Про черепаху. Весёлая карусель №11 1980 © (реж. А. Петров)
Всем, кто когда-либо касался радиоэлектроники, хорошо известны понятие макетирования и польза применения макетных плат. Когда решение только появляется голове, нет никакого смысла отливать сразу все в бетоне. От первой идеи до финального результата может пройти не один эксперимент, может многократно поменяться элементая база, по результатам первичных проверок и исходная постановка может претерпеть значительные изменения.
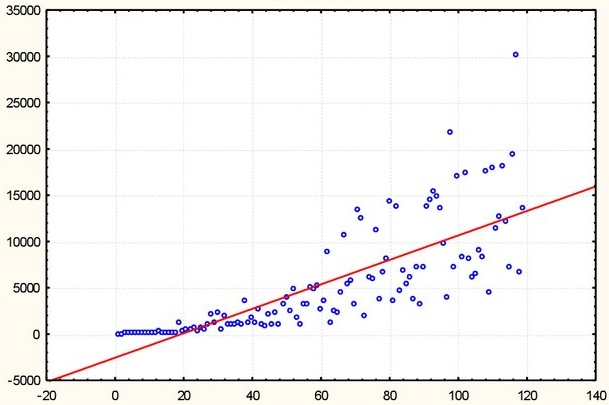
Степень автоматизации и цифровизации в современных компаниях достаточно велика. Фактически, можно говорить о двух плоскостях: плоскость материальных процессов и объектов (машины, каналы, вышки, вагоны, печи, ...) и плоскость цифровых потоков. Различные мобильные приложения, без ограничения общности, для пользователей мы можем рассматривать как «удлинитель» до материальных процессов. Для обеспечения качества и непрерывности материальных процессов необходимо обеспечивать полноту и актуальность соответствующих цифровых потоков, а также оперативно отвечать на вопросы, возникающие у представителей бизнеса.
Учитывая требуемую оперативность ответов, а также скорость изменений в окружающем мире, классический enterprise интеграционный подход с многолетними процедурами выбора решения и потом его долгого внедрения оказывается малопригодным. Да и собственную разработку стартовать на каждый запрос от бизнеса — тоже ничуть не быстрее и не дешевле.
Проведение аналогий с радиоэлектроникой позволяет найти неплохое решение.
Все предыдущие публикации.