Комментарии 31
интересный материал. почаще бы…
Что такое энтропия текста?
Я сначала хотела добавить определение в начало топика, но потом передумала. Возможно, всё-таки ошиблась.
В теории информации энтропия — это мера неопределённости. Она вычисляется по формуле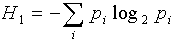 , где p — вероятности появления символов.
, где p — вероятности появления символов.
Смысл энтропии в том, что она численно равна среднему количеству информации, которую несёт один символ данного текста, в битах. В рамках одного алфавита энтропия максимальна для генератора случайных букв с равномерным распределением, и минимальна (нулевая) для генератора, возвращающего один неслучайный символ. В реальном языке частота букв различна, поэтому энтропия меньше максимального значения; кроме того, вероятность появляения каждого символа зависит от предыдущих, и поэтому вводят условную энтропию 2,3 и т.п. порядка.
Энтропия текста — это некоторое приближение к энтропии языка, при котором мы вместо вероятностей используем относительные частоты появления символов в данном тексте.
В теории информации энтропия — это мера неопределённости. Она вычисляется по формуле
, где p — вероятности появления символов.Смысл энтропии в том, что она численно равна среднему количеству информации, которую несёт один символ данного текста, в битах. В рамках одного алфавита энтропия максимальна для генератора случайных букв с равномерным распределением, и минимальна (нулевая) для генератора, возвращающего один неслучайный символ. В реальном языке частота букв различна, поэтому энтропия меньше максимального значения; кроме того, вероятность появляения каждого символа зависит от предыдущих, и поэтому вводят условную энтропию 2,3 и т.п. порядка.
Энтропия текста — это некоторое приближение к энтропии языка, при котором мы вместо вероятностей используем относительные частоты появления символов в данном тексте.
Спасибо, теперь ваш пост понятен. :-)
Вы как-то упустили из виду, что стилистика изложения формируется из слов (корпус), их цепочек (статистика) и правил их формирования (эвристика), а не единичных литер. По-моему так, на мой дилетантский взгляд.
…Вот если бы вы анализировали прононсы, вот тогда бы ваше наблюдение могло быть применено с бoльшим успехом.
Вы как-то упустили из виду, что стилистика изложения формируется из слов (корпус), их цепочек (статистика) и правил их формирования (эвристика), а не единичных литер. По-моему так, на мой дилетантский взгляд.
…Вот если бы вы анализировали прононсы, вот тогда бы ваше наблюдение могло быть применено с бoльшим успехом.
Не то чтобы я упускала это из виду, просто исследование велось как раз на уровне максимальной абстракции, на основе имеющихся данных о статистических различиях по буквам и их сочетаниям.
Планирую взять более конкретные разработки данной темы для магистерского диплома, поэтому огромный интерес представляют комментарии хабралюдей :)
Планирую взять более конкретные разработки данной темы для магистерского диплома, поэтому огромный интерес представляют комментарии хабралюдей :)
Стратоновича читать стоит?
эту формулу хорошо произносить как «эпилог тупи» :-)
Грубый пример - сжатие архиватором. Два текста одного автора должны сжаться лучше, чем два текста разных авторов того же размера (в символах) из-за повторяемости речевых особенностей стиля, оборотов и т. п.
Ого. Лингво-архиватор :-)
В разделе Самиздат Lib.ru раньше работал на этом принципе Лингвоанализатор - который позволял определить "похожесть" текста на тексты авторов из Lib.ru. Не всегда точно - но иногда действительно очень удачно.
Насколько я вникала в эту тему, Лингвоанализатор подсчитывал похожесть сразу по большому количеству признаков, среди которых как энтропийные, так и чисто статистические (типа процентного соотношения служебных слов), а потом уже по их совокупности подбирал наиболее близкий вариант. Весьма разумный подход :)
Спасибо, интересно.
Значит определить, кто написал курсовой проект, до сих пор точно нельзя =)
Кто-нибудь, объясните пожалуйста: imdb.com работает по схожему принципу?
Значит определить, кто написал курсовой проект, до сих пор точно нельзя =)
Кто-нибудь, объясните пожалуйста: imdb.com работает по схожему принципу?
упс, ошибся: http://www.gracenote.com/ конечно же, а не imdb.com.
Мне кажется, вы исходно взяли неподходящюю для задачи модель. Для рассмотрения авторства посимвольный анализ не очень подойдёт - в конце концов все авторы используют одни и теже буквы и слова.
