XSD — это язык описания структуры XML документа. Его также называют XML Schema. При использовании XML Schema XML-парсер может проверить не только правильность синтаксиса XML документа, но также его структуру, модель содержания и типы данных. Многие так или иначе сталкивались с процедурой полной валидации, обеспечивающей соответствие документа заданной схеме или сообщающей о возможных ошибках. В данной статье речь пойдет о частичной валидации, кроме вышеописанного, позволяющей конструировать валидные документы «на лету». Мы разберемся, какие возможности может предоставить такой подход и способы его реализации.
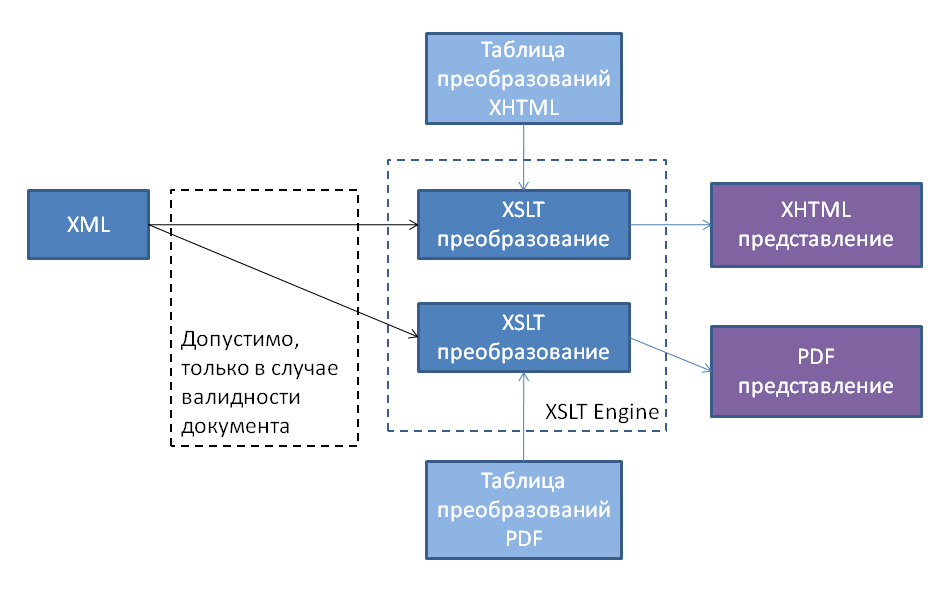
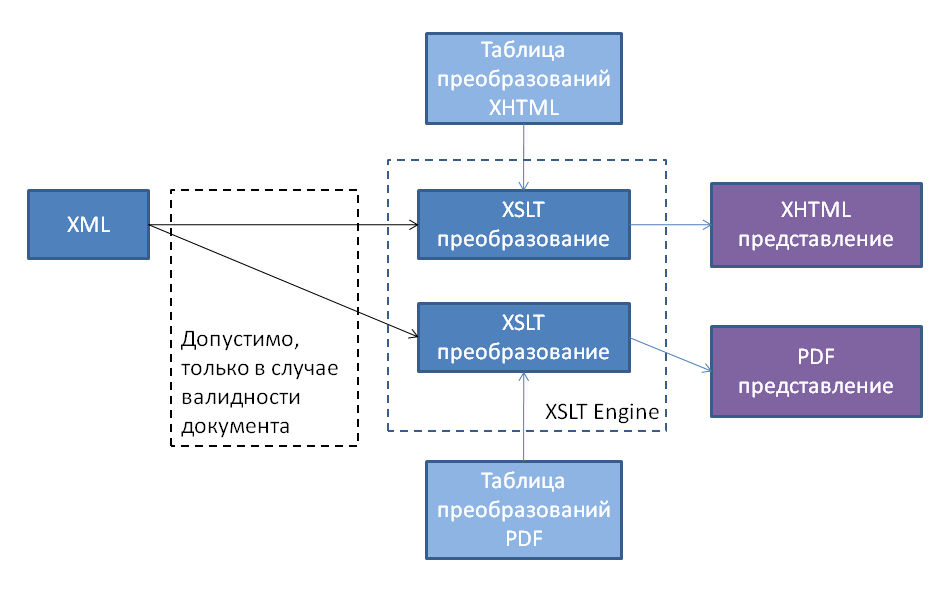
Зачем вообще может понадобиться конструировать документ, обладающий заданными свойствами, и какими свойствами мы можем управлять? На первый вопрос ответ практически очевиден; большинство документов не являются просто текстом, а наделены некоторой семантикой. XML решает вопрос синтаксического представления, а схема – частично решает вопрос семантического значения. Благодаря соответствию документа схеме, можно выполнять над ним набор предопределенных действий, допустимых для целого класса валидных документов, будь то представление в другом формате, экспорт значимой части информации для конкретной задачи, импорт новой информации с учетом глобальных ограничений. Наиболее часто применяемый механизм в таком случае – это XSLT преобразование, смысл которого можно проиллюстрировать следующей диаграммой:
На второй вопрос полностью ответит спецификация схемы, а мы остановимся лишь на самых важных пунктах, которые дают представление о возможностях схем. Итак, схема позволяет:
В качестве простого примера можно привести оглавление статьи – схемой можно задать семантику данных «название – страница», проконтролировать, что страницы идут по возрастанию, что нет одинаковых названий, что предопределенный элемент «Введение» идет до «Списка литературы» и обязателен, если есть элемент «Заключение». Наиболее сложным и мощным примером являются XML-базы данных, где и типизация и валидность данных определяются исключительно схемами.
Часто возникает желание модифицировать документ, уже отвечающий выбранной схеме, таким образом, чтобы он не потерял валидность. Здесь речь идет и о автоматических модификациях, например добавление веб-агентами (агрегаторами) информации в документ или модифицирующие запросы в XML-базу данных, так и о ручной модификации, скажем, в визуальном XML-редакторе. Операция полной валидации для больших документов может занимать существенное время, десятки секунд и более, что в целом препятствует использованию подхода «атомарное изменение – проверка – отказ/разрешение». А для визуальных редакторов хотелось бы еще больше – иметь возможность не только проверить атомарное действие, а предложить все допустимые по схеме варианты модификации конкретного узла. Однако, хорошие XML-редакторы умеют это делать, и мы попробуем разобраться каким образом у них это получается.
W3C XML схема является развитием идеи XML DTD (Document Type Definition). Оба стандарта описывают схему документа посредством набора объявлений (объектов-параметров, элементов и атрибутов), которые описывают его класс (или тип) с точки зрения синтаксических ограничений этого документа. DTD рассматривает набор регулярных выражений над атомарными термами или элементами словаря типов. Каждый тип строится на основе других типов, атомарных термов и операций альтернативы “|”, конкатенации “,” и операторов “?”, “+”, “*”, означающих опциональность, наличие одного-или-более или нуля-или-более элементов. XML схема отличается от XML DTD синтаксисом, и расширяет функционал DTD в трех направлениях:
Алгоритмически валидация по схеме является более сложной задачей, чем соответствующая задача для DTD [1], но более поздний стандарт описания XML схем дополнен правилом существенно облегчающим валидацию.
Правило Unique Particle Attribution (однозначность определения частиц) требует, чтобы каждый элемент документа однозначно соответствовал ровно одной частице xsd:element или xsd:any в модели содержимого родительского элемента [2].
Вообще говоря, правило Unique Particle Attribution (UPA) не является жестким требованием к структуре XML схем, а только крайне желательной рекомендацией и часть используемых схем ему не соответствует. Рассмотрим простейший пример, иллюстрирующий нарушение правила однозначности определения частиц.
Определим схему следующим образом:
Тогда XML документ, состоящий из одного элемента , доказывает нарушение правила однозначности; элемент может быть сопоставлен и ветке xsd:elment и xsd:any одновременно.
