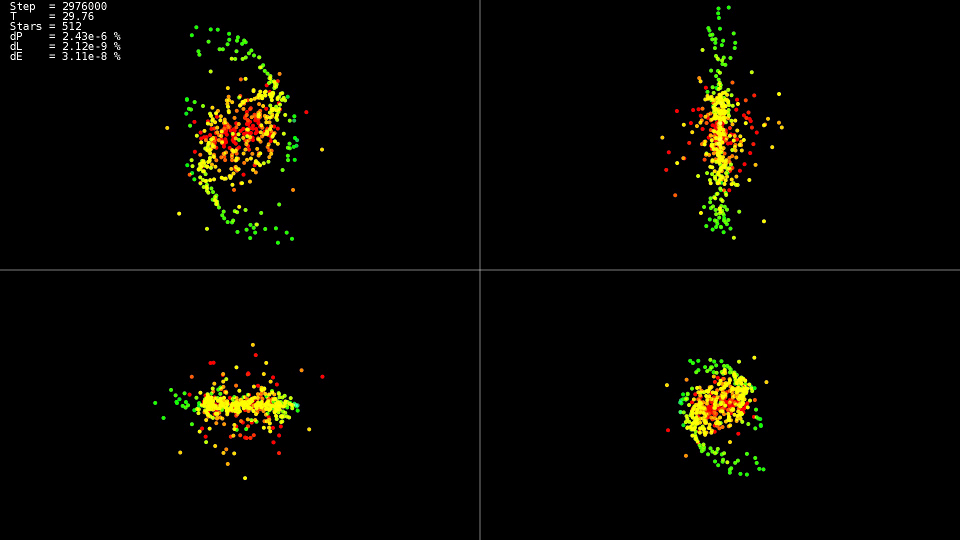
Привет, Хабр. В этой статье мы разберемся с уравнением Навье-Стокса для несжимаемой жидкости, численно его решим и сделаем красивую симуляцию, работающую за счет параллельного вычисления на CUDA. Основная цель — показать, как можно применить математику, лежащую в основе уравнения, на практике при решении задачи моделирования жидкостей и газов.