
SqlBulkCopy — это эффективное решение для массовой загрузки данных в таблицы Microsoft SQL Server. Источник данных может быть любой, будь то xml-файл, csv-файл или другая СУБД, например MySQL. Достаточно получить из источника данные в виде объекта DataTable или реализовать интерфейс IDataReader поверх методов доступа к данным.
Вам не придется создавать файлы на диске для дальнейшей их загрузки с помощью утилиты BCP, вам не придется писать код для генерации множественных INSERT запросов. При загрузке данных SqlBulkCopy работает на более низком уровне, позволяя вставлять миллионы записей за максимально короткий срок.
Проблема
Все хорошо, SqlBulkCopy настолько быстрый и безбашенный, что игнорирует любые триггеры, внешние ключи и прочие ограничения и события при вставке данных (при желании можно включить). Он так же умеет вставлять данные транзакциями по несколько блоков.
Но SqlBulkCopy не умеет обрабатывать исключения, возникающие при импорте данных. Если возникнет хотя бы одна ошибка (дублирование ключей, недопустимость NULL значений, невозможность приведения типов), то он быстро закончит работу, так ничего и не добавив.
Мы рассмотрим две задачи и их решения:
1) Как использовать SqlBulkCopy с произвольным источником данных.
2) Как избежать исключений, возникающих при работе с SqlBulkCopy.
С чего начать?
// Создаем ридер IDateReader для источника, с которым хотим работать. Его создание рассмотрим ниже.
var reader = GetReader();
var connectionString = @"Server={сервер};initial catalog={база данных};Integrated Security=true";
// Создаем объект SqlBulkCopy, указываем таблицу назначения и загружаем.
using (var loader = new System.Data.SqlClient.SqlBulkCopy(connectionString))
{
loader.DestinationTableName = "Persons";
loader.WriteToServer(reader);
}
Помимо свойства DestinationTableName объект класса SqlBulkCopy имеет так же важное свойство BatchSize (число строк, загружаемых за раз на сервер, по умолчанию — равно 0 и все данные загружаются одним пакетом), подробнее о нем читайте здесь.
Так же вторым параметром конструктор SqlBulkCopy может принимает переменную типа SqlBulkCopyOptions, обратите на это внимание, если вам нужно включить триггеры, ограничения или форсировать NULL значениям при вставке. По умолчанию ничего этого нет. Подробнее о возможных значениях этого параметра читайте здесь.
Реализация интерфейса IDataReader
Теперь рассмотрим более практичный пример того, как реализовать интерфейс IDataReader для произвольного источника данных. В нашем примере в качестве источника данных будет выступать csv файл. Наша задача скопировать данные из него в таблицу SQL Server.
Мы будем импортировать клиентов (customers) из файла csv, поэтому наша таблица в SQL Server выглядит так:
Структура таблицы Customers на языке T-SQL.
CREATE TABLE [Customers](
[ID] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [nvarchar](50) NOT NULL,
[SecondName] [nvarchar](50) NOT NULL,
[Birthday] [smalldatetime] NULL,
[PromoCode] [int] NULL
) ON [PRIMARY]
Наш csv файл выглядит примерно так:
Петрович;Николай;04.10.1974;65125
Михалков;Никита;12.12.1962;54671
Иванов;Иван;не указана;
Дмитриус;;10.12.1981;4FS2FGAТеперь окончательно ясно, что при импорте данных нам придется решать следующие проблемы:
- Обеспечить корректный маппинг данных. Так, например, фамилия в CSV документе указана первой, в отличие от таблицы SQL Server. Так же в csv данных отсутствует значение для ID, которое является первичным автоматически обновляемым ключом.
- Привести данные к формату SQL Server и осуществить обработку некорректных записей. Посмотрите на последнюю строку csv документа, она не содержит имени, в то время как в SQL таблице это поле обязательно, или на значение «не указана» в третье строке, которое, никак не привести к типу smalldatetime.
Как работает SqlBulkCopy
- Соединяется с базой данных SQL Server и запрашивает метаданные указанной таблицы.
- Получает количество столбцов с помощью свойства FieldCount интерфейса IDadaReader.
- Рассчитывает откуда куда будет загружать (из какого столбца источника данных в какой столбец таблицы SQL Server).
- Вызывает метод Read() и последовательно получает значения в виде object с помощью метода GetValue(int i) — опять же интерфейса IDadaReader.
- Вызывает один из методов конвертирования, например Convert.ToInt32(object value), Convert.ToDateTime(object) и так далее. Какой метод вызвать — SqlBulkCopy определят по метаданным таблицы. Тип данных источника его совершенно не интересует, если метод конвертирования выдаст исключение, то загрузка прервется.
