

В этой статье я хотел бы совсем чуть-чуть порассуждать о том, с какими намерениями авторы приходят на Хабр, а также рассказать вам чем занимаюсь лично я, чтобы быть одним из авторов Хабра.
В этой статье я хотел бы совсем чуть-чуть порассуждать о том, с какими намерениями авторы приходят на Хабр, а также рассказать вам чем занимаюсь лично я, чтобы быть одним из авторов Хабра.

Привет, Хабр! На связи вновь Андрей Дугин, руководитель группы видеоаналитики компании MTS AI. Сегодня я закончу рассказ о том, как мы с помощью ИИ выбираем обложки для сериалов в KION. Первую часть можно прочитать здесь.

Короткая версия
После длинного вступления, будет туториал по применению аугментации XYMasking к спектрограммам от ЭЭГ. Кто экономит время - код с примерами можно найти по ссылке в документации библиотеки.
Длинная версия
Albumentations - это Open Source библиотека для аугментации изображений.
Аугментация - это умное слово, которое в переводе с русского на русский означает "преобразование".
Q: Зачем это надо?
A: Основное применение - тренировка нейронных сетей на картиночных данных, например ImageNet.
Чем больше разнообразных данных сеть видит при тренировке, тем выше шансы, что она выучит закономерности, а не просто запомнит их.
На практике, пока прошлый батч картинок обрабатывается сетью на GPU, CPU занимается подготовкой нового батча, причем к каждому изображению применяются различные аугментации. Это позволяет достигнуть большего разнообразия данных, которые видит сеть.
Благодаря такому подходу нейронная сеть никогда не видит один и тот же набор пикселей, что способствует более высокой точности и обобщающей способности.
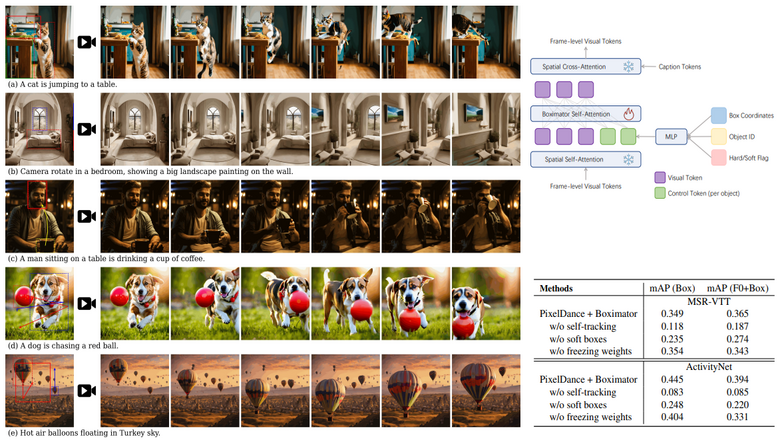
Одной из главных целей в генерации видео с помощью искусственного интеллекта является создание полностью управляемого, а также достоверного движения объектов. С помощью изменения сцен и улучшения качества по заданным критериям на основе предпочтений пользователя генерация контента выходит на совершенно новый уровень. К нему сделала шаг команда ByteDance Research, представив Boximator (box + animator) – новый инструмент для работы с видео на основе ИИ. ByteDance – родитель небезызвестного Tik-Tok, а из этого следует, что в скором времени там следует ожидать больше искусственно генерируемого контента. По-настоящему танцующих девушек или реального липсинка, судя по всему, станет значительно меньше :)
В этой статье вы познакомитесь с новой разработкой, узнаете о её новаторстве, архитектуре и функциях, а также о её преимуществах перед конкурентами.
Приятного прочтения!

