Комментарии 115
Я так понял, железка заточена на обсчёт нейронок. Т.е. закачали данные, обсчитали веса, выгрузили результат.
Для питания два контакта, но больших, под винт М10. Ими же и прижимать.
Она при нагреве расширяется, и при толщине обычных подложек в миллиметр-два хрупкий кремний прикрутить болтом — верный шанс поломать её крайне быстро.

И к тому же как вы такой рулон охлаждать собираетесь?
Как пулемет Гатлинга, подозреваю — вращением "обоймы" процессоров. :)
Более того, так можно даже сделать модульный процессор. Когда на ленту можно по желанию наклеить хоть 10, хоть 100 модулей кэша, и любое требуемое количество ядер, причём ещё и разной специализации.
И получить или многопроцессорный сервер (на нашей планете такое уже изобрели) или большие проблемы с микрокодом, которую нужно будет пилить и тестировать под разные варианты или он будет причиной тормозов. Не считая проблем с шинами для взаимодействия с этими модулями кеша (или падение скорости при росте цены).
Погружать в жидкость в обойме, как для проявки фотопленок.
Длинна ли, коротка ли была кто? Но длина будет вполне ограничена. Главное — чтобы не окружность, а не то вдруг углов более миллиона будет и всё, USB уже не хватит для передачи данных. Кстати, к USB что планируется подключить и почему именно он?
А как этот процессор в плане игор?)
~800 000 "сложных" полей в сапёр в секунду
Спасибо за ссылку, залип на пару часов
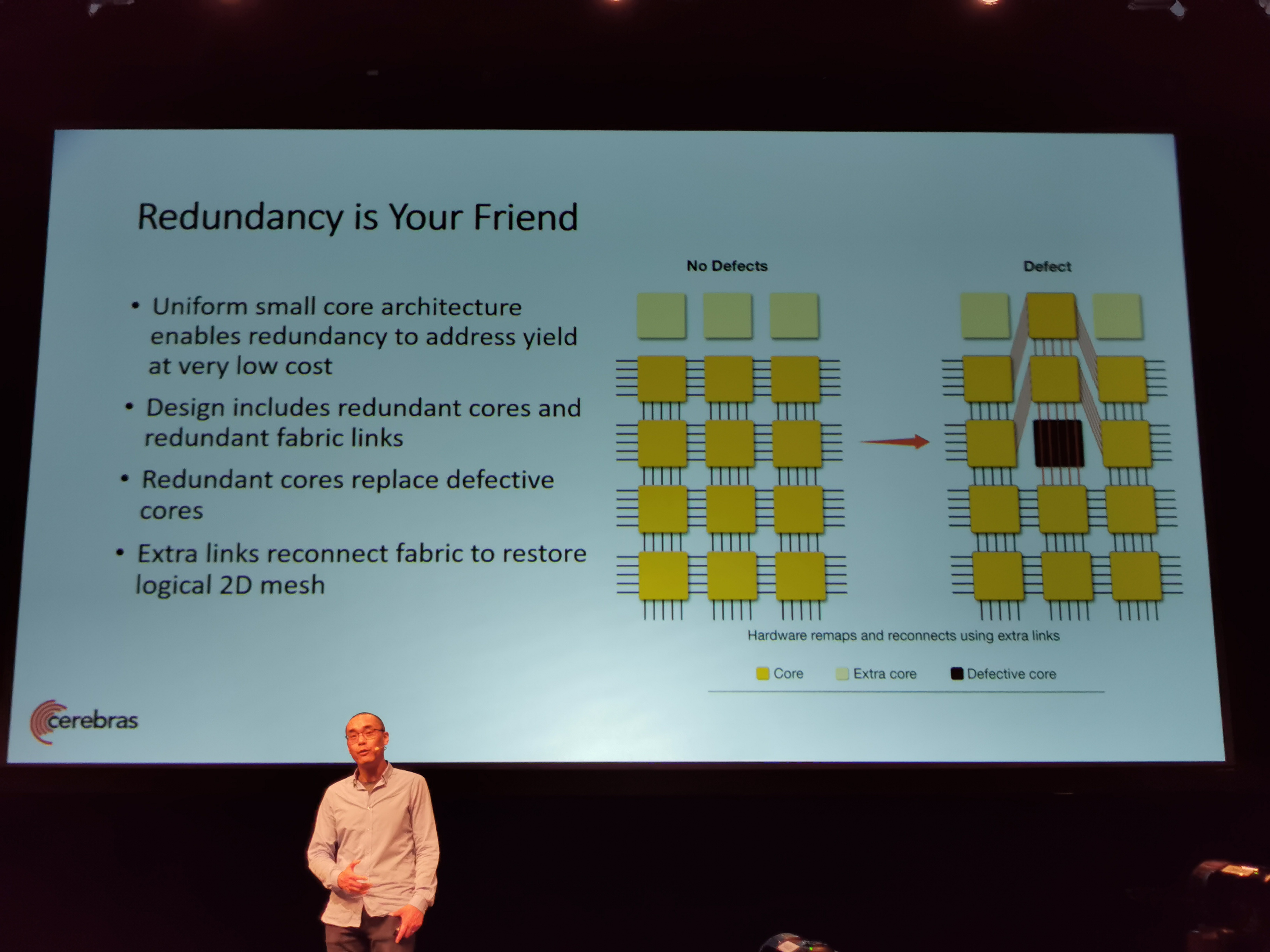
а дополнительную логику встраивают лишь для исправления ошибок проектирования. и то с большими оговорками о длинных путях до этих элементов.
спасибо, открыли для меня откуда есть пошел спектрум. его я как-то пропустил в своей деревне.


Не увидел в тексте статьи, за счёт чего конкретно они сделали этот waferscale коммерчески оправданным. Сама по себе идея не нова, занимались этим тоже ради быстрого интерконнекта, и были рабочие образцы, но как-то не взлетело.
за счёт чего конкретно они сделали этот waferscale коммерчески оправданнымОтдельные cpu получаются относительно мелкие. Возможно за счёт умного роутинга битых как пишут. Но вообще — слишком фантастично. Интересно, что сказал бы amartology
