Всем привет.
Время от времени я, как и большинство программистов, изучаю какие-то новые структуры и алгоритмы.
В этот раз мне на глаза попались статьи по cache oblivious алгоритмам. Это такие алгоритмы, которые изначально более оптимизированы для работы с подсистемой кэширования современных процессоров.
Одним из представителей этой группы является Unrolled linked list.
Что же это такое?
Чтобы понять, что же это такое и с чем его едят, предлагаю вспомнить наиболее популярные реализации списков: ArrayList (с некоторым упрощением будем говорить о массивах вместо непосредственно списка) и LinkedList.
Рассмотрим их основные достоинства и недостатки:
ArrayList:
Достоинства
Недостатки
LinkedList:
Достоинства
Недостатки
Так вот UnrolledLinkedList пытается объединить достоинства двух списков и при этом не унаследовать их недостатки.
Рассмотрим устройство этого списка более подробно.
Попросту говоря, UnrolledLinkedList — связный(двусвязный) список массивов длины n. То есть каждая нода содержит в себе не одно значение, а массив значений. При этом массив является достаточно маленьким, чтобы операции вставки и удаления были очень быстрыми и фрагментация памяти меньше влияла на возможность создания ноды, но достаточно большие, чтобы полностью помещаться в строку кэша, для сокращения количества cache miss. Дополнительно каждая нода хранит в себе количество добавленных в неё элементов. Графически этот список можно представить следующим образом:
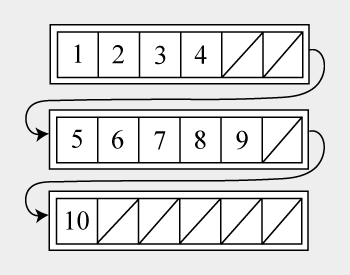
Рассмотрим операции для этого списка:
Вставка в ноду:
В случае наличия свободных ячеек, новый элемент просто добавляется в конец массива. Если массив уже полон, то мы создаём новую ноду за текущей и переносим в неё правую половину массива, создавая тем самым место для вставки новых значений. Новый элемент в таком случае будет вставлен в конец новой ноды. То же можно применить к вставке в середину массива.
Графически эту операцию можно представить следующим образом:
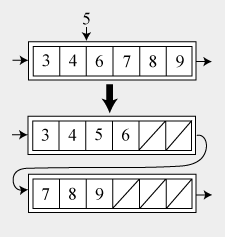
Удаление из ноды:
Операция досточно простая, мы просто удаляем нужный элемент из массива и делаем сдвиг остальных элементов, если это необходимо. Но есть одно но, в случае если количество элементов в массиве уменьшается до n/2, то из соседних ячеек переносятся n/2 элементов. Если после этого какая-то из ячеек оказалась пустой — она удаляется. Эта опреция нужна для редуцирования расхода памяти при постепенной очистке больших списков.
Поиск ноды по индексу:
Как и в связном списке поиск начинается с головы или хвоста, откуда ближе, отличие в том, что итерироваться по массивам нет нужды — необходимо просто суммировать значения полей, содержащих количество элементов в ноде. Таким образом поиск нужной ноды происходит существенно быстрее, чем в LinkedList, хотя асимптотика тут по-прежнему O(N).
Изначально мне показалось, что половина пустых ячеек в каждой ноде — это слишком расточительно. Однако как показали небольшие экперименты, в среднем уровень заполнения ячеек находится на уровне 70%, и даже с 50% заполнением расход памяти должен быть существенно меньше, чем у связного списка. Более того список позволяет настраивать себя под различные нужды. Я пытался поиграть с коэффициентом заполнения массива, но существенной выгоды не извлёк, поэтому оставил всё как есть.
Говоря про количество cache miss, то при итерации по таком списку его можно оценить как (N/n+1)(n/B), где N — длина списка, n — длина массива ноды, B — длина строки кэша. Такая оценка достаточно близка к оценке для ArrayList.
На момент написания мне также пришла в голову мысль, что подобный список может стать достаточно эффективной реализацией concurrent коллекции с возможностью блокировки только одной ноды. Однако это тема для нового исследования и новой статьи.
Исходники выложены на github.
Из себя они представляют достаточно сырой код, так что просьба не сильно пинать ногами за качество. Однако в любом случае буду признателен любой критике.
В исходниках есть некоторые попытки измерить и сравнить различные списки, однако я стесняюсь их представлять в статье, потому что не очень уверен, что все измерения произведены корректно и я не выстрелил себе в ногу. Буду очень рад помощи экспертов в области бенчмаркинга для окончательной расстановки точек над списками!
Спасибо за внимание.
