Комментарии 33
познавательно, спасибо
Очень интересно, надо попробовать реализовать самому, +1 ^_^
Я писал две статьи про помехоустойчивое кодирование, года полтора назад. Обе лежат в черновиках, так и не дописанные. Правда там не только про код Хэмминга, а еще про код с проверкой на четность и блочное кодирование было… Если кому интересно (к первой статье маленький интерес был, поэтому и затих энтузиазм), могу опубликовать.
Вы университете лабораторная была
А я это дело даже в железе реализовал в своё время (кодер/декодер Хэмминга).
Здорово, помнится, мне я лабораторную работу по коду Хэмминга защищал 2 часа. Проблема была в том, что я пытался объяснить аппаратную реализацию, но неправильно истолковал исходные данные.
Теперь осталось добавить статью по циклическим кодам, я уже начал их забывать.
Теперь осталось добавить статью по циклическим кодам, я уже начал их забывать.
В питерском политехе коды Хемминга на схемотехнике проходят. Спасибо за статью!
Два вопроса:
1. Что будет если изменился контрольный бит? Судя по вашему описанию, мы поменяем какой-то информационный бит. Что не совсем верно.
2. Что будет, если изменилось 2 бита? Ясно, что исправить это мы не сможем, но сможем ли определить, что была ошибка?
1. Что будет если изменился контрольный бит? Судя по вашему описанию, мы поменяем какой-то информационный бит. Что не совсем верно.
2. Что будет, если изменилось 2 бита? Ясно, что исправить это мы не сможем, но сможем ли определить, что была ошибка?
1. поскольку при проверке не совпадёт единственный контрольный бит (потому что именно он поменялся), сумма номеров несовпадающих контрольных битов укажет как раз на него самого.
2. если изменилось два бита (очевидно, имеющих разные номера), сумма их номеров по модулю 2 будет отлична от 0, а значит такое изменение гарантированно даст ненулевой вклад в синдром (значения контрольных битов). При изменении 3 или более битов сообщение может выглядеть как хорошее (например, изменение битов 1, 2 и 3).
2. если изменилось два бита (очевидно, имеющих разные номера), сумма их номеров по модулю 2 будет отлична от 0, а значит такое изменение гарантированно даст ненулевой вклад в синдром (значения контрольных битов). При изменении 3 или более битов сообщение может выглядеть как хорошее (например, изменение битов 1, 2 и 3).
По второму пункту: да, синдром будет ненулевой. Но ведь он будет указывать на какой-то один бит. Как определить, что на самом деле была двукратная ошибка?
В данном примере синдром имеет длину 5 бит, так что теоретичиски может указывать за пределы сообщения.
Но в примере (7,4) каждый синдром указывает на какой-то поврежденный бит.
В общем, мне кажется всего этого не хватает в предложенной статье…
В данном примере синдром имеет длину 5 бит, так что теоретичиски может указывать за пределы сообщения.
Но в примере (7,4) каждый синдром указывает на какой-то поврежденный бит.
В общем, мне кажется всего этого не хватает в предложенной статье…
По второму пункту: да, синдром будет ненулевой. Но ведь он будет указывать на какой-то один бит. Как определить, что на самом деле была двукратная ошибка?
К сожалению, никак. Насколько я понимаю, это два разных способа использования кода хэмминга: либо мы в случае ненулевого синдрома бракуем сообщение (и тогда код гарантирует нам, что все 1- и 2- битовые ошибки будут отбракованы), либо мы молча исправляем бит, на который указывает синдром (и тогда даже в случае однобитовых ошибок мы получаем верное сообщение). Какой способ использования выбрать — зависит от поставленной цели и свойств канала/передаваемых данных.
Да нет, тут где-то подвох есть. Для обнаружения двухкратных ошибок хватит двух бит и суммы по модулю 4.
Да и везде пишут, что код Хемминга позволяет исправлять однократные и обнаруживать двукратные ошибки.
Да и везде пишут, что код Хемминга позволяет исправлять однократные и обнаруживать двукратные ошибки.