К счастью, большая часть готовых схем следуют правилу UPA. Дальнейшие рассуждения будут верны только в случае соответствия схемы правилу UPA, но в целом небольшими модификациями рассуждения можно добиться корректности и на не совместимых с UPA-схемах, за счет потери скорости.
Для начала определим элементарные изменения структуры, которые мы и будем проверять на корректность:
Теперь опишем модель содержимого сложного типа схемы:
Можно переходить непосредственно к алгоритму валидации. Первое необходимое действие – построение соответствия «тип схемы» -> «автомат, который умеет проверять потомков элемента этого типа на валидность». Задача сводится к двум рекурсивным действиям:
1. Построение недетерминированного конечного автомата (NFA) с заданным конечным состоянием S по заданной частице:
a. Установим начальное состояние n на S;
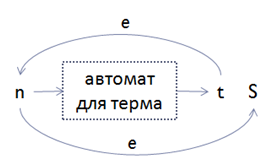
b. Если MaxOccurs частицы равен бесконечности (inf):
• Добавим новое промежуточное состояние t; получаемое из преобразования терма в NFA (случай 2); добавим эпсилон-ребра из t в n и из n в S:
c. Если MaxOccurs частицы – число m:
• Строим цепочку из (MaxOccurs-MinOccurs) преобразований терма, начиная из конечного состояния S, добавляя эпсилон-ребро из промежуточного состояния на каждом шаге в конечное состояние S;
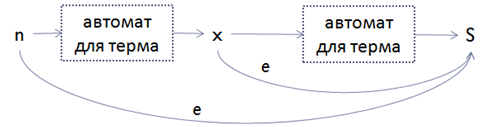
Например, для MaxOccurs=4 и MinOccurs=2 получаем следующий автомат:
d. Достраиваем minOccurs копий преобразования терма от нового начального состояния n, до начального состояния, полученного на предыдущих шагах.
2. Построение недетерминированного конечного автомата с заданным принимающим состоянием S по заданному терму:
a. Если терм – шаблон (any):
• Создаем новое состояние b, и соединяем его с S ребром, помеченным типом терма, возвращаем b;
b. Если терм – описание элемента:
• Создаем новое состояние b, затем для каждого элемента группы подстановки создаем ребро из b в S, помеченное типом элемента и возвращаем b;
c. Если терм – выбор (choice):
• Создаем новое состояние b, для каждого элемента выбора создаем автомат (случай 1) и соединяем его эпсилон-ребрами с состоянием b и состоянием S. Возвращаем b;
d. Если терм – последовательность (sequence):
• Для каждого элемента выбора создаем автомат (случай 1) и соединяем полученные автоматы в обратном порядке, начиная с состояния S, и возвращаем первое состояние в цепочке;
Затем применим алгоритм Томпсона к полученным NFA [3], для построения детерминированных автоматов. Алгоритм Томпсона можно применить в тех же случаях, что и алгоритм построения детерминированного автомата Ахо и Ульмана, основанный на сворачивании одинаково помеченных не-эпсилон ребер [4]. Однако в ряде случаев по исходному автомату (созданному на шагах 1–2) алгоритм Ахо и Ульмана не сможет построить детерминированный автомат.
Это происходит когда существуют два исходящих ребра из одной вершины, такие что:
Нетрудно показать, что каждый случай отвечает нарушению ограничения UPA (третий случай уже был рассмотрен в примере схемы нарушающей правило однозначности определения частиц). Таким образом, эти пункты не помешают корректности решения, и на выходе алгоритма мы всегда получим детерминированный конечный автомат, валидирующий содержание элементов соответствующего типа.
Применим предложенный алгоритм к каждому типу схемы и получим соответствие тип -> автомат, который умеет проверять потомков элемента этого типа.
Осталось решить последнюю задачу – выбор нужного конечного автомата при валидации операции над заданным элементом дерева. С этим нам поможет структура привязки типов валидации (PSVI, Post-Schema-Validation Infoset), порождаемая почти любым (например, MSXML или libxml) полным валидатором. Для любого элемента дерева она указывает на соответствующий ему тип в описании схемы – в точности тот, по которому мы порождали нужный автомат.
