При анализе производительности приложений с целью ее повышения, наиболее мощной из доступных является методика детального анализа циклов центрального процессора. Традиционный анализ завершения инструкций вряд ли поможет, когда мы говорим об архитектуре, применяющей переупорядочивание инструкций (Out of Order, OOO), чья основная задача и состоит в том, что бы продолжать исполнять инструкции, пока их завершение невозможно.
Чтобы разработать методику на основе подсчета использования циклов, необходимо познакомиться с основами механизма OOO выполнения. Чрезвычайно упрощенная блок-схема представлена на рисунке 1.

После того, как инструкции декодированы в микрооперации (uops), они передаются дальше, если доступны необходимые ресурсы.
Это (среди прочих):
Завершение и отложенная запись состояния в видимые регистры производится только для инструкций и микроопераций, которые находятся в правильной ветви исполнения. Инструкции и микрооперации неправильно предсказанных ветвей сбрасываются как только определена ошибка предсказания переходов, затем происходит загрузка правильной ветви. Завершение правильных инструкций ветви исполнения может произойти при соблюдении 2-х условий:
Такая механика гарантирует, что видимое состояние программы всегда совпадает с тем, которое бы было при упорядоченном исполнении инструкций.
«Волшебство» такого дизайна состоит в том, что, если самая старая инструкция блокирована, например, ожиданием прибытия данных из памяти, последующие независимые инструкции, операнды которых доступны, могут быть отправлены операционным устройствам и складированы в ROB, в ожидании завершения. Они будут вытеснены, когда вся предыдущая работа завершена.
Трудность, с точки зрения анализа производительности, состоит в том, что завершение инструкций в системе происходит «пачками», то есть некоторые циклы не порождают завершенных инструкций, а некоторые сопровождаются большими их потоками. Таким образом, то, что случается в отдельном цикле на блоке завершения, ужасно неинформативно, и нужно использовать осредненные значения времени и отношений, чтобы понять, что же происходит на самом деле. Возникающая проблема состоит в том, что когда отношения используются как метрика производительности, процесс оптимизации приложения неизбежно изменит и числитель и знаменатель, ставя под сомнения сделанные успехи. Рассмотрим стандартный показатель выполнения инструкций, «Количество циклов на завершенную инструкцию» (Cycles per Instruction, CPI), в случае оптимизации цикла.
Высокое значение CPI считают признаком плохой производительности, в то время как низкое значение считают признаком хорошей производительности. Если во время процесса оптимизации цикл векторизован, то есть при компиляции генерирует инструкции из набора Streaming SIMD Extension (SSE), то число завершенных инструкций понизится значительно (в 2 или более раза). Однако количество циклов, затраченных на счет, вряд ли уменьшится в той же мере, поскольку эта оптимизация не будет влиять на такие вещи как неудачные обращения в КЭШ последнего уровня, останавливающие исполнение. В конечном счете, векторизация цикла, лишь гарантирует возрастание числа CPI. Фактически, чтобы уменьшить CPI, необходимо увеличить число завершенных инструкций!
Вместо того чтобы сосредотачиваться на метриках, исходящих из отношений числа событий жизнедеятельности центрального процессора, можно просто сосредоточиться на уменьшении числа циклов, потребляемых при выполнении желаемой работы.
Анализ использования циклов упрощает задачу, позволяя разработчику снижать индивидуальный вклад компонент, потребляющих циклы, считая их. Основным показателем в таком случае являются только циклы, и процесс оптимизации приложения всегда понижает основную метрику.
Далее:
Полная версия статьи в формате PDF
Чтобы разработать методику на основе подсчета использования циклов, необходимо познакомиться с основами механизма OOO выполнения. Чрезвычайно упрощенная блок-схема представлена на рисунке 1.
