Мне всегда был интересен Ruby-on-Rails (RoR) и Twitter как яркий представитель платформы на этом framework. 6 апреля этого года в блоге команды Twitter появилась запись о полной смене поисковой платформы с RoR на Java. Под катом перевод о том, как это было.
«Весной 2010, команда поиска Twitter приступила к переписыванию нашего поискового движка с целью обслуживания постоянно растущего траффика, уменьшения задержки для конечного пользователя и увеличения доступности нашего сервиса, получения возможности быстрой разработки новых поисковых возможностей. Как часть работы, мы запустили новый поисковый движок реального времени, сменив наш back-end с MySQL на версию Lucene. На прошлой неделе, мы запустили замену для нашего Ruby-on-Rails front-end: сервер Java, который мы называем Blender. Мы рады анонсировать, что это изменение уменьшило время поиска в 3 раза и даст нам возможность последовательно наращивать поисковый функционал в следующие месяцы.
Поиск Twitter один из самых нагруженных поисковых движков в мире, обслуживающий более одного миллиарда поисковых запросов в день. На этой неделе до того, как мы развернули Blender, #tsunami в Японии способствовало значительному увеличению поисковых запросов и связанных с ними пиками задержек в поиске. После запуска Blender, наша 95-ти процентная задержка уменьшилась в 3 раза, с 800мс до 250мс и загрузка CPU на наших front-end серверах сократилась вдвое. Сейчас мы имеем потенциал для того, чтобы обслужить в 10 раз больше запросов на одну машину. Это означает, что мы можем поддерживать прежнее число запросов с меньшим количеством серверов, уменьшая на порядок расходы на наш front-end сервис.

95-ти % задержка поискового API до и после запуска Blender.
Для лучшего понимания прироста производительности, вам необходимо сначала понять недостатки наших бывших Ruby-on-Rails front-end серверов. Они запускали фиксированное число однопоточных рабочих процессов, каждый из которых делал следующее:
Нам давно было известно, что модель синхронной обработки запросов использует наши CPUs неэффективно. За долгое время, мы также накопили значительный технический долг в нашем основном коде на Ruby, делая его сложным для добавления функциональности и улучшения надёжности нашего поискового движка. Blender решает эти вопросы путем:
Следующая диаграмма показывает архитектуру поискового движка Twitter. Запросы с веб-сайта, API или внешние клиенты в Twitter передаются Blender через аппаратный балансировщик нагрузки. Blender разбирает поисковый запрос и передаёт его back-end сервисам, используя рабочие процессы для обработки зависимостей между сервисами. Наконец, результаты от сервисов объединяются и формируются на соответствующем языке клиента.
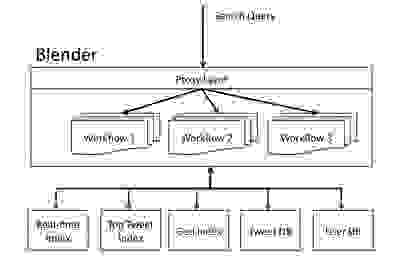
Поисковая архитектура Twitter с Blender.
Blender – это Thrift и HTTP сервис построенный на Netty, широко масштабируемой NIO клиент-серверной библиотекой написанной на Java, что позволяет разрабатывать для различных серверов и клиентов быстро и легко. Мы выбрали Netty из нескольких его конкурентов, таких как Mina и Jetty, потому что она имеет более прозрачный API, более хорошую документацию и, самое важное, потому что несколько других проектов Twitter используют этот framework. Для того чтобы Netty работала с Thrift, мы написали простой Thrift кодек, который декодирует входящие запросы Thrift из канального буфера Netty, когда он считывается из сокета и кодирует исходящие ответы Thrift, когда он записывается в сокет. Netty вводит ключевую абстракцию, названную Канал (Channel), для инкапсуляции соединения к сетевому сокету, который предоставляет интерфейс для выполнения множества I/O операций, таких как чтение, запись, соединение и привязка. Все канальные I/O операций асинхронны по своей природе. Это означает, что любой I/O вызов немедленно возвращается с экземпляром ChannelFuture, который сообщает, когда запрошенные операции I/O успешны, неудачны или отменены. Когда сервер Netty принимает новое соединение, он создаёт новый канальный конвейер для обработки соединения. Канальный конвейер – это последовательность канальных обработчиков, которые реализуют бизнес логику необходимую для обработки запроса. В следующей секции мы покажем, как Blender переносит эти конвейеры для запроса, обрабатывающих рабочие процессы.