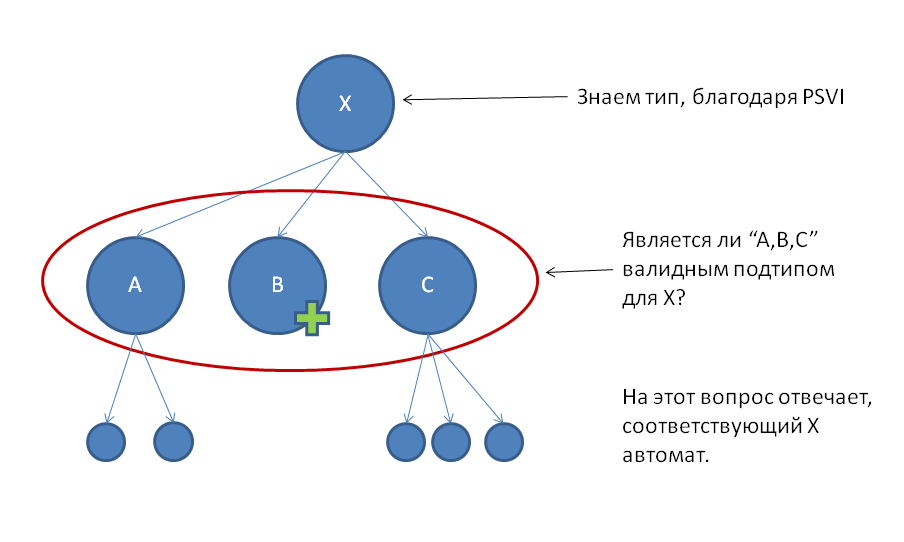
В нашем случае реализация структуры PSVI представляется ссылкой на тип схемы для каждого элемента дерева.
Операции MOVE и REMOVE не меняют тип операнда (поэтому не требуют изменения структуры PSVI), а операция ADD вместе с добавлением элемента x, потребует добавления в структуру PSVI типа x. Таким образом, вместе с изменением структуры мы меняем и информационное множество привязки типов валидации, решая задачу частичной валидации и поддерживая дерево PSVI без вызова внешнего валидатора.
Вообще говоря, непосредственного сравнения не будет – ведь мы описали надстройку, решающую частную задачу (операции ADD/REMOVE/MOVE) в частном случае (соответствие UPA), но хочется показать что в этом случае она дает существенный прирост скорости, относительно попытки использовать полную валидацию. В качестве эталонного валидатора, генерирующего PSVI был выбран MSXML6, поэтому и сравнивать будем с его временем работы.
Таким образом, мы получили вполне допустимое среднее время ожидания проверки, позволяющее реализовать механизм Drag’n’Drop «на лету» в визуальном редакторе, и обеспечивающее хорошее количество запросов в секунду для возможной XML-базы данных.
[1] XML Schema Validator. Thompson, Henry S. and R. Tobin, W3C and University of Edinburgh, 2003.
[2] XML Schema Part 1: Structures. Henry S. Thompson, David Beech, Murray Maloney, Noah Mendelsohn, editors. W3C Recommendation, 2001.
[3] Regular Expression Matching Can Be Simple And Fast. Russ Cox, 2007.
[4] Принципы построения компиляторов. А. Ахо. Д. Ульман. М.: Мир, 1977.
