но да, вы правы, для того, чтобы rebase использовал свой же merge, нужно явно выбрать "--merge", когда делается rebase.
А принцип использования мержа очень простой (для git rebase onto A из ветки B):
1. находим merge-base между A и B = C (точка расхождения истории коммитов)
2. i = 1
3. мержим коммит номер i (считая из точки C в направлении B) в ветку A (находясь в ветке A, делаем git merge <sha1>)
4. повторяем до тех пор, пока не закончатся коммиты из B
Да, rebase --interactive и squash коммитов так сделать нельзя, но перенос коммитов — можно :).
Скрытый текст
int try_merge_command(const char *strategy, size_t xopts_nr,
const char **xopts, struct commit_list *common,
const char *head_arg, struct commit_list *remotes)
{
const char **args;
int i = 0, x = 0, ret;
struct commit_list *j;
struct strbuf buf = STRBUF_INIT;
args = xmalloc((4 + xopts_nr + commit_list_count(common) +
commit_list_count(remotes)) * sizeof(char *));
strbuf_addf(&buf, "merge-%s", strategy);
args[i++] = buf.buf;
for (x = 0; x < xopts_nr; x++) {
char *s = xmalloc(strlen(xopts[x])+2+1);
strcpy(s, "--");
strcpy(s+2, xopts[x]);
args[i++] = s;
}
for (j = common; j; j = j->next)
args[i++] = xstrdup(merge_argument(j->item));
args[i++] = "--";
args[i++] = head_arg;
for (j = remotes; j; j = j->next)
args[i++] = xstrdup(merge_argument(j->item));
args[i] = NULL;
ret = run_command_v_opt(args, RUN_GIT_CMD);
strbuf_release(&buf);
i = 1;
for (x = 0; x < xopts_nr; x++)
free((void *)args[i++]);
for (j = common; j; j = j->next)
free((void *)args[i++]);
i += 2;
for (j = remotes; j; j = j->next)
free((void *)args[i++]);
free(args);
discard_cache();
if (read_cache() < 0)
die(_("failed to read the cache"));
resolve_undo_clear();
return ret;
}
Но да, вы правы, для того, чтобы rebase использовал свой же merge, нужно явно выбрать "--merge", когда делается rebase.
А принцип использования мержа очень простой (для git rebase onto A из ветки B):
1. находим merge-base между A и B = C (точка расхождения истории коммитов)
2. i = 1
3. мержим коммит номер i (считая из точки C в направлении B) в ветку A (находясь в ветке A, делаем git merge <sha1>)
4. повторяем до тех пор, пока не закончатся коммиты из B
Да, rebase --interactive и squash коммитов так сделать нельзя, но перенос коммитов — можно :).
Опять вы говорите о merge как об операции наложения изменений. Git merge тоже основан на merge. Git stash apply тоже основан на merge. Только споры обычно идут операции git merge, а точнее о том, стоит ли перед ней делать git rebase или нет. А еще о том, как подливать кодовую базу в тематическую ветку — через перебазирование самой ветки или через слияние изменений. Спасибо за интересную беседу anyway. У меня до ковыряния в сорцах гита еще не доходило.
Моя мысль лишь в том, что бОльшую часть операций гита можно свести к мержу, поэтому устраивать холиворы из-за надстроек над мержем как-то странно :). Я ещё понимаю холиворы между разными DVCS, в которых по-разному хранятся данные и устроен merge, но чтобы между merge и rebase — это уже действительно Linux-way :).
> У меня до ковыряния в сорцах гита еще не доходило.
К сожалению, некоторые вещи, которые касаются внутреннего устройства гита, нигде толком не описаны, поэтому приходится лезть в исходный код, чтобы понять, что же там на самом деле происходит.
К сожалению, некоторые вещи, которые касаются внутреннего устройства гита, нигде толком не описаны, поэтому приходится лезть в исходный код, чтобы понять, что же там на самом деле происходит.
Цель ребейза не уменьшить количество конфликтов, а уменьшить количество мержей в истории. Так что сравнивать по количеству/качеству конфликтов — не имеет смысла — конфликты они в вашем коде, а не в операции, которой вы его сливаете — просто при мердже вы разруливаете конфликт для конечных версий в ветках, а при rebase конфликт каждого изменения (коммит-а).
