Написать эту статью меня побудила заметка уважаемого
jobgemws "
Отправка запроса на все базы данных всех указанных серверов на примере MS SQL Server и C#.NET"
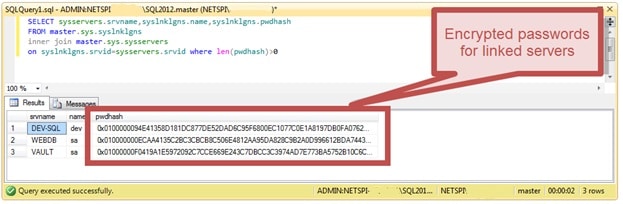
Я расскажу, как схожую задачу можно решить штатными инструментами MSSQLSERVER, а именно – SSMS (или, для экстремалов от администрирования — sqlcmd), быстро, без программирования, с помощью крошечного лайфхака.
Итак, у нас в организации имеется несколько десятков разнотипных MSSQLSERVER, разных редакций. Express превалирует, но это – не важно. Инфраструктура – старая, целиком унаследованная, и — «кусочно-непрерывная».
Задача: «запустить один и тот же запрос/пакет на нескольких серверах в нескольких базах данных», у нас, что называется, «редко бывает, но часто случается».
И то, что это «редко бывает» — не позволяет изобрести достойного обоснования для закупки или написания полноценного софта для централизованного администрирования всего зоопарка, а то, что «часто случается» — бывает, требует мгновенного решения в стиле «5 секунд до взрыва».
Но всё это – лирическое отступление, дисклаймер и всё такое.