Таким образом, если данные, которые вы хотите импортировать далеки от идеала (как в нашем примере), вам придется проделать немного больше работы, чтобы загрузить хотя бы часть данных, которые корректны.
За работу!
Реализовать интерфейс IDataReader для SqlBulkCopy довольно просто, необходимо реализовать всего 3 метода и одно свойство, остальные попросту не нужны, так как не вызываются объектом SqlBulkCopy. И так это:
public int FieldCount
Возвращает количество столбцов в источнике данных (csv-файле). Вызывается первым, до вызова Read().
public bool Read()
Читает очередную строку. Возвращает true — если конец файла/источника не достигнут, иначе false.
public object GetValue(int i)
Возвращает значение с указанным индексом для текущей строки. Вызывается всегда после метода Read().
public void Dispose()
Освобождение ресурсов, SqlBulkCopy не вызывает этот метод, но всегда пригодится.
Простая реализация класса для чтения csv файлов, поддерживающего интерфейс IDataReader.
using System.Data;
using System.IO;
namespace SqlBulkCopyExample
{
public class CSVReader : IDataReader
{
readonly StreamReader _streamReader;
readonly Func<string, object>[] _convertTable;
readonly Func<string, bool>[] _constraintsTable;
string[] _currentLineValues;
string _currentLine;
// Конструктор ридера CSV-файла.
// Передаем полный абсолютный путь к файлу, таблицы функций ограничений и преобразований.
// (о функциях ограничения и преобразования - читайте ниже, в пояснении).
public CSVReader(string filepath, Func<string, bool>[] constraintsTable, Func<string, object>[] convertTable)
{
_constraintsTable = constraintsTable;
_convertTable = convertTable;
_streamReader = new StreamReader(filepath);
_currentLine = null;
_currentLineValues = null;
}
// Возвращаем значение, используя одну из функций преобразования и обработку исключения.
// Это обезопасит нас от прерывания загрузки данных.
public object GetValue(int i)
{
try
{
return _convertTable[i](_currentLineValues[i]);
}
catch (Exception)
{
return null;
}
}
// Чтение очередной строки.
// Используем функции ограничения для того, чтобы еще на этапе чтения понять, что строка
// вызовет исключения при передаче ее в SqlBulkCopy, поэтому мы пропускаем некорректные строки.
public bool Read()
{
if (_streamReader.EndOfStream) return false;
_currentLine = _streamReader.ReadLine();
// В случае, если значения будут содержать символ ";" это работать не будет,
// и придется использовать более сложный алгоритм разбора.
_currentLineValues = _currentLine.Split(';');
var invalidRow = false;
for (int i = 0; i < _currentLineValues.Length; i++)
{
if (!_constraintsTable[i](_currentLineValues[i]))
{
invalidRow = true;
break;
}
}
return !invalidRow || Read();
}
// Возвращем число столбцов в csv файле.
// Нам заранее известно, что 4, поэтому не будем усложнять код.
public int FieldCount
{
get { return 4; }
}
// Освобождаем ресурсы. Закрываем поток.
public void Dispose()
{
_streamReader.Close();
}
// ... множестве нереализованных методов IDataReader, которые здесь не нужны.
}
}
Таблица ограничений constraintsTable
Вторым параметром constraintsTable в конструктор мы передали массив ссылок на методы, которые используются для того, чтобы заранее быстро определить сможет ли SqlBulkCopy корректно обработать запись или нет. Каждый метод принимает значение соответствующего столбца и выдает заключение true или false. Если хотя бы один из методов возвращает false, строка пропускается. Рассмотрим как создать массив подобных функций.
var constraintsTable = new Func<string, bool>[4];
constraintsTable[0] = x => !string.IsNullOrEmpty(x);
constraintsTable[1] = constraintsTable[0];
constraintsTable[2] = x => true;
constraintsTable[3] = x => true;У нас четыре столбца, поэтому и четыре метода. Мы задаем их через лямбда-выражения, так удобнее. Первый метод проверяет допустима ли фамилия (не должна быть пустой или являться NULL), второй делает тоже самое. Вспомните схему нашей таблицы в SQl Server, имя и фамилия не могут быть равны NULL. Остальные методы всегда возвращают true, так как это необязательные поля.
Примечание. Вы можете избежать использования таблиц ограничений, в вместо этого сделайте все столбцы в таблице SQL Server способными хранить NULL значения. Это сделает вставку данных быстрее.
