Комментарии 83
Для php очень неплохо работает Doctrine Migrations — используюся инкрементные изменения. Если использовать в сочетании с ORM, то частично и 3ий метод используется (изменения генерируются из описания маппинга).
В некоторых фреймворках, например Yii Framework, версионирование БД уже предусмотрено. Прежде чем рассматривать внешние решения, убедитесь, что в вашем фреймворке нет своего.
Убил кучу времени, пока нашёл версионирование БД для Yii. Причём сначала нашёлся экстеншн, который потом стал частью фреймворка :) Короче, вот ссылка на детальное описание: www.yiiframework.com/doc/guide/1.1/en/database.migration
И кстати, это версионирование в Yii появилось совсем недавно, буквально год назад ещё ничего не было :)
И кстати, это версионирование в Yii появилось совсем недавно, буквально год назад ещё ничего не было :)
спасибо автору за статью, добавил в избранное
Для django удобно работать с south — реализация варианта «Метод инкрементных изменений».
Мы в проекте все изменения базы данных записываем в два скрипта: статичный, для создания базы с нуля (с create-ами), и инкрементный лог, для апгрейда версий (с alter-ами). Задача — удостовериться, что оба метода создают одинаковые базы данных. Это делает ночной билдер, создавая базы обоими методами и сравнивая их information schema.
Не совсем понятно, можете уточнить? От какого основания отталкиваются ваши инкрементные изменения?
Если я правильно понял, то: есть начальное состояние A0, есть конечное состояние An, есть набор изменений X1-Xn. Соответсвенно на пустую базу можно сразу накатить An, а на базу в версии Am через изменения Xn.
Скрипт проверяет условия равенства A0 + X1...Xn = An
Скрипт проверяет условия равенства A0 + X1...Xn = An
От первой версии, поставленной на продакшн. После этого собственно и завели инкрементный лог.
Подскажите, есть ли инструменты для версионирования er-диаграмм? Например, может ли Erwin или PowerDesigner хранить несколько состояний базы и генерировать скрипты для перехода между любым из состояний? Было бы идеально, чтобы на каждый schema-update можно было повесить дополнительный data-update скрипт, но это наверное что-то из области фантаскики :)
В некотором смысле тот же SQLyog подходит под ваше описание. Он может отображать диаграммы связей, и умеет генерировать diff'ы. Только делает это на реальных копиях БД. И проблема состоит в том, что он не заточен под именно эту функциональность, поэтому будет не слишком удобно.
Я уверен, что есть и другие инструменты со схожим функционалом, но у меня пока не было времени для их обзора.
Я уверен, что есть и другие инструменты со схожим функционалом, но у меня пока не было времени для их обзора.
Еще в Oracle есть ретроспективные запросы и flashback'и
В Oracle чего только нет. Например, отчасти по данной теме, в версии 11gR2 появилась интересная фича, называемая Edition Based Redefinition.
Она не касается вопроса, как поддерживать версионирование структуры базы, но позволяет без проблем применять миграции на живую базу в режиме реального времени без остановок. Можно также одновременно держать две версии объектов базы данных (например, если один модуль еще не переписан под новую структуру) без их рассогласования.
Она не касается вопроса, как поддерживать версионирование структуры базы, но позволяет без проблем применять миграции на живую базу в режиме реального времени без остановок. Можно также одновременно держать две версии объектов базы данных (например, если один модуль еще не переписан под новую структуру) без их рассогласования.
Можно почитать книжку «Рефакторинг баз данных: эволюционное проектирование»
Скотт В. Эмблер, Прамодкумар Дж. Садаладж
Скотт В. Эмблер, Прамодкумар Дж. Садаладж
Метод инкрементных изменений мне кажется не до конца описан. Например, если мы поддерживаем несколько версий своих продуктов, и может быть такое, что в версии 2.3 была исправлена ошибка в хранимке, а самая свежая версия, к примеру, 2.6. Тут мы делаем обновление для 2.3, а что потом делать с остальными версиями, если там тоже нужно это обновление? Продублировать эти изменения в каждую из следующих версий (естественно, после тестирования), или есть другой, более верный вариант? Подскажите пожалуйста, кто уже сталкивался с этим
Имхо — править и выпускать версии
2.3.1
2.3.1
Так же как нужно поступать с исходным кодом в двух разных branch-ах — мержить.
Проблема в том, что с методе инкрементных изменений есть своя нумерация версий, которая может конфликтовать с версионностью системы контроля версий. К примеру, в бранче в какой-то момент уже могут быть свои изменения структуры БД под тем же номером, что и в транке, которые туда попасть не должны. А система контроля версий захочет все это смержить. В общем, есть, над чем подумать.
Вы не правильно поняли меня. Я имел ввиду, что если поддерживаются две различные версии продукта (а они должны поддерживаться в в двух разных бранчах), если исправляется как-то критический баг в одном из них (в младшей версии), то тогда чтобы изменения затронули и последнюю или придется скопипастить в ней эти исправления или дождаться момента мержинга двух бранчей. В любом случае делать это придется вручную для разруливания зависимостей.
