Комментарии 58
А почему нет никаких настроек? Например, было бы не плохо реализовать работу через прокси-сервер (копоративный).
Данный функционал будет настроен одновременно с авторизацией пользователей.
А еще хотелось бы иметь возможность в настройках указать — все новые или только захабренные. Сейчас, как я понимаю, только захабренные? А я люблю просматривать все новые.
Сейчас отображаются именно новые, со страницы habrahabr.ru/blogs/new/, а уже в настройках сделаю фильтрацию.
> — Использование БД.
На клиенте?
На клиенте?
Да, на клиенте для хранения различных данных. Пока ведутся работы по использованию sqlite, поскольку это библиотека и не является отдельно работающим процессом.
Рекомендую передумать.
Аргументация:
1. Если вы намерены качать все и хранить локально у клиента — на вас обидется хабр, канал забъете. Вплоть до того, что хабр может посчитать это за DDoS (если много народу установит приложение), и забанит всех своих пользователей)). Нужно будет использовать прокси своего изготовления, что стоит времени и денег, и, вероятно, менее надежно, чем сам хабр.
2. Если нужно хранить только заголовки и мета-информацию — все прекрасно влезит в ОП (и жрать не много будет, главное чистить нормально).
3. В любом случае, трогать файловую систему пользователя — некрасиво, для мини-приложения.
P. S. А как-же IM?
Аргументация:
1. Если вы намерены качать все и хранить локально у клиента — на вас обидется хабр, канал забъете. Вплоть до того, что хабр может посчитать это за DDoS (если много народу установит приложение), и забанит всех своих пользователей)). Нужно будет использовать прокси своего изготовления, что стоит времени и денег, и, вероятно, менее надежно, чем сам хабр.
2. Если нужно хранить только заголовки и мета-информацию — все прекрасно влезит в ОП (и жрать не много будет, главное чистить нормально).
3. В любом случае, трогать файловую систему пользователя — некрасиво, для мини-приложения.
P. S. А как-же IM?
1) Программа для того, чтоб сократить количество запросов к хабре, т.е. экономить время клиентов и не делать бессмысленные запросы к хабре.
2) Необходимо хранить только издержки данных, для того, чтоб человек мог получать более точные данные об обновлениях + для реализации оффлайт мониторинга, т.е. человек неделю не входил на хабру, включил информер, а ему все за неделю отобразились обновления(конечно можно будет настроить фильтр, чтоб не создавать помойку).
3) Не трогать файловую систему, из за пункта 2 не выйдет.
4) IM пока еще ничего не распланировано, как и что сделать, да и если горит информер в трее, для чего вещать на IM?
2) Необходимо хранить только издержки данных, для того, чтоб человек мог получать более точные данные об обновлениях + для реализации оффлайт мониторинга, т.е. человек неделю не входил на хабру, включил информер, а ему все за неделю отобразились обновления(конечно можно будет настроить фильтр, чтоб не создавать помойку).
3) Не трогать файловую систему, из за пункта 2 не выйдет.
4) IM пока еще ничего не распланировано, как и что сделать, да и если горит информер в трее, для чего вещать на IM?
> Программа для того, чтоб сократить количество запросов к хабре, т.е. экономить время клиентов и > не делать бессмысленные запросы к хабре.
Простите, не поверил — проверил. Программа стягивает 3 страницы, каждую минуту. Пользователи так не делают. Ваша программа делает 4230 запросов в день, обычный пользователь — не больше 100. То бишь, вы таки обижаете канал хабру.
По поводу, офлайн — пожалуйста, подробней. Как вы собираетесь это делать, поделитесь алгоритмом.
IM для того, чтобы в трее не было 100-500 информеров, чтобы все могли пользоватся, а не только те, кто умеют компилировать…
А теперь по поводу исходников:
1. QNetworkAccessManager должен быть один на все приложение.
2. MainWindow должен только отрисовкой заниматься, а не треем и сетью. Следите за ООП.
3. Реализуйте динамический массив нужных страниц, и циклом обрабатывайте Статьи, QA, Песочница… что-то еще появится…
Простите, не поверил — проверил. Программа стягивает 3 страницы, каждую минуту. Пользователи так не делают. Ваша программа делает 4230 запросов в день, обычный пользователь — не больше 100. То бишь, вы таки обижаете канал хабру.