Меня одного путает направление стрелок?
Ооо, вы украли мой коммент :) Я тоже не понял, почему стрелки в обратную сторону!
Так устроена система хранения в GIT. Коммит указывает на родителя/родителей.
Хотите познать GIT? GIT.pro Вам в помощь!
Хотите познать GIT? GIT.pro Вам в помощь!
Прочитайте пожалуйста мой коммент. Очень надеюсь, что он поможет понять почему стрелки нарисованы именно так, а не иначе.
Направление от потомка к родителю соответствует физике процесса. Дело в том что в коммите B например хранится указатель на коммит A (хэш родительского коммита). Отпугивает видимо не только вас, так как на github стрелки рисуют в другую сторону. Однако в литературе например рисуют также. Нужно стрелку воспринимать как указатель, а не как направление действия.
Использую и merge и rebase.
Удобство merge в «маленьких» commit-ах, каждый из которых не обязан иметь законченное решение. Получает, что ветка это удобная история изменений, каждый merge-commit это законченное решение. Ни кто, ни кому не мешает при разработке в группе.
Удобство rebase в «прямолинейности» ветки, но каждый commit это законченное решение, или нужно будет создавать теги. Не очень удобен, поскольку постоянно придется следить кто какие commit-ы уже сделал,
Удобство merge в «маленьких» commit-ах, каждый из которых не обязан иметь законченное решение. Получает, что ветка это удобная история изменений, каждый merge-commit это законченное решение. Ни кто, ни кому не мешает при разработке в группе.
Удобство rebase в «прямолинейности» ветки, но каждый commit это законченное решение, или нужно будет создавать теги. Не очень удобен, поскольку постоянно придется следить кто какие commit-ы уже сделал,
Как быть в таком случае:
Есть ветки master, feature-1 (основа — master), feature-2 (основа — master). В каждую из веток регулярно коммитят.
Возникает задача параллельно делать feature-3, которая будет включать себя изменения из feature-1 и feature-2 (и соответственно изменения из master).
При этом по ходу разработки в feature-3 нужно регулярно подтягивать изменения feature-1 и feature-2 (которые меняются и регулярно ребейзятся на master).
Если в feature-3 для получения изменения из 1 и 2 я буду использовать rebase, то коммиты постоянно будут дублироваться (что логично, ведь git не будет знать о том, что коммиты в feature-1 и feature-2 «те же самые»).
Если использовать merge, то история загрязнится мердж-коммитами и почти невозможно будет получить «чистую» история по feature-3.
Как вариант, для получения изменений делать squash всех коммитов в feature-3 и уже потом rebase на ветки, но теряется история, что не удобно.
Может быть я упускаю какое-то простое очевидное решение?
Есть ветки master, feature-1 (основа — master), feature-2 (основа — master). В каждую из веток регулярно коммитят.
Возникает задача параллельно делать feature-3, которая будет включать себя изменения из feature-1 и feature-2 (и соответственно изменения из master).
При этом по ходу разработки в feature-3 нужно регулярно подтягивать изменения feature-1 и feature-2 (которые меняются и регулярно ребейзятся на master).
Если в feature-3 для получения изменения из 1 и 2 я буду использовать rebase, то коммиты постоянно будут дублироваться (что логично, ведь git не будет знать о том, что коммиты в feature-1 и feature-2 «те же самые»).
Если использовать merge, то история загрязнится мердж-коммитами и почти невозможно будет получить «чистую» история по feature-3.
Как вариант, для получения изменений делать squash всех коммитов в feature-3 и уже потом rebase на ветки, но теряется история, что не удобно.
Может быть я упускаю какое-то простое очевидное решение?
Реально сложная задача, может она неправильно поставлена? Почему все три фичи не могут делаться в одной ветке если они так тесно взаимосвязаны?
Тестироваться и выпускаться (мерджиться в мастер) будут отдельно.
Можно ли разбить фичи 1 и 2 на этапы? Например после завершения определенной работы в ветке 1 и 2 они готовы к вливанию в 3? В каком порядке фичи будут мерджиться в мастер заранее известно или по готовности? Может вам стоит пилить общий для всех этих 3 веток функционал в базовой ветке, относительно которой ребейзить все эти три фиче-ветки? И там уже тестировать перед вливанием в мастер?