Мы в Smart Engines много пишем про распознавание документов. И, конечно, для распознавания документов нам требуется обучать нейросети, в частности, сети, распознающие текст на картинке. А им, как известно, нужно больше золота данных. И сегодня мы бы хотели поговорить о влиянии обучающих данных на итоговую сеть и о том, как такие данные синтезировать.
Вашему вниманию предлагается небольшая заметка, посвящённая особенностям хранения одноканальных (серых) 16 бит изображений (как беззнаковых, так и знаковых) в PNG формате. В некоторых случаях интенсивности пикселей, получаемые из такого файла могут не соответствовать изначальным интенсивностям, под катом мы заглянем во внутренности PNG файла и разберёмся, почему так происходит.
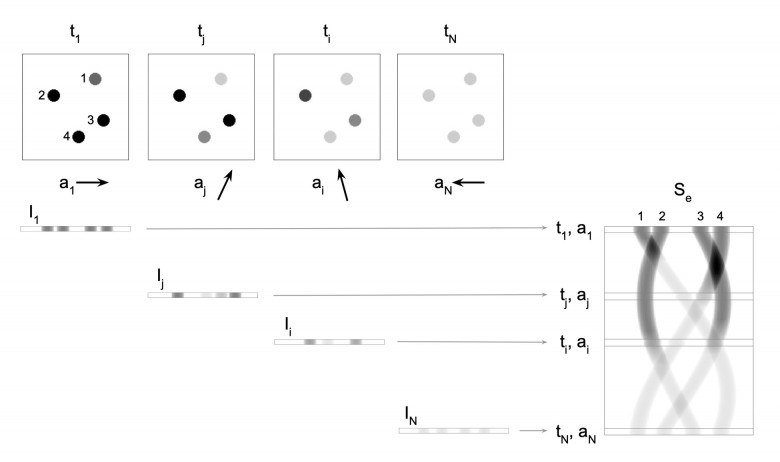
Привет, Хабр! Мы уже рассказывали про наши успехи в рентгеновской томографии. В этом же посте мы хотим поделиться с вами деталями наших исследований в динамической или 4D томографии. Здесь, для исследования объекта, который менялся в процессе проведения измерений, нам пришлось разработать новый алгоритм томографической реконструкции и даже провести гидродинамическое моделирование.
Но давайте обо всём по порядку.

В этой статье рассмотрим простой алгоритм обработки и распознавания значений из массива фотографий с показаниями цифровых индикаторов.
Не будет машинного обучения, нейросетей, только стандартные библиотеки Python для работы с изображениями.

Вы, вероятно, слышали о Тейлор Свифт и очень креативном наборе изображений, созданных одним из её фанатов. Что могу сказать - это был лишь вопрос времени, когда кто-то это сделает. Как мы знаем - не бывает плохой рекламы, однако что если вас зовут не Тейлор Свифт, и никто не создает и не ищет ваши изображения в Google?
Хотя это действительно очень печально, по крайней мере вы можете создать свои собственные изображения. Правда если вы хотите использовать генеративные модели для создания последовательных историй с элементами сюжета, это не так просто, как вам могло показаться. Создать одного-двух персонажа с помощью Dall-e или Stable Diffusion довольно просто. Но что, если вы хотите создать целую историю с одними и теми же персонажами в разных обстановках и стилях? Исследователи генеративных моделей неустанно работают над тем, чтобы упростить для вас процесс создания собственного творческого искусства с вашим любимым актером, но пока что это не так просто.
Так что же мы можем сделать сейчас? Давайте посмотрим.
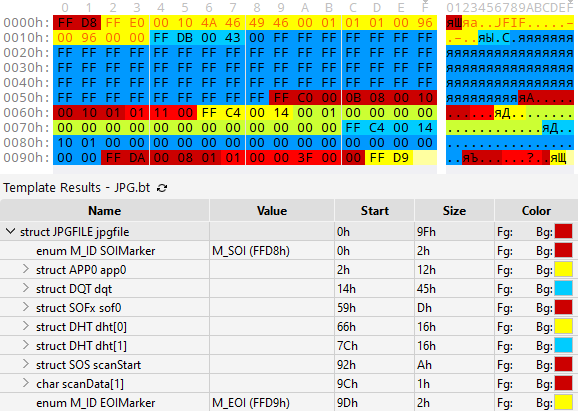
Недавно на Хабре была опубликована статья Разбираем самый маленький PNG в мире. Интересно, а какой самый маленький файл JPEG? В ответах на StackOverflow и Reddit можно встретить размеры 107, 119, 125, 134, 141, 160 байтов. Все они представляют серый прямоугольник 1 на 1. И кто прав? Все правы, просто такая разница объясняется различными режимами кодирования и степенью строгости соответствия стандарту. Описание всех нюансов разрослось до целой статьи cо всеми необходимыми подробностями для более-менее хорошего знакомства с самыми маленькими jpeg-ами. После краткой теории разберем 159-байтный файл на КДПВ, а затем рассмотрим способы его уменьшения.

