При разработке бизнес-приложений постоянно стоит проблема хранения данных в репозитории совместно с проектом. Особенно эта тема актуальна для корпоративных ERP, CRM, многабукав и так далее систем.
Для чего это нужно:
Также, не менее остро стоит проблема надежного обновления данных на рабочем проекте, совместно с обновлением модели.
В нашей системе мы применили подход, который позволяет контролировать целостность данных, их загрузку и обновление, хранит данные в репозитории и при этом работает быстро и надежно.
Во-первых, данные должны храниться с учетом версий.
Во-вторых, хранимые данные должны быть человекочитаемыми, например, для сравнения версий.
В-третьих, сохраненные данные должны легко загружаться в работающую систему
Итак, рассмотрим типичную ERP систему с сотней взаимосвязанных сущностей, наследованием, иерархическими справочниками и так далее.
Какое решение применяет неопытный разработчик? Правильно, делает дамп базы и хранит его. Сам так делал :)
Какие минусы есть у такого решения:
1. Бинарные бэкапы сложно/неэффективно хранятся в VCS
2. Если бэкап большой и текстовый – сложно разобраться, что изменилось
3. Человеку сложно читать и искать что-то

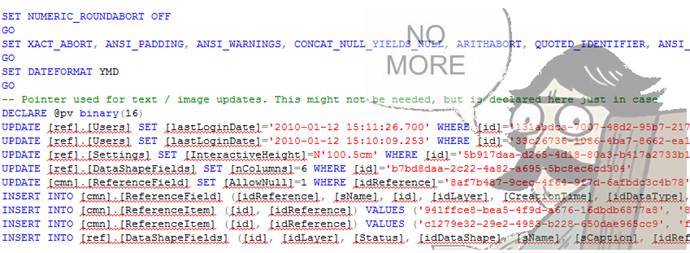
В общем, дампы/бэкапы/Sql-скрипты хранить неудобно, еще неудобнее в них разбираться.
Гораздо правильнее и удобнее хранить данные текстом, структурированным, например, в XML. В таком виде они легко читаются, diff-аются и хранятся в VCS. Данные хранятся единообразно как для создания новых записей, так и для обновления существующих.
Кроме того, MS SQL/Postgresql/Oracle умеют нативно парсить XML, а MS SQL еще и загружать его прямо в таблицы. По-большому счету, это было одним из главных преимуществ XML при выборе формата хранения.
Кстати, вот так умеет показывать Araxis Merge diff для XML-файлов
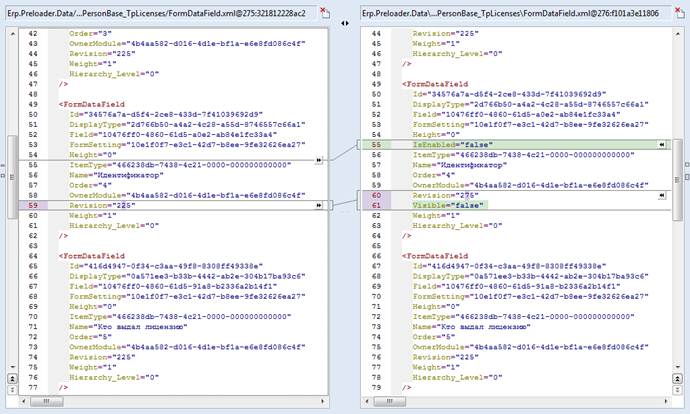
Возникает только вопрос: как это счастье загружать с учетом зависимостей, внешних ключей и взаимосвязей?
Ну… можно сделать проще всего: удалять все внешние ключи, грузить данные, после этого все ключи возвращать на место. Опять же, прошел и этот этап в моей жизни :)
Минусы решения:
1. Сложная логика по удалению/созданию ключей
2. Если структура БД сложная или объем данных велик – процесс создания/удаления ключей может быть длительным
3. И самое главное: при восстановлении ключей ошибка проявится уже только после того, как загружены ВСЕ данные, поэтому нет возможности точно определить место ошибки.
Размышляя на эту тему, я пришел к мысли, что удалять внешние ключи и ограничения для загрузки не нужно. Нужно просто грузить данные сущностей в правильном порядке.
