
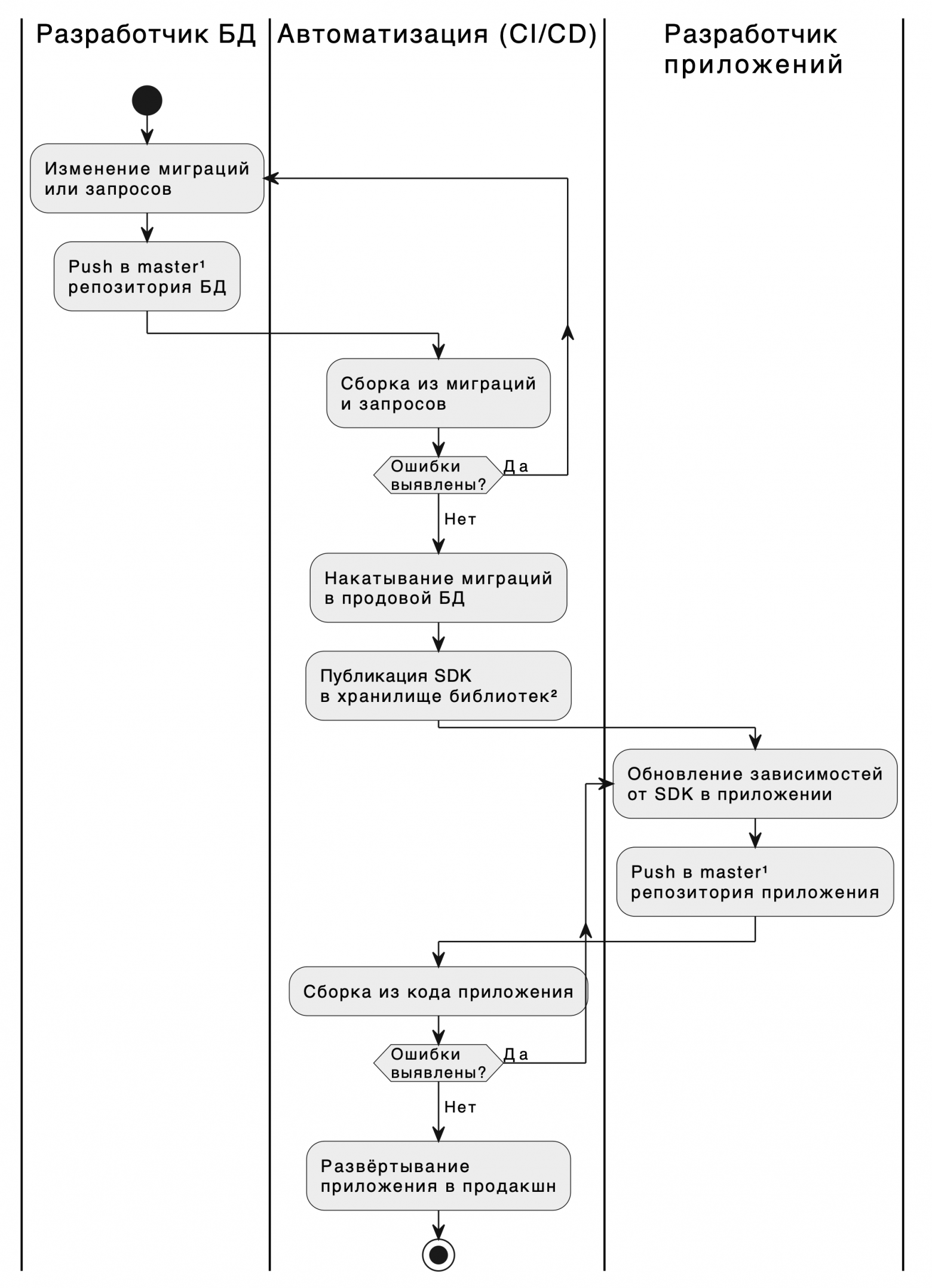
В статье рассматривается Continuous Deployment для БД с бесшовными релизами за счёт обратно-совместимых обновлений и автоматизации проверок совместимости с помощью подхода DB-First.
В статье рассматривается Continuous Deployment для БД с бесшовными релизами за счёт обратно-совместимых обновлений и автоматизации проверок совместимости с помощью подхода DB-First.

В данной публикации я поделюсь двумя основными причинами, по которым я предпочитаю избегать использования автоинкрементных полей в PostgreSQL и MySQL в будущих проектах. Вместо этого я предпочитаю использовать UUID-поля, за исключением случаев, когда есть очень веские аргументы против этого подхода.