Да, вы правы, удобство работы с бранчами в системах контроля версий может быть еще одним критерием при выборе подхода. Мне представляется, что лучше всего с этим обстоит у третьего метода (так и не придумал, как его кратко назвать). Чуть хуже — у метода идемпотентных изменений, и совсем нехорошо у инкрементного подхода.
Наверное, позже добавлю это в статью.
Наверное, позже добавлю это в статью.
Я бы предложил для этого 4-й вариант. Инкрементные версии по таблицам/сущностям. Решит проблемы с мержем, ну и добавит больше гибкости (например можно откатить только одну таблицу, хотя откат — это очень скользкая тема). Счетчик версий один, так что легко знаем какие инкременты накатывать. Правда выйдет нечто вроде VCS в VCS, т.е. небольшая избыточность, но возможно получится использовать 3й метод в совокупности с VCS. Например, версия базы — это номер ревизии, делаем дифф с хэдом и накатываем. Здесь также структура лежит для каждой таблицы в отдельных файлах.
Немного дополнил статью своими мыслями по поводу слияния веток.
После долгих мучений с ораклом, написали таск, который экспортирует схему в текстовые файлы. А дальше уже системой контроля версий
Можете посмотреть это: www.xt-r.com/2010/11/oracle-svn-git-etc.html
Спасибо, конечно, но велосипед уже давно собран: clck.ru/EiGe
Хорошая статья. Хотелось бы отметить, то что вы называете «Ruby Migrations», в действительности является ActiveRecord Migrations. ActiceRecord не является частью руби. В руби есть и другие ORM, поддерживающие миграции. Например, Sequel и DataMapper.
Когда-то давно использовали скрипты миграции, сколько же с ними приключений было…
Сейчас используем что-то близкое к «уподобления структуры БД исходному коду» только чуть дальше чем уровень бд.
ORM + CodeFirst методология разработки.
В исходном коде хранится структура классов, а уже ORM отвечает за то что будет находится в конкретной базе, при необходимости создавая/изменяя структуру.
Сейчас используем что-то близкое к «уподобления структуры БД исходному коду» только чуть дальше чем уровень бд.
ORM + CodeFirst методология разработки.
В исходном коде хранится структура классов, а уже ORM отвечает за то что будет находится в конкретной базе, при необходимости создавая/изменяя структуру.
Как вариант еще можно использовать ddl-триггеры для сбора ddl-скриптов, но вообще автоматическая генерация скл-скриптов апгрейда-дегрейда продакшн баз это абсолютное зло.
У нас отлично второй способ работает — «Метод идемпотентных изменений».
Мы в хранимой процедуре проверяем номер текущей версии базы, пропускаем выполнение если данная процедура уже выполнялась, а дальше в теле процедуры накатываем все изменения. Получаем такой скрипт с кучей процедур, которые выполняются по очереди, и автоматом применяются или пропускаются.
Достоинство этого еще в том, что каждая процедура — отдельная транзакция (PostgreSQL), которая либо выполнится, либо нет — соответственно если обновление сбойнет в середине, то откат будет до конкретной версии — очень удобно такие обновления отлаживать.
Ну и на закуску — номера версии в базе критичны, чтобы приложение могло проверить, а совместимо-ли оно с базой (или даже обновить базу самостоятельно).
Мы в хранимой процедуре проверяем номер текущей версии базы, пропускаем выполнение если данная процедура уже выполнялась, а дальше в теле процедуры накатываем все изменения. Получаем такой скрипт с кучей процедур, которые выполняются по очереди, и автоматом применяются или пропускаются.
Достоинство этого еще в том, что каждая процедура — отдельная транзакция (PostgreSQL), которая либо выполнится, либо нет — соответственно если обновление сбойнет в середине, то откат будет до конкретной версии — очень удобно такие обновления отлаживать.
Ну и на закуску — номера версии в базе критичны, чтобы приложение могло проверить, а совместимо-ли оно с базой (или даже обновить базу самостоятельно).
Я так понимаю, каждое конкретное изменение у вас не идемпотентно само по себе? Просто ваша хранимая процедура принимает решение о применении каждого изменения, в зависимости от текущей версии БД? А каким образом она определяет, в какой версии было добавлено каждое изменение?
Да, действительно, не совсем оно… просто результат похож :-)
Каждая процедура может обновить только с конкретной версии на конкретную, соответственно ошибки исключены — либо она пропускает себя как уже примененную, либо пропускает, так как версия базы не достаточна, либо накатывает изменения, если она точно попадает в версию.
Версии отслеживаются по таблице с датой, номером версии, и порядковым номером обновления (удобно для поиска последнего обновления, которое и есть текущая версия базы).
Самое удобное — транзакционность самого файла обновлений — его можно накатывать сколько угодно.
А сделать каждое изменение в базе идемпотентным — имхо на практике не реально.
