Несколько месяцев назад мой коллега
Тимур Палташев, менеджер в графическом отделении Advanced Micro Devices (AMD) в Саннивейл, Калифорния, предложил мне съездить и устроить семинар в Казахстане. Он будет рассказывать про гетерогенный компьютинг и большие процессоры AMD для игровых приставок и виртуальной реальности, а я буду рассказывать про маленькие процессоры MIPS для встроенных процессоров и машинного видения. Кроме этого мне было обещано попробовать конину, ферментированное молоко кобылицы (кумыс) и ферментированное молоко верблюдицы (шубат). «А тянь-шанские ели там будут?», — спросил я, и получив утвердительный ответ, воскликнул «я готов».
«А под каким соусом будет делаться данное мероприятие?», — спросил я у Тимура и его казахской одноклассницы
Гульфариды Тулемиссовой, которая делала всю работу по организации в
Almaty Management University. Выяснилось, что казахский народ в настоящее время заинтересовала тематика интернета вещей. Сети из сенсоров с беспроводной связью уже используются чтобы присматривать за шахтерами в казахстанских шахтах, не случилось ли с ними чего. Кроме этого в стране есть качественные программисты микроконтроллеров и инженеры встроенных систем, которые делают сейсмоанализаторы и телекоммуникационные ящики (в кооперации с россиянами и китайцами).
«Хорошо», — сказал я, у
Imagination Technologies и ее отделения
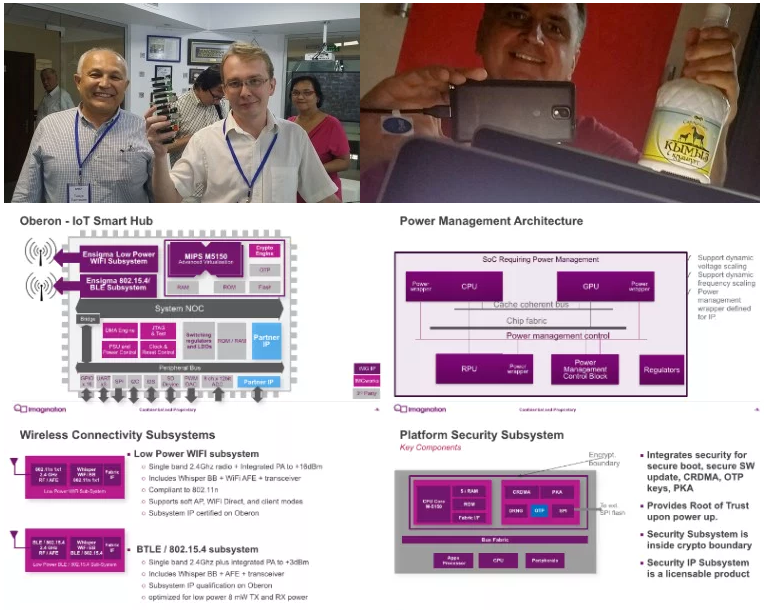
MIPS Business Unit, в котором я работаю, есть продукты в области интернета вещей, в частности ядра MIPS microAptiv, которые Samsung использует в платформе для интернета вещей
Samsung Artik 1. Кроме этого, у нас есть и материалы по микроконтроллерам, а также то, чего в Казахстане пока не хватает — знание ПЛИС-ов и проектирования микросхем, чем казахстанцы могли бы заняться в кооперации с россиянами, которые сейчас хорошо прогрессируют в данном направлении.
После этой беселы я поймал в коридоре нашего компанейского аналитика в области интернета вещей и спросил у него, что собственно такое интернет вещей.