Вашему внимания предлагается небольшой этюд, посвящённый отображению 10-битного цвета (1024 градаций по каждому каналу) на мониторе через OpenGL при помощи библиотеки GLFW. Под катом мы напишем пару небольших приложений, открывающих два окна, где рассмотрим тестовые изображения в восьмибитном и десятибитном режимах на оборудовании, поддерживающем такую опцию. Включение 10 бит в основном позволяет избавиться от эффектов «полосатости» (также используются термины «бандинг» или «постеризация»), возникающих на протяжённых градиентах со слабо меняющейся интенсивностью, когда вы начинаете видеть границы между отдельными градациями, но по какой-либо причине не хотите пользоваться дизерингом, подмешивая в изображение шум.
Дифференциальные уравнения и нейронные сети вместе? Не может быть или может... Neural ODE – подход в глубоком обучении, объединяющий идеи нейронных сетей и обыкновенных дифференциальных уравнений. Выглядит пугающе, давайте проверим!








Привет, Хабр! Меня зовут Андрей Дугин, я руководитель группы видеоаналитики компании MTS AI. В статье раскрою то, как мы создаём постеры для сериалов и подбираем материалы для обложек фильмов в онлайн-кинотеатре KION. О том, как мы решили эту задачу, я постараюсь рассказать максимально подробно и с техническими деталями. Забегая вперёд, упомяну, что для выбора одной-единственной обложки приходится обрабатывать сотни тысяч кадров фильмов и сериалов. Конечно же, не вручную. Интересно, как всё это реализовано? Тогда прошу под кат.

Всем привет! Буквально несколько дней назад была представлена новая модель семейства Yolo. Ее основная фишка заключается в том, что в отличие от своих старших братьев, она способна распознавать на изображении фактически любые объекты (которые интересуют человека) без предварительного обучения и делает все это в real-time режиме! Звучит неплохо, не так ли?
В этой статье мы попробуем разобраться, что же за магия скрывается внутри новой архитектуры.

Вам не обязательно придумывать промпты для генеративных нейросетей самостоятельно, если вы хотите получить картинку, соответствующую вашим требованиям. Существуют специализированные конструкторы, библиотеки с запросами, генераторы и даже маркетплейсы. С их помощью можно не только упростить использование «картиночных» нейросетей, но и сэкономить время на создание креативов для рекламных кампаний, которые вы можете запускать с помощью click.ru и других сервисов. Еще больше площадок для генерации промптов вы найдете в этой статье.

Некоторое время назад в нашей стране крупные сети магазинов стали вводить электронные чеки. В частности, магазины сети Rimi. Эти чеки покупатель получает по почте в виде PDF документа. У меня скопилось много таких чеков, и мне стало интересно посмотреть на разного рода статистику: например, на цены на различные товары в разное время, сколько чего было приобретено и т. п.
К сожалению, PDF документы, которые покупатели получают – это картинка. Получить интересующую меня информацию из них без оптического распознавания символов (OCR) невозможно. Однако, OCR, как оказалось, не на столько хорош, чтоб идеально справиться и точно всё распознать с первого раза. И это несмотря на то, что чеки достаточно хорошего качества: строки ровные, нет никаких артефактов в виде тёмных пятен, буквы достаточно одинаковые (правда присутствуют несколько разных шрифтов).


Прошлый год в Computer Vision запомнился тем, что появилось множество больших претрейненных сетей (Fondation Models). Самая известная - GPT4v (ChatGPT с обработкой изображений).
В статье я попробую простым языком объяснить что это такое (для тех кто пропустил), как меняет индустрию. Какие задачи стало проще решать. Какие продукты появились в последнее время и появятся в будущем.
И можно ли уже выгнать на мороз лишних "ресерчеров"?!

В настоящее время все более востребованными становятся данные радиолокационного наблюдения (РЛН) с космических аппаратов дистанционного зондирования Земли. Наблюдая повышенный интерес к этой предметной области с одной стороны и явный недостаток информационных материалов по теме обработки радиолокационных данных ДЗЗ с другой, решили написать статью, которая, надеемся, будет полезна для всех интересующихся темой ДЗЗ.