По поводу, офлайн — пожалуйста, подробней. Как вы собираетесь это делать, поделитесь алгоритмом.
IM для того, чтобы в трее не было 100-500 информеров, чтобы все могли пользоватся, а не только те, кто умеют компилировать…
А теперь по поводу исходников:
1. QNetworkAccessManager должен быть один на все приложение.
2. MainWindow должен только отрисовкой заниматься, а не треем и сетью. Следите за ООП.
3. Реализуйте динамический массив нужных страниц, и циклом обрабатывайте Статьи, QA, Песочница… что-то еще появится…
1) Не будем вдаваться сколько запросов делается и выводить другие исчисления, но есть люди, которым удобно не самим обновлять страницы, наверняка не зная есть ли там вообще обновления, а посещать сайт именно когда действительно появляются обновления. Поэтому для таких не важно количество запросов и я сомневаюсь, что всем поголовно нужен информер.
2) Пользоваться могут не только те кто умеют компилировать — несколько распространенных версий выложены. А для использования IM — я просто не знаю пока правильной реализации, для IM лучше делать нечто в виде сервиса, который будет рассылать сообщения, а не качать программу и запускать в трее. Да и опять не всем это нужно будет, как и сам информер.
3) Технически вопросы приму во внимание и исправлю.
4) Оффлайн — имеется в виду, буду после долговременного отключения сканировать страницы на наличие новых статей, чтоб узнать новая или нет — обращаемся к локальной базе.
5) Полностью обрабатывать все пока не вариант и тут действительно понадобится одобрение хабры. Но в будущем все, что будет предложено на мониторинг — все постараюсь реализовать, пока из за отсутствия глобальных предложений исхожу от того, что нужно лично мне.
2) Пользоваться могут не только те кто умеют компилировать — несколько распространенных версий выложены. А для использования IM — я просто не знаю пока правильной реализации, для IM лучше делать нечто в виде сервиса, который будет рассылать сообщения, а не качать программу и запускать в трее. Да и опять не всем это нужно будет, как и сам информер.
3) Технически вопросы приму во внимание и исправлю.
4) Оффлайн — имеется в виду, буду после долговременного отключения сканировать страницы на наличие новых статей, чтоб узнать новая или нет — обращаемся к локальной базе.
5) Полностью обрабатывать все пока не вариант и тут действительно понадобится одобрение хабры. Но в будущем все, что будет предложено на мониторинг — все постараюсь реализовать, пока из за отсутствия глобальных предложений исхожу от того, что нужно лично мне.
По пункту 2) Почему на чём вы пишите нет аналога как в java класса Properties? Ну или любого другово key/value встроенного хранилища — pList как в iOS, или банальный xml? По идее всё что нужно, это хранить дату последней загруженной статьи из каждой категории, которою мониторите. От неё уже отталкиватся что подгружать дальше или если дата последнего загруженно поста больше 3дней, берём статьи за сегодня.
Build for OS X 10.6+
Проверял на 10.6.8 и 10.7.1
Проверял на 10.6.8 и 10.7.1
Есть, правда, пара моментов:
- Иконка приложения в доке стандартная
- При щелчке по иконке в трее окно скрывается/отображается, однако при этом также открывается контекстное меню
При закрытии окна через «крестик» приложение остается в доке, но повторно не открывается. Закрыть можно только через меню сверху или док. А за работу спасибо, буду пользоваться
Иконка несколько подкачала. Не очень выразительная, на современном таскбаре смотрится чужеродно.
Можно безвозмездно редактировать содержимое со всеми вытекающими:

Вы что, свою программу совсем не тестировали? Я понимаю, можно не заметить баг, вылезающий в ночь с 29 февраля на 1 марта, но не заметить такое…
Из пожеланий:
— Настройка времени обновления
— Настройка отображения (размер шрифта, цвет)
— Всплывающие уведомления (с возможностью отключения)
Не знаю, с помощью чего у вас сейчас организовано отображение, но советую попробовать QListView.


Вы что, свою программу совсем не тестировали? Я понимаю, можно не заметить баг, вылезающий в ночь с 29 февраля на 1 марта, но не заметить такое…
Из пожеланий:
— Настройка времени обновления
— Настройка отображения (размер шрифта, цвет)
— Всплывающие уведомления (с возможностью отключения)
Не знаю, с помощью чего у вас сейчас организовано отображение, но советую попробовать QListView.
