
Привет Хабр!
Многие постоянные читатели и авторы сайта наверное задумывались о том, какой жизненный цикл имеют опубликованные здесь статьи. И хотя интуитивно это и так более-менее ясно (очевидно например, что статья на первой странице имеет максимальное число просмотров), но сколько конкретно?
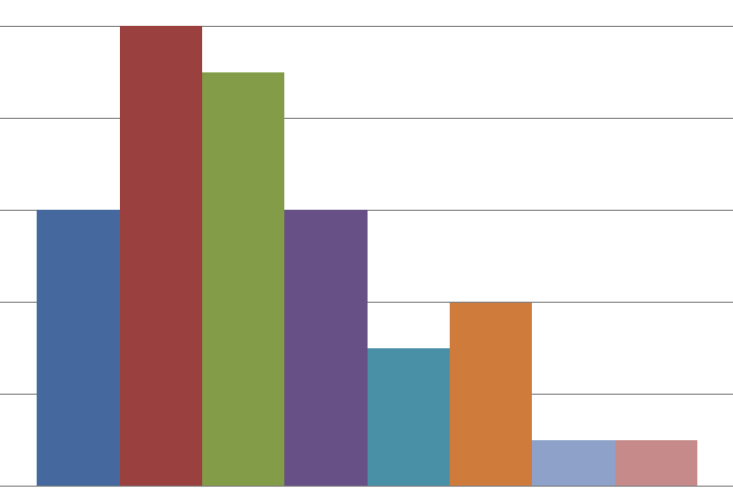
Для сбора статистики воспользуемся Python, Pandas, Matplotlib и Raspberry Pi.
Тех кому интересно, что из этого получилось, прошу под кат.
Многие постоянные читатели и авторы сайта наверное задумывались о том, какой жизненный цикл имеют опубликованные здесь статьи. И хотя интуитивно это и так более-менее ясно (очевидно например, что статья на первой странице имеет максимальное число просмотров), но сколько конкретно?
Для сбора статистики воспользуемся Python, Pandas, Matplotlib и Raspberry Pi.
Тех кому интересно, что из этого получилось, прошу под кат.



















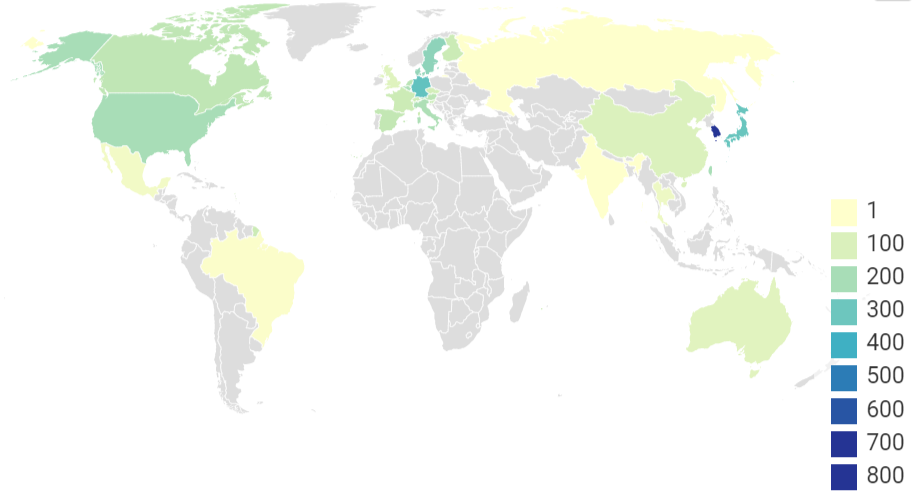


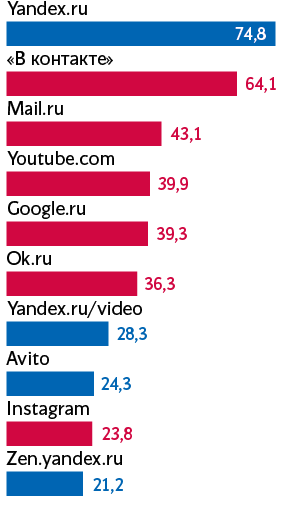 Вчера компания «Яндекс»
Вчера компания «Яндекс»