Основная цель
Зачем вообще может понадобиться конструировать документ, обладающий заданными свойствами, и какими свойствами мы можем управлять? На первый вопрос ответ практически очевиден; большинство документов не являются просто текстом, а наделены некоторой семантикой. XML решает вопрос синтаксического представления, а схема – частично решает вопрос семантического значения. Благодаря соответствию документа схеме, можно выполнять над ним набор предопределенных действий, допустимых для целого класса валидных документов, будь то представление в другом формате, экспорт значимой части информации для конкретной задачи, импорт новой информации с учетом глобальных ограничений. Наиболее часто применяемый механизм в таком случае – это XSLT преобразование, смысл которого можно проиллюстрировать следующей диаграммой:
На второй вопрос полностью ответит спецификация схемы, а мы остановимся лишь на самых важных пунктах, которые дают представление о возможностях схем. Итак, схема позволяет:
- Строго контролировать типизацию данных узлов и атрибутов;
- Определять порядок следования узлов, следить за наличием обязательных узлов и атрибутов;
- Требовать уникальность элементов в заданном контексте;
- Создавать вариантные узлы, требующие наличия одних атрибутов или других, в зависимости от контекста;
- Требовать выполнения определенного предиката на группе узлов или атрибутов.
В качестве простого примера можно привести оглавление статьи – схемой можно задать семантику данных «название – страница», проконтролировать, что страницы идут по возрастанию, что нет одинаковых названий, что предопределенный элемент «Введение» идет до «Списка литературы» и обязателен, если есть элемент «Заключение». Наиболее сложным и мощным примером являются XML-базы данных, где и типизация и валидность данных определяются исключительно схемами.
Часто возникает желание модифицировать документ, уже отвечающий выбранной схеме, таким образом, чтобы он не потерял валидность. Здесь речь идет и о автоматических модификациях, например добавление веб-агентами (агрегаторами) информации в документ или модифицирующие запросы в XML-базу данных, так и о ручной модификации, скажем, в визуальном XML-редакторе. Операция полной валидации для больших документов может занимать существенное время, десятки секунд и более, что в целом препятствует использованию подхода «атомарное изменение – проверка – отказ/разрешение». А для визуальных редакторов хотелось бы еще больше – иметь возможность не только проверить атомарное действие, а предложить все допустимые по схеме варианты модификации конкретного узла. Однако, хорошие XML-редакторы умеют это делать, и мы попробуем разобраться каким образом у них это получается.
Необходимая информация о XML схеме
W3C XML схема является развитием идеи XML DTD (Document Type Definition). Оба стандарта описывают схему документа посредством набора объявлений (объектов-параметров, элементов и атрибутов), которые описывают его класс (или тип) с точки зрения синтаксических ограничений этого документа. DTD рассматривает набор регулярных выражений над атомарными термами или элементами словаря типов. Каждый тип строится на основе других типов, атомарных термов и операций альтернативы “|”, конкатенации “,” и операторов “?”, “+”, “*”, означающих опциональность, наличие одного-или-более или нуля-или-более элементов. XML схема отличается от XML DTD синтаксисом, и расширяет функционал DTD в трех направлениях:
- Шаблоны (any, anyType, anyAttribute), позволяющие использовать любой элемент, соответствующий заданному пространству имен;
- Группы подстановки, определяющие набор типов, который может быть использован вместо конкретного описания типа;
- Количество повторений, определяющее для каждого элемента минимальное и максимально допустимое количество его вхождений в тип (обобщение операторов Клини: "*", "+").
Алгоритмически валидация по схеме является более сложной задачей, чем соответствующая задача для DTD [1], но более поздний стандарт описания XML схем дополнен правилом существенно облегчающим валидацию.
Правило Unique Particle Attribution (однозначность определения частиц) требует, чтобы каждый элемент документа однозначно соответствовал ровно одной частице xsd:element или xsd:any в модели содержимого родительского элемента [2].
Вообще говоря, правило Unique Particle Attribution (UPA) не является жестким требованием к структуре XML схем, а только крайне желательной рекомендацией и часть используемых схем ему не соответствует. Рассмотрим простейший пример, иллюстрирующий нарушение правила однозначности определения частиц.
Определим схему следующим образом:
<xsd:element name="root">
<xsd:complexType>
<xsd:choice>
<xsd:element name="e1"/>
<xsd:any namespace="##any"/>
</xsd:choice>
</xsd:complexType>
</xsd:element>
Тогда XML документ, состоящий из одного элемента , доказывает нарушение правила однозначности; элемент может быть сопоставлен и ветке xsd:elment и xsd:any одновременно.