1) Подробней после чего такие тесты и на чем тестировалось?
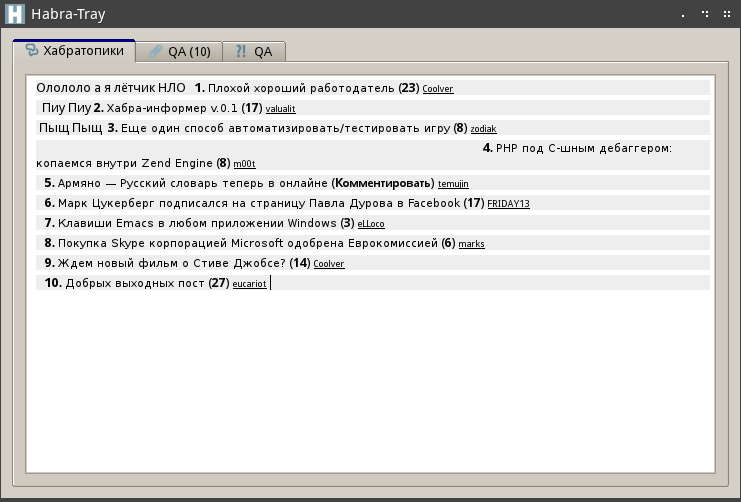
2) «Ололо а я летчик НЛО» и т.д. каким образом у Вас там очутились? Посмотрите на исходный код.
Как?
2) «Ололо а я летчик НЛО» и т.д. каким образом у Вас там очутились? Посмотрите на исходный код.
templatehtml["template"]=QString::fromUtf8("<div class=\"brd\"> <b>%5</b>. <a href=\"%1\" style=\"text-decoration: none; font-size:11px; color: #000\"><font face=\"Arial\">%2</font></a> (<b style=\"font-size:12px;\">%3</b>) <a href=\"http://habrahabr.ru/users/%4/\" style=\"font-size:9px; color: #000\">%4</a> </div>");
....
htmltext+=QString(templatehtml["templatepes"])....
Как?
Баг.
Windows 7.
После выхода из программы значок в трее остаётся, пока не проведёшь над ним мышкой.
Похоже, это потому, что винда автоматически не удаляет из трея значки программ, когда процесс завершается.
Windows 7.
После выхода из программы значок в трее остаётся, пока не проведёшь над ним мышкой.
Похоже, это потому, что винда автоматически не удаляет из трея значки программ, когда процесс завершается.
Проблема действительно связана с тем, что windows(не только 7) автоматически не удаляют значок из лотка, но эту проблему исправлю принудительным удалением значка из трея при сигнале на закрытие программы.
Ага, такая ерунда также наблюдается и в других приложениях: я заметил тот же эффект в некоторых версиях DC++, и недавно установленном Free-Lance Tray, похожему, кстати, по принципу действия на сей информер
«чтоб… не отвлекаться лишний раз»
:'-)
:'-)
Ну объясню подробней, у меня нечто вроде информационного голода и примерно каждые 5-10 минут листал страницы хабра, чтоб посмотреть обновления, тем более что большинство горячих событий постоянно публикуются тут. Мне проще было для себя сделать информер, который мне говорил, когда есть обновления, чтоб я без нужды не тратил время и не кликал по страницам, тем более, что некоторые страницы от главной скрыты на несколько кликов.
десктопный rss-ридер с поддержкой отображения кол-ва непрочитанных на панели задач — и никакие подобные нотификаторы не нужны =)
но спасибо, именно благодаря вашему приложению таки нашёл клёвый rss-клиент для google reader.
но спасибо, именно благодаря вашему приложению таки нашёл клёвый rss-клиент для google reader.
А зачем вы парсите страницу, делайте не нужный трафик хабру и пользователям, когда есть RSS. Если только ради отображения кол-во коментов на момент парсинга, то сомнительная фича.
Ну или сделали бы парсер на сервере, который бы уже инфу раздавал на свой клиент, так бы меньше нагрузки было хабру и пользователям.
Вообще в твитере уже с 5 хабра ботов, которые уведомляют о новых постах, так что если стоит какой-нибуть тфи клиент, можно там нотификации получать.