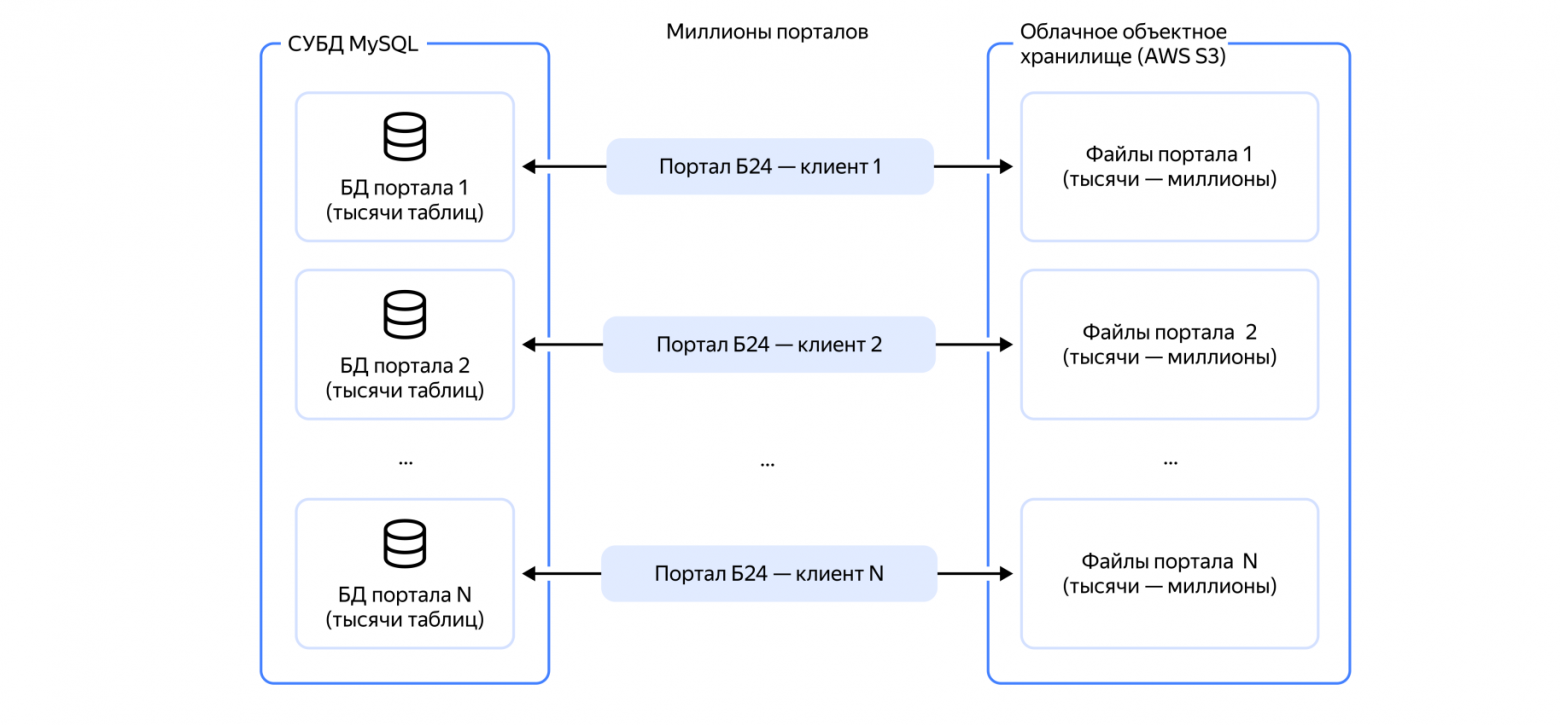
Меня зовут Александр, я руковожу направлением больших данных в Битрикс24. Клиенты нашего сервиса хранят миллиарды файлов: от документов до фотографий, — а моя команда предоставляет возможность строить бизнес-аналитику на основе этого множества данных. И нам важно позаботиться об их сохранности.
Более 10 лет назад мы продумали необходимую нам схему репликации объектного хранилища в облаке. Затем файлы клиентов потребовалось перенести в другое облако, и нам очень хотелось также перенести все наши наработки в режиме «Ctrl+C, Сtrl+V».
В статье расскажу, как мы организовали резервирование данных в парадигме слабого связывания и как перенесли эту схему в Yandex Cloud без потери важных нам деталей.

 Привет, Хаброжители!
Привет, Хаброжители!
Учеба в политехе заключается в сдаче лабораторных работ. Буквально. Очень редко бывает такое, что на парах мы чему-то учимся, зачастую все завязано на самообучении. Грубо говоря, вот вам методичка, разбирайтесь сами, через неделю дедлайн.
В связи с этим мы столкнулись с очередями на сдачу этих лабораторных. Сначала просто писали в общий чат, кто каким будет в очереди (например, "я первый", "я вторая", "я третий" и т.д.). Далее решили создать расшаренную таблицу в гугле для формирования очередей. Однако долго она тоже не прожила, так как со временем появились "умники", которые стали ставить себя первыми в очереди, сдвигая остальных вниз. Потом общий доступ для таблицы закрыли, и было принято решение для записи на сдачу писать старосте, он, в свою очередь, будет добавлять студентов в список. Но староста группы не может быть постоянно на связи, иными словами, оперативно добавиться в очередь было просто невозможно.
