Комментарии 35
МТ/с это «мегатакт в секунду»? Обычно в мегагерцах измеряют
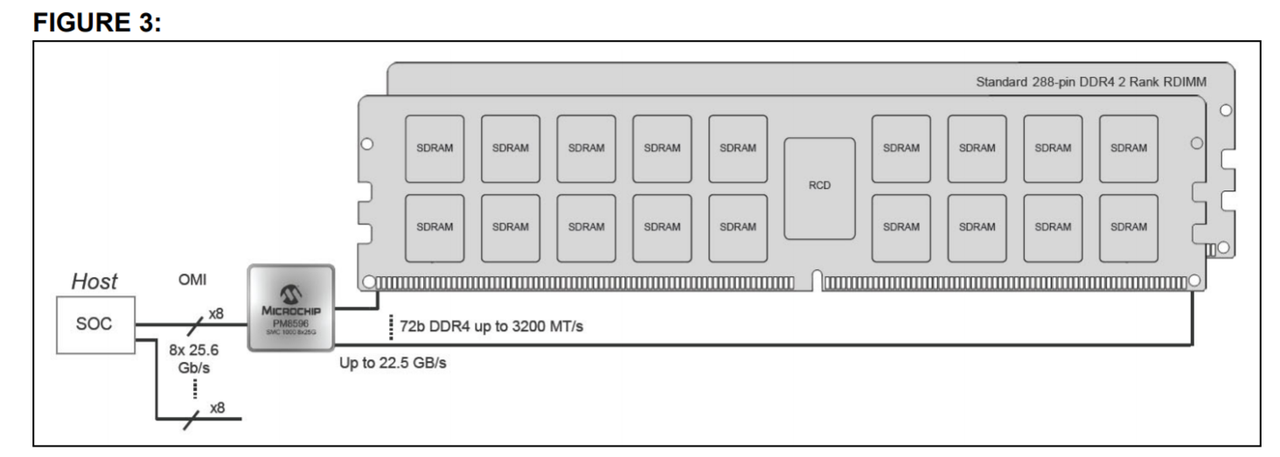
Дело за малым — протащить сотню single-ended трасс с частотой 4GHz от процессора до DIMM, чтобы оно не загнулось от перекрестных помех.
Когда уже интересно эти парни там заменят DDR на последовательную шину и перестанут закапывать стюардессу?
Когда уже интересно эти парни там заменят DDR на последовательную шину и перестанут закапывать стюардессу?
НЛО прилетело и опубликовало эту надпись здесь
Так уже заменили — HMC, только это оказалось еще хуже стюардессы, поэтому закопали даже раньше. Основной фэйл, как я понимаю — еще большая чем у классических sdram латентность из-за гигабитных трансиверов.
На самом деле у толстых процессоров последовательная шина. У Intel Xeon E7. У IBM Power 8 — DMI, Power 10 — OMI. Там ставится специальный чип, который разворачивает последовательную шину в параллельную на месте и все. То есть процессор может вообще на другой плате находиться и к памяти подключаться кабелем.
Это позволяет подключать к ним конское количество памяти и держать в ОЗУ целые БД, видимо Latency тут не жмет особо. Все равно на порядок ниже чем у подсистемы хранения и сети.
Вот Вам в качестве рекламы например наша машина с 16ТБ ОЗУ на борту. 128 плашек в 2U.

Пора уже и плашки делать штатно с сердесами. А то мы получаем типичные проблемы Signal Integrity на параллельной шине. Заниматься анализом глазковых диаграмм и смотреть BER на таких шинах — это нонсенс.
Я думаю причина просто в инерционности процесса — ну типа пока канает параллельная шина — пусть будет.
Это позволяет подключать к ним конское количество памяти и держать в ОЗУ целые БД, видимо Latency тут не жмет особо. Все равно на порядок ниже чем у подсистемы хранения и сети.
Вот Вам в качестве рекламы например наша машина с 16ТБ ОЗУ на борту. 128 плашек в 2U.

Пора уже и плашки делать штатно с сердесами. А то мы получаем типичные проблемы Signal Integrity на параллельной шине. Заниматься анализом глазковых диаграмм и смотреть BER на таких шинах — это нонсенс.
Я думаю причина просто в инерционности процесса — ну типа пока канает параллельная шина — пусть будет.