Вот если, к примеру, взять за элементы не символы, а слова, и рассматривать их порядок и формы в предложении, то такие показатели должны существенно отличаться для разных текстов. Но это тема для анализа на порядок сложнее проведённого.
Вот если, к примеру, взять за элементы не символы, а слова, и рассматривать их порядок и формы в предложении, то такие показатели должны существенно отличаться для разных текстов. Но это тема для анализа на порядок сложнее проведённого.
Интересное исследование. Необычно для Хабра - однозначно плюс в карму :) Вообще лично у меня и до этого были сомнения на сколько корректно оценивать при работе с такими данными, как тексты, показатели распределения символов, а не слов.
Видимо для работы с текстами вообще (и решения вопросов определения авторства , идентификации и классификации текстов и т.д.) более плодотворно применять такие модели как Vector space model - то есть работать с текстами не как с состоящими из символов, а как состоящими из набора терминов-идентификаторов.
Видимо для работы с текстами вообще (и решения вопросов определения авторства , идентификации и классификации текстов и т.д.) более плодотворно применять такие модели как Vector space model - то есть работать с текстами не как с состоящими из символов, а как состоящими из набора терминов-идентификаторов.
По-хорошему бы ещё словоформы отслеживать, но это значительно сложнее, думаю.
Не так уж сложно. Другое дело в том, что, поставив целью определение авторства, мы должны оперировать в первую очередь производной формой слова, как частью N-граммы, а не нормальными формами.
Видимо да - при рассмотрении вопросов определения авторства, особенно в таком языке как русский, нужно учитывать именно все словоформы.
Работать с текстами как с набором идентификаторов больше подходит для задач автоматической классификации, но для определения авторства/стиля скорее всего не будет давать достаточную точность.
Работать с текстами как с набором идентификаторов больше подходит для задач автоматической классификации, но для определения авторства/стиля скорее всего не будет давать достаточную точность.
ДА исследование интересное. Теперь этот способ скорее всего можно отбросить.
Лично мне интересно было бы сделать проверку на сходство текста так.
Имеется некоторая база: Id - список синонимичных слов. Далее каждому слову происходит сопоставление Id. Таким образом получаем закодированную последовательность. После этого все это дело пропускается через wavelet с устранением шума. Затем сравнивается с оригиналом, прошедшем предварительно такую же обработку. И затем просто находим разницу весов полученных коэффициентов. Проходя порог можно с какой то достоверностью утверждать что данный текст изменённая копия. Вкратце так. Это всего лишь макет за одну минуту. Может и бред.
Ps А не кто не даст ссылку, где можно найти тексты похожие, я может сам бы занялся таким экспериментом.
Лично мне интересно было бы сделать проверку на сходство текста так.
Имеется некоторая база: Id - список синонимичных слов. Далее каждому слову происходит сопоставление Id. Таким образом получаем закодированную последовательность. После этого все это дело пропускается через wavelet с устранением шума. Затем сравнивается с оригиналом, прошедшем предварительно такую же обработку. И затем просто находим разницу весов полученных коэффициентов. Проходя порог можно с какой то достоверностью утверждать что данный текст изменённая копия. Вкратце так. Это всего лишь макет за одну минуту. Может и бред.
Ps А не кто не даст ссылку, где можно найти тексты похожие, я может сам бы занялся таким экспериментом.
А вы поищите что-нибудь про Highload :-)
Таким образом можно вычислить сплог, контент которого прогнан через синонимайзер. При рерайтинге изменения почти всегда не пословные.
Идею поддерживаю. Но есть два момента:
1. Автор вообще-то говорит о другой задаче - установить общее авторстово, а не общую суть. Разница существенная.
2. Есть говорить об затронутой вами проблеме поиска дублей, то увы, обычно задача определения схожести не приходит одна. Если оригинал неизвестен, подобный метод теряет актуальность из-за своей ресурсовемкости.
1. Автор вообще-то говорит о другой задаче - установить общее авторстово, а не общую суть. Разница существенная.
2. Есть говорить об затронутой вами проблеме поиска дублей, то увы, обычно задача определения схожести не приходит одна. Если оригинал неизвестен, подобный метод теряет актуальность из-за своей ресурсовемкости.
Интересный вариант, но любой грамотный плагиатчик будет производить с текстом некоторые более сложные изменения, и далеко не всегда исходный текст известен.