Мне что-то то кажется что между вашими тремя ветками и мастером должна быть промежуточная ветка в которую вы вливаете изменения из этих трех.
Мне что-то то кажется что между вашими тремя ветками и мастером должна быть промежуточная ветка в которую вы вливаете изменения из этих трех.
Если в очень упрощённом варианте: сделали 1 и 2, отдали в тестирование, начинаем делать 3, зависящую от 1 и 2. В 1 и 2 тестировщик нашёл баги, правим, 3 нужно обновить. И так несколько раз.
Как будут мержится известно, но 1 и 2 раньше. Предполагается, что к моменту передачи в тестирование 3 фичи 1 и 2 уже будут выпущены (или по крайней мере протестированы).
Всё в одной не удобно — сложнее тестировать, сложнее планировать и следить за процессом разработки.
Как будут мержится известно, но 1 и 2 раньше. Предполагается, что к моменту передачи в тестирование 3 фичи 1 и 2 уже будут выпущены (или по крайней мере протестированы).
Всё в одной не удобно — сложнее тестировать, сложнее планировать и следить за процессом разработки.
Стойте, а код из ветки 1 в ветку 2 не может попадать? То есть изменения объединяются только в ветке 3?
Из 1 в 2 не может попадать. Объединяются только в 3, да.
У вас тут есть одно внутреннее противоречие из-за которого все проблемы:
— ветки 1 и 2 должны вестись изолировано
— ветка 3 должна содержать объединенные изменения из ветки 1 и 2.
Отсюда следует, что эти изменения не могут храниться в одних и тех же коммитах. Два выхода:
1. Либо изменения приезжают в ветку 3 с помощью мерджа и храняться в мердж-коммитах — запутываем граф.
2. Либо изменения из веток 1 и 2 дублируются в других коммитах — в ветке три — их можно переносить туда cherry-pick-ом, но тогда готовьтесь к конфликтам и дублированию пикнутых коммитов при интеграции ветки 3 в мастер, в который уже проинтегрированы ветки 1 и 2. Ну и черрипик не слишком быстрая операция так как предполагает много ручной работы.
3. Либо вам надо отказаться от полной изолированности ветки 1 и 2, то есть когда ветки 1 и 2 готовы к интеграции в ветку 3 они склеиваются ребейзом до текущего состояния (можно пометить его веткой release) и далее снова разрабатываются изолировано. Ветка 3 ребейзится на состояние release.
Третий вариант я не посчитал, так как он нарушает одно из входящих условий
— ветки 1 и 2 должны вестись изолировано
— ветка 3 должна содержать объединенные изменения из ветки 1 и 2.
Отсюда следует, что эти изменения не могут храниться в одних и тех же коммитах. Два выхода:
1. Либо изменения приезжают в ветку 3 с помощью мерджа и храняться в мердж-коммитах — запутываем граф.
2. Либо изменения из веток 1 и 2 дублируются в других коммитах — в ветке три — их можно переносить туда cherry-pick-ом, но тогда готовьтесь к конфликтам и дублированию пикнутых коммитов при интеграции ветки 3 в мастер, в который уже проинтегрированы ветки 1 и 2. Ну и черрипик не слишком быстрая операция так как предполагает много ручной работы.
3. Либо вам надо отказаться от полной изолированности ветки 1 и 2, то есть когда ветки 1 и 2 готовы к интеграции в ветку 3 они склеиваются ребейзом до текущего состояния (можно пометить его веткой release) и далее снова разрабатываются изолировано. Ветка 3 ребейзится на состояние release.
Третий вариант я не посчитал, так как он нарушает одно из входящих условий
А вот еще классный вариант придумал — не делать фичу 3 пока не сделаны первые две. Сложно писать код на такой зыбкой почве как две динамично меняющиеся кодовые базы совместимость которых тестится только у меня в бранче. Ну и да декомпозиция задач 1 и 2 на более мелкие может облегчить этот процесс за счет того, что каждый этап занимает меньше времени и по сути делается в отдельной ветке (может с тем же названием, может «новая» ветка — продолжение отребейзенной старой)
Теперь объясните это дяденьке, который деньги из большой пачки отслюнявливает.
