
Исследователи кафедры аэронавтики и космонавтики Массачусетского технологического института разработали модель, которая помогает роботам воспринимать свою физическую среду так, как это делают люди.
«Чтобы принимать какие-либо решения, вам необходимо иметь мысленную модель окружающей вас среды», — говорит доцент кафедры Лука Карлон. — «Это что-то очень легкое для людей. Но для роботов это мучительно трудная проблема, когда речь идет о преобразовании значений пикселей, которые они видят через камеру, в понимание мира».
Представление пространственного восприятия 3D Dynamic Scene Graphs позволяет роботу быстро создавать 3D-карту своего окружения, которое включает объекты и их семантические метки (например, стул против стола), а также людей, комнаты, стены и другие конструкции, которые робот, вероятно, видит в окружающей среде.
Модель также позволяет роботу извлекать соответствующую информацию из 3D-карты, запрашивать местоположение объектов и помещений или движение людей на своем пути.
«Это сжатое представление об окружающей среде полезно, потому что оно позволяет нашему роботу быстро принимать решения и планировать свой путь», — говорит Карлон. — «Это не слишком далеко от поведения людей. Если вам нужно спланировать путь от вашего дома до Массачусетского технологического института, вы не продумываете каждую позицию, которую вам нужно занять. Вы просто мыслите на уровне улиц и достопримечательностей, что помогает вам планировать свой маршрут быстрее».
Ученые считают, что роботы с таким уровнем мышления могут быть полезны не только в домашнем хозяйстве, но и подойдут для других высокоуровневых задач, таких как работа бок о бок с людьми на фабрике или исследование места катастрофы.
В настоящее время роботизированное зрение и навигация развиваются в основном по двум маршрутам: трехмерное картографирование, которое позволяет роботам реконструировать свою среду в трех измерениях при их исследовании в реальном времени; и семантическая сегментация, которая помогает роботу классифицировать объекты в его среде как семантические объекты, такие как автомобиль или велосипед, что до сих пор, в основном, делалось на 2D-изображениях.
Новая модель пространственного восприятия первой создала трехмерную карту окружающей среды в реальном времени, а также пометила объекты, людей (которые являются динамическими, в отличие от объектов) и структуры на этой карте.
Ключевым компонентом новой модели является Kimera, библиотека с открытым исходным кодом, которую группа ранее разработала для построения трехмерной геометрической модели среды, одновременно кодируя вероятность того, что объектом внутри среды может быть, например, стул или стол.
Kimera работает, принимая потоки изображений с камеры робота, а также инерциальные измерения с бортовых датчиков, чтобы оценить траекторию робота или камеры и реконструировать сцену в виде трехмерной сетки. Все это происходит в режиме реального времени.
Чтобы создать семантическую трехмерную сетку, Kimera использует существующую нейронную сеть, обученную миллионами реальных изображений, чтобы предсказать метку каждого пикселя, а затем проецирует эти метки в 3D, используя метод, известный как преобразование лучей.
В результате получается карта окружающей среды робота, которая напоминает плотную трехмерную сетку, где все имеет цветовую кодировку как объекты, структуры и люди.
Если бы робот мог полагаться только на эту сетку для навигации, это было бы дорогой и трудоемкой задачей в плане вычислений. Исследователи создали Kimera, разрабатывая алгоритмы для построения трехмерных динамических «графов сцен» из исходной, очень плотной, семантической сетки 3D.
Графы сцен — это популярные модели компьютерной графики, которые манипулируют сложными сценами и воспроизводят их, и обычно используются в движках видеоигр для представления трехмерных сред.
В случае трехмерных динамических графов сцены соответствующие алгоритмы разбивают детализированную трехмерную семантическую сетку Kimera на отдельные семантические слои, так что робот может «видеть» сцену через определенный слой или линзу. Слои прогрессируют в иерархии от объектов и людей к открытым пространствам и структурам, таким как стены и потолки, комнаты, коридоры и залы, наконец, целые здания.
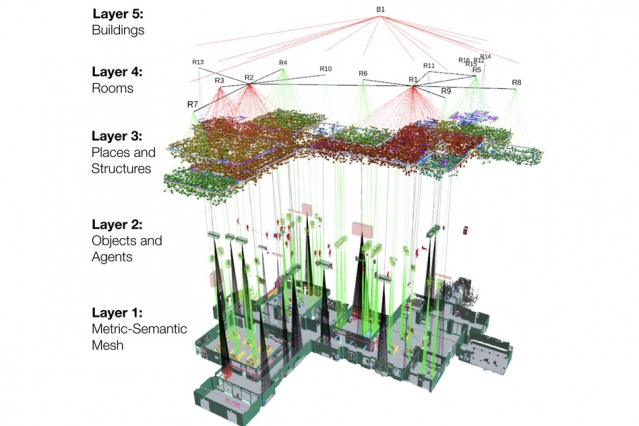
Карлон говорит, что это многоуровневое представление позволяет избежать необходимости роботу распознавать миллиарды точек и граней в исходной трехмерной сетке.
На уровне объектов и людей исследователи также смогли разработать алгоритмы, которые в реальном времени отслеживают движение и форму объектов в окружающей среде.
Команда протестировала свою новую модель в фотореалистичном симуляторе, разработанном в сотрудничестве с Lincoln Laboratory. Он имитирует робота, который перемещается по динамичной офисной среде, заполненной такими же подвижными людьми.
«По сути, мы даем роботам ментальные модели, аналогичные тем, которые используют люди», — говорит Карлон. — «Это может повлиять на многие сферы, в том числе автомобили с автопилотом, поиск и спасение, производство. Другая область — это виртуальная и дополненная реальность. Представьте себе, что вы носите очки AR, которые работают по нашему алгоритму: очки могут помочь вам с такими вопросами, как «Где я оставил свою красную кружку?» и «Какой ближайший выход?».
Исследователи говорят, что их работа стала возможной благодаря недавним достижениям в области глубокого обучения и десятилетиям исследований по одновременной локализации и картированию. Они отмечают, что это позволило совершить скачок к новой эре роботизированного восприятия, называемой пространственным ИИ, которая только зарождается, но имеет огромный потенциал.
См. также:









