Авторы позиционируют HyperDex как распределённое, отказоустойчивое, легко-маштабируемое, заточенное на очень быстрый поиск NoSQL key-value хранилище.
Главная фича — новый принцип хранения объектов в многомерном эвклидовом пространстве (рис. слева), используя гиперпространственное хэширование (hyperspace hashing) (на который, кстати, авторы сейчас получают патент), которое позволяет выполнять большинство типичных задач от 2 до 13 раз быстрее, чем в MongoDB, Redis, Cassandra.
О проекте
HyperDex появился в недрах факультета компьютерных наук Корнелльского Университета силами 3-х авторов.
Один из авторов заявил о проекте на Hacker News & Slashdot лишь вчера, 22 февраля.
Судя по сайту и описанию проекта — инфы пока ещё мало. Характер этого топика — вводный, я решил перевести вступительную инфу о проекте, доступную на их сайте и в документации. Если проект заинтересовал — советую ознакомиться с более подробным 15-ти страничным описанием (ссылка ниже)
Написан на C++; 39,750 LoC; Сорсы на гитхабе (лицензия 3-clause BSD license)
Сайт | Полное описание (PDF, 15 стр., англ.)
Мануал по установке (есть пакеты для Debian, Ubuntu, Fedora)
* Важно: HyperDex заводится только на x86_64 платформе.
В двух словах про гиперпространственное хэширование (hyperspace hashing)
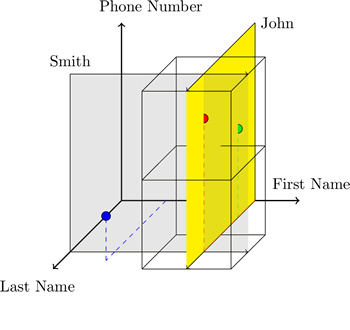
HyperDex представляет каждую таблицу в качестве независимого многомерного пространства, где оси — атрибуты таблицы. На примере 1-го рисунка, мы имеем таблицу, содержащую инфу о пользователе с атрибутами «First Name» (ось X), «Last Name» (Y) и «Phone Number» (Z). HyperDex присваивает каждому объекту соответствующие координаты на основе его атрибутов. Далее, объект мэпится к оным координатам методом хэширования каждого его атрибута по соответствующим осям.
В случае, когда атрибутов много, пространство разбивается на подпространства (subspaces)


Более подробная инфа по принципам хэширования, хранения на диске, а также шардингу и репликации — читайте в полном описании проекта.
Бенчмарки
Бенчмарки проводились тулзой YCSB (Yahoo! Cloud Serving Benchmark) на кластере из 14 нод (конфа каждой — 2х Intel Xeon 2.5 GHz E5420, 16 GB RAM, 500 GB SATA 3 Gbit 7200 RPM. 64-bit Debian 6 Linux 2.6.32 kernel)
MongoDB 2.0.0
Cassandra 0.7.3
UPD: Сейчас, спустя несколько суток после публикации на HN & Slashdot, видно что эти бенчмарки — основная тема дебатов, в которых участвуют авторы как самого проекта, так и Редиса (antirez) и другие спецы по сравниваемымм продуктам. Очевидно, что каждая БД лучше всего работает по своему фронту задач и «универсальные» бенчы не дают картины для объективного сравнения.
Описание нагрузочных сценариев на графиках (Workloads (англ.)):

- A. 50/50 чтение-запись (сессии, пара действий с бд)
- B. 95/5 чтение-запись
- C. Только чтение
- D. Добавление новых записей и чтение последних изменений
- E. Поиск
- F. Чтение объекта / изменение / запись обратно
 Вставка 10 000 000 объектов |
 Workload B. 95% чтение, 5% запись на 10К сценарных операций |
 Поиск. 10К сценарных операций. Важное замечание по этому бенчу: HyperDex ищет не по индексным (non-primary) атрибутам объектов, в то время как остальные — только по primary-key |
 Линейная маштабируемость. на 32-х нодах HyperDex обрабатывает 3.2 млн. операций в секунду |
 Сравнение с Redis. Workload E — поиск. Обсуждение этого бенча в рассылке Redis (agladysh) |
Обсуждение с одним из авторов (rescrv) на Hacker News | Slashdot