А ситуация, которую описывает Splurov, к сожалению, жизненная, и мне встречалась.
А ситуация, которую описывает Splurov, к сожалению, жизненная, и мне встречалась.
К сожалению, это невозможно.
Мне кажется если «в feature-3 нужно регулярно подтягивать изменения feature-1 и feature-2», то feature-1 и feature-2 не должны «регулярно ребейзятся на master».
В противном случае каким бы мы способом ни вливали изменения из feature-1, feature-2 в feature-3 — проблем не избежать. Rule of thumb: не ребэйзить ветку, если на неё кто-то ссылается (или имеет локальную копию, или если она есть в публичном репозитории). Хоть автор статьи и утверждает «здесь мы рассмотрели, как легко можно избежать этой проблемы с помощью git pull --rebase», но на самом деле проблемы так не решатся, и, как мне кажется могут быть решены вовсе: изменение истории слишком грязный трюк, чтобы делать его где-то кроме локальной ветки, которую никто не видел.
В противном случае каким бы мы способом ни вливали изменения из feature-1, feature-2 в feature-3 — проблем не избежать. Rule of thumb: не ребэйзить ветку, если на неё кто-то ссылается (или имеет локальную копию, или если она есть в публичном репозитории). Хоть автор статьи и утверждает «здесь мы рассмотрели, как легко можно избежать этой проблемы с помощью git pull --rebase», но на самом деле проблемы так не решатся, и, как мне кажется могут быть решены вовсе: изменение истории слишком грязный трюк, чтобы делать его где-то кроме локальной ветки, которую никто не видел.
Если же предположим, что ветки 1 и 2 не ребейзятся, то всё более-менее просто.
Делаем вспомогательную ветку feature-3-base, куда периодически мержим изменения из веток 1 и 2 и master, и своих коммитов в неё не делаем. А ветку feature-3 периодически ребейзим на feature-3-base. Когда ветки 1 и 2 вмержатся в мастер, через git rebase --onto перенесем третью ветку с feature-3-base на мастер. Аналогичные действия можно сделать если в мастер вмержилась только первая или только вторая ветка.
В принципе, используя rebase --onto можно пытаться делать что-то похожее даже если первая и вторая ветки регулярно _ребэйзятся_ на мастер.
Если мерж первой, второй ветки и мастера нетривиален — то возникает проблема с тем, что мы его делаем несколько раз (сперва мержим чтобы использовать в feature3, а потом повторяем те же действия, когда будем отправлять первую и вторую ветку в мастер). rerere как-то поможет, но всё-равно неприятно.
Делаем вспомогательную ветку feature-3-base, куда периодически мержим изменения из веток 1 и 2 и master, и своих коммитов в неё не делаем. А ветку feature-3 периодически ребейзим на feature-3-base. Когда ветки 1 и 2 вмержатся в мастер, через git rebase --onto перенесем третью ветку с feature-3-base на мастер. Аналогичные действия можно сделать если в мастер вмержилась только первая или только вторая ветка.
В принципе, используя rebase --onto можно пытаться делать что-то похожее даже если первая и вторая ветки регулярно _ребэйзятся_ на мастер.
Если мерж первой, второй ветки и мастера нетривиален — то возникает проблема с тем, что мы его делаем несколько раз (сперва мержим чтобы использовать в feature3, а потом повторяем те же действия, когда будем отправлять первую и вторую ветку в мастер). rerere как-то поможет, но всё-равно неприятно.
Правда? Пока проблем не обнаружено. Со вторичными тематическими ветками не пробовал но шаренные ветки ребейзил. git pull --rebase вытягивает новую ветку и перемещает локальные коммиты наверх. Да и git help pull говорит:
Что намекает, что это допустимая ситуация. Возможно в более ранних версиях гита это был грязный трюк, но сейчас это вполне работает.
--rebase
Rebase the current branch on top of the upstream branch after fetching. If there is a remote-tracking branch corresponding to the upstream branch and the upstream branch was rebased
since last fetched, the rebase uses that information to avoid rebasing non-local changes.
