Привет, Хабр!
Мы в билайне любим машинное обучение. В какой-то момент моделей машинного обучения стало так много, что это вынудило нас решать определенные задачи. Я Дмитрий Ермилов, руковожу ML в дирекции по искусственному интеллекту и цифровым продуктам. О решении одной такой задачи и будет этот рассказ.
Давайте представим, что у вас в компании большое количество моделей машинного обучения, каждая из которой может зависеть от нескольких десятков до нескольких тысяч признаков (фич). Причем разные модели могут зависеть от одних и тех же фич. Неожиданно случается несчастье, и одна из популярных фич ломается. Может произойти поломка на уровне подготовки данных, могут измениться внешние источники, отвалиться интеграции и прочее. Что делать с этим знанием? Конечно, бежать в продуктовые команды и кричать, что модели, которые зависят от этой фичи, могут деградировать, то есть их метрики качества могут снизиться. Вопрос только в том, какие модели могут деградировать и в какие команды бежать?
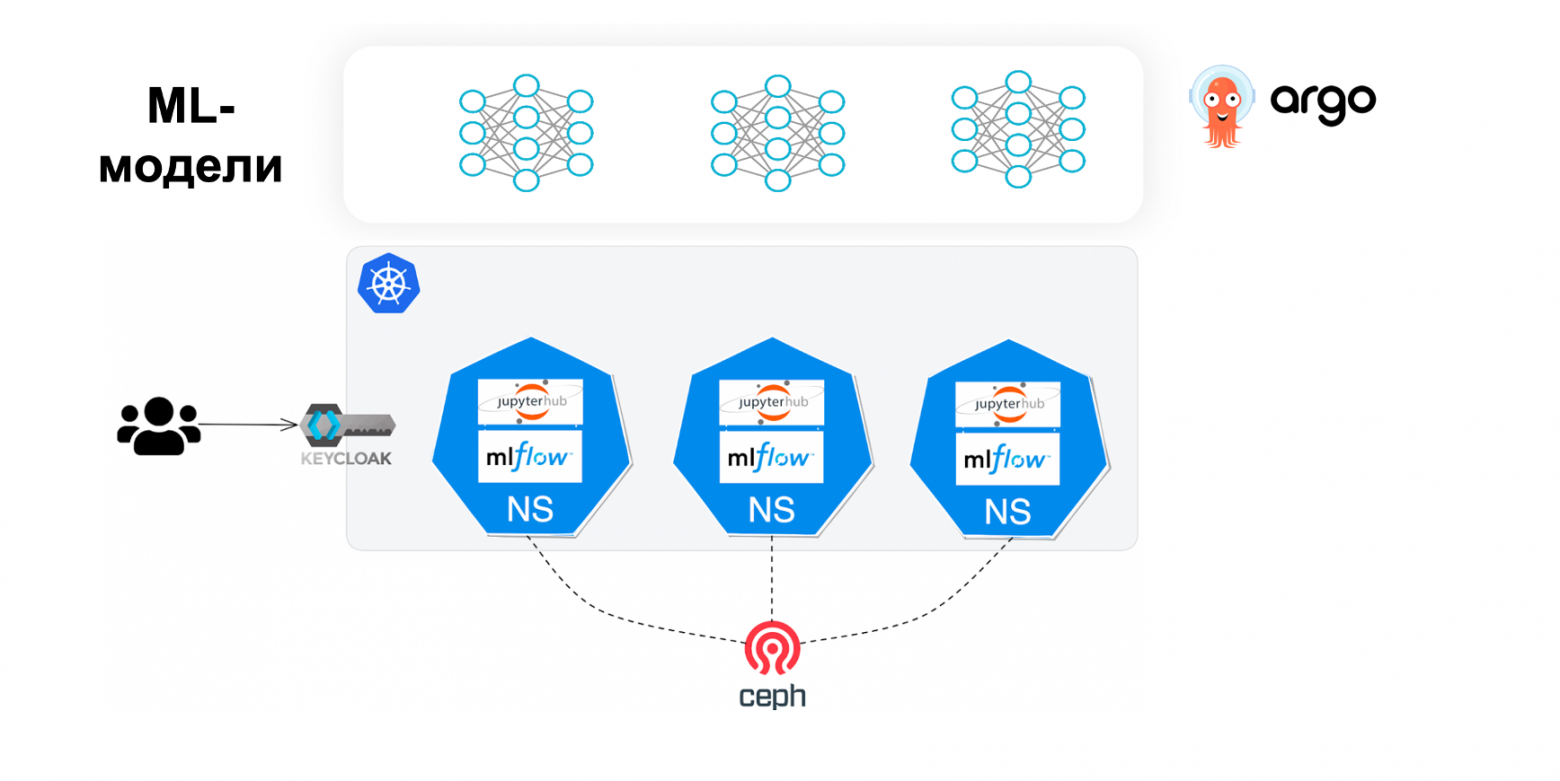
Напомним, в каких условиях мы анализируем данные и строим модели машинного обучения.