Все началось с необходимости в одном из приложений получать снимок произвольного окна и 3-4 раза в секунду распознавать несколько областей изображения с заранее известными символами. Сделать скриншот окна с помощью WinAPI проблем не составило, а вот над распознаванием пришлось немного потрудиться.
Естественно для начала я поискал готовые решения. Первое что выдал гугл — библиотека Tesseract, а точнее ее обертка под .NET – под названием Tessnet2. К сожалению при детальном изучении оказалось что она мне не подходит. Во второй версии Tesseract довольно много утечек памяти, что мне не подходило, так как после 10 минут работы программы с использованием Tessnet2 приложение вылетало с OutOfMemoryException. На странице Tesseract написано, что в третьей версии утечек не должно быть, но и рабочей обертки для Tesseract3 я не нашел.
Так же мне не подошло средство MODI (Microsoft Office Document Imaging) – так как распознает только файлы (нельзя передать ему экземпляр класса Bitmap для распознавания).
После непродолжительного поиска в гугле других бесплатных библиотек распознавания символов под .NET и проблем с ними связанных, я решил что проще будет сделать свою маленькую библиотеку как раз для таких случаев. Тем более задача довольно интересная.
Что мы имеем:
Что я хотел получить в итоге? Получить класс, методу которого можно передать изображение, специальный файл с набором распознаваемых символов, и на выходе получить распознанную строку. Примерно так:
Еще подумалось было бы неплохо иметь утилиты для создания таких файлов шрифтов и для проверки созданного шрифта на конкретном изображении. Утилиты исключительно для удобства. Все действия которые можно сделать с помощью утилит, можно сделать и в коде.
Вся функциональность распределена между тремя классами OCRSymbol, OCRFont и OCRReader.
OCRSymbol – описывает символ: его название, ширину и высоту, сдвиг символа вниз относительно самого высокого символа из всего набора, списки точек характерных для символа и точек составляющих фон.
OCRFont – набор символов, сериализуется с помощью BinaryFormater.
OCRReader – координирует считывание символов один за другим. Так же задает стратегию считывания. Дело в том, что при создании экземпляра этого класса мы можем задать цвет. Этот цвет будет использован либо как цвет фона (все что не этот цвет, то символ), либо как цвет символа (все что не этот цвет – фон). Это надо для случаев когда в фоне используется больше одного цвета, либо когда символ нарисован более чем одним цветом.
Случай когда символ нарисован более чем одним цветом (черный фон, все остальное символ)
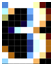
Случай, когда фон не одноцветный (фон – зеленый градиент, символы нарисованы белым цветом)

Алгоритм распознавания очень простой. Каждый символ описывается двумя универсальными списками List. Первый – точки, которые должны присутствовать в символе (Good), второй – которые не должны, то есть фон (Bad). При сравнении с очередным символом сначала проходится список точек фона, если при проверке очередной точки соответствующая точка в распознаваемом изображении оказывается не фоном (цвет фона задается при создании OCRReader), цикл заканчивается и переходим к сравнению со следующим символом. Если список точек фона успешно пройден, то аналогично прогоняем через список точек символа. Любое несовпадение – переходим к сравнению со следующем символом. Если все проверки прошли успешно, значит мы распознали наш символ и можем переходить к распознаванию следующего.
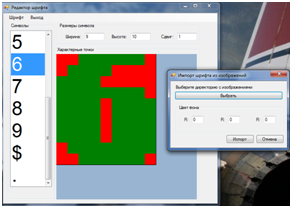
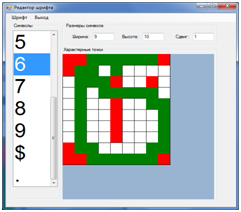
В ручную описывать списки точек для каждого символа не хотелось, поэтому я написал утилиту которая автоматически импортирует из заданной директории все файлы изображений и по названию файла и заданному цвету фона сама создает эти списки. Конечно в большинстве случаев будет желательна ручная корректировка. Так как все пиксели изображения раскидываются по спискам точек фона и точек символа. В большинстве случаев такой точности не надо. Достаточно указать по 10-20 точек из каждого списка для однозначного определения символа. Например для моего примера для символа ‘6’ хватило следующих списков пикселей (красный – фон, зеленый – символ, белый – не проверяется). Первый скриншот — символ описан утилитой, второй — после ручного редактирования. Распознаются они одинаково. Можно было сделать еще меньше характерных точек.