Источники:
blogs.msdn.com/b/devdev/archive/2005/08/22/454887.aspx
en.wikipedia.org/wiki/Unrolled_linked_list
UPD: Всё же добрался до замеров производительности и размеров. Для микробенчмаркинга пользовался гугло-тулой caliper.
Вот результаты:
Linear Iteration
length benchmark us linear runtime
1000 UnrolledListIteration 6,34 =
1000 ArrayListIteration 5,56 =
1000 LinkedListIteration 5,93 =
100000 UnrolledListIteration 827,68 ==
100000 ArrayListIteration 637,05 =
100000 LinkedListIteration 1124,38 ==
1000000 UnrolledListIteration 9056,77 =======================
1000000 ArrayListIteration 6731,73 =================
1000000 LinkedListIteration 11800,96 ==============================
Random Access:
length benchmark us linear runtime
1000 UnrolledListIteration 6,34 =
1000 ArrayListIteration 5,53 =
1000 LinkedListIteration 5,97 =
100000 UnrolledListIteration 844,30 ==
100000 ArrayListIteration 652,21 =
100000 LinkedListIteration 1106,90 ===
1000000 UnrolledListIteration 9066,88 ==========================
1000000 ArrayListIteration 6723,21 ===================
1000000 LinkedListIteration 10339,15 ==============================
Size of:
The average size of a ArrayList is 45172432,000 bytes //Не совсем честные результаты, но показателен расход памяти при постепенном наращивании объёма.
The average size of a ArrayList with lenght 1KK is 24000064,000 bytes
The average size of a bit in a UnrolledList is 26250048,000 bytes
The average size of a bit in a LinkedList is 56000048,000 bytes
Вот такие результаты, которые вполне согласуются с теорией)
Репозиторий обновлён, все кто желает познакомиться с обновлениями или позапускать свои тесты — милости просим.
Время от времени я, как и большинство программистов, изучаю какие-то новые структуры и алгоритмы.
В этот раз мне на глаза попались статьи по cache oblivious алгоритмам. Это такие алгоритмы, которые изначально более оптимизированы для работы с подсистемой кэширования современных процессоров.
Одним из представителей этой группы является Unrolled linked list.
Что же это такое?
Чтобы понять, что же это такое и с чем его едят, предлагаю вспомнить наиболее популярные реализации списков: ArrayList (с некоторым упрощением будем говорить о массивах вместо непосредственно списка) и LinkedList.
Рассмотрим их основные достоинства и недостатки:
ArrayList:
Достоинства
- Компактность — массив является наиболее (по крайней мере одной из) компактной структур данных для представления списков;
- Скорость вставки в конец незаполненного массива — операция очень быстрая, факт!;
- Скорость взятия элемента по индексу — также очень высока, количество cache miss можно оценить в N/B, где B — размер строки кэша, а N — количество элементов массива, что можно считать эталонным для такого рода структуры.
Недостатки
- Вставка в середину — не очень удобная операция для массива, приходится сдвигать правую часть, что даже с arraycopy всё же не бесплатно;
- Протяжённость области памяти — для хранения больших массивов требуется большой непрерывный участок памяти. И хотя многие сборщики мусора эффективно борются с фрагментацией памяти, вероятность OutOfMemmory особенно для больших списков является существенной.
LinkedList:
Достоинства
- Относительно более простая и быстрая операция вставки в середину;
- Нет проблем при работе с сильно фрагментированой памятью.
Недостатки
- Существенно больший объём необходимой памяти для хранения данных того же размера (до 4-х раз);
- При итерации по списку количество cache miss в худшем случае может быть равно количеству нод списка. Даже в лучшем случае, когда все ноды находятся в пямяти друг за другом, за счёт большего размера ноды количество cache miss будет в несколько раз больше такового для ArrayList.
Так вот UnrolledLinkedList пытается объединить достоинства двух списков и при этом не унаследовать их недостатки.
Рассмотрим устройство этого списка более подробно.
Попросту говоря, UnrolledLinkedList — связный(двусвязный) список массивов длины n. То есть каждая нода содержит в себе не одно значение, а массив значений. При этом массив является достаточно маленьким, чтобы операции вставки и удаления были очень быстрыми и фрагментация памяти меньше влияла на возможность создания ноды, но достаточно большие, чтобы полностью помещаться в строку кэша, для сокращения количества cache miss. Дополнительно каждая нода хранит в себе количество добавленных в неё элементов. Графически этот список можно представить следующим образом:
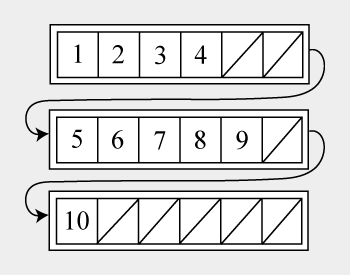
Рассмотрим операции для этого списка:
Вставка в ноду:
В случае наличия свободных ячеек, новый элемент просто добавляется в конец массива. Если массив уже полон, то мы создаём новую ноду за текущей и переносим в неё правую половину массива, создавая тем самым место для вставки новых значений. Новый элемент в таком случае будет вставлен в конец новой ноды. То же можно применить к вставке в середину массива.
