Идут дни, требования к качеству видео постоянно растут. При этом ширина каналов и емкость носителей не могла бы поспевать за этим ростом, если бы не совершенствовались алгоритмы сжатия видео.
Далее пойдет речь именно о некоторых базовых понятиях сжатия видео. Некоторые из них несколько устарели или описаны слишком просто, но при этом дают минимальное представление о том, как все работает.
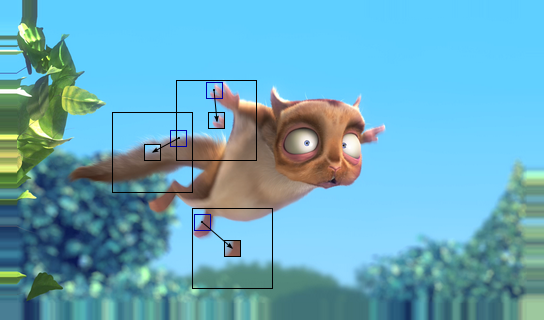
Поиск векторов движения для компенсации движения (-: Об этом далее...
Практически все знают, что любое видео – это множество статичных картинок, которые сменят друг друга во времени. Далее это упорядоченное множество мы будем называть видеопотоком. Они бывают разными, поэтому здесь крайне полезно провести небольшую классификацию:
Если мы будем передавать видео несжатым, то ни на что серьезное нам не хватит ни каналов связи, ни места для хранения данных. Пусть мы имеем HD поток с характеристиками:
1920x1080p, 24 к/с, RGB24 и подсчитаем “стоимость” такого потока.
1920*1080*24*24 = 1139 Мегабит/с, а если захотим записать 90 минутный фильм, то потребуется 90*60*1139 = 750 Гигабайт! Круто? Это при том, что видео фильма изумительного качества с тем же 1920x1080p на BluRay будет занимать 20 Гб, то есть разница почти в 40 раз!
Очевидно, что видео требует сжатия, особенно учитывая то, что можно сократить размер в 40 и более раз, оставив при этом зрителя в восторге.
Я постарался рассказать некоторые базовые понятия, не сильно нагружая техническими подробностями. Далее я расскажу о структуре кодеков, контейнеров и т.д. Для тех, кто серьезно интересуется сжатием и обработкой видеоданных существует сайт compression.ru, поддерживающийся родной лабораторией компьютерной графики и мультимедиа ВМК МГУ.
Продолжение следует…
Далее пойдет речь именно о некоторых базовых понятиях сжатия видео. Некоторые из них несколько устарели или описаны слишком просто, но при этом дают минимальное представление о том, как все работает.
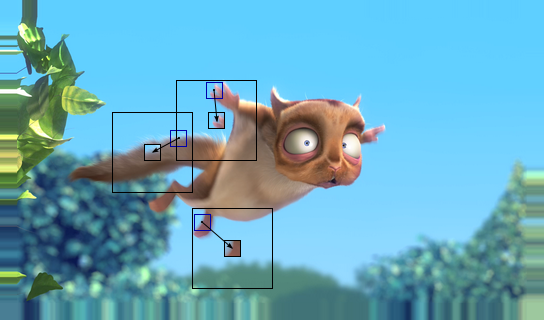
Поиск векторов движения для компенсации движения (-: Об этом далее...
Характеристики видеопотока
Практически все знают, что любое видео – это множество статичных картинок, которые сменят друг друга во времени. Далее это упорядоченное множество мы будем называть видеопотоком. Они бывают разными, поэтому здесь крайне полезно провести небольшую классификацию:
- Формат пикселя. Пиксель не дает нам никакой информации кроме его цвета. Однако восприятие цвета сильно субъективно и были приложены большие усилия для создания систем цветопредставления и цветопередачи, которые были бы приемлемы для большинства людей. Так цвет, видимый нами в реальном мире, является достаточно сложным по спектру частот света, что передать его в цифровом виде крайне сложно, а отобразить еще сложней. Однако было замечено, что все тремя точками в спектре можно достаточно точно приблизить отображаемый цвет к настоящему в метрике восприятия цвета обычным человеком. Эти три точки: красный, зеленый и синий. То есть их линейной комбинацией мы можем покрыть большую часть видимого спектра цветов. Поэтому самый простой способ представления пикселя: RGB24, где под компоненты Red, Green и Blue отводится ровно по 8 бит информации. И так мы можем передать 256 градаций каждого цвета и всего 16,777,216 всевозможных оттенков. Но на практике при хранении такое цветопредставление практически не используется, не только потому что мы тратим целых 3 байта на пиксель, но и по другим причинам, но об этом позже (про YV12).
