 В последнее время на Хабре появилось, а также существует много содержательных статей, описывающих работу и принцип понятия “нейронная сеть”, но, к сожалению, как всегда очень мало описания и разбора полученных практических результатов или их не получения. Я думаю, что многим, как и мне удобней, проще и понятней разбираться на реальном примере. Поэтому в данной статье постараюсь описать почти пошаговое решение задачи распознавания букв латинского алфавита + пример для самостоятельного исследования. Распознавание цифр с помощью однослойного персептрона уже сделано, теперь давайте еще разберёмся и научим компьютер распознавать буквы.
В последнее время на Хабре появилось, а также существует много содержательных статей, описывающих работу и принцип понятия “нейронная сеть”, но, к сожалению, как всегда очень мало описания и разбора полученных практических результатов или их не получения. Я думаю, что многим, как и мне удобней, проще и понятней разбираться на реальном примере. Поэтому в данной статье постараюсь описать почти пошаговое решение задачи распознавания букв латинского алфавита + пример для самостоятельного исследования. Распознавание цифр с помощью однослойного персептрона уже сделано, теперь давайте еще разберёмся и научим компьютер распознавать буквы.Наша проблема
В вкратце скажу, что нейронные сети вообще позволяют решать очень большой круг практических задач, в частности, задачи распознавания. В большинстве случаев последние имеют «шаблонный» характер. Например, система, которая «читает» банковские чеки, по эффективности, в несколько раз превосходит оператора. В задачах подобного плана применение нейронных сетей оправдано и в значительной степени экономит средства и ресурсы.
Определимся с тем, что мы должны разобрать, понять и сделать. Нам необходимо построить экспертную систему, которая сможет распознавать буквы латинского алфавита. Для этого требуется разобраться с возможностями нейронных сетей (НС) и построить такую систему, которая сможет распознавать буквы латинского алфавита. Детально с теорией нейронных сетей можно познакомиться по ссылкам, приведенным в конце статьи. В данной статье не найти описания теории (математики) работы НС или описания команд при работе с MATLAB (ну только если по ссылкам в конце статьи), это остается на вашей совести. Целью статьи ставится задача показать и рассказать применение нейронной сети для практической задачи, показать результаты, наткнутся на подводные камни, постараться показать, что возможно выжать из нейронной сети, не вдаваясь в подробности, как она реализована, для остального есть специализированная литература, от которой все равно не убежать.
Попробуем разобраться с возможностями при использовании нейронной сети с обратным распространением ошибки в целях распознавания букв латинского алфавита. Алгоритм будем реализовывать в программной среде инженерного математического пакета MATLAB, а именно понадобится мощь Neural Network Toolbox.
Что дано
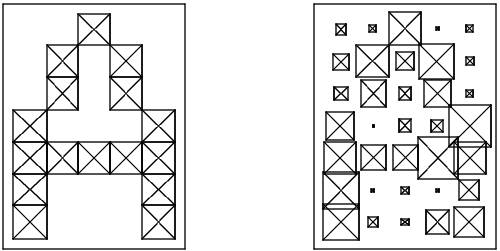
Необходимо разобраться с входными данными. Все мы представляем, что собой представляют буквы, как они выглядят на мониторе в книге и т.п. (как, например, представлено на рисунке ниже).

В реальности часто приходится работать не с идеальными буквами, как показано выше, а чаще всего как показано ниже, то есть вносятся искажения в символы.

Теперь вернемся к проблеме представления изображения, понятного для нейронной сети. Понятно, что каждая буква на изображение может быть представлена как матрица с определенными значениями элементов, которые четко могут определить букву. То есть представление символа латинского алфавита удобно формализовать матрицей из n строк и m столбцов. Каждый элемент такой матрицы может принимать значения в диапазоне [0, 1]. Так, символ A в таком формализованном виде будет выглядеть следующим образом (слева — без искажений, справа — с искажениями):
Не много представив происходящее в голове, приступим к реализации этого в MATLAB. В данном пакете уже предоставлен латинский алфавит, даже есть демо-пример работы с ним, но с него возьмем только алфавит. Поэтому можно воспользоваться их данными, а можно даже нарисовать все буквы самому, это по желанию.
MATLAB предлагает символы, формализуемые матрицей из 7 строк и 5 столбцов. Но такую матрицу нельзя просто так подать на вход нейронной сети, для этого необходимо еще собрать 35 — элементный вектор.
