Комментарии 31
Еще есть format у str и нужно вариант модуля на Си.
Такой вариант протестируйте пожалуйста: gist.github.com/1685623
Спасибо за вариант! :)
Протестировал.
100 символов: 0.085 секунд
1000 символов: 0.752 секунд
10000 символов: 7.321 секунд
Тест точно такой же — время выполнения 500 одинаковых операций.
Поскольку ваш вариант оказался самым крутым при обработке 100 символов — решил ради интереса сравнить его с первым вариантом на очень маленькой строке («Юный химик» — 10 символов).
Но тут первый вариант всё же оказался быстрее — всего 0.001 секунд. Ваш вариант занял 0.016 секунд.
Протестировал.
100 символов: 0.085 секунд
1000 символов: 0.752 секунд
10000 символов: 7.321 секунд
Тест точно такой же — время выполнения 500 одинаковых операций.
Поскольку ваш вариант оказался самым крутым при обработке 100 символов — решил ради интереса сравнить его с первым вариантом на очень маленькой строке («Юный химик» — 10 символов).
Но тут первый вариант всё же оказался быстрее — всего 0.001 секунд. Ваш вариант занял 0.016 секунд.
Сохранение регистра букв надо, только если вы потом захотите обратно преобразовать транслит в кирилицу. Но при этом вы наступите еще на пару граблей, потому что, опять-таки, преобразование не 1 к 1.
А в остальных 99.99% случаев транслитерация букв нужна для получения ascii-идентификаторов. Ключей в базе, урлов (тут сомнительно, потому что нормальный юникод давно везде работает). А исходя из сути идентификаторов — нам начхать на регистр. Более того, в половине из этих случаев стоит приводить все к одному регистру, потому что есть еще подводные камни, связанные с сортировкой (двоичной, а не символьной).
А в остальных 99.99% случаев транслитерация букв нужна для получения ascii-идентификаторов. Ключей в базе, урлов (тут сомнительно, потому что нормальный юникод давно везде работает). А исходя из сути идентификаторов — нам начхать на регистр. Более того, в половине из этих случаев стоит приводить все к одному регистру, потому что есть еще подводные камни, связанные с сортировкой (двоичной, а не символьной).
Есть ещё одно применение — преобразование текста (названий и прочего) в латиницу с целью обеспечить возможность чтения нерусскоговорящими людьми.
Разумеется, прочитают они это всё равно не вполне корректно, но вот отсутствие подобного прыгающего регистра в транслитерации (там, где реально было обычное слово с большой буквы или слово целиком в верхнем регистре) может помочь чтению.
Разумеется, прочитают они это всё равно не вполне корректно, но вот отсутствие подобного прыгающего регистра в транслитерации (там, где реально было обычное слово с большой буквы или слово целиком в верхнем регистре) может помочь чтению.
А такое бывает? По-моему, изучение любого языка начинается с алфавита.
Ну, разве что таблички в туристических местах, с текстами типа «Tsentralnaya ploschad». Но оно вырвиглазное по своей сути (кто им мешает нормально перевести название? нигде такого бреда не встречал, кроме как в бывшем союзе), во первых, во вторых, тут нет объемов (если уж бенчмарки затеяли, значит объемы принципиальные), в третьих — ручная правка текста будет все-равно.
Ну, разве что таблички в туристических местах, с текстами типа «Tsentralnaya ploschad». Но оно вырвиглазное по своей сути (кто им мешает нормально перевести название? нигде такого бреда не встречал, кроме как в бывшем союзе), во первых, во вторых, тут нет объемов (если уж бенчмарки затеяли, значит объемы принципиальные), в третьих — ручная правка текста будет все-равно.
Ну, как сказать.
Если даже вы, не зная русского, спросите:
Excuse me, where is the Tsentralnaya ploschad?
То вам, скорее всего, покажут пальцем, куда идти.
А вот если вы спросите:
Where is the Central Square?
То велика вероятность, что тот, у кого вы будете спрашивать, не поймёт вообще ничего. Можете даже проэкспериментировать как-нибудь ради интереса. Незнание английского языка — совершенно типичное явление в любой неанглоговорящей стране. Тут, в общем-то, нечему удивляться. По этой причине транслит во многих случаях лучше, чем перевод. Иногда, кстати, встречается и то, и другое рядом, когда название дублируется в транслите и в переводе.
Если даже вы, не зная русского, спросите:
Excuse me, where is the Tsentralnaya ploschad?