Так-то да, но такое ОЗУ становится все менее оперативным. Это здорово, когда альтернатива — хранить данные HDD. Ну и серверным процессорам, как я понимаю не столь критично за счет большого объема кэша. Но в качестве единственной памяти для пользовательских машин как-то не супер.
А нет данных по латентности этих шин? (лень искать самому)
А нет данных по латентности этих шин? (лень искать самому)
Ну я вот смотрю сейчас в даташиты P8 и его Memory Buffer и не вижу в явном виде какой-то цифры. Да и бестолковая она сама по себе, не особо информативна.
Про OMI я слышал что чуть ли не время распространения сигнала + 1 такт (на то чтобы последовательную шину развернуть в параллельную). Но там тупой SerDes вообще.
DMI буфер умнее — там кэш внутри, еще мозги какие-то — я думаю побольше будет задержка.
DDR сама по себе не особо «оперативна» — там циклы рефреша до 20% производительности могут отъедать.
Про OMI я слышал что чуть ли не время распространения сигнала + 1 такт (на то чтобы последовательную шину развернуть в параллельную). Но там тупой SerDes вообще.
DMI буфер умнее — там кэш внутри, еще мозги какие-то — я думаю побольше будет задержка.
DDR сама по себе не особо «оперативна» — там циклы рефреша до 20% производительности могут отъедать.
Уже двигаются в этом направлении достаточно давно- притом без жесткой привязки к такому-то вендору

но все равно почему-то цепляются за тот же форм фактор.
но все равно почему-то цепляются за тот же форм фактор.
Дело за малым — протащить сотню single-ended трасс с частотой 4GHz от процессора до DIMM, чтобы оно не загнулось от перекрестных помех.
А протащить еще более быстрый(= кратно выше частота Найквиста) SERDES сильно проще(пусть и short reach)? В конце-концов, даже иные DIMM под DDR5 рассчитаны на 7+ GHz- понятно что порог быстро исчерпается, но тем не менее. И почему проблема именно в xtalk, тем более что это довольно легко решаемая проблема? К примеру, почему не PI vs BER/bathtub curve? «Легко»(sarcasm on) набрать on-die memory типа HBM, но цена будет космическая при меньшем итоговом объёме и расширяемости в сравнении с DDR- это легко заметить на примере цен того же Nvidia A100 SXM4.
А протащить еще более быстрый(= кратно выше частота Найквиста) SERDES сильно проще(пусть и short reach)?
Конечно проще ибо дифпара сама по себе менее шумная и восприимчивая как к Xtalk так и к чистоте питания.
А во вторых SerDes имеют схему CDR — там не надо ровнять клок с данными как наркоман. И тащить можно сильно дальше. С DDR же проблема в том что в окрестности процессора еще и разгуляться особо негде.
В конце концов там же есть UPI рядом 20+ лэйнов 5GHz — я бы не сказал что с ними какие-то трудности бывают особые. Растаскивается за 2-3 дня обычно и все.
И почему проблема именно в xtalk, тем более что это довольно легко решаемая проблема?
Проблема Xtalk не решается легко при спейсингах в 4-5mil, всяческий изврат типа tabbed routing имеет предел эффективности, я уже не говорю о том, что он очень хреново производится на фабриках.
Конечно проще ибо дифпара сама по себе менее шумная и восприимчивая как к Xtalk так и к частоте питания.
Это пока она нормальная диффпара, т.е. не загубленная mode conversion.
А во вторых SerDes имеют схему CDR — там не надо ровнять клок с данными как наркоман. И тащить можно сильно дальше. С DDR же проблема в том что в окрестности процессора еще и разгуляться особо негде.