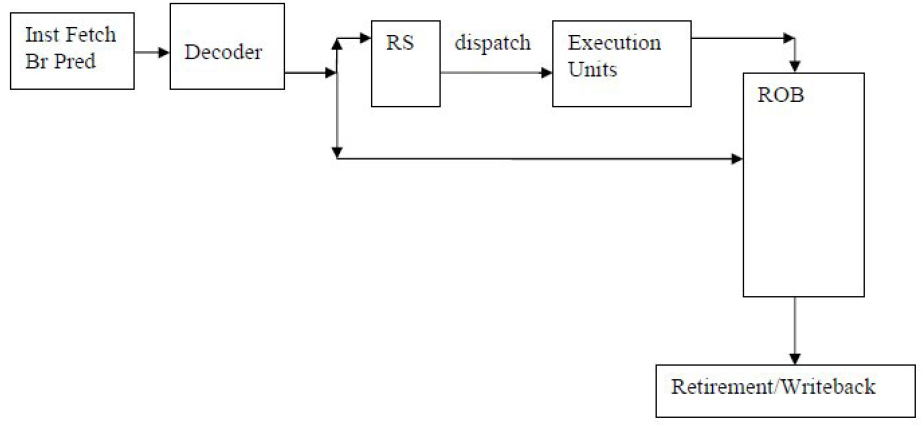
После того, как инструкции декодированы в микрооперации (uops), они передаются дальше, если доступны необходимые ресурсы.
Это (среди прочих):
- пространство в Станции Резервирования (Reservation Station, RS), где микрооперации ожидают появления своих операндов;
- пространство в Буфере восстановления последовательности (Re-order Buffer, ROB), где микрооперации ожидают очереди на завершение;
- достаточный объем буферов загрузки и выгрузки в случае микроопераций, связанных с работой с памятью (загрузка и выгрузка).
Завершение и отложенная запись состояния в видимые регистры производится только для инструкций и микроопераций, которые находятся в правильной ветви исполнения. Инструкции и микрооперации неправильно предсказанных ветвей сбрасываются как только определена ошибка предсказания переходов, затем происходит загрузка правильной ветви. Завершение правильных инструкций ветви исполнения может произойти при соблюдении 2-х условий:
- завершены все микрооперации, связанные с этой инструкцией, что позволяет завершить всю инструкцию;
- завершились все предыдущие инструкции и их микрооперации в правильно предсказанной ветви.
Такая механика гарантирует, что видимое состояние программы всегда совпадает с тем, которое бы было при упорядоченном исполнении инструкций.
«Волшебство» такого дизайна состоит в том, что, если самая старая инструкция блокирована, например, ожиданием прибытия данных из памяти, последующие независимые инструкции, операнды которых доступны, могут быть отправлены операционным устройствам и складированы в ROB, в ожидании завершения. Они будут вытеснены, когда вся предыдущая работа завершена.
Трудность, с точки зрения анализа производительности, состоит в том, что завершение инструкций в системе происходит «пачками», то есть некоторые циклы не порождают завершенных инструкций, а некоторые сопровождаются большими их потоками. Таким образом, то, что случается в отдельном цикле на блоке завершения, ужасно неинформативно, и нужно использовать осредненные значения времени и отношений, чтобы понять, что же происходит на самом деле. Возникающая проблема состоит в том, что когда отношения используются как метрика производительности, процесс оптимизации приложения неизбежно изменит и числитель и знаменатель, ставя под сомнения сделанные успехи. Рассмотрим стандартный показатель выполнения инструкций, «Количество циклов на завершенную инструкцию» (Cycles per Instruction, CPI), в случае оптимизации цикла.
Высокое значение CPI считают признаком плохой производительности, в то время как низкое значение считают признаком хорошей производительности. Если во время процесса оптимизации цикл векторизован, то есть при компиляции генерирует инструкции из набора Streaming SIMD Extension (SSE), то число завершенных инструкций понизится значительно (в 2 или более раза). Однако количество циклов, затраченных на счет, вряд ли уменьшится в той же мере, поскольку эта оптимизация не будет влиять на такие вещи как неудачные обращения в КЭШ последнего уровня, останавливающие исполнение. В конечном счете, векторизация цикла, лишь гарантирует возрастание числа CPI. Фактически, чтобы уменьшить CPI, необходимо увеличить число завершенных инструкций!
Вместо того чтобы сосредотачиваться на метриках, исходящих из отношений числа событий жизнедеятельности центрального процессора, можно просто сосредоточиться на уменьшении числа циклов, потребляемых при выполнении желаемой работы.
Анализ использования циклов упрощает задачу, позволяя разработчику снижать индивидуальный вклад компонент, потребляющих циклы, считая их. Основным показателем в таком случае являются только циклы, и процесс оптимизации приложения всегда понижает основную метрику.
Далее:
- Анализ на основе выполнения
- Декомпозиция Простоев
- Ошибки Предсказания Переходов и Интеллектуальное выполнение
- Оценка последствий возникновение проблемных Событий Производительности
- Анализ приложения
- Основные ремарки по оптимизации кода
- Параллелизм на уровне инструкций
Полная версия статьи в формате PDF