В Blender, рабочий процесс – это множество back-end сервисов с зависимостями между ними, которые должны быть обработаны для обслуживания входящего запроса. Blender автоматически определяет зависимости между ними, для примера, если сервис A зависит от сервиса B, A запрашивается первым и результаты его работы передаются B. Это удобно для представления рабочих процессов в виде направленных ацикличных графов (см. рисунок ниже).
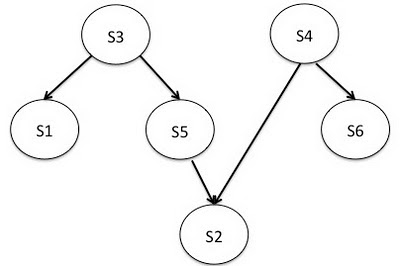
Пример рабочего процесса Blender с 6 back-end сервисами.
В примере рабочего процесса, мы имеем 6 сервисов {s1, s2, s3, s4, s5, s6} с зависимостями между ними. Прямая грань от s3 в s1 означает, что s3 должен быть вызван до вызова s1, потому что s1 нужны результаты s3. Для такого рабочего проекта, библиотека Blender выполняет топологическую сортировку на DAG для определения конечного порядка сервисов, который также является порядком их вызова. Порядок выполнения для рабочего процесса выше будет {(s3, s4), (s1, s5, s6), (s2)}. Это означает, что s3 и s4 могут быть вызваны параллельно на первом шаге; когда они вернут результаты, на следующем шаге также параллельно вызываются s1, s5, и s6; до завершающего вызова s2. После того как Blender определил порядок выполнения, он отображается на Netty конвейер. Этот конвейер – последовательность обработчиков, которым нужно передать запрос для обработки.
Так как рабочие процессы отображаются на конвейеры Netty в Blender, нам было нужно направить входящие клиентские запросы на соответствующий конвейер. Для этого, мы построили прокси слой, который мультиплексирует и направляет клиентские запросы по следующим правилам:
Мы использовали модель Netty управляемую событиями для выполнения всех перечисленных задач асинхронно, так что больше нет потоков ожидающих I/O.
Как только поисковый запрос поступает на конвейер рабочего процесса, он проходит через последовательность сервисных обработчиков в последовательности определённой рабочим процессом. Каждый сервисный обработчик создаёт соответствующий back-end запрос для этого поискового запроса и передаёт его на удалённый сервер. Например, сервисный обработчик реального времени создаёт запрос реального времени и отправляет его асинхронно на один или несколько индексов реального времени. Мы используем twitter commons библиотеку (недавно ставшей open source!) для предоставления управления пулом соединений, балансировки нагрузки и определения мёртвых хостов. Поток I/O, который обрабатывает поисковый запрос, освобождается, когда все back-end ответы обработаны. Поток таймера проверяет каждые несколько миллисекунд для того, чтобы увидеть, если любой из back-end ответов вернулся с удалённых серверов и устанавливает флаг, указывающий если запрос успешен, превысил время ожидания или неудачен. Мы поддерживаем один объект на протяжении жизненного цикла поискового запроса для управления этим типом данных. Успешные ответы агрегируются и посылаются на следующий шаг для обработки сервисными обработчиками в конвейере рабочего процесса. Когда все ответы с первого шага прибывают, делается второй шаг асинхронных запросов. Этот процесс повторяется пока мы не завершим рабочий процесс или время ожидания не превысит допустимое. Как вы можете видеть, на протяжении выполнения рабочего процесса, ни один поток не простаивает в ожидании I/O. Это позволяет нам эффективно использовать CPU на наших машинах с Blender и обрабатывать большое число конкурентных запросов. Мы также экономим на задержках, так как выполняем большинство запросов для back-end сервисов параллельно.
Для того чтобы убедиться в высоком качестве сервиса пока мы интегрируем Blender в нашу систему, мы используем старые Ruby-on-Rails front-end сервера как прокси для перенаправления thrift запросов для нашего Blender кластера. Использование старых front-end серверов в качестве прокси позволяет нам обеспечивать целостность пользовательского восприятия, делая значительные изменения в базовой технологии. В следующей фазе нашего развёртывания, мы полностью уберём Ruby-on-Rails из нашего поискового стека, соединив пользователей напрямую с Blender и потенциально уменьшив задержки еще больше.»
«Весной 2010, команда поиска Twitter приступила к переписыванию нашего поискового движка с целью обслуживания постоянно растущего траффика, уменьшения задержки для конечного пользователя и увеличения доступности нашего сервиса, получения возможности быстрой разработки новых поисковых возможностей. Как часть работы, мы запустили новый поисковый движок реального времени, сменив наш back-end с MySQL на версию Lucene. На прошлой неделе, мы запустили замену для нашего Ruby-on-Rails front-end: сервер Java, который мы называем Blender. Мы рады анонсировать, что это изменение уменьшило время поиска в 3 раза и даст нам возможность последовательно наращивать поисковый функционал в следующие месяцы.