Ну или сделали бы парсер на сервере, который бы уже инфу раздавал на свой клиент, так бы меньше нагрузки было хабру и пользователям.
Вообще в твитере уже с 5 хабра ботов, которые уведомляют о новых постах, так что если стоит какой-нибуть тфи клиент, можно там нотификации получать.
1) Если внимательно читать, то я никому не навязываю его, кому удобно пользоваться — для таких буду рад усовершенствовать программу, но в первую очередь я ее пишу для себя.
2) Меня не интересуют трансляторы, информер делал с целью закрыть вкладку в браузере до тех пор пока не появится обновление.
3) То, что в перспективе программы вообще rss и трансляторы по типу твитера мне не помогут. Я хочу работать и входить на хабру только при наличии новой и интересной для меня информации, а не мониторить все подряд много раз переходя по вкладкам браузера.
2) Меня не интересуют трансляторы, информер делал с целью закрыть вкладку в браузере до тех пор пока не появится обновление.
3) То, что в перспективе программы вообще rss и трансляторы по типу твитера мне не помогут. Я хочу работать и входить на хабру только при наличии новой и интересной для меня информации, а не мониторить все подряд много раз переходя по вкладкам браузера.
На Федоре 15 сходу заработал идеально. Непривычно даже как-то…
Молодец, хорошая работа! Собрал и установил на Ubuntu 10.04 — все четко…
Продолжай развивать…
Продолжай развивать…

Хм, что-то не так с шаблоном)
P.S. и опять старые грабли в работе с QNetworkAccessManager) ща будет фикс в гитхабе
win7/ubuntu10.04 четко.
Было бы хорошо настраивать время обновления кэша и при обновлении выводить разницу в комментариях.
Было бы хорошо настраивать время обновления кэша и при обновлении выводить разницу в комментариях.
скачал
по мне проще открыть хабр и увидеть все что надо, чем держать запущенной отдельную прогу, не показывает описания постов (по которым я обычно решаю — читать или не читать), зато показывает кол-во комментов что мне абсолютно не надо и неинтересно
по мне проще открыть хабр и увидеть все что надо, чем держать запущенной отдельную прогу, не показывает описания постов (по которым я обычно решаю — читать или не читать), зато показывает кол-во комментов что мне абсолютно не надо и неинтересно
Mac OS X 10.6.8 — не запустилась программа. Куда выслать отчёт? Если, конечно, нужно.
Если вы качали сборку из топика, то вам нужно установить Qt. Либо попробуйте эту
А зачем аж 3 потока плодить? Для вывода данных на форму все рано нужно лезть в основной поток. Если для обработки скаченного, то да. Но зачем аж три. Если можно сделать так:
— в асинхроне получить страницу в главном потоке и сохранить в буфер;
— передать буфер в поток (использовать QThread, либо одну из оберток Run/Map/MapReduce);
— получить готовые структуры и вывести.
Еще вариант: сделать предварительную обработку страницу, т.е. отпилить все что ДО постов и все что после постов, разделить массив фагментов (фрагмент = пост) и передать в QtConcurrent::Run тогда можно в процессе обработки фрагментов выводить их на экран, а еще лучше помещать в модель. Данную модель в дальнейшем будет удобно использовать для построения QML списка.
— в асинхроне получить страницу в главном потоке и сохранить в буфер;
— передать буфер в поток (использовать QThread, либо одну из оберток Run/Map/MapReduce);
— получить готовые структуры и вывести.
Еще вариант: сделать предварительную обработку страницу, т.е. отпилить все что ДО постов и все что после постов, разделить массив фагментов (фрагмент = пост) и передать в QtConcurrent::Run тогда можно в процессе обработки фрагментов выводить их на экран, а еще лучше помещать в модель. Данную модель в дальнейшем будет удобно использовать для построения QML списка.
А как мне следить за обновлениями тогда? Самый уместный вариант — выдирать регуляркой данные, если я не прав — поправьте.
QThread — в моем варианте больше подошел таймер.
QThread — в моем варианте больше подошел таймер.
В основном потоке таймер (настраиваемый), который дергает метод загрузки страницы. Потом по мере поступления можно складывать данные в буфер либо дождать все целиком. А дальше уже и регулярки и что угодно еще в отдельном потоке. Но можно обойтись без них, QXMLStreamReader использовать для этого. Структура страниц думаю будет ему по-зубам.