Для совместимости с различными версиями и удобства я сохранил матрицы символов в файл (а так можно использовать функцию prprob, она загрузит в рабочую область алфавит).
Из теории известно, что нам надо входные данные и выходные данные (targets, целевые данные) для обучения сети. Целевой вектор будет содержать 26 элементов, где один из элементов имеет значение 1, а все остальные элементы равны 0, номер элемента содержащего единицу кодирует соответствующую букву алфавита.
Подведя итог, на вход нейронной сети подается входной 35-элементный вектор, который сопоставляется с соответствующей буквой из 26-элементного выходного вектора. Выходом НС является 26-элементный вектор, в котором только один элемент, который кодирует соответствующую букву алфавита, равен 1. Разобравшись с созданием интерфейса для работы с НС приступим к её созданию.
Построение сети
Построим нейронную сеть, которая включает в себя 35 входов (потому что вектор состоит из 35 элементов) и 26 выходов (потому что букв 26). Данная НС является двухслойной сетью. Функцией активации поставим логарифмическую сигмоидную функцию, которую удобно использовать, потому что выходные векторы содержат элементы со значениями в диапазоне от 0 до 1, что потом удобно перевести в булеву алгебру. На скрытый уровень выделим 10 нейронов (потому что просто так, можно любое значение, дальше проверим, а сколько их надо). Если Вам, что-то не понятно из выше написанного про построение сети, прочитайте, пожалуйста, про это в литературе (нужные понятия, если собираетесь работать с НС). Схематически рассматриваемую сеть можно представить следующей схемой:
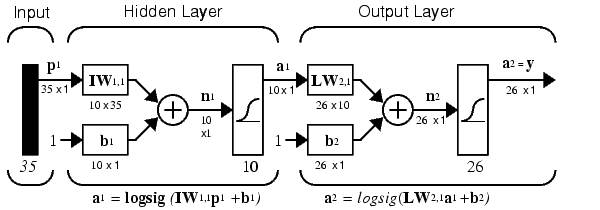
А если записать в синтаксисе скриптового языка MATLAB это все, то получим:
- S1 = 10; % количество нейронов на скрытом слое
- [S2,Q] = size(targets); % количество нейронов на втором слое (количество выходов сети)
- P = alphabet; % входная матрица, содержащая информацию о буквах
- % создаем новую сеть с использованием диалогового окна
- net = newff(minmax(P), % матрица минимальных и максимальных значений строк входной матрицы
- [S1 S2], % количество нейронов на слоях
- {’logsig’ ’logsig’}, % функция активации
- ’traingdx’ % алгоритм подстройки весов и смещений (обучающий алгоритм)
- );
Обучение сети
Теперь, когда НС создана, необходимо её обучить, потому что она как маленький ребенок ничего не знает, полностью чистый лист. Нейронная сеть обучается с помощью процедуры обратного распространения – распространение сигналов ошибки от выходов НС к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы (существуют еще способы обучения, данный считается самый основной, а все остальные как модификации).
Для создания нейронной сети, которая может работать с зашумленными входными данными, необходимо обучить сеть, подавая на вход данные, как с шумом, так и без. Для этого необходимо сначала обучить сеть, подавая данные без шумовой составляющей. Затем, когда сеть обучим на идеальных данных, произведем обучение на наборах идеальных и зашумленных входных данных (это как убедимся дальше, очень важно, потому что такое обучение повышает процент правильного распознавания букв).
Для всех тренировок используется функция traingdx – функция тренировки сети, которая модифицирует значения весов и смещений по методу градиентного спуска с учетом моментов и с применением адаптивного обучения.
Сначала необходимо обучить сеть на не зашумленных данных, то есть, начиная с простого. В принципе порядок обучения не особо важен, но часто меняя порядок, можно получить различное качество адекватности НС. Затем для возможности сделать нейронную систему, которая не будет чувствительна к шуму, обучим сеть двумя идеальными копиями и двумя копиями, содержащими шум (добавляется шум с дисперсией 0,1 и 0,2). Целевое значение, поэтому будет содержать 4 копии целевого вектора.
После завершения обучения с зашумленными входными данными, необходимо повторить обучение с идеальными входными данными, для того чтобы нейронная сеть успешно справлялась с идеальными входными данными. Куски кода не привожу, потому что они очень просты, используется одна функция train, которую легко применить.