- Размер кадра. Мы уже взяли и закодировали все пиксели видеопотока и получили огромный массив данных, но он неудобен в работе. Поначалу все очень просто, кадр характеризуется: шириной, высотой, размерами видимой части и форматом (об этом чуть позже). Тут наверняка многим покажутся знакомыми цифры: 640x480, 720x480, 720x576, 1280x720, 1920x1080. Почему? Да потому что, они фигурируют в разных стандартах, например разрешение 720x576 имеет большая часть европейских DVD. Нет, конечно, можно сделать видео размером 417x503, но не думаю, что в этом будет что-то хорошее.
- Формат кадра. Даже зная размеры кадра, мы не можем представить массив пикселей в более удобной форме, не имея информации о способе “упаковки” кадра. В простейшем случае ничего хитрого: берем строку пикселей и выписываем подряд биты каждого закодированного пикселя и так строчку за строчкой. То есть выписываем столько строк, сколько у нас высота по столько пикселей, сколько у нас ширина и все подряд, по порядку. Такая развертка называется прогрессивной (Progressive). Но может быть вы пытались смотреть телепередачи на компьютере без должных настроек и видели “эффект гребенки”, это когда один и тот же объект находится в разных положениях относительно четных и нечетных строк. Можно очень долго спорить о целесообразности чересстрочной (Interlaced) развертки, но факт, что она осталась как пережиток прошлого от традиционного телевидения (кому интересно почитайте про устройство кинескопа). Про методы устранения (деинтерлейсинга) этого неприятного эффекта сейчас говорить не буду. Отсюда и исходят магические обозначения: 576i, 720p, 1080i, 1080p, где указано количество строк (высота кадра) и тип развертки.
- Частота кадров. Одни из стандартных значений: 23.976, 24, 25 и 29.97 кадров в секунду. Например, 25 к/с используется в европейском телевидении, 29.97 в американском, а с частотой 24 к/с снимают на кинопленку. Но откуда взялись “странные” 23.976 и 29.97? Открою секрет: 23.976 = 24/1.001, а 29.97 = 30/1.001, то есть в стандарт американского телевещания NTSC заложен делитель 1.001. Соответственно при показе киноленты произойдет совсем небольшое замедление, которое не будет заметно зрителю, но если это музыкальный концерт, то скорость показа настолько критична, что лучше изредка пропускать кадры и опять же зритель ничего не заметит. Хотя я немного обманул, по американскому телевизору никогда не показывается “24” кадра в секунду, а показывается “30” чересстрочных кадров (и того 59.94 полукадра в секунду, что соответствует частоте их электросети), но они получаются “методом спуска” (3:2 pulldown). Суть метода состоит в том, что у нас есть 2 полных кадра и 5 полукадров, и мы информацией из первого кадра заполним первые 3 полукадра, а из второго оставшиеся 2. То есть последовательность полукадров такова: [1 top, 1 bottom], [1 top, 2 bottom], [2 top, 3 bottom], [3 top, 3 bottom], [4 top, 4 bottom] и т.д. Где top – верхние строки (поля, fields), а bottom нижние, то есть, нечетные и четные начиная сверху соответственно. Таким образом, пленочная картинка вполне смотрибельна на телевизоре, но на динамичных сценах заметны подергивания. Частота кадров может быть и переменной, но с этим связано много проблем, поэтому рассматривать этот случай не буду.
- Глобальные характеристики. Все вышерассмотренное относится к локальным свойствам, то есть тех, которые отражаются во время воспроизведения. Но длительность видеопотока по времени, объем данных, наличие дополнительной информации, зависимости и т.п. Например: видеопоток может содержать в себе один поток, отвечающий левому глазу, а другой поток некоторым образом будет хранить информацию об отличии потока правого глаза от левого. Так можно передавать стерео видео или всенародно известное “3D”.
Почему видео нужно сжимать?
Если мы будем передавать видео несжатым, то ни на что серьезное нам не хватит ни каналов связи, ни места для хранения данных. Пусть мы имеем HD поток с характеристиками:
1920x1080p, 24 к/с, RGB24 и подсчитаем “стоимость” такого потока.
1920*1080*24*24 = 1139 Мегабит/с, а если захотим записать 90 минутный фильм, то потребуется 90*60*1139 = 750 Гигабайт! Круто? Это при том, что видео фильма изумительного качества с тем же 1920x1080p на BluRay будет занимать 20 Гб, то есть разница почти в 40 раз!
Очевидно, что видео требует сжатия, особенно учитывая то, что можно сократить размер в 40 и более раз, оставив при этом зрителя в восторге.
На чем можно сэкономить?