К счастью, большая часть готовых схем следуют правилу UPA. Дальнейшие рассуждения будут верны только в случае соответствия схемы правилу UPA, но в целом небольшими модификациями рассуждения можно добиться корректности и на не совместимых с UPA-схемах, за счет потери скорости.
Построение валидатора
Для начала определим элементарные изменения структуры, которые мы и будем проверять на корректность:
- ADD: создание подэлемента с типом x на позиции n;
- REMOVE: удаление подэлемента, стоящего на позиции n;
- MOVE: перенос элемента с позиции n на позицию m (хоть перенос и сводится к выполнению удаления и добавления элементов, но промежуточное состояние может нарушать валидность документа).
Теперь опишем модель содержимого сложного типа схемы:
- Частица:
• MinOccurs – минимальное число повторений терма (если 0, то терм становится опциональным);
• MaxOccurs – максимальное число повторений терма (допустима бесконечность – inf).
• Терм: описание элемента, шаблон, последовательность или выбор;
- Описание элемента (typedef):
• Локальное имя;
• Имя пространства имен (может быть опущено, тогда элемент считается допустимым в любом пространстве имен);
• Группа подстановки – множество всех элементов, принимаемых в выражениях содержащих typedef;
- Шаблон (any):
• Имя пространства имен, допустимого для элемента подстановки (может отсутствовать);
- Последовательность (sequence):
• Последовательное перечисление допустимых частиц;
- Выбор (choice):
• Множество допустимых частиц.
Можно переходить непосредственно к алгоритму валидации. Первое необходимое действие – построение соответствия «тип схемы» -> «автомат, который умеет проверять потомков элемента этого типа на валидность». Задача сводится к двум рекурсивным действиям:
1. Построение недетерминированного конечного автомата (NFA) с заданным конечным состоянием S по заданной частице:
a. Установим начальное состояние n на S;
b. Если MaxOccurs частицы равен бесконечности (inf):
• Добавим новое промежуточное состояние t; получаемое из преобразования терма в NFA (случай 2); добавим эпсилон-ребра из t в n и из n в S:
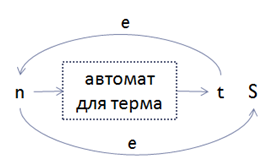
c. Если MaxOccurs частицы – число m:
• Строим цепочку из (MaxOccurs-MinOccurs) преобразований терма, начиная из конечного состояния S, добавляя эпсилон-ребро из промежуточного состояния на каждом шаге в конечное состояние S;
Например, для MaxOccurs=4 и MinOccurs=2 получаем следующий автомат:
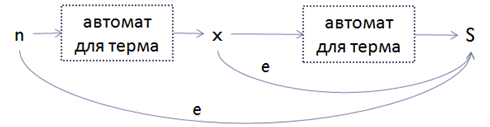
d. Достраиваем minOccurs копий преобразования терма от нового начального состояния n, до начального состояния, полученного на предыдущих шагах.
2. Построение недетерминированного конечного автомата с заданным принимающим состоянием S по заданному терму:
a. Если терм – шаблон (any):
• Создаем новое состояние b, и соединяем его с S ребром, помеченным типом терма, возвращаем b;
b. Если терм – описание элемента:
• Создаем новое состояние b, затем для каждого элемента группы подстановки создаем ребро из b в S, помеченное типом элемента и возвращаем b;
c. Если терм – выбор (choice):
• Создаем новое состояние b, для каждого элемента выбора создаем автомат (случай 1) и соединяем его эпсилон-ребрами с состоянием b и состоянием S. Возвращаем b;
d. Если терм – последовательность (sequence):
• Для каждого элемента выбора создаем автомат (случай 1) и соединяем полученные автоматы в обратном порядке, начиная с состояния S, и возвращаем первое состояние в цепочке;
Затем применим алгоритм Томпсона к полученным NFA [3], для построения детерминированных автоматов. Алгоритм Томпсона можно применить в тех же случаях, что и алгоритм построения детерминированного автомата Ахо и Ульмана, основанный на сворачивании одинаково помеченных не-эпсилон ребер [4]. Однако в ряде случаев по исходному автомату (созданному на шагах 1–2) алгоритм Ахо и Ульмана не сможет построить детерминированный автомат.