Сложный вопрос — это корпус, и на него у этих людей нет ответа. Как и во что упаковать такую пластину, не наловив при этом отказов при сборке, не сломав ее, не получив проблем с тем, что она, например, погнётся. Как обеспечить теплоотвод (оно же наверняка жрет не один килоВатт) и т.д. и т.п.
Отдельно представьте себе: вы разработчик печатной платы. В центре надо поставить эту штуку 30*30. И подвести к ней 5000 А тока. Ваши действия? )
И ещё представьте себе: вы венчурный инвестор из Долины, с финансовым образованием. Вы давно работаете с хайтеком, неплохо для финансиста в нем разбираетесь. Но не более того. И тут приходит Джонни и говорит «есть очень крутая идея». Вы спрашиваете каких-то своих аналитиков, они говорят «идея выглядит чрезмерно смелой и, кажется, не взлетит». Но на пятом слайде презентации Джонни была надпись «я продал свой предыдущий стартап в AMD за X». И этот X будет реально жечь вам мозг, потому что AMD-то понимают получше вас, и Джонни вот молодец же, а не обычный балабол, которые к вам ходят. А вдруг Джонни прав, а ваши аналитики — нет? Тогда вы заработаете на Джонни 100*Х. Рискнете ли вы в такой ситуации десятком-другим миллионов? Особенно с учётом того, что в ваш бизнес-план и так заложен процент фейла 80-90%? Я бы рискнул.
Вот так эти люди собрали деньги, а дальше начали разбираться, а что там с корпусами. И вот именно эта часть про отсутствие готовых ответов на вопросы, что дальше делать с чипом, заставляет меня думать, что эта история — типичное порождение венчурной модели Кремниевой долины. Если протянут достаточно долго — успеют разработать что-то полезное, что потом используют в менее монструозных проектах другие.
Весь вопрос в том, насколько это экономически эффективно. Хотя, опять же, если эта штука эффективна настолько, насколько рассказывают авторы, крупные фирмы типа гугла или теслы могут забить на высокую цену ради получения преимущества в обучении нейросетей, чтобы захватить какую-то часть рынка.
Вообще, на картинке прекрасно видно матрицу 7*12, где один элемент примерно в 1.5раза меньше «топового гпу». Так что считаем условно 150Вт на один элемент, что дает 13кВт энергии на 46к кв. мм. Это всего то 0.3Вт на кв. мм. площади, что рассеять вообще говоря не так уж и сложно.