Энтропийные тесты (основанные на архивировании, а не прямом подсчёте, как в моём случае) применялись в частности для анализа авторства «Тихого Дона» — то есть в условиях, когда даны некоторые другие, не связанные с данным текстом произведения разных авторов (Шолохов, Крюков), и необходимо выявить схожесть авторского стиля. На высоком уровне этим занимаются лингвисты и филологи, а данная статья — пример самого низкого уровня определения авторских закономерностей.
Вот интересная статья по данной тематике: http://www.voppsy.ru/issues/1989/891/891…
Энтропийные тесты (основанные на архивировании, а не прямом подсчёте, как в моём случае) применялись в частности для анализа авторства «Тихого Дона» — то есть в условиях, когда даны некоторые другие, не связанные с данным текстом произведения разных авторов (Шолохов, Крюков), и необходимо выявить схожесть авторского стиля. На высоком уровне этим занимаются лингвисты и филологи, а данная статья — пример самого низкого уровня определения авторских закономерностей.
Вот интересная статья по данной тематике: http://www.voppsy.ru/issues/1989/891/891…
НЛО прилетело и опубликовало эту надпись здесь
Спасибо за комментарий.
Дело в том, что сравнение по N-граммам показывает довольно сильные различия между авторами, и там легко видны характерные черты. Я предполагала, что энтропия более высокого порядка может служить некоторым характерным значением для текста, так как она учитывает именно не просто статистическое распределение символов, а зависимости между ними. Собственно, такой вариант виделся очень удобным — один текст (автор, период творчества автора) — одна характеристика (некоторая, вероятно нечёткая или на худой конец интервальная, оценка средней энтропии), что приводило бы к существенной экономии на базе данных и трудоёмкости сравнения. Однако получилось, что чем выше уровень рассматриваемых связей, тем более чувствительно значение к репрезентативности выборки (что, собственно, ожидалось, но не в таких масштабах), и о стаблизации значения на небольших выборках не может быть и речи. Разброс же значений энтропий высокого порядка на больших объёмах даёт сходную картину.
Тем не менее, вопрос авторской инварианты остаётся в силе. К сожалению, я ещё не разобралась с методами анализа текстов пословно, в частности с игнорированием словоформ, но возможно именно этой темой займусь в будущем.
Что же касается пунктуации, то это не кажется мне яркой характеристикой авторского текста, отому что, во-первых, большинство авторов всё-таки приедживаются общеустановленных правил в этой области, и во-вторых, это та область, в которой большое значение имеет редакторская правка. Однако если использовать пунктуацию для разбиения текста на блоки с последующим анализом их сложности, это может действительно дать интересную картину.
Дело в том, что сравнение по N-граммам показывает довольно сильные различия между авторами, и там легко видны характерные черты. Я предполагала, что энтропия более высокого порядка может служить некоторым характерным значением для текста, так как она учитывает именно не просто статистическое распределение символов, а зависимости между ними. Собственно, такой вариант виделся очень удобным — один текст (автор, период творчества автора) — одна характеристика (некоторая, вероятно нечёткая или на худой конец интервальная, оценка средней энтропии), что приводило бы к существенной экономии на базе данных и трудоёмкости сравнения. Однако получилось, что чем выше уровень рассматриваемых связей, тем более чувствительно значение к репрезентативности выборки (что, собственно, ожидалось, но не в таких масштабах), и о стаблизации значения на небольших выборках не может быть и речи. Разброс же значений энтропий высокого порядка на больших объёмах даёт сходную картину.
Тем не менее, вопрос авторской инварианты остаётся в силе. К сожалению, я ещё не разобралась с методами анализа текстов пословно, в частности с игнорированием словоформ, но возможно именно этой темой займусь в будущем.
Что же касается пунктуации, то это не кажется мне яркой характеристикой авторского текста, отому что, во-первых, большинство авторов всё-таки приедживаются общеустановленных правил в этой области, и во-вторых, это та область, в которой большое значение имеет редакторская правка. Однако если использовать пунктуацию для разбиения текста на блоки с последующим анализом их сложности, это может действительно дать интересную картину.
Бросайте тексты, анализируйте ноты: Бах, Моцарт, Шопен.)
ЙЕС! В точку!
Сaston, понимаю, много воды утекло с момента написания вашего комментария. Но знаете, вы не пошутили. Это хорошая идея.
Навскидку, можно прикрутить смешанный пуассоновский процесс или порыться во всем семействе непрерывных справа.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
К вопросу об использовании энтропии для идентификации текстов