Комментарии 24
P.S. Если у вас есть готовые наработки или скрипты по подготовке изображения к распознаванию — делитесь в комментариях. Всем будет интересно и полезно.
Не совсем по теме, но я однажды распознавал слабую каптчу односточником на баше. Все очень просто: сначала обрабатывал её imagemagick'ом, разделяя все пиксели на черные и белые по яркости. После кормил её ocrad'у и получал практически 100% точность
Великолепный обзор, очень полный и детальный, прочитал с удовольствием!
С тем же cunei form довольно печальная ситуация: клепают для него фронтенды, а распознавалка всё так же работает. Вот tesseract выглядел в перспективе решением всех проблем, когда только вышел, но что с ним стало сейчас я не был в курсе.
А в чем смысл сборки всего и вся руками? Например в Ubuntu, Arch и Gentoo Cuneiform ставится пакетами. Остальное не проверял.
Юзал Tesseract и Cuneiform для распознавания капч. Перед OCR применял различные фильтры (grayscale и т.п.). Оба продукта вполне юзабельны на несложных задачах.
Апстрим Cuneinform вроде мертв, а жаль. Оцифровываю 100-страничный скан книги с помощью YAGF — немного неудобно, но ничего криминального. Приходится текст копировать в LibreOffice, а уже там проверять орфографию.
А вы не пробовали делать препроцессинг с ImageMagick?
www.imagemagick.org/Usage/
www.imagemagick.org/Usage/
Во-первых, это слишком простой пример: яркость распределена достаточно равномерно. Во-вторых, в препроцессинге руками для каждого изображения параметры подбирать сложно.
Ваш пример:

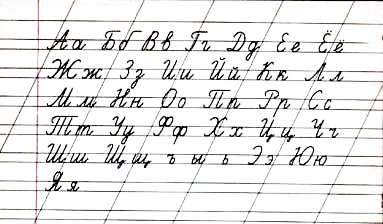
Но возьмите ту же фотографию со вспышкой или просто кучу изображений с различной яркостью — как их обработать пакетно? Одинаковые настройки конвертирования не подойдут.
Тут нужен инструмент, который для каждого изображения будет изменять, к примеру, яркость и контраст, и при этом оценивать данные изменения (нет ли пересвета и не достаточно ли темное изображение).
Ваш пример:

convert INPUT -modulate 190 -contrast -contrast -normalize OUTPUT

Но возьмите ту же фотографию со вспышкой или просто кучу изображений с различной яркостью — как их обработать пакетно? Одинаковые настройки конвертирования не подойдут.
Тут нужен инструмент, который для каждого изображения будет изменять, к примеру, яркость и контраст, и при этом оценивать данные изменения (нет ли пересвета и не достаточно ли темное изображение).
Вообще для целей предобработки неплохо бы использовать один из многих алгоритмов адаптивной (динамической) бинаризаци. Т.к. в опенсорсных OCR бинаризация ну уж совсем некачественная — плохо выбирает порог, не обрабатывает переменную яркость и пр.
Вот пример описания: it-claim.ru/Library/Books/ITS/wwwbook/ist4b/its4/fyodorov.htm
И пара примеров работы с той статьи:


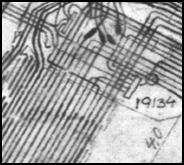
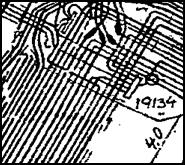
Вот пример описания: it-claim.ru/Library/Books/ITS/wwwbook/ist4b/its4/fyodorov.htm
И пара примеров работы с той статьи:




Вообще-то это пример не мой, а из самого ImageMagick, если бы вы пошли по ссылке, то увидели бы его:
convert text_scan.png \( +clone -blur 0x20 \) -compose Divide_Src -composite text_scan_divide.png
По указанной вами ссылке на www.imagemagick.org/Usage/ такого примера не вижу.
{kind=link}
{kind=link}
{kind=link}
В своё время (года два назад) маме понадобилось распознавать тексты. Собрал cuneiform.
Yagf у меня, несмотря на свою «функциональность», просто не заработал (почти всегда приводил к загрузке процессора в 100% и полное отсутствие реакции, либо просто к сегфолту). В общем, между yagf и cuneiform-qt остановился именно на последнем, как на работающем.
Вот и собрал для неё cuneiform + cuneiform-qt.
Основная проблема собственно cuneiform — на некоторых изображениях он падает; как правило, на А4 разрешением 600 dpi и больше. Фотографии документов распознаёт нормально, с таблицами и прочими не-текстовыми элементами, а также расположением текста в несколько колонок — проблемы (приходится резать на колонки и удалять всё лишнее). Фотографии распознаёт не сильно-то и хуже, чем сканы.
В целом, такого решения более чем хватило для работы. Так что категорически не согласен с выводом «бесполезен» для cuneiform-qt.
Yagf у меня, несмотря на свою «функциональность», просто не заработал (почти всегда приводил к загрузке процессора в 100% и полное отсутствие реакции, либо просто к сегфолту). В общем, между yagf и cuneiform-qt остановился именно на последнем, как на работающем.
Вот и собрал для неё cuneiform + cuneiform-qt.
Основная проблема собственно cuneiform — на некоторых изображениях он падает; как правило, на А4 разрешением 600 dpi и больше. Фотографии документов распознаёт нормально, с таблицами и прочими не-текстовыми элементами, а также расположением текста в несколько колонок — проблемы (приходится резать на колонки и удалять всё лишнее). Фотографии распознаёт не сильно-то и хуже, чем сканы.
В целом, такого решения более чем хватило для работы. Так что категорически не согласен с выводом «бесполезен» для cuneiform-qt.
Да, забыл добавить: всё это пробовалось в kubuntu и gentoo. В генте и сейчас стоит.
У меня тоже падал на больших картинках (1336х1852) с русским языком, я написал в багзиллу федоры и через месяц получил фикс, вот уже 20 штук распознал, пока ни разу не падал.
Может, и вам поможет bugzilla.redhat.com/show_bug.cgi?id=836706
Может, и вам поможет bugzilla.redhat.com/show_bug.cgi?id=836706
Спасибо за хороший обзор
Когда я писал программу для распознавания автомобильного номера в Qt + Tesseract OCR, столкнулся с проблемой шумов
Поэтому перед распознаванием делал адаптивную бинаризацию, затем морфологические операции, но и это от шумов не избавило
В итоге применил оператор кэнни для автономера, получил список внешних контуров символов, отфильтровав эти контуры по размеру. Вроде работает. Может быть у кого-нибудь есть опыт использования Tesseract OCR с текстами, символы которых расположены под углами?
Когда я писал программу для распознавания автомобильного номера в Qt + Tesseract OCR, столкнулся с проблемой шумов
Поэтому перед распознаванием делал адаптивную бинаризацию, затем морфологические операции, но и это от шумов не избавило
В итоге применил оператор кэнни для автономера, получил список внешних контуров символов, отфильтровав эти контуры по размеру. Вроде работает. Может быть у кого-нибудь есть опыт использования Tesseract OCR с текстами, символы которых расположены под углами?
Немного дурацкий вопрос — а есть ли OCR, способные распознавать на картинке текста, в корявой кодировке? То есть что то типа ╨╥╔╫┼╘ ╚┴┬╥
3. Finereader Сразу отмечу большой минус: насколько я понял, Finereader работает только с правами суперпользователя.
Под рутом нужно только активировать лицензию, дальше от обычного пользователя работает.
Сейчас тестирую 11-ю версию движка finereader под linux.
Из интересных особенностей:
1. Есть режимы выдергивания и сохранения всех вариантов распознаваемых слов, а не только какого-то одного. Это полезно например в случае хранения архива сканированных документво (как в моем случае) — текст храниться в pdf под картинкой, при этом хранятся все варианты слов которые finereader предполагал — и правильные и неправильные. Это позволяет лучше искать по содержимому документа — в тех случаях, когда FineReader отбросил бы правильный вариант слова и выбрал бы другой для подстановки в обычный текст.
2. Одновременный экспорт в несколько форматов. Например из pdf сразу в pdf (распознанный), txt и xml. Последние два формата могут использоваться для автоматической сортировки документов по содержимому без необходимости разбора и чтения pdf-формата. Txt получается качественный, очень простой для анализа. Xml-ка настраивается и может быть как простой, так и очень полной — включая все варианты предполагаемых слов и все варианты предполагаемых символов для распознавания с их характеристиками. Т.е. в специальных случаях можно использовать FineReader для распознавания символов на бумаге, а потом уже самостоятельно корректировать текст или собирать его из символов в нужном виде. Например для разбора анкет или распознавания ИНН на какой-то форме из собственной базы контрагентов и т.п. — можно посмотреть в xml для каждой позиции те символы которые тут могли бы быть.
Для себя пока оставлю сортировку по текстовому варианту, но возможность работы с таким подробным xml сильно понравилась.
Т.е. интересный инстурмент для построения на его базе специализированных ocr, переложив на finereader самую тяжёлую работу — по доставанию символов из картинки.
Под рутом нужно только активировать лицензию, дальше от обычного пользователя работает.
Сейчас тестирую 11-ю версию движка finereader под linux.
Одиннадцатая версия — да, рут не нужен. Девятая версия для запуска его требовала.
Finereader:
Тут надо отметить, что оплата однократная — т.е. 149 евро оплатчивается 1 раз, а потом можно распознавать по 12000 страниц в год без ограничения количества лет — т.е. пока программу на компьютере без виртуалки сможете запустить (внутри виртуалок не работает).
При однократной оплате, а не ежегодной интересность предложения значительно повышается.
Однако, минимальная стоимость его составляет 149€ за лицензию на 12000 распознаваний в год — надо ли вам это?
Тут надо отметить, что оплата однократная — т.е. 149 евро оплатчивается 1 раз, а потом можно распознавать по 12000 страниц в год без ограничения количества лет — т.е. пока программу на компьютере без виртуалки сможете запустить (внутри виртуалок не работает).
При однократной оплате, а не ежегодной интересность предложения значительно повышается.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Оптическое распознавание символов в Linux