А как это повлияет на производительность, а то я не совсем сейчас до конца всего понимаю. тайемр работает на фоне всей программы и не блокирует ее работу, а как для меня, если я буду делать множество веток, отдельно на получение и отдельно на обработку данных — мне кажется это наоборот прибавит работы. Или я не правильно мыслю?
Т.к. страницы ничем кроме своего названия не отличаются, то логично использовать на их обработку один и тотже метод. Отличить от какого запроса пришел ответ можно либо по url, либо по динамическому свойству, в которое можно поместить все что угодно (если вопрос в этом был). А то что запросов будет много не страшно, они все равно асинхронно будут выполняться и не будут блокировать основной поток. Если есть еще вопросы то лучше продолжить в ICQ/jabber.
doc.qt.nokia.com/latest/xml-rsslisting.html вот как-то так.
Зачем в дереве исходников автоматически генерируемые файлы? Уберите.
10.7.1 не запускается установщик
Process: habr [68149]
Path: /Users/USER/Downloads/habr.app/Contents/MacOS/habr
Identifier: com.yourcompany.habr
Version: ??? (???)
Code Type: X86-64 (Native)
Parent Process: launchd [326]
Date/Time: 2011-10-09 13:27:48.749 +0400
OS Version: Mac OS X 10.7.1 (11B26)
Report Version: 9
Interval Since Last Report: 282724 sec
Crashes Since Last Report: 5
Per-App Crashes Since Last Report: 2
Anonymous UUID: FD1664B8-23DE-4AC3-B689-6CD079218DC9
Crashed Thread: 0
Exception Type: EXC_BREAKPOINT (SIGTRAP)
Exception Codes: 0x0000000000000002, 0x0000000000000000
Application Specific Information:
dyld: launch, loading dependent libraries
Dyld Error Message:
Library not loaded: /Users/*/QtGui.framework/Versions/4/QtGui
Referenced from: /Users/USER/Downloads/habr.app/Contents/MacOS/habr
Reason: image not found
Binary Images:
0x100000000 — 0x10001afef +com.yourcompany.habr (??? — ???) /Users/USER/Downloads/habr.app/Contents/MacOS/habr
0x7fff69404000 — 0x7fff69438ac7 dyld (195.5 — ???) /usr/lib/dyld
Model: MacBookPro8,1, BootROM MBP81.0047.B1E, 2 processors, Intel Core i5, 2.3 GHz, 8 GB, SMC 1.68f96
Process: habr [68149]
Path: /Users/USER/Downloads/habr.app/Contents/MacOS/habr
Identifier: com.yourcompany.habr
Version: ??? (???)
Code Type: X86-64 (Native)
Parent Process: launchd [326]
Date/Time: 2011-10-09 13:27:48.749 +0400
OS Version: Mac OS X 10.7.1 (11B26)
Report Version: 9
Interval Since Last Report: 282724 sec
Crashes Since Last Report: 5
Per-App Crashes Since Last Report: 2
Anonymous UUID: FD1664B8-23DE-4AC3-B689-6CD079218DC9
Crashed Thread: 0
Exception Type: EXC_BREAKPOINT (SIGTRAP)
Exception Codes: 0x0000000000000002, 0x0000000000000000
Application Specific Information:
dyld: launch, loading dependent libraries
Dyld Error Message:
Library not loaded: /Users/*/QtGui.framework/Versions/4/QtGui
Referenced from: /Users/USER/Downloads/habr.app/Contents/MacOS/habr
Reason: image not found
Binary Images:
0x100000000 — 0x10001afef +com.yourcompany.habr (??? — ???) /Users/USER/Downloads/habr.app/Contents/MacOS/habr
0x7fff69404000 — 0x7fff69438ac7 dyld (195.5 — ???) /usr/lib/dyld
Model: MacBookPro8,1, BootROM MBP81.0047.B1E, 2 processors, Intel Core i5, 2.3 GHz, 8 GB, SMC 1.68f96
Лично пока не могу организовывать сборку для MAC, но можно скомпилировать самому или попробовать еще habrahabr.ru/blogs/announcements/129986/#comment_4305883
Какую сборку запускали? попробую помочь.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Хабра-информер v.0.1