Каждая процедура может обновить только с конкретной версии на конкретную, соответственно ошибки исключены — либо она пропускает себя как уже примененную, либо пропускает, так как версия базы не достаточна, либо накатывает изменения, если она точно попадает в версию.
Версии отслеживаются по таблице с датой, номером версии, и порядковым номером обновления (удобно для поиска последнего обновления, которое и есть текущая версия базы).
Самое удобное — транзакционность самого файла обновлений — его можно накатывать сколько угодно.
А сделать каждое изменение в базе идемпотентным — имхо на практике не реально.
Примерно так работает:
Завязано на особенности PostgreSQL в работе с хранимыми процедурами (я-бы предпочел без них, но не получается по ряду причин).
А это собственно, проверка версии:
CREATE OR REPLACE FUNCTION update_1_0_2() RETURNS INTEGER AS $PROC$
BEGIN
IF validate_update_script( '1.0.1', '1.0.2' ) = 1 THEN RETURN 1; END IF;
----- Собственно изменения
RETURN 1;
END;
$PROC$ LANGUAGE plpgsql VOLATILE;
SELECT * FROM update_1_0_2();
Завязано на особенности PostgreSQL в работе с хранимыми процедурами (я-бы предпочел без них, но не получается по ряду причин).
А это собственно, проверка версии:
-- service function - no need to copy it to the next update script (it will be saved)
-- this function returns 1 if the updated was already applied, and 0 if the update must be applied
-- an exception is thrown if the update cannot be applied due to wrong database version
CREATE OR REPLACE FUNCTION validate_update_script( old_version TEXT, new_version TEXT ) RETURNS INTEGER AS $PROC$
BEGIN
IF EXISTS( SELECT id FROM version WHERE id = new_version ) THEN
RAISE INFO 'Already upgraded to version %, skipping.', new_version;
RETURN 1; -- means already done - skip the update
END IF;
RAISE INFO 'Upgrading from version % to version %...', old_version, new_version;
IF NOT EXISTS( SELECT id FROM version WHERE id = old_version ) THEN
RAISE EXCEPTION 'Error: version % not found - cannot upgrade', old_version;
END IF;
-- set the version here, assuming that if a transaction fails, it will be rolled back
INSERT INTO version( id, modified, update_number ) --VALUES( new_version, NOW() );
SELECT new_version, NOW(), MAX(update_number) + 1 FROM version;
IF NOT EXISTS( SELECT id FROM version WHERE id = new_version ) THEN
RAISE EXCEPTION 'Error: version % not found - upgrade failed', new_version;
END IF;
RETURN 0; -- means continue with the update
END;
$PROC$ LANGUAGE plpgsql VOLATILE;
Могу, кстати, порекомендовать статью М. Фаулера по теме эволюционного дизайна баз данных, перевод на русский имеется там по ссылке
У метода инкрементых изменений есть существенный минус — при большом количестве версий миграция с очень старой версии до очень новой занимает все больше и больше времени. Так, в одном из моих старых проектов, полный скрипт от первой до последней версии весит уже 3 МБ и проигрывается несколько десятков минут даже на пустой базе. На рабочих БД миграция может идти сутками.
Сейчас в разработке идея сделать т.н. jump-скрипты прямой конвертации между отдаленными версиями без промежуточной конвертации. Беда в том, что кроме изменения метаданных скрипты содержат и работу с данными.
Сейчас в разработке идея сделать т.н. jump-скрипты прямой конвертации между отдаленными версиями без промежуточной конвертации. Беда в том, что кроме изменения метаданных скрипты содержат и работу с данными.
Да, в таком случае вам, действительно, может подойти третий способ. Но в потенциале проблемы с данными есть всегда.
С другой стороны, настолько ли часто вам нужно обновляться с очень старой версии до новой? Если же речь об очень старой версии baseline-файла, то проблема решается созданием нового baseline для каждой новой версии, или же подверсии.
С другой стороны, настолько ли часто вам нужно обновляться с очень старой версии до новой? Если же речь об очень старой версии baseline-файла, то проблема решается созданием нового baseline для каждой новой версии, или же подверсии.
Софт о котором я писал — тиражируемый. БД в комплекте. Клиенты обновляют свои БД самостоятельно при обновлении версии ПО.
baseline'ы мы используем в разработке. фактически храним «эталон» БД каждой релизной версии
baseline'ы мы используем в разработке. фактически храним «эталон» БД каждой релизной версии
Ага, БД у клиентов — это даже интереснее. В таком случае, конечно, всегда желательно минимизировать время обновления.
Если найдете какой-нибудь интересный подход к изменениям данных (привязка DML-запросов к номеру ревизии системы контроля, или еще что) — пишите, будет интересно почитать :)
Если найдете какой-нибудь интересный подход к изменениям данных (привязка DML-запросов к номеру ревизии системы контроля, или еще что) — пишите, будет интересно почитать :)
Я планировал статью на эту тему сделать, вы меня в каком-то смысле опередили :)
В тиражируемом софте вообще много интересных нераскрытых тем. Та же миграция, например, должна производится полностью автоматически с расчетом на неподготовленного пользователя. Бывает, версия СУБД меняется, что накладывает определенные особенности на миграцию.