Графически эту операцию можно представить следующим образом:
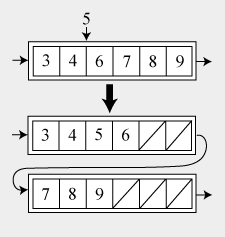
Удаление из ноды:
Операция досточно простая, мы просто удаляем нужный элемент из массива и делаем сдвиг остальных элементов, если это необходимо. Но есть одно но, в случае если количество элементов в массиве уменьшается до n/2, то из соседних ячеек переносятся n/2 элементов. Если после этого какая-то из ячеек оказалась пустой — она удаляется. Эта опреция нужна для редуцирования расхода памяти при постепенной очистке больших списков.
Поиск ноды по индексу:
Как и в связном списке поиск начинается с головы или хвоста, откуда ближе, отличие в том, что итерироваться по массивам нет нужды — необходимо просто суммировать значения полей, содержащих количество элементов в ноде. Таким образом поиск нужной ноды происходит существенно быстрее, чем в LinkedList, хотя асимптотика тут по-прежнему O(N).
Изначально мне показалось, что половина пустых ячеек в каждой ноде — это слишком расточительно. Однако как показали небольшие экперименты, в среднем уровень заполнения ячеек находится на уровне 70%, и даже с 50% заполнением расход памяти должен быть существенно меньше, чем у связного списка. Более того список позволяет настраивать себя под различные нужды. Я пытался поиграть с коэффициентом заполнения массива, но существенной выгоды не извлёк, поэтому оставил всё как есть.
Говоря про количество cache miss, то при итерации по таком списку его можно оценить как (N/n+1)(n/B), где N — длина списка, n — длина массива ноды, B — длина строки кэша. Такая оценка достаточно близка к оценке для ArrayList.
На момент написания мне также пришла в голову мысль, что подобный список может стать достаточно эффективной реализацией concurrent коллекции с возможностью блокировки только одной ноды. Однако это тема для нового исследования и новой статьи.
Исходники выложены на github.
Из себя они представляют достаточно сырой код, так что просьба не сильно пинать ногами за качество. Однако в любом случае буду признателен любой критике.
В исходниках есть некоторые попытки измерить и сравнить различные списки, однако я стесняюсь их представлять в статье, потому что не очень уверен, что все измерения произведены корректно и я не выстрелил себе в ногу. Буду очень рад помощи экспертов в области бенчмаркинга для окончательной расстановки точек над списками!
Спасибо за внимание.
Источники:
blogs.msdn.com/b/devdev/archive/2005/08/22/454887.aspx
en.wikipedia.org/wiki/Unrolled_linked_list
UPD: Всё же добрался до замеров производительности и размеров. Для микробенчмаркинга пользовался гугло-тулой caliper.
Вот результаты:
Linear Iteration
length benchmark us linear runtime
1000 UnrolledListIteration 6,34 =
1000 ArrayListIteration 5,56 =
1000 LinkedListIteration 5,93 =
100000 UnrolledListIteration 827,68 ==
100000 ArrayListIteration 637,05 =
100000 LinkedListIteration 1124,38 ==
1000000 UnrolledListIteration 9056,77 =======================
1000000 ArrayListIteration 6731,73 =================
1000000 LinkedListIteration 11800,96 ==============================
Random Access:
length benchmark us linear runtime
1000 UnrolledListIteration 6,34 =
1000 ArrayListIteration 5,53 =
1000 LinkedListIteration 5,97 =
100000 UnrolledListIteration 844,30 ==
100000 ArrayListIteration 652,21 =
100000 LinkedListIteration 1106,90 ===
1000000 UnrolledListIteration 9066,88 ==========================
1000000 ArrayListIteration 6723,21 ===================
1000000 LinkedListIteration 10339,15 ==============================
Size of:
The average size of a ArrayList is 45172432,000 bytes //Не совсем честные результаты, но показателен расход памяти при постепенном наращивании объёма.
The average size of a ArrayList with lenght 1KK is 24000064,000 bytes
The average size of a bit in a UnrolledList is 26250048,000 bytes
The average size of a bit in a LinkedList is 56000048,000 bytes
Вот такие результаты, которые вполне согласуются с теорией)
Репозиторий обновлён, все кто желает познакомиться с обновлениями или позапускать свои тесты — милости просим.