Касаемо клока спору нет, но с выравниванием не могу согласиться- как мне кажется(не вселенское откровение не претендую) у проблемы есть четкие очертания, которые выглядят примерно во так
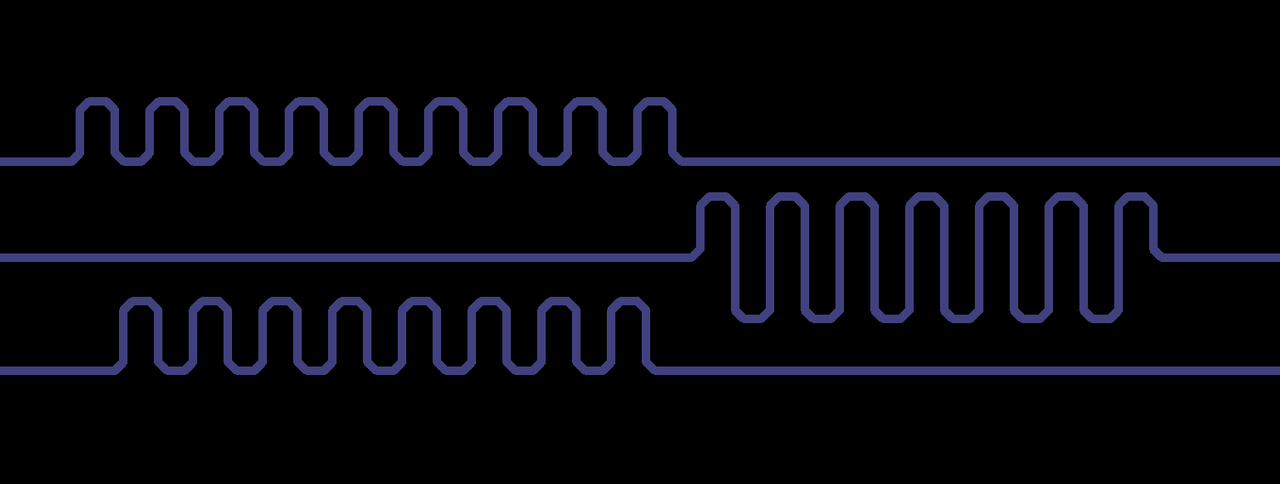
Так ровняет большинство дезигнеров, схожим образом ровняет и автомат- так и съедается то самое место у проца.
Так ровняет большинство дезигнеров, схожим образом ровняет и автомат- так и съедается то самое место у проца.
И что в этом хорошего? У тебя во первых на более высоких частотах сигнал будет ходить не по аккордиону а сквозь него из-за stray-capacitance между петлями, а во вторых — стоит тебе отойти от оптимального размещения из рефдизайна (ну например DIMM двинуть вправо по отношению к процессору, или подвинуть их поближе) и все сразу становится сильно хуже.
И что в этом хорошего?
Абсолютно ничего- и в этом собственно мой посыл вкупе с этой картинкой.
У тебя во первых на более высоких частотах сигнал будет ходить не по аккордиону а сквозь него из-за stray-capacitance между петлями
Если не сделано адекватное расстояние до опоры, то конечно все будет ровно так как ты сказал- но я так не делаю, а делаю вот так.

Это пример во многом искусственный(LPDDR4-3200, HDI, подогнанный дизайн) но принцип иллюстрирует. Выравнивание в ноль(менее 0.001мм), к слову- сугубо потому, что это довольно легко если к этому подходить определенным образом. С any angled+tangent arc свичбэками и поворотом аккордеонов проблема режется под корень- притом со всех сторон.
Ну и ты как то легко показал масштаб проблемы.
Он выглядит так:
Он выглядит так:

Ну и ты как то легко показал масштаб проблемы.
Дык, тут как раз она- очень много пустых островов. Я шутки ради сегодня завтра в пост вставлю картинку с
any angled+tangent arc свичбэками и поворотом аккордеонов проблема режется под корень
Сугубо смеха ради конечно- никакой фаллометрии и критики с удобных диванов)
Дык, тут как раз она- очень много пустых островов.
Тебе кажется =) Ты же не думаешь что мы не знаем про такую технику выравнивания. Знаем — чай не вчера с ветки спрыгнули.
Да — она экономит больше места (хотя не капитально, поэтому я написал что тебе кажется — оно просто выглядит более плотно что-ли), но требует гораздо больше времени. А еще потом очень больно когда приходит главный конструктор и просит подвинуть DIMM на пару мм. Ты ж их прямо по констрейну жмешь к друг другу. Как в последний раз.
Тебе кажется =)
Да вроде нет xD — достаточно посмотреть на правый нижний угол и в пинфилд чтобы место найти. Тут проблема скорее в этом
А еще потом очень больно когда приходит главный конструктор и просит подвинуть DIMM на пару мм.
Если класть без островов, с киберспортом, то это катастрофа без вариантов.
