Я продолжаю небольшой цикл статей на тему In-memory-data-grid.
В первой статье была раскрыта сама концепция IMDG без конкретных примеров и деталей реализации. Сегодня мы копнем чуть глубже.
Режимы работы принципиально не отличаются в зависимости от конкретного IMDG-решения, поэтому описанное ниже справедливо для концепции IMDG в целом, а не для отдельных решений.
В этом режиме IMDG-кластер состоит только из одного узла. В основном используется только для отладочных целях.
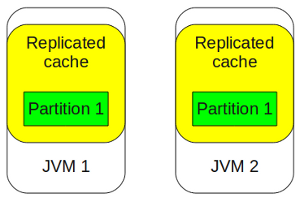
В replicated mode полный набор данных реплицируется на каждый узел кластера.
Плюсы:
Для того, чтоб каждый PUT не отнимал столько времени можно выполнять его асинхронно (многие IMDG предоставляют такую возможность), но тогда за консистентность данных отвечать только вам. Поэтому я бы не стал использовать такой режим работы в write intensive системах.
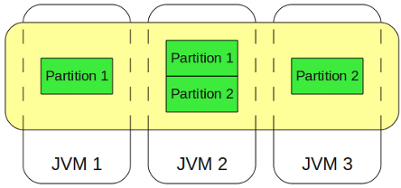
Самый интересный и используемый режим работы IMDG, в котором можно оценить все положительные качества этой концепции.
Описание этого режима и было основой предыдущей статьи.
Для поиска данных в IMDG используется поиск по инвертированному индексу (inverted index).
Индексы представлены объектами, реализующими интерфейс MapIndex.
На данный момент (Oracle Coherence 3.7) доступны 2 реализации индексов:
Если запрос требует обращения сразу к нескольким индексам, то сначала происходит формирование ответа по каждому из индексов, а затем те множества, которые получились пересекаются между собой, чтоб получить конечный результат. Это пересечение не происходит мгновенно, поэтому прежде чем сделать запрос, который требует обращения к нескольким индексам, надо подумать, не приведет ли это к пересечению огромных множеств ключей.
Плюсы:
Минусы:
Здесь для поиска по кэшам используется Apache Lucene (open source full text search engine) и HibernateSearch (который основан всё на том же Lucene).
У этого выбора есть существенные недостатки, но есть и преимущества.
Плюсы:
При индексировании данных используется 2 типа индекса: Primary Key Index и Functional Index.
Различие между ними состоит в том, что Primary Key Index позволяет проверять значение какого-либо индексированного атрибута только на равенство какой-то константе, а Functional Index позволяет выполнять сравнение. Например можно выбрать такие объекты, у которых поле someField > 10.
Обновление индекса может выполняться синхронно (обеспечивает консистентность) либо асинхронно (скорость обновления индекса).
В целом, плюсы и минусы те же самые, что и у Oracle Coherence.
Не имеет разделения индекса на типы, но принцип работы индексов такой же, как и у Oracle Coherence, поэтому отдельно их расписывать не имеет смысла.
Если ваше приложение допускает возможность многопоточной записи данных в какой-либо объект, то для обеспечения целостности данных обычно используется механизм блокировок. И этот механизм надежно работает, если вы находитесь в пределах одной машины. Но что делать, если ваши данные распределены по кластеру?
На этот случай IMDG-решения имеют реализации распределенных блокировок.
Распределенная блокировка (distributed lock) — это блокировка, доступная на всех узлах кластера, и имеющая на всех этих узлах одно и то же состояние. Т.е. невозможна ситуация, при которой 2 потока на разных узлах одновременно владели бы одной и той же блокировкой.
Распределенная блокировка обеспечивает синхронизацию доступа к данным в кластере.
В следующей статье я попытаюсь рассказать о результатах сравнения различных IMDG и NoSQL решений, но, как вы прекрасно понимаете, это займет некоторое время, поэтому не ждите статьи раньше середины сентября. Всех приглашаю поучаствовать в обсуждении результатов:)
В первой статье была раскрыта сама концепция IMDG без конкретных примеров и деталей реализации. Сегодня мы копнем чуть глубже.
Режимы работы IMDG
Режимы работы принципиально не отличаются в зависимости от конкретного IMDG-решения, поэтому описанное ниже справедливо для концепции IMDG в целом, а не для отдельных решений.
1. Local mode
В этом режиме IMDG-кластер состоит только из одного узла. В основном используется только для отладочных целях.
2. Replicated mode
В replicated mode полный набор данных реплицируется на каждый узел кластера.