Дополнительно получается примерно 5к ядер на один большой матричный элемент, который внутри наверняка имеет свою память независимо от остальных матричных элементов. Дальше все это чудо стыкуется по кастомной NoC и готово.
В общем выглядит прикольно, но насколько это эффективнее кластера отдельно стоящих ускорителей — вопрос открытый.
Ты так говоришь, как будто не существует вариантов сделать большой корпус.Я не говорю, что их не существует в принципе. Я сомневаюсь, что есть экономически эффективные варианты. И эти сомнения усиливает то, что эти ребята много говорят про кристалл и много молчат про все остальное.
Например, у меня есть подозрения, что и такого монстра будут серьезные проблемы с тем, что пластину будет коробить от неравномерного нагрева, причем каждую пластину по-своему. И на таких размерах оно может иметь весьма заметный эффект. То есть усложнятся контакты от чипа к корпусу, чтобы их не отрывало. И так дале и тому подобное.
13кВт энергии на 46к кв. мм.13 кВт, питание ядра 1 В, ток 13 кА, сечение провода питания 2100 кв. мм. Это полностью реалистично, но плата выглядеть должна очень красиво.
В общем выглядит прикольно, но насколько это эффективнее кластера отдельно стоящих ускорителей — вопрос открытый.Именно так. Я бы даже сказал, что итоговая реализация наверняка будет более производительна, чем кластер (особенно если посчитать на единицу объема сервера), но вопрос состоит в том, насколько оно будет дороже и не получится ли выгоднее поставить два кластера, чем одного такого монстра.
Впрочем, суперкомпьютеры давно уже больше зависят от интерконнекта, а не от вычислительных мощностей, и вот там-то такие решения могут быть оправданными.
www.anandtech.com/show/14758/hot-chips-31-live-blogs-cerebras-wafer-scale-deep-learning
Система охлаждения сидит прямо на кристалле.
С расширением материалов справляются с помощью некоего переходника.
Питание подаётся сквозь плату.
images.anandtech.com/doci/14758/IMG_20190819_181142.jpg
{kind=link}
С расширением материалов справляются с помощью некоего переходника.Мне интереснее скорее неравномерное расширение самой пластины и соединение пластины с корпусом, а не расширение корпуса относительно платы. Но окей, так оно намного лучше выглядит.
Особенно подача питания в перпендикулярном направлении.
Как понял из их презентации она у них представляет огромный (такой же как чип) кастомный водоблок прижимающийся ко всей площади пластины с множеством каналов с регулируемыми клапанами, реагирующими на показания множества же датчиков раскиданных по всей площади.
Через наиболее горячие участки ток охлаждающей жидкости будет усиливаться, через холодные наоборот снижаться. Все это динамически в зависимости от данных с множества температурных датчиков.
Независимых зон охлаждения в каждую из которых входят свои каналы, регулируемый клапан и набор датчиков вероятно столько же сколько «чипов» — матрица 7x12
В результате при гигантской площади кремния его температура должна оставаться максимально однородной при любом характере нагрузок.
Да и локализация дефектов отдельных ядер далеко не всегда легко делается, например если шины питания хорошо замкнулись… Впрочем нельзя исключать, что питание каждого ядра (группы ядер) отдельно заводится с несущей платы, тогда этой проблемы не будет.
Все ядра являются равными копиями друг друга (никаких выделенных среди них нет), память интегрирована в каждое ядро и является локальной одноуровневой без иерархии, а интерконнект между ними связывает ядра только с его ближайшими соседями. Mesh сеть, т.е. никаких центральных шин/хабов/свичей в архитектуре тоже нет.
Во-вторых все-таки шины питания и силовые транзисторы ими управляющие намного крупнее делаются и от тех типовых мелких дефектов, смертельных для логики и информационных шин обычно не умирают.
крупные фирмы типа гугла или теслыГугл сам делает почти то же самое, см TPU
Гугл сам делает почти то же самое, см TPUСам гугл это делает с чипами нормального размера.

А вопрос был в том, кому может быть экономически выгоден такой вот монстр.
С биржевой аналитикой как раз понятно, там реально может быть ситуация, когда сколь угодно малый рост производительности за сколь угодно большие деньги может окупиться, если девайс можно поставить рядом с местом событий, а не в качестве удаленного в пространстве сервера. Но считать, что эта штука нужна только для биржевых спекуляций, мне очень печально.