Прирост производительности
Поиск Twitter один из самых нагруженных поисковых движков в мире, обслуживающий более одного миллиарда поисковых запросов в день. На этой неделе до того, как мы развернули Blender, #tsunami в Японии способствовало значительному увеличению поисковых запросов и связанных с ними пиками задержек в поиске. После запуска Blender, наша 95-ти процентная задержка уменьшилась в 3 раза, с 800мс до 250мс и загрузка CPU на наших front-end серверах сократилась вдвое. Сейчас мы имеем потенциал для того, чтобы обслужить в 10 раз больше запросов на одну машину. Это означает, что мы можем поддерживать прежнее число запросов с меньшим количеством серверов, уменьшая на порядок расходы на наш front-end сервис.

95-ти % задержка поискового API до и после запуска Blender.
Улучшенная поисковая архитектура Twitter
Для лучшего понимания прироста производительности, вам необходимо сначала понять недостатки наших бывших Ruby-on-Rails front-end серверов. Они запускали фиксированное число однопоточных рабочих процессов, каждый из которых делал следующее:
- Разбирал поисковый запрос;
- Синхронно запрашивал поисковые сервера;
- Агрегировал и формировал результаты.
Нам давно было известно, что модель синхронной обработки запросов использует наши CPUs неэффективно. За долгое время, мы также накопили значительный технический долг в нашем основном коде на Ruby, делая его сложным для добавления функциональности и улучшения надёжности нашего поискового движка. Blender решает эти вопросы путем:
- Создания полностью асинхронного сервиса агрегирования. Без потоков ожидающих сетевого I/O для завершения;
- Агрегируя результаты от back-end сервисов, таких как, сервис реального времени, сервис топового твита (tweet) и сервис географических индексов;
- Аккуратнее разрешая зависимости между сервисами. Рабочие процессы автоматически обрабатывают транзитивные зависимости между back-end сервисами.
Следующая диаграмма показывает архитектуру поискового движка Twitter. Запросы с веб-сайта, API или внешние клиенты в Twitter передаются Blender через аппаратный балансировщик нагрузки. Blender разбирает поисковый запрос и передаёт его back-end сервисам, используя рабочие процессы для обработки зависимостей между сервисами. Наконец, результаты от сервисов объединяются и формируются на соответствующем языке клиента.
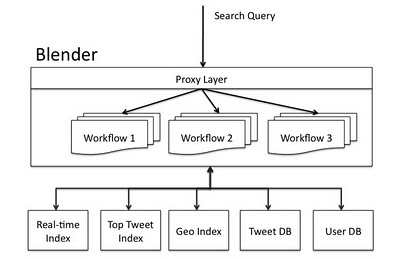
Поисковая архитектура Twitter с Blender.
Обзор Blender
Blender – это Thrift и HTTP сервис построенный на Netty, широко масштабируемой NIO клиент-серверной библиотекой написанной на Java, что позволяет разрабатывать для различных серверов и клиентов быстро и легко. Мы выбрали Netty из нескольких его конкурентов, таких как Mina и Jetty, потому что она имеет более прозрачный API, более хорошую документацию и, самое важное, потому что несколько других проектов Twitter используют этот framework. Для того чтобы Netty работала с Thrift, мы написали простой Thrift кодек, который декодирует входящие запросы Thrift из канального буфера Netty, когда он считывается из сокета и кодирует исходящие ответы Thrift, когда он записывается в сокет. Netty вводит ключевую абстракцию, названную Канал (Channel), для инкапсуляции соединения к сетевому сокету, который предоставляет интерфейс для выполнения множества I/O операций, таких как чтение, запись, соединение и привязка. Все канальные I/O операций асинхронны по своей природе. Это означает, что любой I/O вызов немедленно возвращается с экземпляром ChannelFuture, который сообщает, когда запрошенные операции I/O успешны, неудачны или отменены. Когда сервер Netty принимает новое соединение, он создаёт новый канальный конвейер для обработки соединения. Канальный конвейер – это последовательность канальных обработчиков, которые реализуют бизнес логику необходимую для обработки запроса. В следующей секции мы покажем, как Blender переносит эти конвейеры для запроса, обрабатывающих рабочие процессы.
Библиотека рабочих процессов
В Blender, рабочий процесс – это множество back-end сервисов с зависимостями между ними, которые должны быть обработаны для обслуживания входящего запроса. Blender автоматически определяет зависимости между ними, для примера, если сервис A зависит от сервиса B, A запрашивается первым и результаты его работы передаются B. Это удобно для представления рабочих процессов в виде направленных ацикличных графов (см. рисунок ниже).