Тестирование сети
Самый интересный и значащий этап, что же мы получили. Для этого я приведу графики зависимости с комментариями.
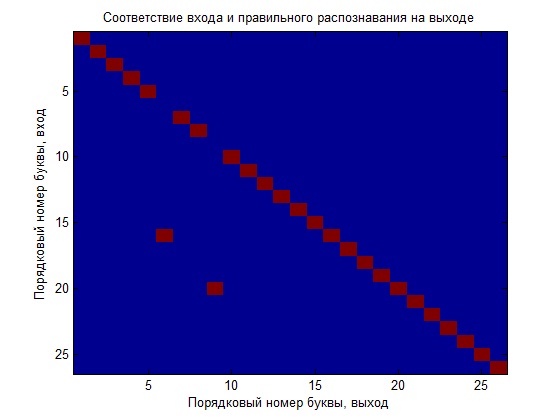
Сначала обучили сеть только на идеальных данных и теперь посмотрим, как она справляется с распознаванием. Для наглядности буду строить график, иллюстрирующий вход выходное соотношение, то есть номер буквы на входе должен соответствовать номеру буквы на выходе (идеальный распознаванием будет тот случай, когда получим диагональ квадранта на графике).

Как видно, что сеть плохо справилась с задачей, можно конечно поиграться с параметрами обучения (что желательно сделать) и это даст лучший результат, но мы сделаем еще сравнение, создадим новую сеть и обучим её зашумленными данными, а потом сравним полученные НС.
А сейчас вернемся к вопросу, а сколько же нейронов в скрытом слое должно быть. Для этого построим зависимость, наглядно показывающую соотношение нейронов в скрытом слое и процент ошибочного распознавания.

Как видно, с увеличением количества нейронов, можно добиться 100 % распознавания входных данных. Так же повышением вероятности правильного распознавания будет повторное обучение ране обученной нейронной сети большим количеством данных. После такого этапа нетрудно заметить, что возрастает процент правильного распознавания букв. Правда все хорошо работает до определенного момента, потому что видно при количестве больше 25 нейронов сеть начинает допускать ошибки.
Помните, что мы собрались обучить еще одну сеть, используя помимо идеальных данных, ещё и зашумленные данные и сравнить. Так вот посмотрим на то какая сеть лучше, исходя из полученных результатов на графике ниже.
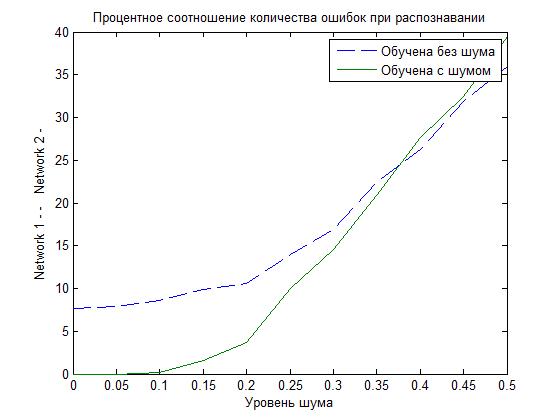
Как видно, что при не значительном шуме НС, которая была обучена искаженными данными, справляется гораздо лучше (процент ошибочного распознавания ниже).
Подведение итогов
Постарался не томить подробностями и мелочами, попытался организовать «мурзилку» (журнал с картинками), чтоб просто понять, что такое применение НС.
По поводу полученных результатов то они указывают, на то, что для увеличения количества правильного распознавания необходимо больше времени тренировать (обучать) нейронную сеть и увеличивать количество нейронов, находящихся в скрытом слое. Если есть возможность, то увеличить разрешение входных векторов, например, букву формализует матрица 10х14. Самое важное, то, что в процессе обучения необходимо использовать большее количество наборов входных данных, по возможности с большим зашумлением полезной информации.
Ниже приведен пример, в котором проделано, все что описано и приведено в статье (даже чуть больше). Пытался рассказать, что-то полезное и не грузить какими-то непонятными формулами. Планируются еще статьи, но все зависит от ваших пожеланий.
Пример и литература
CharacterRecognition.zip
Подборка статей по нейронным сетям
Описание нейросетевых алгоритмов