позволяет исправлять однократные и обнаруживать двукратные ошибки
Ну да. Для 2-битовой ошибки синдром ненулевой? — ненулевой. Ошибка обнаружена? — обнаружена. Там же не пишут, что он позволяет исправлять, обнаруживать и отличать случаи, когда можно исправлять, от случаев когда нельзя (: Для этого просто недостаточно избыточности этого кода. С другой стороны, добавление общего бита чётности решает эту проблему (см. www.sernam.ru/book_tec.php?id=85):
Расширенный код Хэмминга образуется из совершенного путем добавления общей проверки на четность, т. е. проверочного символа, равного сумме всех символов кода Хэмминга. Код имеет кодовое расстояние, что позволяет исправить все однократные и одновременно обнаружить все двукратные ошибки. Такой режим целесообразен, в частности, в системах передачи информации с обратной связью.
… кодовое расстояние d = 4, что позволяет…
Хм, действительно. Спасибо.
А я столько лет жил в уверености что код Хэмминга позволяет одновременно делать и то и другое :)
А я столько лет жил в уверености что код Хэмминга позволяет одновременно делать и то и другое :)
НЛО прилетело и опубликовало эту надпись здесь
@livsiusна самом деле это написано в конце комментария, на который вы отвечаете.
А нет, с двумя битами я поторопился, каюсь :/ Не выйдет так.
>К сожалению, никак. Насколько я понимаю, это два разных способа использования кода хэмминга:
Этот ответ неверный. Определить можно и совсем не трудно.
Кодовое множество (векторное пространство 128 слов) раскладывается в смежные (8) классы по группе кодовых слов (7,4)-кода. Принятое декодером слово лежит в одном из таких классов. Определяете класс и место в нем слова с ошибками. Сравниваете с кодовым словом и находите разность. Все это у Вас игнорируется. Вы не показали как строится (7,4)-код, какие он имеет свойства. Почему он так устроен? Мое мнение- писать надо о том в, чем разбираешься лучше других.
Этот ответ неверный. Определить можно и совсем не трудно.
Кодовое множество (векторное пространство 128 слов) раскладывается в смежные (8) классы по группе кодовых слов (7,4)-кода. Принятое декодером слово лежит в одном из таких классов. Определяете класс и место в нем слова с ошибками. Сравниваете с кодовым словом и находите разность. Все это у Вас игнорируется. Вы не показали как строится (7,4)-код, какие он имеет свойства. Почему он так устроен? Мое мнение- писать надо о том в, чем разбираешься лучше других.
Я не уверен, что вы VAE написали свой комментарий именно мне. Но если мне, то у меня есть два комментария к следующему:
Первый: традиционно на этом сайте люди пишут статьи и комментарии в процессе того, как они разбираются в предмете. Оборот «насколько я понимаю» в моём комментарии указывает, что это моё текущее представление, не обязательно на 100% верное.
Второй: вы, очевидно, лучше меня разбираетесь в кодах хэмминга. Не могли бы вы наглядно продемонстрировать, как одним алгоритмом исправить ошибку в одном бите и детектировать ошибку в двух битах в коде (7, 4)? Например, исходное сообщение: 0000 + 000, полученное сообщение: 0000 + 100 (1 бит) и исходное сообщение: 0000 + 000, полученное сообщение: 0000 + 110 (2 бита).
Мое мнение- писать надо о том в, чем разбираешься лучше других.
Первый: традиционно на этом сайте люди пишут статьи и комментарии в процессе того, как они разбираются в предмете. Оборот «насколько я понимаю» в моём комментарии указывает, что это моё текущее представление, не обязательно на 100% верное.
Второй: вы, очевидно, лучше меня разбираетесь в кодах хэмминга. Не могли бы вы наглядно продемонстрировать, как одним алгоритмом исправить ошибку в одном бите и детектировать ошибку в двух битах в коде (7, 4)? Например, исходное сообщение: 0000 + 000, полученное сообщение: 0000 + 100 (1 бит) и исходное сообщение: 0000 + 000, полученное сообщение: 0000 + 110 (2 бита).
На практике, обычно сообщение дополняется контрольной суммой (CRC), и если после коррекции контрольная сумма не сошлась, значит бракуем нафиг все сообщение.