Это происходит когда существуют два исходящих ребра из одной вершины, такие что:
- Их метки являются описаниями типов с одинаковыми локальными именами и названиями пространства имен;
- Их метки – это названия шаблонов, с перекрывающимся областями;
- Метка одного ребра – шаблон, другого – описание типа, оба лежат в одном пространстве имен, и описание типа входит в область шаблона.
Нетрудно показать, что каждый случай отвечает нарушению ограничения UPA (третий случай уже был рассмотрен в примере схемы нарушающей правило однозначности определения частиц). Таким образом, эти пункты не помешают корректности решения, и на выходе алгоритма мы всегда получим детерминированный конечный автомат, валидирующий содержание элементов соответствующего типа.
Применим предложенный алгоритм к каждому типу схемы и получим соответствие тип -> автомат, который умеет проверять потомков элемента этого типа.
Осталось решить последнюю задачу – выбор нужного конечного автомата при валидации операции над заданным элементом дерева. С этим нам поможет структура привязки типов валидации (PSVI, Post-Schema-Validation Infoset), порождаемая почти любым (например, MSXML или libxml) полным валидатором. Для любого элемента дерева она указывает на соответствующий ему тип в описании схемы – в точности тот, по которому мы порождали нужный автомат.

В нашем случае реализация структуры PSVI представляется ссылкой на тип схемы для каждого элемента дерева.
Операции MOVE и REMOVE не меняют тип операнда (поэтому не требуют изменения структуры PSVI), а операция ADD вместе с добавлением элемента x, потребует добавления в структуру PSVI типа x. Таким образом, вместе с изменением структуры мы меняем и информационное множество привязки типов валидации, решая задачу частичной валидации и поддерживая дерево PSVI без вызова внешнего валидатора.
Сравнение результатов
Вообще говоря, непосредственного сравнения не будет – ведь мы описали надстройку, решающую частную задачу (операции ADD/REMOVE/MOVE) в частном случае (соответствие UPA), но хочется показать что в этом случае она дает существенный прирост скорости, относительно попытки использовать полную валидацию. В качестве эталонного валидатора, генерирующего PSVI был выбран MSXML6, поэтому и сравнивать будем с его временем работы.
| Количество элементов структуры | Уровни вложенности | Количество типов схемы | Среднее время валидации MSXML6 | Среднее время валидации с использованием описанной надстройки |
| 32 | 4 | 16 | 10 ms | <1 ms |
| 32 | 4 | 40 | 16 ms | <1 ms |
| 120000 | 4 | 16 | 51 ms | <2 ms |
| 120000 | 4 | 40 | 62 ms | <2 ms |
| 120000 | 32 | 16 | 2300 ms | <5 ms |
| 120000 | 32 | 40 | 2600 ms | <6 ms |
Таким образом, мы получили вполне допустимое среднее время ожидания проверки, позволяющее реализовать механизм Drag’n’Drop «на лету» в визуальном редакторе, и обеспечивающее хорошее количество запросов в секунду для возможной XML-базы данных.
Ссылки
[1] XML Schema Validator. Thompson, Henry S. and R. Tobin, W3C and University of Edinburgh, 2003.
[2] XML Schema Part 1: Structures. Henry S. Thompson, David Beech, Murray Maloney, Noah Mendelsohn, editors. W3C Recommendation, 2001.
[3] Regular Expression Matching Can Be Simple And Fast. Russ Cox, 2007.
[4] Принципы построения компиляторов. А. Ахо. Д. Ульман. М.: Мир, 1977.