При этом нужно учитывать:
1. Внешние ключи (они же ссылки на сущности)
2. Наследование сущностей
3. Иерархичные сущности
4. Возможные циклы
Для решения этих проблем я представил совокупность сущностей в виде графа и применил Топологическую сортировку. С её помощью я отсортировал все загружаемые сущности так, что все необходимые данные уже присутствуют на момент загрузки любого элемента.

В сети есть много реализаций данного алгоритма, я же взял тот, который шел вместе с используемым ORM. На вход он принимает перечисление объектов и метод, их соединяющий, на выходе получает сортированный список + out параметр с циклами, если они были.
Выглядит примерно так:
Для работы этого алгоритма, главное правильно представить граф сущностей и его связи.
В моем случае коннектор связей выглядит так:
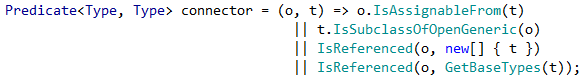
Что в переводе с древнемолдавского означает, что тип T зависит от (имеет направленную связь) типа O если:
1. T наследник O
2. T является наследником или закрытым generic-типом от открытого generic-типа O
3. T имеет в себе поля-ссылки на O
4. Базовые классы T имеют в себе поля-ссылки на O
Если первые два условия довольно очевидны, то со ссылками все не так просто, т.к. необходимо учитывать циклические связи. В реальных системах циклы между сущностями не редкость, самый очевидный пример: Сотрудники – Отделы. Сотрудник относится к Отделу, но при этом у Отдела также есть Начальник, который тоже Сотрудник.

Такие связи приходится принудительно разрывать, чтобы сортировка могла отработать. В данном примере, на поле «Отдел» у Сотрудника помещается атрибут, который указывает, что данное поле не учитывается при построении связей сущностей. После такого разрыва, однако, приходится написать немного кода, чтобы правильно заполнить поля, которые не могут быть заполнены при автоматической загрузке.
Таким образом, у меня получилось хранить данные в удобном формате, легко видеть и контролировать изменения, а также корректно и быстро загружать данные в БД при необходимости. Чего и вам желаю.
Для чего это нужно:
- Для целей тестирования
- Для совместной разработки
- Для каких-то программных алгоритмов, оперирующих этими данными
Также, не менее остро стоит проблема надежного обновления данных на рабочем проекте, совместно с обновлением модели.
В нашей системе мы применили подход, который позволяет контролировать целостность данных, их загрузку и обновление, хранит данные в репозитории и при этом работает быстро и надежно.
Каким требованиям должна удовлетворять такая система хранения?
Во-первых, данные должны храниться с учетом версий.
Во-вторых, хранимые данные должны быть человекочитаемыми, например, для сравнения версий.
В-третьих, сохраненные данные должны легко загружаться в работающую систему
Итак, рассмотрим типичную ERP систему с сотней взаимосвязанных сущностей, наследованием, иерархическими справочниками и так далее.
Какое решение применяет неопытный разработчик? Правильно, делает дамп базы и хранит его. Сам так делал :)
Какие минусы есть у такого решения:
1. Бинарные бэкапы сложно/неэффективно хранятся в VCS
2. Если бэкап большой и текстовый – сложно разобраться, что изменилось
3. Человеку сложно читать и искать что-то
В общем, дампы/бэкапы/Sql-скрипты хранить неудобно, еще неудобнее в них разбираться.
Гораздо правильнее и удобнее хранить данные текстом, структурированным, например, в XML. В таком виде они легко читаются, diff-аются и хранятся в VCS. Данные хранятся единообразно как для создания новых записей, так и для обновления существующих.
Кроме того, MS SQL/Postgresql/Oracle умеют нативно парсить XML, а MS SQL еще и загружать его прямо в таблицы. По-большому счету, это было одним из главных преимуществ XML при выборе формата хранения.