Обычно, это там, где вероятность даже однобитовой ошибки шкалит ниже 10^(-9) (например, в азернете проводном) и цена потери одного пакета копеечная, либо его легко и быстро перезапросить можно. А если речь идёт о, например, хранении инфы (на том же НЖМД), или передачи в эфире, например, вы с вашим CRC быстро в трубу вылетете :(
Причём CRC — это же то же из семейства циклических кодов, к-рый, если сгенерирован по неприводимому полиному, в состоянии одну битовую ошибку исправлять (что, кстати, мало кто даже из спецов помнит). Тем более, что, по-большому счёту, вся теория помехоустойчивых кодов — это обощение понятия бита чётности. Так нафига мучатся с «недокодом», если несложным по нынешним временам (в смысле вычислит. или аппаратных нагрузок) «апгрейдом» и при сравнимой скорости кода можно получить полноценное исправление ошибки тем же Хэммингом?
Причём CRC — это же то же из семейства циклических кодов, к-рый, если сгенерирован по неприводимому полиному, в состоянии одну битовую ошибку исправлять (что, кстати, мало кто даже из спецов помнит). Тем более, что, по-большому счёту, вся теория помехоустойчивых кодов — это обощение понятия бита чётности. Так нафига мучатся с «недокодом», если несложным по нынешним временам (в смысле вычислит. или аппаратных нагрузок) «апгрейдом» и при сравнимой скорости кода можно получить полноценное исправление ошибки тем же Хэммингом?
а почему бы не привести реализацию алгоритма на c++ или java?
На С например так (использование, правда, не (21, 16) как в статье, а (38,32)):
#include <assert.h>
#include <string.h>
#include <stdint.h>
#include <limits.h>
int get_bit(const void *in, size_t n)
{
return (((const uint8_t*)in)[n / CHAR_BIT] & (1 << (n % CHAR_BIT))) != 0;
}
void set_bit(void *out, size_t n, int bit)
{
if (bit)
((uint8_t*)out)[n / CHAR_BIT] |= (1 << (n % CHAR_BIT));
else
((uint8_t*)out)[n / CHAR_BIT] &= ~(1 << (n % CHAR_BIT));
}
void flip_bit(void *out, size_t n)
{
((uint8_t*)out)[n / CHAR_BIT] ^= (1 << (n % CHAR_BIT));
}
size_t encode(void *out, const void *in, size_t in_bits)
{
size_t i, j, k;
unsigned s = 0;
for (i = j = 0; j < in_bits; ++i) {
if ((i + 1) & i) {
if (get_bit(in, j))
s ^= i + 1;
set_bit(out, i, get_bit(in, j));
++j;
}
}
for (k = 1; k < i; k <<= 1) {
set_bit(out, k - 1, s & k);
}
return i;
}
size_t decode(void *out, const void *in, size_t in_bits, unsigned *out_syndrome)
{
size_t i, j;
unsigned s = 0;
for (i = j = 0; i < in_bits; ++i) {
if (get_bit(in, i))
s ^= i + 1;
if ((i + 1) & i) {
set_bit(out, j, get_bit(in, i));
++j;
}
}
*out_syndrome = s;
return j;
}
size_t decode_and_fix(void *out, const void *in, size_t in_bits)
{
unsigned s;
size_t out_bits = decode(out, in, in_bits, &s);
if (s && s <= in_bits && (s & (s - 1))) {
unsigned k;
for (k = 0; 1u << k < s; ++k);
flip_bit(out, s - k - 1);
}
return out_bits;
}
int main()
{
char habr[4] = "habr";
char encoded[5];
char decoded[4];
unsigned s;
size_t i;
size_t encoded_bits = encode(encoded, habr, sizeof(habr) * CHAR_BIT);
size_t decoded_bits = decode(decoded, encoded, encoded_bits, &s);
assert(s == 0);
assert(encoded_bits == sizeof(habr) * CHAR_BIT + 6);
assert(decoded_bits == sizeof(habr) * CHAR_BIT);
assert(memcmp(habr, decoded, sizeof(habr)) == 0);
for (i = 0; i < encoded_bits; ++i) {
flip_bit(encoded, i);
decoded_bits = decode(decoded, encoded, encoded_bits, &s);
decoded_bits = decode_and_fix(decoded, encoded, encoded_bits);
assert(decoded_bits == sizeof(habr) * CHAR_BIT);
assert(memcmp(habr, decoded, sizeof(habr)) == 0);
flip_bit(encoded, i);
}
return 0;
}
Я когда на лекциях расказывал про код Хемминга, обычно использовал вот эти слайды:


Положим, есть сообщение A, а P дополнительные биты, тогда сумма всех битов по модулю 2 нe покажет нам есть ли другая ошибка?