Так же была создана утилита для проверки работы созданного с помощью предыдущей утилиты файла шрифта.
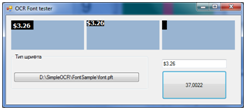
Распознавание 5 символов с учетом кроппинга (обрезания изображения до границ символов) заняло 37 мсек. Для полного алфавита время распознавания будет само-собой больше.
Библиотеку с классами распознавателя, утилиту для создания и редактирования файлов шрифтов и проверки на изображении, примеры изображений шрифта, а так же исходники всего этого для Visual Studio 2010 можно загрузить с mediafire.com.
Или с GitHub.com
Для обрезания изображения по краям используется библиотека AForge .NET так как метод Bitmap.Clone очень медленно работает. Буду рад если мои наработки пригодятся кому-нибудь кроме меня.
Tessnet2 и MODI
Естественно для начала я поискал готовые решения. Первое что выдал гугл — библиотека Tesseract, а точнее ее обертка под .NET – под названием Tessnet2. К сожалению при детальном изучении оказалось что она мне не подходит. Во второй версии Tesseract довольно много утечек памяти, что мне не подходило, так как после 10 минут работы программы с использованием Tessnet2 приложение вылетало с OutOfMemoryException. На странице Tesseract написано, что в третьей версии утечек не должно быть, но и рабочей обертки для Tesseract3 я не нашел.
Так же мне не подошло средство MODI (Microsoft Office Document Imaging) – так как распознает только файлы (нельзя передать ему экземпляр класса Bitmap для распознавания).
После непродолжительного поиска в гугле других бесплатных библиотек распознавания символов под .NET и проблем с ними связанных, я решил что проще будет сделать свою маленькую библиотеку как раз для таких случаев. Тем более задача довольно интересная.
Что мы имеем:
- Символы никак не искажаются. То есть для распознавания капчи использовать не получится
- Набор распознаваемых символов постоянный и для каждого символа мы имеем файл с его изображением
- Небольшое количество символов для распознавания. Чем больше символов – тем дольше распознает
Идея
Что я хотел получить в итоге? Получить класс, методу которого можно передать изображение, специальный файл с набором распознаваемых символов, и на выходе получить распознанную строку. Примерно так:
var playerStacks = new OCRReader(OCRFont.Load("MyFont.pft")), Color.Black, useForeColor: false);
var stackString = playerStacks.Recognize(imageToRecognition);Еще подумалось было бы неплохо иметь утилиты для создания таких файлов шрифтов и для проверки созданного шрифта на конкретном изображении. Утилиты исключительно для удобства. Все действия которые можно сделать с помощью утилит, можно сделать и в коде.
Реализация
Вся функциональность распределена между тремя классами OCRSymbol, OCRFont и OCRReader.
OCRSymbol – описывает символ: его название, ширину и высоту, сдвиг символа вниз относительно самого высокого символа из всего набора, списки точек характерных для символа и точек составляющих фон.
OCRFont – набор символов, сериализуется с помощью BinaryFormater.
OCRReader – координирует считывание символов один за другим. Так же задает стратегию считывания. Дело в том, что при создании экземпляра этого класса мы можем задать цвет. Этот цвет будет использован либо как цвет фона (все что не этот цвет, то символ), либо как цвет символа (все что не этот цвет – фон). Это надо для случаев когда в фоне используется больше одного цвета, либо когда символ нарисован более чем одним цветом.
Случай когда символ нарисован более чем одним цветом (черный фон, все остальное символ)

Случай, когда фон не одноцветный (фон – зеленый градиент, символы нарисованы белым цветом)

Алгоритм распознавания очень простой. Каждый символ описывается двумя универсальными списками List. Первый – точки, которые должны присутствовать в символе (Good), второй – которые не должны, то есть фон (Bad). При сравнении с очередным символом сначала проходится список точек фона, если при проверке очередной точки соответствующая точка в распознаваемом изображении оказывается не фоном (цвет фона задается при создании OCRReader), цикл заканчивается и переходим к сравнению со следующим символом. Если список точек фона успешно пройден, то аналогично прогоняем через список точек символа. Любое несовпадение – переходим к сравнению со следующем символом. Если все проверки прошли успешно, значит мы распознали наш символ и можем переходить к распознаванию следующего.
Дополнительные утилиты
В ручную описывать списки точек для каждого символа не хотелось, поэтому я написал утилиту которая автоматически импортирует из заданной директории все файлы изображений и по названию файла и заданному цвету фона сама создает эти списки. Конечно в большинстве случаев будет желательна ручная корректировка. Так как все пиксели изображения раскидываются по спискам точек фона и точек символа. В большинстве случаев такой точности не надо. Достаточно указать по 10-20 точек из каждого списка для однозначного определения символа. Например для моего примера для символа ‘6’ хватило следующих списков пикселей (красный – фон, зеленый – символ, белый – не проверяется). Первый скриншот — символ описан утилитой, второй — после ручного редактирования. Распознаются они одинаково. Можно было сделать еще меньше характерных точек.

Так же была создана утилита для проверки работы созданного с помощью предыдущей утилиты файла шрифта.
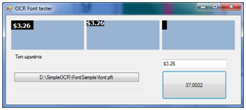
Распознавание 5 символов с учетом кроппинга (обрезания изображения до границ символов) заняло 37 мсек. Для полного алфавита время распознавания будет само-собой больше.
Исходники
Библиотеку с классами распознавателя, утилиту для создания и редактирования файлов шрифтов и проверки на изображении, примеры изображений шрифта, а так же исходники всего этого для Visual Studio 2010 можно загрузить с mediafire.com.
Или с GitHub.com
Заключение
Для обрезания изображения по краям используется библиотека AForge .NET так как метод Bitmap.Clone очень медленно работает. Буду рад если мои наработки пригодятся кому-нибудь кроме меня.