Ты же не думаешь что мы прям не знаем про такую технику выравнивания.
Нет, конечно нет- мне ваши возможности понятны(насколько это слово применимо), к YADRO я отношусь с уважением.
Ты ж их прямо по констрейну жмешь к друг другу. Как в последний раз.
Ага, а потом еще выяснится что забыли какой-нибудь SMBus c гпио и все- и это непременно после того как тюнинг уже сделан по N-му кругу.
Вот если твою картинку привести к такому виду
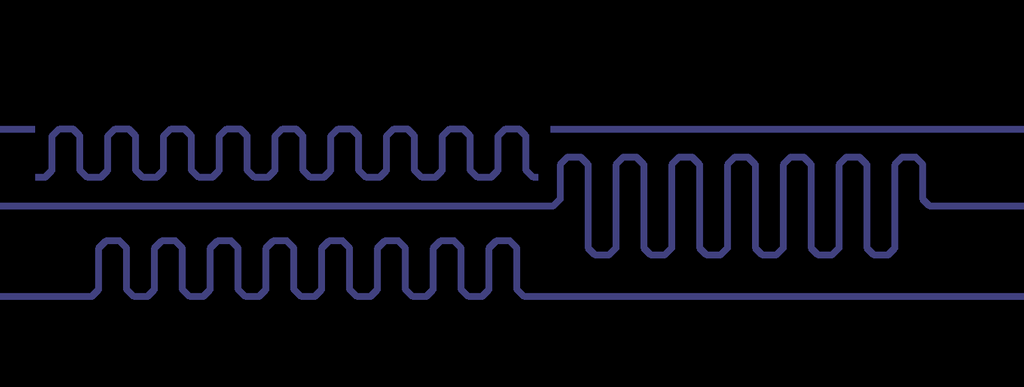
Я не думаю что будет большая разница с switch-back. Чудес не бывает.
Я не говорю что твое конфу плохое — я и сам так делал и не раз и не два когда сам занимался топологией. Просто это не панацея и у него есть расплата.

Я не думаю что будет большая разница с switch-back. Чудес не бывает.
Я не говорю что твое конфу плохое — я и сам так делал и не раз и не два когда сам занимался топологией. Просто это не панацея и у него есть расплата.
Вот если твою картинку привести к такому виду
Это, так сказать, прелюдия к тому чтобы сделать все немного плотнее — но делаться оно должно иначе: сначала траска заровнялась, потом к ней прижалась следующая с размазыванием тюнинга где надо, повтор до финиша. Однако с укладкой произвольным углом с дугами и свичбэками это конкурировать не может- даже если делать все под 45 гр, все равно возникнут острова и «излишняя геометрия» в силу повторяющейся митры

И это еще даже без докрученных фанаутов.
Просто это не панацея и у него есть расплата.
Конечно- при киберспорте цена ошибки абсолютна, relayout.
Я не думаю что будет большая разница с switch-back. Чудес не бывает.
Заявленный выше пример odd-angled segments + tangent arcs, очень простой и почти синтетический, к тому же все еще с островами пусть и с минимальными.
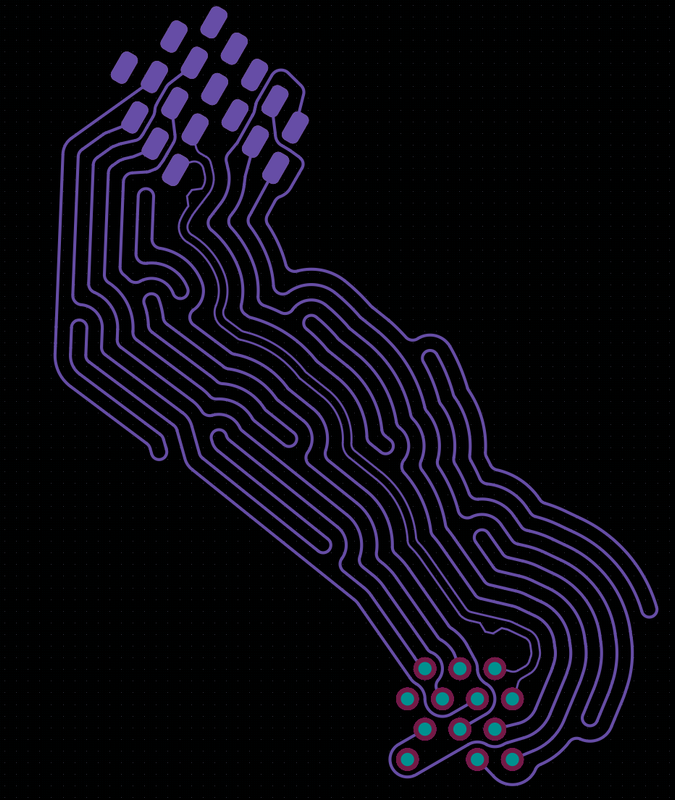
Касаемо чудес- вот прямо чудес конечно нет, но заметно сэкономить слои это почти наверняка, а если идти дальше по пути киберспорта, например с итеративной подгонкой таргета(видно на пикче) то можно делать прелестные вещи, особенно в memory down дезигнах. Скажем, для PCIe ускорителя(front-/backhaul, неважно) с 4 ранками ддр и большой FPGA это выстреливает на 200%. С DIMM выстреливает слабее, но становится проще зарулить те самые проблемы с xtalk, тем более все равно сильно выигрывается место.