- Кодирование цвета. Наверняка многие знают, что когда-то давно телевидение было черно-белым, но сегодняшнее телевидение целиком в цвете. Но черно-белый телевизор по-прежнему может показывать передачи. Дело в том, что в телесигнале яркость кодируется отдельно от цветных составляющих и представляется в формате YUV (подробнее на википедии). Где Y компонента – это яркость, а U и V – цветовые компоненты и все это вычисляется по “волшебной” формуле:
Y = 0.299 * R + 0.587 * G + 0.114 * B
U = -0.14713 * R - 0.28886 * G + 0.436 * B
V = 0.615 * R - 0.51499 * G - 0.10001 * B
Как видно, преобразование линейное и невырожденное. Следовательно, мы можем с легкостью получать обратно значения R, G и B. Допустим под хранение Y, U и V мы выделим по 8 бит, тогда было 24 бита на пиксель и так и осталось. Никакой экономии. Но человеческий глаз чувствителен к яркости, а вот к цвету он не сильно притязателен. Да и почти на всех изображениях цвета сменяют друг друга не так часто. Если мы условно разделим изображение на слои Y, U и V и яркостный слой оставим без изменений, а слои U и V в два раза сократим по высоте и в два раза по ширине и того в четыре раза. Если раньше на каждый пиксель тратили 24 бита, то теперь тратим 8*4+8+8=48 бит на 4 пикселя, то есть, грубо говоря, 12 бит на пиксель (именно поэтому данный формат кодирования называется YV12). За счет цветового прореживания мы сжали поток в два раза без особых потерь. Например, JPEG всегда выполняет подобное преобразование, но по сравнению с другими возможными артефактами прореживание цвета не несет никакого вреда. - Избыточность изображения. Здесь особо останавливаться не буду, поскольку здесь нет никаких отличий от алгоритмов сжатия изображений. Тот же JPEG сжимает изображение за счет его локальной избыточности методами дискретного косинусного преобразования (DCT) и квантования, о чем опять же можно прочитать на википедии. Обозначу лишь то, что встроенный в кодек алгоритм сжатия статичных изображений должен хорошо сжимать даже отдаленно напоминающее реальные изображения, скоро узнаете зачем.
- Межкадровая разность. Наверняка, любой, посмотрев любое видео, заметит, что изображения не меняются резко, а соседние кадры достаточно похожи. Конечно, резкие смены бывают, но они обычно происходят при смене сцен. И тут возникает проблема: как компьютер должен представлять все то многообразие возможных преобразований изображения? На помощь приходит алгоритм компенсации движения. Про него мной написана статья на википедии. Чтобы не производить копипаст, ограничусь лишь основными моментами. Изображение делится на блоки и в окрестности каждого из них ищется похожий блок на другом кадре (motion estimation), так получается поле векторов движения. А уже при компенсации (motion compensation) учитываются вектора движения, и создается изображение в целом похожее на исходный кадр.

Разница до компенсации движения

Разница между оригиналом и скомпенсированным кадрами
Здесь четко видно, что исходная межкадровая разность значительно больше, чем разность между исходным и скомпенсированным кадрами. С учетом объемов информации при сжатии изображений мы можем сохранить вектора движения почти бесплатно. Сделали это и потом сжали изображение скомпенсированной межкадровой разности алгоритмом сжатия статических изображений. А так как на второй картинке откровенное месиво, то алгоритм сжатия изображений должен корректно с такими вещами работать. В силу большой избыточности таких изображений они сжимают очень сильно. Но если кодек сжимает их слишком сильно, то и возникает эффект блочности. Старые алгоритмы никак не учитывают изменения объектов по яркости и именно поэтому по телевизору видно блочность президента при вспышках фотокамер. - Организация последовательностей кадров. В первую очередь кодек должен быть чувствителен к смене сцен. Определить это достаточно просто, так как компенсация движения отработает в этом случае безобразно. Кадр начала новой сцены логично сохранить “как есть”, поскольку он ни на что ранее встречавшееся не похож. Такие кадры называют опорными (I-frame). А далее идут кадры, к которым применялась компенсация движения, то есть они зависят от опорного кадра и друг от друга. Это могут быть P-frame или B-frame. Первые могут опираться только на предыдущие кадры, а последние могут на левого и правого соседа. I-кадр и все его зависимые образуют GOP (group of pictures). От использования би-кадров следует насколько преимуществ: быстрая навигация (потому что предыдущие би-кадры не нужно декодировать) и то, что они имеют самый маленький размер среди всех кадров фильма, ну и немного более низкое качество (но быстрое чередование с более качественными кадрами делает это малозаметным для зрителя).
- Избыточность выходных данных. Даже после выполнения всех сжимающих процедур поток коэффициентов имеет избыточность. Далее может применяться разные методы сжатия без потерь. В кодеке H.264, например, есть два варианта CABAC и CAVLC, реализующие арифметическое сжатие с мощной вероятностной моделью и реализующие Хаффмана с более простой моделью. ПО непонятным причинам компания Apple предпочитает последний вариант, хотя на хороших декодерах разница в быстродействии незначительна.


Вместо заключения
Я постарался рассказать некоторые базовые понятия, не сильно нагружая техническими подробностями. Далее я расскажу о структуре кодеков, контейнеров и т.д. Для тех, кто серьезно интересуется сжатием и обработкой видеоданных существует сайт compression.ru, поддерживающийся родной лабораторией компьютерной графики и мультимедиа ВМК МГУ.
Продолжение следует…