Я конечно все понимаю, у вас 2й проверочный, НЕ ВЕРНЫЙ.
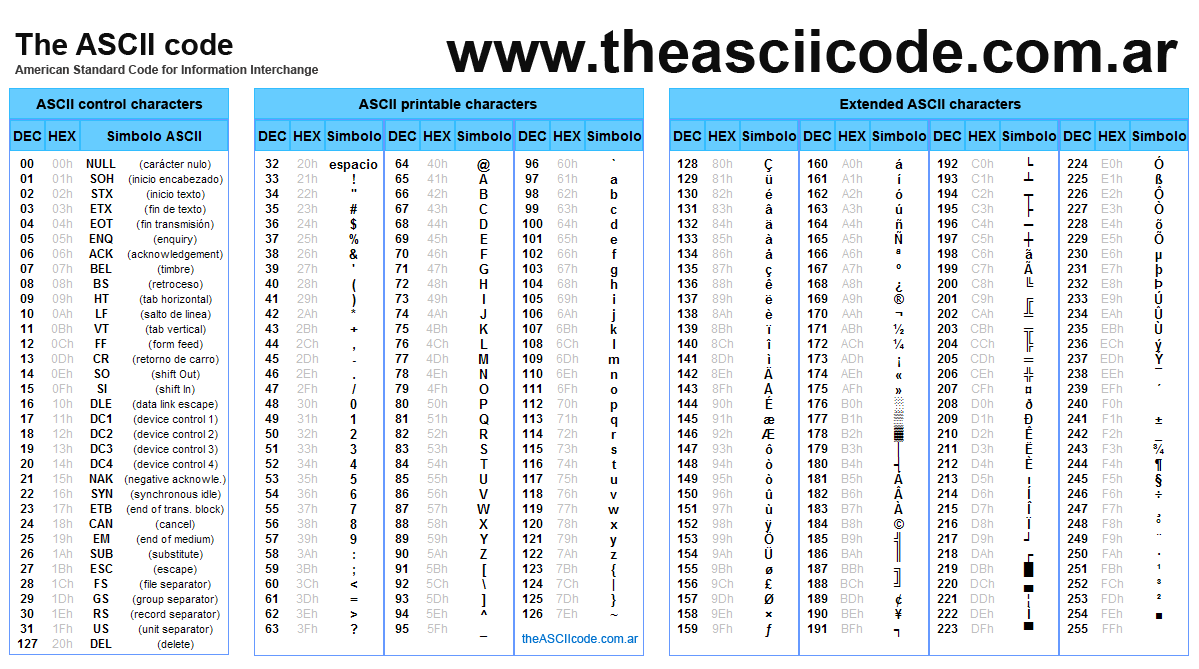
Мне кажется вы перепутали значения ascii кодов в первой табличке — указали hex значения, вместо dec.
h — 104
a — 97
b — 98
r — 114
Таблица
h — 104
a — 97
b — 98
r — 114
Таблица
{kind=link}
На самом деле, если бы я, в бытность свою преподавателем, так излагал теорию студентам, то они бы мало чего поняли. Проблема в том, что в большинстве источников, начинают с примера про контрольный бит чётности, а затем резко переходят к кодам Хэмминга. И у слушатлей возникает недоумение: «а связь-то какая?». Не кому не навязываю, но я обычно объясняю именно в стиле «давайте изобретём код Хэмминга — обобщение контрольной суммы». Вот есть бит чётности, но у него <известные> недостатки. А давайте попробуем ввести ещё один. Но как его вычислять, что бы…? Но два не достигают цели, поэтому давайте перейдём к коду (7,4). Ага, получилось! А теперь давайте проанализируем… И вот на таком пути студенты легко врубались что это и с чем.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Код Хэмминга. Пример работы алгоритма