Напишу обязательно
В тиражируемом софте вообще много интересных нераскрытых тем. Та же миграция, например, должна производится полностью автоматически с расчетом на неподготовленного пользователя. Бывает, версия СУБД меняется, что накладывает определенные особенности на миграцию.
Напишу обязательно
т.е. вы предлагаете, для каждой версии писать отдельный (прямой) скрипт для старых версий?
например, у нас имеется 4 версии:
1,2,3,4
При первом подходе, мы пишем инкрементальные скрипты для последовательного обновления:
1->2, 2->3, 3->4
а вы предлагаете поддерживать миграцию типа:
1->2
1->3
1->4
2->3
2->4
3->4
Не слишком ли накладно получается?
например, у нас имеется 4 версии:
1,2,3,4
При первом подходе, мы пишем инкрементальные скрипты для последовательного обновления:
1->2, 2->3, 3->4
а вы предлагаете поддерживать миграцию типа:
1->2
1->3
1->4
2->3
2->4
3->4
Не слишком ли накладно получается?
Спасибо за статью! Помогла разложить мысли по полкам :)
Хочу еще добавить, что сейчас идет работа над 2 версией ECM7.Migrator.
Добавлена возможность параллельного ведения нескольких независимых последовательностей номеров версий (например, когда в системе несколько модулей и каждый имеет собственную структуру БД), почти полностью переписано ядро. Также планируется добавить поддержку MSSQL CE 4.0 и возможность выполнения всех миграций в пределах одного подключения (для пересоздания БД в тестах на SQLite).
Планируем релиз через 1-2 месяца.
Хочу еще добавить, что сейчас идет работа над 2 версией ECM7.Migrator.
Добавлена возможность параллельного ведения нескольких независимых последовательностей номеров версий (например, когда в системе несколько модулей и каждый имеет собственную структуру БД), почти полностью переписано ядро. Также планируется добавить поддержку MSSQL CE 4.0 и возможность выполнения всех миграций в пределах одного подключения (для пересоздания БД в тестах на SQLite).
Планируем релиз через 1-2 месяца.
Для контроля версий БД, особенно при работе большого количества разработчиков, была мной написана специальная утилита (для внутреннего использования). Которая умеет: сканировать и сохранять «снимок» структуры, сравнивать снимки/структуры, генерировать скрипт изменений.
Анализ изменений:
habrastorage.org/storage/264fb666/e8f75ce4/d4fef82b/d7001ddd.png
Просмотр скрипта на изменение
habrastorage.org/storage/65279ec4/eb2e479f/147fda2f/5f59112f.png
Анализ изменений:
habrastorage.org/storage/264fb666/e8f75ce4/d4fef82b/d7001ddd.png
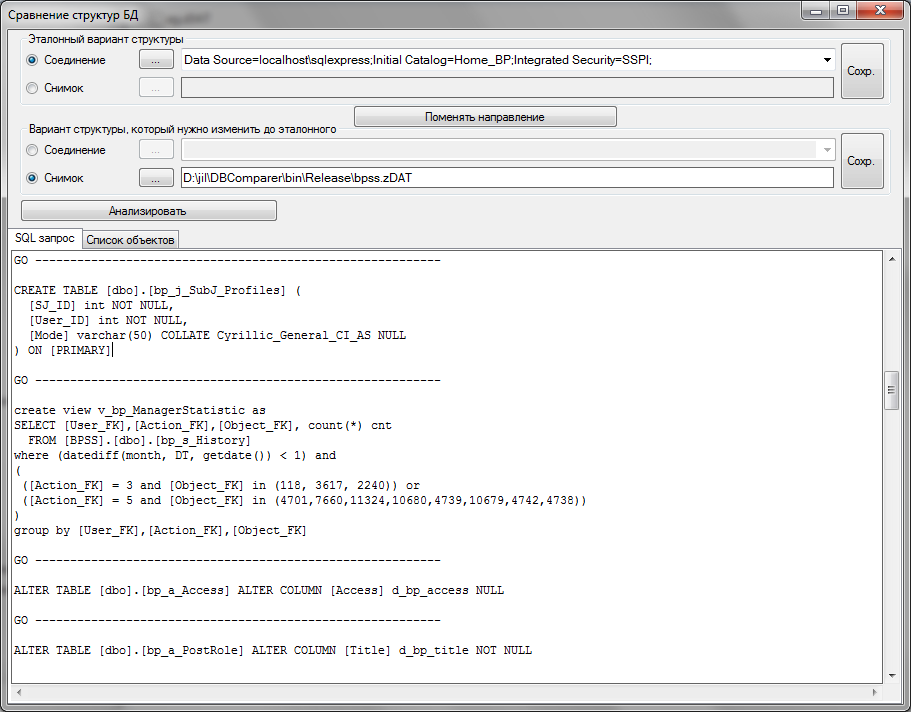{kind=link}
Просмотр скрипта на изменение
habrastorage.org/storage/65279ec4/eb2e479f/147fda2f/5f59112f.png
{kind=link}
Вот это очень интересно! Не хотите написать статью на эту тему?