Что намекает, что это допустимая ситуация. Возможно в более ранних версиях гита это был грязный трюк, но сейчас это вполне работает.
Не знал. Но это похоже на хак, а решает проблему только в очень частном случае. Хотел написать подробнее, но тут уже всё отлично написали.
Ну и когда мы пушим отребейзенную ветку: «git push origin feature --force» у нас есть race condition, ведь если кто-то запушил в эту ветку свой коммит за секунду до того как мы запушили с форсом, его коммит из репозитория пропадёт. После чего когда он сделает у себя git pull --rebase, этот коммит наверно пропадёт и из его локальной копии (т.к. его копия git не считает этот коммит локальным и не будет его ребэйзить).
+1, про race-condition я даже и не подумал, когда писал коммент! А ведь действительно, причем там не секунды синхронизации, далеко не секунды. Нужно обязательно перед каждым push --force делать тот же pull --rebase. Если забыл и затер изменения коллеги — будет много недовольных в лучшем случае. Т.е. добавляется еще одно административное ограничение кроме как запускать git pull --rebase — запускать его пере push, причем прямо перед самым им, чтобы минимизировать между ними время и, соответственно, вероятность race condition
Race condition фактически есть, но реально, это надуманная проблема — если я с кем-то работаю в одной ветке — значит я много общаюсь с ними, постоянно делюсь кодом, обсуждаю архитектуру. Ничего не мешает договориться о моменте ребейза и зафризить ветку — это конечно хак за пределами SCM, но мне при работе в общей ветке не приходилось сталкиваться с race condition. Насчет того пропадет ли «гоночный» коммит при ребейзе — надо поставить эксперимент — в теории выглядит именно так, но надо бы убедиться — поэкспериментирую на досуге.
Можно попробовать вот такое решение blog.caurea.org/2009/11/19/subtree-octopus-merge.html
Хорошая статья… Вот бы еще убедить коллег придерживаться такого стиля, ведь «и так всё работает» :(
Это не очевидно, но git pull --rebase делает не просто git pull && git rebase. Как вы процитировали доки выше, он смотрит, не ребейзился ли апстрим, и если ребейзился, то он ребейзит только те изменения что добавили мы. Это вообще говоря, похоже не хак и корректно работает только в некоторых конкретных случаях: когда у нас есть один главный бранч и фичебранчи. Действительно тогда фичебранчи можно без проблем ребейзить, если все делают git pull --rebase при работе. Как только система становится сложнее (например, добавляется фичебранч, основанный на другом фичебранче, как тут), git pull --rebase уже не будет корректно работать (как, собственно, вы и написали в конце статьи). Подозреваю, что все станет еще хуже, как только у вас появятся релиз-бранчи, staging, хотфиксы в master. Если только не взять за правило ничего кроме фичебранчей не ребейзить.
Конечно, линейная история гита при использовании долгоживущих фичебранчей это круто. И я ни в коем случае не агитирую против такого подхода, потому что хистори гита это часть исходников и как и все другие исходники она должна быть чистой и понятной. (Я против фичебранчей в целом, но это не относится к теме этой статьи.) Но цена за такую линейную историю — грязные хаки в виде git pull --rebase, которые будут работать только в конкретных случаях. Т.е. как только у нас в репозитории произойдет что-то нестандартное, наш стандартный хак не сработает. Это должно быть как-то административно поставлено, что все используют только git pull --rebase, что тоже не очень хорошо, ИМХО.
Повторюсь, я не против такого подхода, если необходимость использования долгоиграющих (например, отдельно тестируемых) фичебранчей не ставится под сомнение, но нужно понимать границы применения, и цену такого подхода.
Конечно, линейная история гита при использовании долгоживущих фичебранчей это круто. И я ни в коем случае не агитирую против такого подхода, потому что хистори гита это часть исходников и как и все другие исходники она должна быть чистой и понятной. (Я против фичебранчей в целом, но это не относится к теме этой статьи.) Но цена за такую линейную историю — грязные хаки в виде git pull --rebase, которые будут работать только в конкретных случаях. Т.е. как только у нас в репозитории произойдет что-то нестандартное, наш стандартный хак не сработает. Это должно быть как-то административно поставлено, что все используют только git pull --rebase, что тоже не очень хорошо, ИМХО.