То вам, скорее всего, покажут пальцем, куда идти.
А вот если вы спросите:
Where is the Central Square?
То велика вероятность, что тот, у кого вы будете спрашивать, не поймёт вообще ничего. Можете даже проэкспериментировать как-нибудь ради интереса. Незнание английского языка — совершенно типичное явление в любой неанглоговорящей стране. Тут, в общем-то, нечему удивляться. По этой причине транслит во многих случаях лучше, чем перевод. Иногда, кстати, встречается и то, и другое рядом, когда название дублируется в транслите и в переводе.
А между собой они будут «what the fuck is tsentralnaya ploschad?». И будут искать какой-нить памятник, скамейку, бабУшку, в конце концов, но так и не узнают, что это всего лишь central square.
> Можете даже проэкспериментировать как-нибудь ради интереса.
Сталкивался. Не понимают точно так же, как и «where is central square?».
> Незнание английского языка — совершенно типичное явление в любой неанглоговорящей стране.
Бывший союз, скорее. В остальном мире как-то с этим по-лучше.
> Можете даже проэкспериментировать как-нибудь ради интереса.
Сталкивался. Не понимают точно так же, как и «where is central square?».
> Незнание английского языка — совершенно типичное явление в любой неанглоговорящей стране.
Бывший союз, скорее. В остальном мире как-то с этим по-лучше.
В Испании тоже основные массы плохо знают английский. Впрочем, говорят, и англичан они сильно не любят.
> А между собой они будут «what the fuck is
Чем-то напоминает Задорнова «ну тупыеее». Правда это мало соотносится с действительностью: англоговорящие не испытывают таких проблем с иностранными названиями, как Вы хотите это преподнести, для них вполне нормальны подобные вкрапления иностранных названий
Что также добавляет и своеобразный шарм экзотики — каждая страна звучит по своему, а не везде одинаковые названия, как было бы, если б всё переводилось. Разумеется, узнать перевод, как в примере, — тоже интересно, но этого достаточно один раз.
Чем-то напоминает Задорнова «ну тупыеее». Правда это мало соотносится с действительностью: англоговорящие не испытывают таких проблем с иностранными названиями, как Вы хотите это преподнести, для них вполне нормальны подобные вкрапления иностранных названий
«Notre Dame Cathedral (full name: Cathédrale Notre-Dame de Paris, „Our Lady of Paris“) is a beautiful cathedral on the the Île de la Cité in Paris»
Что также добавляет и своеобразный шарм экзотики — каждая страна звучит по своему, а не везде одинаковые названия, как было бы, если б всё переводилось. Разумеется, узнать перевод, как в примере, — тоже интересно, но этого достаточно один раз.
Если вам нужно заменить символы одного алфавита на соответствующие им символы другого алфавита. можно обойтись и без циклов, и без регулярок. Есть же string.translate и его верный друг string.maketrans.
Для замен, в которых участвую строки длиннее одного символа все-так понадобится цикл. Но таких замен сильно меньше односимвольных.
Для замен, в которых участвую строки длиннее одного символа все-так понадобится цикл. Но таких замен сильно меньше односимвольных.
А вообще, если вы так гонитесь за скоростью, перепишите первый вариант на sed, по скорости это решение порвет 99% других (на любом языке), а по соотношению (скорость) / (скорость разработки) — так и все 100%.
Neuželi tak složno ne translitizirovat' kirillicu, a romanizirovat' jejo v samuju obyčnuju latinicu s diakritikoj? Eto že tak prosto!
А почему у вас 'ю' транслитерировалось в 'ju', 'е' в 'je' и 'ё' в 'jo', если это так просто? :)
Даже в вашем примере есть «je» и «jo» — то есть опять же, некоторые буквы транслитерируются (романизируются) не в одну, а в несколько латинских букв.
Таблицу транслитерации (романизации) можно отредактировать как угодно — суть в том, что алгоритм, по которому происходит обработка строки, может учитывать регистр следующего символа, и оставлять слово, написанное целиком прописными буквами, в верхнем регистре, а в слове с заглавной буквы оставлять одну заглавную букву.
Можно было бы, конечно, добиться и того, чтобы любая буква была представлена как одна латинская (с добавлением диакритических знаков или в виде лигатур), но в итоге тем, кто это читает, пришлось бы выучить правила чтения этих символов. А если уж учить новые символы, то там и до того, чтобы просто выучить кириллицу, недалеко.