Судя по наречию SQL и коннекшен стрингам — это T SQL для ms SQL Server. А чем кроме цены не устроили существующие инструменты (кроме цены), такие как SQL Examiner www.sqlaccessories.com/SQL_Examiner/
?
?
1) цена. для себя бесплатно, и вообще я не против открыть доступ к своим исходникам. и уже сейчас отдать в использование собранный проект.
2) сейчас реализован только SQL Server, но в коде заложены возможности использования «драйверов», когда-то я их сделаю (или кто-то поможет)
3) будет возможность миграции не только структуры, но и данных
4) ну и самое главное, всё что написано в этом проекте — будет использовано в нашем основном коммерческом продукте.
2) сейчас реализован только SQL Server, но в коде заложены возможности использования «драйверов», когда-то я их сделаю (или кто-то поможет)
3) будет возможность миграции не только структуры, но и данных
4) ну и самое главное, всё что написано в этом проекте — будет использовано в нашем основном коммерческом продукте.
>>в коде заложены возможности использования «драйверов»
интересно какой уровень абстракции предлагают ваши «драйвера», все же структура метаданных да и DDL-синтаксис разных СУБД сильно отличаются
интересно какой уровень абстракции предлагают ваши «драйвера», все же структура метаданных да и DDL-синтаксис разных СУБД сильно отличаются
Классы C# описывают объекты структуры. Некий интерфейс. Вы правы, разные БД отличаются сильно: но ведь не за всеми мелочами и требуется следить. (если всё таки требуется — уж простите).
Вполне достаточно: таблица, представление, хранимка, функция, поле, тип, ключи (внешние и первичные), индексы, некоторые констрейнты.
Ну и конечно: классы можно пополнять, и использовать — если драйвер их умеет обрабатывать, если нет: они будут выдавать «код-заглушку» (например пустую строку).
Вполне достаточно: таблица, представление, хранимка, функция, поле, тип, ключи (внешние и первичные), индексы, некоторые констрейнты.
Ну и конечно: классы можно пополнять, и использовать — если драйвер их умеет обрабатывать, если нет: они будут выдавать «код-заглушку» (например пустую строку).
Классы описывают основные элементы структуры БД. Некий класс-провайдер умеет сравнить два аналогичных элемента: получить скрипт миграции.
Те особенности, которые различаются в разных БД, могу и не использоваться ими. Будет реализованы метод интерфейса как заглушка: возвращать пустую строку например.
Сейчас нам было достаточно такие элементы: таблица, представление, процедура, функция, триггеры, поля, индексы, ключи (первичные, внешние), констрейнты, домены типов.
Те особенности, которые различаются в разных БД, могу и не использоваться ими. Будет реализованы метод интерфейса как заглушка: возвращать пустую строку например.
Сейчас нам было достаточно такие элементы: таблица, представление, процедура, функция, триггеры, поля, индексы, ключи (первичные, внешние), констрейнты, домены типов.
Для Interbase/Firebird есть отличный инструмент Database Comparer. он же включен в IDE IBExpert. пользуемся-ненарадуемся.
Спасибо за статью. От себя еще хочу добавить пару слов про один немаловажный критерий выбора подхода к версионированию — возможность отката до предыдущих версий. Я имею ввиду не удаление базы и применение миграций по порядку до нужной версии, а именно откат.
Я использую один замечательный инструмент: Liquibase. Он предполагает хранение changelog в виде XML, сам по нему генерирует SQL код в прямую и в обратную сторону. Поддерживается достаточно большое число СУБД — вобщем, я им весьма доволен.
Я использую один замечательный инструмент: Liquibase. Он предполагает хранение changelog в виде XML, сам по нему генерирует SQL код в прямую и в обратную сторону. Поддерживается достаточно большое число СУБД — вобщем, я им весьма доволен.
>>Допустим, программисты в процессе разработки записывают свои изменения структуры и данных БД в отдельный файл в виде SQL-запросов
это не очень удобно. С более-менее сложными БД как правило применяют визуальные средства разработки, скрипты напрямую никто не пишет. И тут то встает проблема версионирования. Даже логирование всех запросов не очень-то ее решает, т.к. в логе будет много лишних изменений/откатов.
это не очень удобно. С более-менее сложными БД как правило применяют визуальные средства разработки, скрипты напрямую никто не пишет. И тут то встает проблема версионирования. Даже логирование всех запросов не очень-то ее решает, т.к. в логе будет много лишних изменений/откатов.
Мы в работе используем вот такую вот тулзовину — github.com/davejkiger/mysql-php-migrations (возможно кому-то станет полезной тоже).
Работает как нужно, с задачами справляется, кушать не просит. Да, инкриментальная миграция.
Работает как нужно, с задачами справляется, кушать не просит. Да, инкриментальная миграция.