Повторюсь, я не против такого подхода, если необходимость использования долгоиграющих (например, отдельно тестируемых) фичебранчей не ставится под сомнение, но нужно понимать границы применения, и цену такого подхода.
Git pull — rebase конечно не делает git pull и git rebase, так как git pull — это fetch & merge, а git pull --rebase — это fetch & rebase. Кроме того нужно понимать, что когда удаленная ветка ребейзена и вы делаете git pull --rebase базовый коммит — это не общий коммит в ветках feature и origin/feature, а первый незапушенный вами (то есть локальный) коммит. Линейка локальных коммитов, которая перемещается при git pull --rebase, легко конвертится в серию патчей, которые можно накатить, что бы с веткой не происходило — rebase, squash, такую серию патчей можно накатить куда угодно, поэтому я не понимаю, почему все так боятся ребейзить удаленные ветки.
В ситуации со вторичными ветками — нужно скорее брать за правило ребейзить и закрывать все вторичные бранчи, относительно первичных до их ребейза — и это будет работать просто прекрасно.
Не надо придумывать никаких универсальных административных политик. Цель статьи — чтобы после прочтения стало понятно, как физически работает rebase в описанных ситуациях. Владея этим знанием нужно применять их по обстоятельствам, а не по своду каких-то магических методик. Если у меня 1 локальное изменение и я взял git pull и сижу правлю огромное количество конфликтов в коде, который я даже не трогал — что-то тут пошло не так, да? Наверно нужно откатиться и взять git pull --rebase.
Нет никаких солюшенов и сводов правил, есть вы и git, некий набор инструментов в рамках гита и ваше умение ими пользоваться.
В ситуации со вторичными ветками — нужно скорее брать за правило ребейзить и закрывать все вторичные бранчи, относительно первичных до их ребейза — и это будет работать просто прекрасно.
Не надо придумывать никаких универсальных административных политик. Цель статьи — чтобы после прочтения стало понятно, как физически работает rebase в описанных ситуациях. Владея этим знанием нужно применять их по обстоятельствам, а не по своду каких-то магических методик. Если у меня 1 локальное изменение и я взял git pull и сижу правлю огромное количество конфликтов в коде, который я даже не трогал — что-то тут пошло не так, да? Наверно нужно откатиться и взять git pull --rebase.
Нет никаких солюшенов и сводов правил, есть вы и git, некий набор инструментов в рамках гита и ваше умение ими пользоваться.
Конечно же, я имел ввиду git fetch && git rebase — опечатался там.
Кажется, до меня дошла ваша мысль ). Если есть понимание инструментов и умение ими пользоваться плюс база различных паттернов их использования, то для каждого проекта каждый сам сможем решить для себя, какие техники и когда применять.
Нет никаких солюшенов и сводов правил, есть вы и git, некий набор инструментов в рамках гита и ваше умение ими пользоваться.
Кажется, до меня дошла ваша мысль ). Если есть понимание инструментов и умение ими пользоваться плюс база различных паттернов их использования, то для каждого проекта каждый сам сможем решить для себя, какие техники и когда применять.
Именно это я и хотел сказать — причем «паттерны» — это как бы частички вашего собственного опыта, а не вычитаные где-то рецепты. То есть их конечно можно вычитать, но понимать что и как именно они делают все равно надо, иначе если произойдет что-то непредвиденное разобраться самостоятельно будет крайне трудно. :)
Всегда делаю git fetch, а дальше по обстоятельствам. Я больше не доверяю я git pull и тем более git pull --rebase. Ну не нравиться мне потом в рефлоге ковыряться…
А расскажите подробнее, почему больше не доверяете? Я тоже всегда делаю fetch, а потом смотрю что дальше, но теперь хотел делать всегда git pull --rebase вместо ручного git fetch && git merge/rebase
Потому что ты не видишь что тебе пришло. Он просто берет и начинает ребейз, а потом говорит: упс конфликт. Т.е. его нужно прямо сейчас решить или откатиться.
При явном fetch я могу примерно оценить, будут конфликты или нет, бегло просмотрев сообщения и/или правки. Возможно при ребейзе нужно будет использовать какую-нибудь нестандартную стратегию. Нужны ли мне вообще эти изменения прямо сейчас, и т.д.