Сходу видится большой вопрос даже не в том, КАК отвести с такой пластины тепловой поток, а в том, что делать с ГРАДИЕНТОМ нагревания. Например, при 100% нагрузке ядро греется сильнее, соседнее ядро простаивает. Память в состоянии хранения или чтение/запись и пр. Вафлю такого размера должно очень сильно деформировать при этом. Для минимизации ее придется фигурно надрезать, предусматривать деформационные зазоры… Так и почему бы не пойти дальше и не порезать совсем? У меня пока картина не складывается.
В общем выглядит прикольно, но насколько это эффективнее кластера отдельно стоящих ускорителей — вопрос открытый.
Вот эта фраза натолкнула на мысль, которую, похоже, никто еще не высказал. Предположим, все получилось. Предположим, оно в продакшене. Но всем же понятно, что стоит эта фиговина не три копейки.
Предположим, что оно даже сверхнадежно. Но даже в этом случае фаталити с таким процессором — это, наверное, очень, очень большие финансовые потери. То есть, не как с кластером мух-ускорителей, когда сдох один, берем на Авито следующий, и алга.
ps. а вообще сильно похоже на анекдот про грузовик компакт-дисков.
15 кВт у него потребление: www.eetimes.com/document.asp?doc_id=1335043
Хотя «очень сложно» у всех остальных, включая Intel, AMD и Apple в итоге вылилось в 3D-интеграцию и чиплеты, которые дают почти то же результат, но радикально дешевле и при необходимости с меньшей площадью корпуса
Вот именно, борьба за уменьшение расстояний и упрощение сборки перешла немного в другую плоскость.
Но в целом можно выразить респект TSMC за отличный демонстратор высокого выхода годных
Да, и не более. Еще интересно было бы понять, за сколько итераций они его добились.
Параметры у процесса уж больно хорошие. Например на XS018 нам обещают делать относительно низкоскоростные waferscale-фотосенсоры на пластинах 8 дюймов с КВГ 0,9 (со встроенной «цифрой», поэтому КВГ вообще имеет место). А тут 16 нм (не Бог весть что, но все же), и размер побольше, и сплошная цифра…
заставляет меня думать, что эта история — типичное порождение венчурной модели Кремниевой долины
Предыдущие проекты хотя и были 30 лет назад, но кажется, что результат будет тот же.

Возможно за счёт умного роутинга битых
Разве что…
основной вопрос — сколько будет стоитьВсё же, основной вопрос пока — действительно ли у неё такая производительность, не подтверждена же ещё.
Охлаждать чем? Жидким азотом?
Подозреваю, что не такая уж и проблема. Что-то типа цельного куска меди килограмм на 20 со сквозными порами, через которые фреон гнать)
А холодильная установка будет вообще копейки стоить, учитывая, что даже топовые бытовые кондиционеры за $10к могут 30 киловат в час тепловой энергии отводить.
В любом случае круто, пусть и реальные продукты будут другими, но такие вещи впечатляют всёравно.
Ну какой сейчас процент выхода годных для обычных чипов 16nm процесса? 95%?95% — это уже с учетом отключения неработоспособных ядер и выпуска их на рынок как младших моделей. Тут скорее всего существенно ниже итоговый выход годных, даже с учетом всех разумных мер по противодействию.
Разработка и производство таких изделий является «намного более трудоёмким процессом», признаёт Брэд Полсен (Brad Paulsen), старший вице-президент TSMC.
95% — это уже с учетом отключения неработоспособных ядер и выпуска их на рынок как младших моделей.
Я, допустим, такой информации не имею. Я предполагаю, что если TSMC заявляет, что «на 14nm мы достигли уровня выхода годных более 90%», то имеются в виду не многоядерные процессоры, а некое усреднённое значение по всему, что у них там на линиях выпускается.
Но то такое. Какая здесь картина, думаю, будет сильно зависеть от топологии чипа. Там, естественно, есть какая-то управляющая схема, дефект на которой его убъет целиком. Также, вероятно, соотношение площади этой схемы и площади всего кристалла невелико. Вероятно также дефект на коммуникационной шине может грохнуть целую группу ядер. Впрочем, это всё гадание на кофейной гуще.