Нет идеального хранения структуры и миграции БД. В первом и втором способах требуется довольно много ручной работы (особенно во втором, иногда приходится творить чудеса, чтобы написать идемпотентные скрипты), велика вероятность ошибки. В идеале хорошо бы для каждого скрипта писать скрипт отката, но это еще столько же, если не больше, работы. Кроме того, необходима самописная тулза для применения изменений. В одном проекте для такой тулзы использовали интеграцию с svn, в качестве версии базы использовался номер коммита последнего примененного скрипта. И самое печальное — подходы со скриптованием изменений делают практически невозможным трэкинг изменений объектов базы.
Метод хранения базы как исходного кода всем хорош. Никаких самописных скриптов, изменения можно делать на тестовой базе, а потом реверсить их в проект. Но главный недостаток — необходимость думать о миграции данных, и снова извращаться с ручными скриптами. Кроме того, нужен надежный инструмент. В свое время пришлось отказаться от RedGate, поскольку для MS SQL он генерировал скрипты настолько избыточные и глючные, что проще было писать вручную. Сейчас Database project в VS 2010 довольно стабилен, пользуюсь им в большинстве проектов с MS SQL.
Метод хранения базы как исходного кода всем хорош. Никаких самописных скриптов, изменения можно делать на тестовой базе, а потом реверсить их в проект. Но главный недостаток — необходимость думать о миграции данных, и снова извращаться с ручными скриптами. Кроме того, нужен надежный инструмент. В свое время пришлось отказаться от RedGate, поскольку для MS SQL он генерировал скрипты настолько избыточные и глючные, что проще было писать вручную. Сейчас Database project в VS 2010 довольно стабилен, пользуюсь им в большинстве проектов с MS SQL.
У нас в компании используется что-то среднее между первым и вторым вариантом. Структура таблиц описывается разработчиками на XML. Из этого XML с помощью специальных XSL-файлов можно получить либо скрипт с DDL для создания хранилища с нуля, либо патч для внесения в таблицы идемпотентных изменений. Заодно этот XML используется для описания метамодели (по типу этой).
Это интересный подход. Только, по-моему, он ближе всего как раз к третьему методу, потому что, как я понял, вы используете декларативное описание всей структуры в виде XML. Возникли вот такие вопросы:
1. Скажите, вы храните XML-описание в системе контроля версий?
2. Каким образом вы получаете патч в виде идемпотентных изменений при помощи XSLT? Ведь у вас есть два XML-описания разных версий, и нужно сгенерировать патч как разницу между ними Не совсем представляю, как это сделать при помощи XSLT.
3. Еще интереснее было бы узнать про описание этим файлом мета-модели.
И вообще, на словах ваше решение довольно-таки красиво звучит :) Не расскажете ли поподробнее? Мне кажется, и статья на эту тему была бы хорошо воспринята.
1. Скажите, вы храните XML-описание в системе контроля версий?
2. Каким образом вы получаете патч в виде идемпотентных изменений при помощи XSLT? Ведь у вас есть два XML-описания разных версий, и нужно сгенерировать патч как разницу между ними Не совсем представляю, как это сделать при помощи XSLT.
3. Еще интереснее было бы узнать про описание этим файлом мета-модели.
И вообще, на словах ваше решение довольно-таки красиво звучит :) Не расскажете ли поподробнее? Мне кажется, и статья на эту тему была бы хорошо воспринята.
И конечно, мой главный вопрос во всех комментариях: как вы поступаете с изменениями в данных? :)
1. Да, XML хранится в CVS (так исторически сложилось).
2. Каждое изменение описывается в виде блока на PL/SQL по типу той, что в статье с information_schema. Проверяется, есть ли таблица/индекс/столбец таблицы с описанными свойствами. Если нет, то делается нужный ALTER (или CREATE).
Соответственно, такой блок можно получить из описания одного столбца на XML путем его непосредственного XSLT-преобразования сразу в PL/SQL. Сам XSL-файл, конечно, выглядит страшно :)
3. Привел не очень подходящую ссылку. Метамодель у нас выполняет несколько другие функции. Где-то на Хабре видел более близкое описание, но не смог найти. Когда-нибудь, возможно, она будет приведена здесь в отдельной статье. Коротко так: в метамодели описываются сущности и их атрибуты. Эта модель имеет признаки «объектности»: сущности имеют методы, могут наследоваться, быть абстрактными.
Список всех полей таблиц хранится в таблице метамодели. На него мапятся атрибуты сущности, которые хранятся в соответствующих полях. Это может быть и не простейшее отображение один к одному, хотя бы потому, что поле на самом деле может не являться столбцом таблицы, а вычисляться по формуле.
Формула, кстати — это атрибут поля, которое тоже является сущностью, хотя и не предметной модели, а самой метамодели. Поэтому описывается оно также, как и остальные атрибуты. Есть и описание таблицы-хранилища полей, которое в ней же и хранится.
Заполняется хранилище полей из тех же XML, разумеется.