При явном fetch я могу примерно оценить, будут конфликты или нет, бегло просмотрев сообщения и/или правки. Возможно при ребейзе нужно будет использовать какую-нибудь нестандартную стратегию. Нужны ли мне вообще эти изменения прямо сейчас, и т.д.
Спасибо за статью!
Хотелось бы иметь некую выжимку из статьи, чтобы повесить на стенку. Этакая табличка в 2 столбика: (1) Разработчик, (2) Интегратор проекта, а в строках сверху вниз их действия в хронологическом порядке. Классный бы рефкард получился…
Хотелось бы иметь некую выжимку из статьи, чтобы повесить на стенку. Этакая табличка в 2 столбика: (1) Разработчик, (2) Интегратор проекта, а в строках сверху вниз их действия в хронологическом порядке. Классный бы рефкард получился…
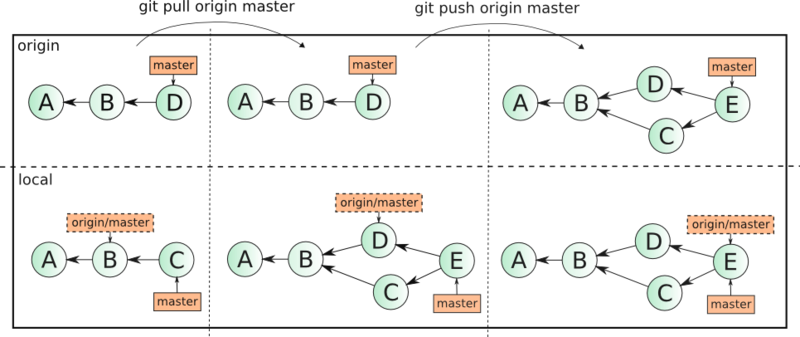{kind=link}
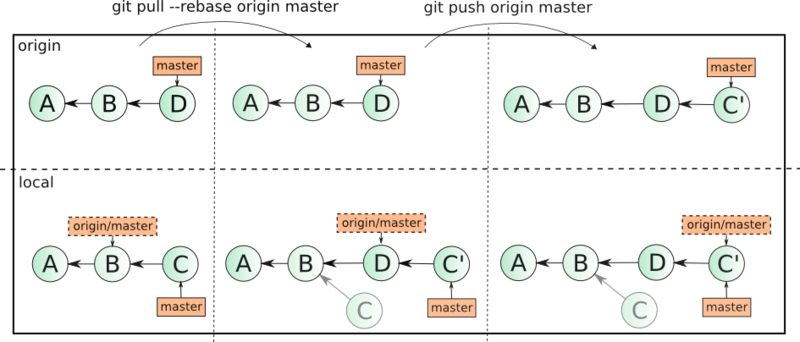{kind=link}
За коммиты в мастер/деволоп а-ля «Mergin remote into local» надо вообще на костре сжигать и точка.
ps: Ну ладно — но хотя бы поджаривать слегонца? :)
ps: Ну ладно — но хотя бы поджаривать слегонца? :)
Спасибо за статью, познавательно. Только не deattached, а detached, исправьте, пожалуйста.
cite: Если вы забудете указать идентификатор ветки, то force-push будет выполнен для всех локальных веток, имеющих удаленный оригинал.
Чтоб такого не случилось — в конфиге git'a параметру push.default надо поставить значение upstream или current (это разные вещи, выберите сами что вам больше подходит).
git config --global push.default upstream
git config --global push.default current
Значение по-умолчанию — matching, и я категорически не понимаю, почему это именно так.
Чтоб такого не случилось — в конфиге git'a параметру push.default надо поставить значение upstream или current (это разные вещи, выберите сами что вам больше подходит).
git config --global push.default upstream
git config --global push.default current
Значение по-умолчанию — matching, и я категорически не понимаю, почему это именно так.
Можно задать настройки для автоматического rebase.
Использовать автоматический rebase для новых веток:
для существующих:
Использовать автоматический rebase для новых веток:
git config branch.autosetuprebase alwaysдля существующих:
git config branch.*branch-name*.rebase true[del]
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Git Rebase: руководство по использованию