Таблицу транслитерации (романизации) можно отредактировать как угодно — суть в том, что алгоритм, по которому происходит обработка строки, может учитывать регистр следующего символа, и оставлять слово, написанное целиком прописными буквами, в верхнем регистре, а в слове с заглавной буквы оставлять одну заглавную букву.
Можно было бы, конечно, добиться и того, чтобы любая буква была представлена как одна латинская (с добавлением диакритических знаков или в виде лигатур), но в итоге тем, кто это читает, пришлось бы выучить правила чтения этих символов. А если уж учить новые символы, то там и до того, чтобы просто выучить кириллицу, недалеко.
Напишите-ка мне букву «щ»? :)
В ASCII не поместится.
Хм, Neu%C5%BEeli%20tak%20slo%C5%BEno?
100мс как-то много для строки из одного символа.
Это время выполнения функции уже в стартоаввшей программы весь запуск программы?
Это время выполнения функции уже в стартоаввшей программы весь запуск программы?
Вы правы. Сейчас перепроверил — получилось всё-таки 0.01 (это вся программа — в данном случае ещё и с выводом результата на экран все 500 раз).
2526 function calls in 0.010 CPU seconds
Из этого функиця transliterate:
test.py:3(transliterate)
ncalls: 500
tottime: 0.006
percall: 0.000
cumtime: 0.006
percall: 0.000
2526 function calls in 0.010 CPU seconds
Из этого функиця transliterate:
test.py:3(transliterate)
ncalls: 500
tottime: 0.006
percall: 0.000
cumtime: 0.006
percall: 0.000
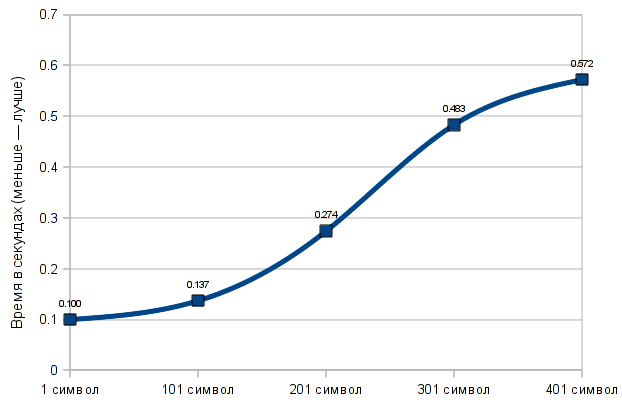{kind=link}
Кстати, если сравнить два графика, то видно, что у них отличаются и другие значения. Это связано с тем, что использовались разные шаблоны строк. То есть скопированная n раз последовательность символов «Шахматы» обрабатывается за одно время, а последовательность «Юный химик», с помощью которой была получена строка той же длины, обрабатывается за другое время.
Помню писал такую утилиту, чтобы русские названия треков в плеере крякозяброй не высвечивались. Заморочки с заглавными буквами мне и в голову тогда не пришли, потому и программа была не сложнее «Hello world».
Частично справляется вот эта мегауниверсальная штука:
>>> import unidecode
>>> unidecode.unidecode(u'ШШШ Щячло')
'ShShSh Shchiachlo'
Посмотри вот на это: pypi.python.org/pypi/trans
Давно я его написал… На скорость не ориентировался, но это реально надо?
Давно я его написал… На скорость не ориентировался, но это реально надо?
Я бы плюсанул, но кармы нет, поэтому просто спасибо. Именно сегодня этот пост сэкономил мне много нервов.
А вы смотрели unidecode? У меня правда был другой критерий отбора, чтобы переводила в транслит любой набор символов на любом языке.
На момент написания статьи — не смотрел, конечно: библиотека на PyPI с 20 сентября 2013, а эта статья опубликована 27 января 2012.
Сейчас посмотрел. В текущей версии у неё та же самая проблема с заглавными буквами, что и у почти всех других реализаций, которые можно найти в Интернете:
А в остальном — хорошая библиотека. Для создавния slug (которые всё равно переводятся в нижний регистр) самое то.
Сейчас посмотрел. В текущей версии у неё та же самая проблема с заглавными буквами, что и у почти всех других реализаций, которые можно найти в Интернете:
>>> unidecode(u"США")
'SShA'
А в остальном — хорошая библиотека. Для создавния slug (которые всё равно переводятся в нижний регистр) самое то.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Обычная (или не совсем обычная) транслитерация на Python