2. Каждое изменение описывается в виде блока на PL/SQL по типу той, что в статье с information_schema. Проверяется, есть ли таблица/индекс/столбец таблицы с описанными свойствами. Если нет, то делается нужный ALTER (или CREATE).
Соответственно, такой блок можно получить из описания одного столбца на XML путем его непосредственного XSLT-преобразования сразу в PL/SQL. Сам XSL-файл, конечно, выглядит страшно :)
3. Привел не очень подходящую ссылку. Метамодель у нас выполняет несколько другие функции. Где-то на Хабре видел более близкое описание, но не смог найти. Когда-нибудь, возможно, она будет приведена здесь в отдельной статье. Коротко так: в метамодели описываются сущности и их атрибуты. Эта модель имеет признаки «объектности»: сущности имеют методы, могут наследоваться, быть абстрактными.
Список всех полей таблиц хранится в таблице метамодели. На него мапятся атрибуты сущности, которые хранятся в соответствующих полях. Это может быть и не простейшее отображение один к одному, хотя бы потому, что поле на самом деле может не являться столбцом таблицы, а вычисляться по формуле.
Формула, кстати — это атрибут поля, которое тоже является сущностью, хотя и не предметной модели, а самой метамодели. Поэтому описывается оно также, как и остальные атрибуты. Есть и описание таблицы-хранилища полей, которое в ней же и хранится.
Заполняется хранилище полей из тех же XML, разумеется.
Я недавно выложил утилиту для создания DIFF-миграций в PostgreSQL, которой пользовался в разных проектах последние несколько лет. Вот она: dklab.ru/lib/dklab_pgmigrator/ — может, кому пригодится.
Вещи, которые я подразумеваю при ее использовании (и которые считаю более-менее резонными исходя из предыдущего опыта, хотя кому-то они могут показаться спорными):
Ну и по процессу разработки:
Вещи, которые я подразумеваю при ее использовании (и которые считаю более-менее резонными исходя из предыдущего опыта, хотя кому-то они могут показаться спорными):
- Идеальная длина релиз-цикла — неделя, не больше (в идеале — как а Facebook, вообще каждый день). Чем чаще происходят релизы, тем меньше рассинхронизация БД на дев-сервере и на продакшене, тем проще бороться с их различиями.
- Откаты к предыдущим версиям на практике не так полезны, как кажутся (поэтому — ИМХО не нужны). Во многих случаях они даже и невозможны (например, удалилась таблица — как такое откатить?). Если откаты хочется применять для отката «неудачных релизов», то на сколько-нибудь больших базах они все равно будут происходить слишком медленно, чтобы их использовать. Лучше вместо откатов применять короткий релиз-цикл.
- При разработке используется единая БД для всех разработчиков (исходники веб-части, естественно, у всех свои). Это лишь самая простая и очевидная схема. Хотя я верю, что ситуация, когда у каждого своя БД, может быть удобнее, но на практике ни разу не получилось ее задействовать — опять же, все упирается в объем данных в БД, ведь на дев-сервере должна быть БД, максимально приближенная по данным к продакшену.
- Структура БД уже и так хранится в недрах сервера СУБД, поэтому дублировать ее еще раз в файлах и версионировать — не есть хорошо. Когда центральная точка находится в БД, а не в файлах, это не приведет к сюрпризам и потерям изменений. Т.е. отказ от хранения схемы в файле в качестве первичной точки — это защита от человеческого фактора.
- После наката всех DIFF-ов БД на продакшене должна стать гарантировано идентичной БД на дев-сервере. Т.е. DIFF генерируется именно как разница между структурой, извлеченной из СУБД дев-сервера, и структурой, извлеченной прямо с продакшена. (Поэтому моя утилита лезет на продакшен, чтобы взять актуальную схему оттуда.) Нельзя завязываться за то, что БД на продакшене меняется только скриптом миграции — всегда существует человеческий фактор, кто-нибудь когда-нибудь обязательно что-то поправит напрямую на продакшене (да и в аварийных случаях бывает удобно прокинуть один-два альтера, которые только что накатил на дев-сервер, чтобы починить «лежащий» сайт — по крайней мере, это лишняя степень свободы, не обязательно же ее каждый день использовать).
- Результирующий DIFF должно быть возможно подвергнуть ручной коррекции (как по альтерам, так и по данным), причем после таких ручных коррекций должен быть, опять же, гарантирован п.4.
Ну и по процессу разработки:
- Должна быть общая для всех дев-база, на нее после каждого удачного релиза целиком копируется БД с продакшена вместе со всеми данными (либо — с большой их частью, плюс можно персональные данные искажать, это уже детали).
- Обязательно должна быть БД «репетиции релиза», на которую перед каждым релизом (выкладкой на продакшен) проводится накат миграции и полная проверка работоспособности сайта. БД «репетиции релиза» перед этим перезаливается самыми свежими данными с продакшена. Ее же, кстати, можно использовать для нагрузочного тестирования (т.е. там должны быть и веб-морды).
