Комментарии 48
Я не могу понять, зачем столько усилий? Не рекапче сидят тыщи китайцев, процент почти 100.
Не спортивно же :)
Далеко не 100 и медленно :)
На рекапче никто не сидит, сидят на антигейтах и подобных сайтах :)
рекапча? Может быть Pixodrom ( pixodrom.com )?
Также можно скриптом завалить сайт заявками используя гугл в качестве генератора случайных урлов.
UPD. мб сделать? кто что думает?
UPD. мб сделать? кто что думает?
Могут по ip заблокировать, надо над прокси подумать еще. Ну и над самими заявками, чтобы сайты побольше были да загружались подольше. Кстати, они же вручную проверяют… Им же случайно могут попасться порноссылки и даже ссылки на вредоносные сайты. Как они с этим борются интересно)
Можно использовать Tor. Да и листы паблик-прокси достать не такая уж и проблема.
И как альтернативный вариант — вебсервер с js-кой, что будет выполнять эти действия и опубликовать ссылку. Кто-то да воспользуется. В реестре не обрадуются.
Я бы назвал это спам-оберткой вокруг zapret-info.gov.ru/ ))
Генератор не интересно. Интересно отправлять ссылки на реальные страницы. В этом случае не будет возможности различить стукачество от шумоизоляции, т.е. кому-то там придётся идти и читать всё, что прислали. А это куда эффективнее, чем засирание базы, ибо в условиях перегрузки люди не прекращают обработку новых запросов, а начинают халтурить с существующими.
В принципе, отправка результатов поиска гугла по inurl:a, inurl:b и т.д. — неплохая стратегия.
В принципе, отправка результатов поиска гугла по inurl:a, inurl:b и т.д. — неплохая стратегия.
Вообще-то я и имел ввиду отправку реальных урлов полученных через поиск гугла. По запросу «сайт» например.
p.s. Существуют сервисы типа этого (http://www.randominio.com/ru) что по клику перенаправляют на случайную страницу. Это ещё круче и проще, чем поиск гугла.
p.s. Существуют сервисы типа этого (http://www.randominio.com/ru) что по клику перенаправляют на случайную страницу. Это ещё круче и проще, чем поиск гугла.
НЛО прилетело и опубликовало эту надпись здесь
Можно по этим спискам пройтись просто =)
panel.reghouse.ru/ru_domains.gz
panel.reghouse.ru/su_domains.gz
panel.reghouse.ru/ru_domains.gz
panel.reghouse.ru/su_domains.gz
Как-то так и закроют хабр, ведь это подстрекательство на кибер-терроризм.
Вкину свои 5 копеек. Встала тут недавно задача голосовалку обмануть. Правда она была без капчи зато позволяла голосануть 1 раз с IP адреса. В общем вот вам однострочник на шеле, может сгодится кому:
Прокси серверы брал отсюда
while read line;
do echo $line;
curl http://voteurl.ru/vote/path/ -d "postKey1=postValue1&postKey2=postValue2" -x $line -o ./output.txt ;
done < /home/name/proxy-list.txt
Прокси серверы брал отсюда
Ну все теперь…
UnixWay!
И в главном скрипте вторую строку лучше вот такой сделать
c=$(curl -c cook.txt http://zapret-info.gov.ru/ | iconv -f cp1251 | grep capcha | sed -n 's/.*src="\(.*\)".*/\1/p')В конце концов они замучаются и сделают белый список вместо черного. Вот тогда реально весело будет.
Я удивлен, если честно, что они с этого не начали.
А что с презумпцией невиновности тогда делать? По такому принципу можно всех садить в тюрьму, а за хорошее поведение выпускать!
Они, конечно могут, я, лично не особо удивлюсь...
Они, конечно могут, я, лично не особо удивлюсь...
Тише, sam002, тише.
Возможно что суть в том, что для того, чтобы составить тот самый белый список, нужно время. И немало времени. Результат же нужен уже сейчас, посему, самый простой способ прекращения доступа к «неподходящим» ресурсам — тупо их блочить. А если не подготавливать такой список заранее то это будет сродни банальному отрубанию кабеля. Если приобщить народ к таким действиям (как сейчас) в виде заявок и прочего, то в первые часы (если не минуты) ресурс просто ляжет. Люди будут массово слать просьбы разлочить их любимый форум ветеринаров, вики скейтеров, ещё-что-нибудь и т.д. и т.п. Как по мне, так геморрою будет по самое небалуйся. Посему, проще сделать то, что сделано.
Можно повысить кдп до 99%, так как по одному урлу(типа zapret-info.gov.ru/services/capcha/?i=123) отдаются одни и те же цифры(так как, судя по всему, сессия генерируется на странице, а не из картинки). Несколько раз запрашиваем, распознаём, выбираем по большинству.
Интересно, а есть зависимость между текстом капчи и параметром i в урле?
i строго зависит от phpssid. Нельзя получить каптчу без phpssid или неправильным i. После получения каптчи i аннулируется
Что вы имеете в виду под «получение капчи»? Отправка серверу ответа на капчу? Ибо так-то ничего не аннулируется. В течение весьма долгого времени можно невозбранно запрашивать капчу снова и снова, и она будет возвращаться с одинаковым текстом внутри, и размещен он при этом будет по-разному, как и писалось выше.
Конечно есть! По значению параметра i они производят сравнение того, какой код ввел пользователь, и какое значение кода на самом деле. в параметре i просто идентификатор кода хранится(не сам код!)
> Минимальное КПД
КПД — это коэффициент, поэтому «минимальный», «максимальный».
КПД — это коэффициент, поэтому «минимальный», «максимальный».
res=$(cat result.txt | sed -e 's/[^0-9]//g')
Useless cat. Почему сразу-то не сделать так:
res=$(sed -e 's/[^0-9]//g' result.txt)
Попробовал увеличить картинку при перед прогоном через Tesseract.
Случаев, когда совсем распознать не получилось становится сильно меньше, но общий результат от этого не меняется. И работать начинает заметно дольше.
Жаль.
Случаев, когда совсем распознать не получилось становится сильно меньше, но общий результат от этого не меняется. И работать начинает заметно дольше.
Жаль.
Вот и начались первые попытки взлома данного занимательного ресурса. Думаю это далеко не последний случай. Ждемс. Ждемс.
Или просто научить Tesseract шрифту каптчи. Сам шрифт похож на Arial, но тессеракт постоянно путает 3 и 8, 1 и 7.
Может быть, стоило решить эту проблему, прежде чем публиковать статью? Все же явно видно, что 3\8 и 1\7 очень сильно отличаются:
Скрытый текст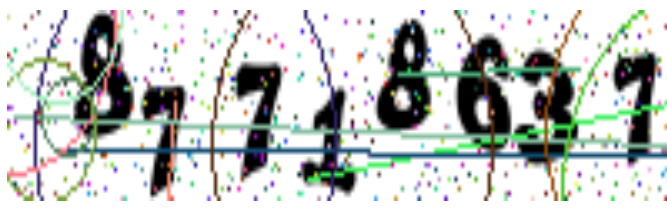

Статья про обработку изображений без картинок — не лучшая идея.
Зарегистрируйтесь на Хабре , чтобы оставить комментарий
«Оцифровываем» каптчу единого реестра сайтов, защищающего людей от информации