Плюсы:
- Высокая скорость доступа к данным, т.к. все данные доступны на каждом узле кластера
- Потеря любого узла не приводит к перебалансировке кластера, т.к. перераспределять данные не нужно
- Этот режим применим только в том случае, если все необходимые для работы данные помещаются в памяти одного узла
- Повышенный расход памяти
- PUT объекта в кластер должен привести к обновлению этого объекта на всех узлах следовательно нужны дополнительные усилия для обеспечения консистентности данных в кластере, поэтому PUT в таком режиме происходит медленнее
- Ограниченная возможность к масштабированию, так как каждый PUT вызывает необходимость репликации данных на каждый узел
Для того, чтоб каждый PUT не отнимал столько времени можно выполнять его асинхронно (многие IMDG предоставляют такую возможность), но тогда за консистентность данных отвечать только вам. Поэтому я бы не стал использовать такой режим работы в write intensive системах.
3. Distributed mode
Самый интересный и используемый режим работы IMDG, в котором можно оценить все положительные качества этой концепции.

Описание этого режима и было основой предыдущей статьи.
Индексы
Для поиска данных в IMDG используется поиск по инвертированному индексу (inverted index).
1. Oracle Coherence
Индексы представлены объектами, реализующими интерфейс MapIndex.
На данный момент (Oracle Coherence 3.7) доступны 2 реализации индексов:
- SimpleMapIndex — обычный инвертированный индекс
- ConditionalIndex — расширяет SimpleMapIndex, в отличие от которого позволяет задать условие, при котором объект кэша будет проиндексирован
Если запрос требует обращения сразу к нескольким индексам, то сначала происходит формирование ответа по каждому из индексов, а затем те множества, которые получились пересекаются между собой, чтоб получить конечный результат. Это пересечение не происходит мгновенно, поэтому прежде чем сделать запрос, который требует обращения к нескольким индексам, надо подумать, не приведет ли это к пересечению огромных множеств ключей.
Плюсы:
- Распределенный индекс обеспечивает распараллеливание поиска
- Можно контролировать, какие объекты необходимо индексировать
Минусы:
- Пересечение нескольких больших множеств может отнять больше времени, чем поиск по неиндексированным данным
- Скорость поиска по такому индексу ниже, чем по индексам, основанным на битовых множествах (bitset)
- Обновление индекса происходит инкрементально, т.е. при добавлении объекта в индекс не надо его полностью перестраивать
2. JBoss Infinispan
Здесь для поиска по кэшам используется Apache Lucene (open source full text search engine) и HibernateSearch (который основан всё на том же Lucene).
У этого выбора есть существенные недостатки, но есть и преимущества.
Плюсы:
- Результатом выполнения запроса к индексу является bitset, следовательно пересечение таких множеств (если ваш запрос требует поиска по нескольким индексам) — операция дешевая.
- Поддержка full-text search
- Быстрый поиск (т.к. производится наложением бинарной маски)
- Индекс не распределенный, он хранится в Apache Lucene Directory (точнее это некая адаптированная имплементация самой ALD)
- Только один поток одновременно может обновлять индекс
- Обновление индекса только через полное его перестроение
3. VMWare Gemfire
При индексировании данных используется 2 типа индекса: Primary Key Index и Functional Index.
Различие между ними состоит в том, что Primary Key Index позволяет проверять значение какого-либо индексированного атрибута только на равенство какой-то константе, а Functional Index позволяет выполнять сравнение. Например можно выбрать такие объекты, у которых поле someField > 10.
Обновление индекса может выполняться синхронно (обеспечивает консистентность) либо асинхронно (скорость обновления индекса).
В целом, плюсы и минусы те же самые, что и у Oracle Coherence.
4. Hazelcast
Не имеет разделения индекса на типы, но принцип работы индексов такой же, как и у Oracle Coherence, поэтому отдельно их расписывать не имеет смысла.
Блокировки
Если ваше приложение допускает возможность многопоточной записи данных в какой-либо объект, то для обеспечения целостности данных обычно используется механизм блокировок. И этот механизм надежно работает, если вы находитесь в пределах одной машины. Но что делать, если ваши данные распределены по кластеру?
На этот случай IMDG-решения имеют реализации распределенных блокировок.
Распределенная блокировка (distributed lock) — это блокировка, доступная на всех узлах кластера, и имеющая на всех этих узлах одно и то же состояние. Т.е. невозможна ситуация, при которой 2 потока на разных узлах одновременно владели бы одной и той же блокировкой.
Распределенная блокировка обеспечивает синхронизацию доступа к данным в кластере.
Заключение
В следующей статье я попытаюсь рассказать о результатах сравнения различных IMDG и NoSQL решений, но, как вы прекрасно понимаете, это займет некоторое время, поэтому не ждите статьи раньше середины сентября. Всех приглашаю поучаствовать в обсуждении результатов:)