- Ну и, естественно, должна быть БД продакшена. :-) Причем, т.е. релиз вначале репетируется на «репетиционной» базе, вероятность того, что на продакшене возникнут проблемы при накате, практически равна нулю.
> Должна быть общая для всех дев-база, на нее после каждого удачного релиза целиком копируется БД с продакшена вместе со всеми данными
Хе-хе, со всеми данными. К счастью, в большинстве случаев это невыполнимо. Хотя такая жесткая синхронизация всех баз сразу решает много проблем.
Хе-хе, со всеми данными. К счастью, в большинстве случаев это невыполнимо. Хотя такая жесткая синхронизация всех баз сразу решает много проблем.
Спасибо за развернутое описание вашего процесса, и отдельное спасибо за diff-утилиту для PostgreSQL, добавил ссылку в статью.
По поводу единой центральной БД для разработки — здесь, думаю, все зависит от проекта и команды. К примеру, когда мы использовали центральную dev-БД, время от времени это приводило к ошибкам, т.к. в процессе разработки какой-либо фичи не всегда сразу понятно, какими именно должны быть изменения в БД. Иногда, после нескольких экспериментов с разной структурой таблиц, человек забывал откатить все ненужные изменения, и в итоге оставлял как те, что нужны для работы фичи, так и те, что остались от экспериментов. Конечно же, при использовании diff-подхода, все эти изменения в итоге попадут на продакшн.
Второй негативный момент центральной dev DB — временное несоответствие структуры БД версии приложения. Ведь когда один разработчик создает фичу и при этом меняет структуру общей БД, у других разработчиков что-то может сломаться в приложении, т.к. код, который работает с измененной структурой, еще не выложен в общий репозиторий кода.
Поэтому мы пришли к следующей схеме:
1. Центральной базы данных нет. Каждый разработчик работает с локальной базой данных.
2. Скрипты для создания текущей версии БД с нуля хранятся в репозитории.
3. Эти же скрипты умеют заливать во вновь созданную БД и один из наборов тестовых данных: легкий набор с минимально необходимыми для тестирования данными, и большой — для тестирования тяжелых запросов на больших объемах данных.
4. При обновлении кода из репозитория, разработчик запускает скрипт, который обновляет и базу данных до последней версии. При этом с нуля она не создается, применяются только изменения по сравнению с прошлым обновлением. Так что много времени это не занимает.
5. Когда человек заканчивает разработку фичи или баг-фикса, он отправляет в общий репозиторий кода как изменения в, собственно, коде, так и изменения в БД. Причем на этом этапе его изменения проходят через общую процедуру code review.
6. Как и вы, мы практикуем «репетицию релиза» на копии продакшн базы данных.
Между прочим, такой подход к разработке может использоваться с любым из трех методов версионирования, описанных в статье.
По поводу единой центральной БД для разработки — здесь, думаю, все зависит от проекта и команды. К примеру, когда мы использовали центральную dev-БД, время от времени это приводило к ошибкам, т.к. в процессе разработки какой-либо фичи не всегда сразу понятно, какими именно должны быть изменения в БД. Иногда, после нескольких экспериментов с разной структурой таблиц, человек забывал откатить все ненужные изменения, и в итоге оставлял как те, что нужны для работы фичи, так и те, что остались от экспериментов. Конечно же, при использовании diff-подхода, все эти изменения в итоге попадут на продакшн.
Второй негативный момент центральной dev DB — временное несоответствие структуры БД версии приложения. Ведь когда один разработчик создает фичу и при этом меняет структуру общей БД, у других разработчиков что-то может сломаться в приложении, т.к. код, который работает с измененной структурой, еще не выложен в общий репозиторий кода.
Поэтому мы пришли к следующей схеме:
1. Центральной базы данных нет. Каждый разработчик работает с локальной базой данных.
2. Скрипты для создания текущей версии БД с нуля хранятся в репозитории.
3. Эти же скрипты умеют заливать во вновь созданную БД и один из наборов тестовых данных: легкий набор с минимально необходимыми для тестирования данными, и большой — для тестирования тяжелых запросов на больших объемах данных.
4. При обновлении кода из репозитория, разработчик запускает скрипт, который обновляет и базу данных до последней версии. При этом с нуля она не создается, применяются только изменения по сравнению с прошлым обновлением. Так что много времени это не занимает.
5. Когда человек заканчивает разработку фичи или баг-фикса, он отправляет в общий репозиторий кода как изменения в, собственно, коде, так и изменения в БД. Причем на этом этапе его изменения проходят через общую процедуру code review.
6. Как и вы, мы практикуем «репетицию релиза» на копии продакшн базы данных.
Между прочим, такой подход к разработке может использоваться с любым из трех методов версионирования, описанных в статье.
НЛО прилетело и опубликовало эту надпись здесь
НЛО прилетело и опубликовало эту надпись здесь
я использую готовую утилиту для контроля версий https://github.com/raoptimus/db-migrator.go
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Версионная миграция структуры базы данных: основные подходы