Кстати, вот так умеет показывать Araxis Merge diff для XML-файлов
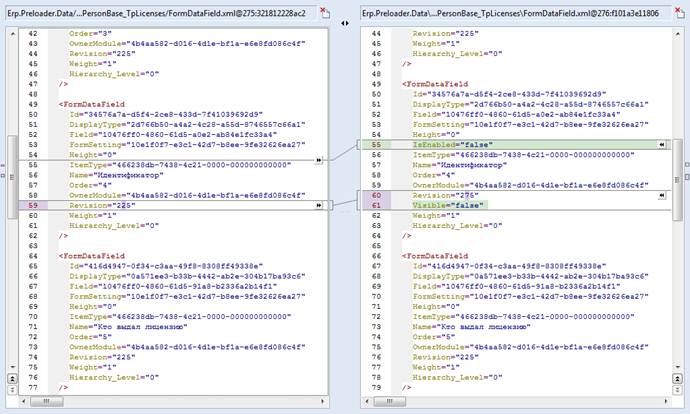
Возникает только вопрос: как это счастье загружать с учетом зависимостей, внешних ключей и взаимосвязей?
Ну… можно сделать проще всего: удалять все внешние ключи, грузить данные, после этого все ключи возвращать на место. Опять же, прошел и этот этап в моей жизни :)
Минусы решения:
1. Сложная логика по удалению/созданию ключей
2. Если структура БД сложная или объем данных велик – процесс создания/удаления ключей может быть длительным
3. И самое главное: при восстановлении ключей ошибка проявится уже только после того, как загружены ВСЕ данные, поэтому нет возможности точно определить место ошибки.
Как же можно избавиться от удаления/создания ключей, а также по возможности получать ошибку на самом раннем этапе загрузки?
Размышляя на эту тему, я пришел к мысли, что удалять внешние ключи и ограничения для загрузки не нужно. Нужно просто грузить данные сущностей в правильном порядке.
При этом нужно учитывать:
1. Внешние ключи (они же ссылки на сущности)
2. Наследование сущностей
3. Иерархичные сущности
4. Возможные циклы
Для решения этих проблем я представил совокупность сущностей в виде графа и применил Топологическую сортировку. С её помощью я отсортировал все загружаемые сущности так, что все необходимые данные уже присутствуют на момент загрузки любого элемента.
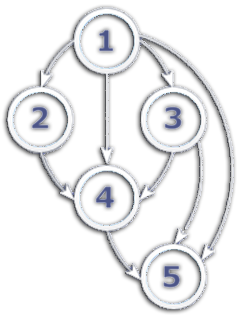
В сети есть много реализаций данного алгоритма, я же взял тот, который шел вместе с используемым ORM. На вход он принимает перечисление объектов и метод, их соединяющий, на выходе получает сортированный список + out параметр с циклами, если они были.
Выглядит примерно так:
public static List<TNodeItem> Sort<TNodeItem>(IEnumerable<TNodeItem> items, Predicate<TNodeItem, TNodeItem> connector, out List<NodeConnection<TNodeItem, object>> removedEdges) {}
Для работы этого алгоритма, главное правильно представить граф сущностей и его связи.
В моем случае коннектор связей выглядит так:
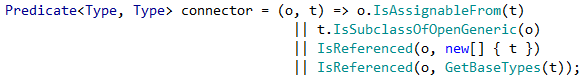
Что в переводе с древнемолдавского означает, что тип T зависит от (имеет направленную связь) типа O если:
1. T наследник O
2. T является наследником или закрытым generic-типом от открытого generic-типа O
3. T имеет в себе поля-ссылки на O
4. Базовые классы T имеют в себе поля-ссылки на O
Если первые два условия довольно очевидны, то со ссылками все не так просто, т.к. необходимо учитывать циклические связи. В реальных системах циклы между сущностями не редкость, самый очевидный пример: Сотрудники – Отделы. Сотрудник относится к Отделу, но при этом у Отдела также есть Начальник, который тоже Сотрудник.
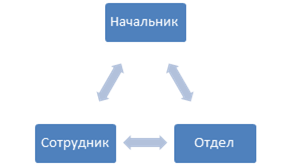
Такие связи приходится принудительно разрывать, чтобы сортировка могла отработать. В данном примере, на поле «Отдел» у Сотрудника помещается атрибут, который указывает, что данное поле не учитывается при построении связей сущностей. После такого разрыва, однако, приходится написать немного кода, чтобы правильно заполнить поля, которые не могут быть заполнены при автоматической загрузке.
Таким образом, у меня получилось хранить данные в удобном формате, легко видеть и контролировать изменения, а также корректно и быстро загружать данные в БД при необходимости. Чего и вам желаю.