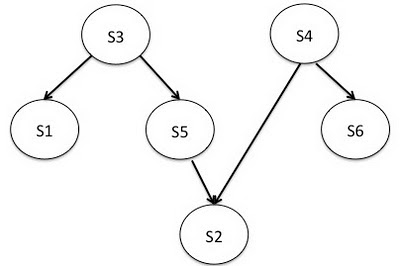
Пример рабочего процесса Blender с 6 back-end сервисами.
В примере рабочего процесса, мы имеем 6 сервисов {s1, s2, s3, s4, s5, s6} с зависимостями между ними. Прямая грань от s3 в s1 означает, что s3 должен быть вызван до вызова s1, потому что s1 нужны результаты s3. Для такого рабочего проекта, библиотека Blender выполняет топологическую сортировку на DAG для определения конечного порядка сервисов, который также является порядком их вызова. Порядок выполнения для рабочего процесса выше будет {(s3, s4), (s1, s5, s6), (s2)}. Это означает, что s3 и s4 могут быть вызваны параллельно на первом шаге; когда они вернут результаты, на следующем шаге также параллельно вызываются s1, s5, и s6; до завершающего вызова s2. После того как Blender определил порядок выполнения, он отображается на Netty конвейер. Этот конвейер – последовательность обработчиков, которым нужно передать запрос для обработки.
Мультиплексирование входящих запросов
Так как рабочие процессы отображаются на конвейеры Netty в Blender, нам было нужно направить входящие клиентские запросы на соответствующий конвейер. Для этого, мы построили прокси слой, который мультиплексирует и направляет клиентские запросы по следующим правилам:
- Когда удалённый клиент Thrift открывает постоянное подключение к Blender, прокси слой создаёт карту для локальных клиентов, одну для каждого из локальных серверов, обслуживающих рабочие процессы. Заметьте, что все эти сервера запускаются в процессе Blender среды JVM и создаются, когда процесс Blender стартует;
- Когда запрос поступает на сокет, прокси слой считывает его, определяет, какой рабочий процесс был запрошен и направляет его соответствующему серверу рабочих процессов;
- Аналогично, когда ответ поступает от локального сервера, обслуживающего рабочие процесс, прокси считывает его и записывает ответ для удалённого клиента.
Мы использовали модель Netty управляемую событиями для выполнения всех перечисленных задач асинхронно, так что больше нет потоков ожидающих I/O.
Диспетчеризация back-end запросов
Как только поисковый запрос поступает на конвейер рабочего процесса, он проходит через последовательность сервисных обработчиков в последовательности определённой рабочим процессом. Каждый сервисный обработчик создаёт соответствующий back-end запрос для этого поискового запроса и передаёт его на удалённый сервер. Например, сервисный обработчик реального времени создаёт запрос реального времени и отправляет его асинхронно на один или несколько индексов реального времени. Мы используем twitter commons библиотеку (недавно ставшей open source!) для предоставления управления пулом соединений, балансировки нагрузки и определения мёртвых хостов. Поток I/O, который обрабатывает поисковый запрос, освобождается, когда все back-end ответы обработаны. Поток таймера проверяет каждые несколько миллисекунд для того, чтобы увидеть, если любой из back-end ответов вернулся с удалённых серверов и устанавливает флаг, указывающий если запрос успешен, превысил время ожидания или неудачен. Мы поддерживаем один объект на протяжении жизненного цикла поискового запроса для управления этим типом данных. Успешные ответы агрегируются и посылаются на следующий шаг для обработки сервисными обработчиками в конвейере рабочего процесса. Когда все ответы с первого шага прибывают, делается второй шаг асинхронных запросов. Этот процесс повторяется пока мы не завершим рабочий процесс или время ожидания не превысит допустимое. Как вы можете видеть, на протяжении выполнения рабочего процесса, ни один поток не простаивает в ожидании I/O. Это позволяет нам эффективно использовать CPU на наших машинах с Blender и обрабатывать большое число конкурентных запросов. Мы также экономим на задержках, так как выполняем большинство запросов для back-end сервисов параллельно.
Развёртывание Blender и будущая работа
Для того чтобы убедиться в высоком качестве сервиса пока мы интегрируем Blender в нашу систему, мы используем старые Ruby-on-Rails front-end сервера как прокси для перенаправления thrift запросов для нашего Blender кластера. Использование старых front-end серверов в качестве прокси позволяет нам обеспечивать целостность пользовательского восприятия, делая значительные изменения в базовой технологии. В следующей фазе нашего развёртывания, мы полностью уберём Ruby-on-Rails из нашего поискового стека, соединив пользователей напрямую с Blender и потенциально уменьшив задержки еще больше.»