Таблица преобразования convertTable
Третьим параметром convertTable в конструктор мы передали массив ссылок на методы, которые используются для преобразования значений, полученных из csv в те, которые понимает SQL Server. В нашем случае эту же работу может сделать сам SqlBulkCopy, но он не обрабатывает исключения и не сможет вставить NULL значение, если преобразование не удалось. Мы облегчим ему работу.
var convertTable = new Func<object, object>[4];
// Функция преобразования первого столбца csv файла (фамилия)
convertTable[0] = x => x;
// Второго (имя)
convertTable[1] = x => x;
// Третьего (дата)
// Разбираем строковое представление даты по определенному формату.
convertTable[2] = x =>
{
DateTime datetime;
if (DateTime.TryParseExact(x.ToString(), "dd.MM.yyyy", CultureInfo.InvariantCulture,
DateTimeStyles.None, out datetime))
{
return datetime;
}
return null;
};
// Четвертого (промо код)
convertTable[3] = x => Convert.ToInt32(x);
Фамилия и имя не нуждаются в каком-либо преобразовании. Они и так являются строковыми значениями и их корректность проверяется в таблицах ограничений. Дату и число мы пробуем преобразовать. Если возникнет исключение, то оно будет перехвачено в методе GetValue().
Маппинг данных
Осталась одна деталь. По умолчанию SqlBulkInsert будет вставлять данные как есть, то есть из первого столбца источника в первый столбцев таблицы SQL Server. Нам такое поведение не нужно, поэтому мы используем свойство ColumnMappings для того, чтобы задать порядок вставки.
// Первый столбец csv файла в третий таблицы SQL Server и так далее.
// Нумерация начинается с нуля.
loader.ColumnMappings.Add(0, 2);
loader.ColumnMappings.Add(1, 1);
loader.ColumnMappings.Add(2, 3);
loader.ColumnMappings.Add(3, 4);Посмотрим теперь, как полностью будет выглядеть вызов нашей программы.
using System;
using System.Data;
using System.Data.SqlClient;
using System.Globalization;
namespace SqlBulkCopyExample
{
class Program
{
static void Main(string[] args)
{
// Создаем ридер для источника, с которым ходим работать.
var reader = GetReader();
// Строка подключения.
var connectionString = @"Server={сервер};initial catalog={база данных};Integrated Security=true";
// Создаем объект загрузчика SqlBulkCopy, указываем таблицу назначения и загружаем.
using (var loader = new SqlBulkCopy(connectionString, SqlBulkCopyOptions.Default))
{
loader.ColumnMappings.Add(0, 2);
loader.ColumnMappings.Add(1, 1);
loader.ColumnMappings.Add(2, 3);
loader.ColumnMappings.Add(3, 4);
loader.DestinationTableName = "Customers";
loader.WriteToServer(reader);
Console.WriteLine("Загрузили!");
}
Console.ReadLine();
}
static IDataReader GetReader()
{
var sourceFilepath = AppDomain.CurrentDomain.BaseDirectory + "sqlbulktest.csv";
var convertTable = GetConvertTable();
var constraintsTable = GetConstraintsTable();
var reader = new CSVReader(sourceFilepath, constraintsTable, convertTable);
return reader;
}
static Func<string, bool>[] GetConstraintsTable()
{
var constraintsTable = new Func<string, bool>[4];
constraintsTable[0] = x => !string.IsNullOrEmpty(x);
constraintsTable[1] = constraintsTable[0];
constraintsTable[2] = x => true;
constraintsTable[3] = x => true;
return constraintsTable;
}
static Func<string, object>[] GetConvertTable()
{
var convertTable = new Func<object, object>[4];
// Функция преобразования первого столбца csv файла (фамилия)
convertTable[0] = x => x;
// Второго (имя)
convertTable[1] = x => x;
// Третьего (дата)
// Разбираем строковое представление даты по определенному формату.
convertTable[2] = x =>
{
DateTime datetime;
if (DateTime.TryParseExact(x.ToString(), "dd.MM.yyyy", CultureInfo.InvariantCulture,
DateTimeStyles.None, out datetime))
{
return datetime;
}
return null;
};
// Четвертого (промо код)
convertTable[3] = x => Convert.ToInt32(x);
return convertTable;
}
}
}В итоге в нашей таблице Customers мы получили такой результат:
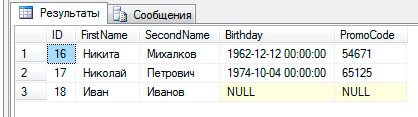
Некорректная запись не была добавлена, а значения, которые невозможно было привести к необходимому типа, были вставлены как NULL.
Заключение
Мы рассмотрели как программным путем с помощью SqlBulkCopy можно быстро вставить данные в таблицу SQL Server на примере csv-файла, реализовав для него декоратор с интерфейсом IDataReader, который обрабатывает проблемы, возникающие при вставке данных. В реальный задачах количество данных безусловно больше, но и в этих случаях SqlBulkCopy будет работать так же хорошо.
Дополнительные материалы
Узнайте о рекомендациях Microsoft по загрузке больших объемов данных от Microsoft.
Полный код одним списком вы можете посмотреть здесь.