В конце концов там же есть UPI рядом 20+ лэйнов 5GHz — я бы не сказал что с ними какие-то трудности бывают особые. Растаскивается за 2-3 дня обычно и все.
Говоря про UPI видимо подразумевается сугубо Intel- с учетом околоидеального пинаута и довольно низкой скорости(~10G, если не путаю) то тут наверное трудностей нет вовсе никаких, спору нет- откуда им взяться?
Проблема Xtalk не решается легко при спейсингах в 4-5mil
Конечно, ведь эта проблема собственно и возникает при таких спейсингах.
tabbed routing имеет предел эффективности, я уже не говорю о том, что он очень хреново производится на фабриках.
Не фанат tabbed routing, но успешный опыт применения есть- все дело в том, как его готовить: в конце концов, он разного вида бывает, с разной же применимостью- нужно просто очень четко сформулировать задачу. С другой стороны, это надо очень далеко зайти чтоб такой прием стал крайней мерой- как мне кажется, в больших камнях это признак либо over-engineering, либо слепого повторения референса, либо просто ошибочного дизайна.
Про тайминги, почему-то, технично умалчивают. Впрочем, понятно почему.
В заголовке «начала производство», а в первом же предложении «сообщила о разработке».
Кликбейт такой кликбейт.
Кликбейт такой кликбейт.
Такие же глючные как их SSD диски?
А ведь при частоте 8400 МГц сигнал успевает пройти расстояние только порядка 36мм за период, а для типичного модуля памяти пару сантиметров это только расстояние от чипа до контактов! Или в этом нет проблемы, кто то скажет?
В 2 раза меньше — оно же не со скоростью света распространяется, а примерно в половину от нее — грубо 15см/1нс.
Проблемы в этом нет — потому что там строб DQS двунаправленный. Просто будет Latency. Но есть другая проблема, которая отсюда вытекает — данные DQ приходится очень плотно выравнивать с DQS по длине и трассировка получается адская. Чем выше частота — тем точнее ровнять, тем адовее будет.
Проблемы в этом нет — потому что там строб DQS двунаправленный. Просто будет Latency. Но есть другая проблема, которая отсюда вытекает — данные DQ приходится очень плотно выравнивать с DQS по длине и трассировка получается адская. Чем выше частота — тем точнее ровнять, тем адовее будет.
НЛО прилетело и опубликовало эту надпись здесь
Не пойму, зачем они постоянно снижают на 0.1 напряжение и выставляют это как супер преимущество. На 1.1 В может быть как 1 Вт нагрузки, так и 100. И смысл тогда в низком напряжении? Вот указывали бы мощность плашки — другое дело.
Блин… я ишо на платформу с DDR4 денег не накопил. Все таки спокойнее на душе, когда лишних денег не тратишь и перепрыгиваешь через 1 — 2 поколения электронники.
Error Correcting Code и прочие «нововведения», как обычно, будут безумно дороги и бестолковы первые года два. Вдобавок, искусственный дефицит видеокарт, чипсетов, памяти? Забудьте… до 2025!
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Adata начала производство модулей памяти DDR5 со скоростью работы 8400 МТ/с