если TSMC заявляет, что «на 14nm мы достигли уровня выхода годных более 90%», то имеются в виду не многоядерные процессоры, а некое усреднённое значение по всему, что у них там на линиях выпускается.Процент выхода годных серьезно зависит от площади чипа и его конструкции (ECC, запасные части и т.д.), поэтому «усредненное значение по всему» — это даже менее информативно, чем средняя температура по больнице.
А дальше вопрос сводится к тому, какая гранулярность отключения неработающих частей у этого монстра. Если отключать надо целый элемент кластера, которых всего 84 — это один разговор. А если внутри у элемента кластера 1000 одинаковых ядер, каждое из которых отключаемое — это совсем другой разговор.

И все будут довольны.
можно сильно увеличить производительность банально за счет сокращения длины маршрутов электронов.На самом деле вообще не факт.
Во-первых, глобального роутинга совсем немного, и большая часть путей электронов (скажем, 99.99999%) находится внутри отдельных ядер.
Во-вторых, переходы с уровня на уровень имеют большие габариты (например пятьдесят микрон диаметр линии) и, вследствие этого, большие паразитные сопротивления, емкости и индуктивности. И площади на кристалле большое количество вертикальных связей заняло бы довольно много. А если вертикальных связей не так много, чтобы отгрызть существенный процент площади, то мы возвращаемся к первому пункту.
В принципе, при таких размерах можно ожидать, что оно хотя бы киловатт рассеивает. Если там есть киловатт, её можно использовать как электроплитку. Надеюсь, они защищают поверхность от царапин и убегающего супа?
Лет 15 назад где-то видел теплый пол из первых пентиумов
А еще говорят, что скорость света ограничивает размер процессора, думаю, что нет, и врядли даже на данный момент частоту ограничивает скорость света, иначе бы разгон был бы невозможен до 7 гигагерц. Скорее все ограничения только в тепловыделении и в сложности создния больших процессоров.
А еще говорят, что скорость света ограничивает размер процессораИнтересно, как именно она его ограничивает, если подвижность носителей заряда в любом применяемом в микросхемах материале радикально ниже скорости света.
В частности, для размеров микросхемы реальными ограничителями являются параметры длинных линий (в электротехническом смысле), а также входные ёмкости и задержки переключения логических вентилей, а вовсе не скорость света.
Например, для частоты 1 ГГц и какого-то разумного запаздывания по фазе (допустим 60 градусов), скорость свет даёт нам ограничение длины линии в (1/6«10^-9)*(3*10^8) ~ 5 см для аналогового сигнала и ещё раза в два больше для цифрового. Если бы это было так, то в микропроцессорах и микроконтроллерах можно было бы вовсе не делать дерево тактовых сигналов (которое в реальности может занимать десятки процентов площади чипа и количества транзисторов). И была бы не нужна дорогая, нудная, сложная и долгая процедура экстракции паразитных параметров из металлических межсоединений, которую приходится делать при моделировании уже для технологий 180-350 нм при длинах линий в сотни, а то и десятки микрон.
И собственно, именно все вышеизложенное побуждает учёных продолжать искать возможности поместить на кристалл оптические линии передачи данных вместо того, чтобы просто использовать металлические. Потому что в случае с оптикой к теоретическому пределу, обусловленному скоростью света, можно подойти радикально ближе. С химическими ракетами и нуль-транспортировкой примерно такая же история)
Если все это жутко секретно, зачем тогда рассказывать о нем сейчас? В сентябре с помпой бы все показали.
p.s. Если честно, сомневаюсь, что чип такого размера вообще будет корректно работать. Есть небольшой опыт проектирования. Сложность у такого процессора просто запредельная.
Хотя бы примерный вид системы охлаждения?Это было в презентации.
Если все это жутко секретно, зачем тогда рассказывать о нем сейчас? В сентябре с помпой бы все показали.Ежегодная выставка сейчас, ждать следующего года не хотелось.
Если честно, сомневаюсь, что чип такого размера вообще будет корректно работать.Там регулярный многоядерный кластер, почему бы ему не работать нормально, если все сделано без ошибок?
Представлен крупнейший в мире процессор размером 22×22 сантиметра с 400 000 ядрами и 18 ГБ локальной RAM