В связи с этим я задумался над созданием автоматизированной очереди. В качестве стека основных технологий выбрал HTML5+CSS3 для фронтенда, PHP для бэкенда. В качестве СУБД был выбран phpMyAdmin (SQL-DB). В первую очередь, конечно, необходимо было продумать структуру базы данных. Предметная область информационной системы уже была сформулирована: "Очередь на сдачу лабораторных работ с возможностью записи по отдельным дисциплинам, удаления своей записи. Учет истории создания записи, удаления записей, включая время записи. Возможность смены пароля, просмотра профиля." Даталогическая модель БД была построена в MySQL Workbench 8.0 CE в нотации IDEF1X.
Привет! Меня зовут Александр Ежков, я Backend-разработчик в AGIMA. Занимаюсь созданием и поддержкой внутренних сервисов для компании. А конкретно сейчас — нашей DWH-системой. Мы построили ее из Open-source продуктов. В этой статье расскажу, какие продукты мы используем, какие хитрости придумали для работы с ними как вся система работает вместе.

Сегодня обсудим общие вопросы, связанные с миграцией баз данных на новую платформу. Как обычно, акцент сделан на системах 1С:Предприятие, как самых популярных на российском рынке. Но многие рекомендации универсальны и годятся для всех ИТ-систем.

21 марта Redis Ltd. объявила, что, начиная с Redis 7.4, ее «in-memory data store» будет выпускаться под несвободными лицензиями с доступным (source-available) исходным кодом. Новость малоприятная, но вполне ожидаемая. Необычно в этой ситуации обилие альтернатив для тех, кто хочет остаться со свободным ПО: есть как минимум четыре варианта замены, включая уже существующий форк под названием KeyDB и недавно анонсированный проект Valkey от Linux Foundation. Вопрос теперь в том, что предпочтут пользователи, провайдеры и создатели дистрибутивов Linux.
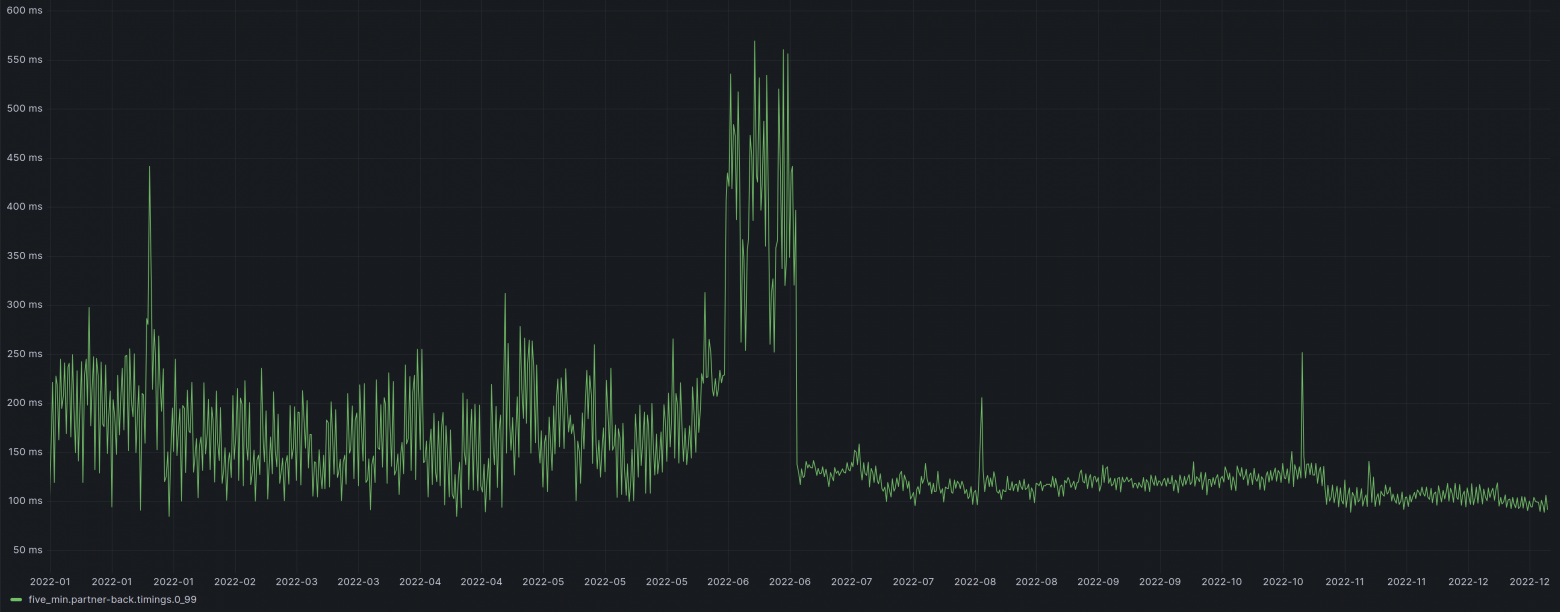
Всем привет! Я Сергей, работаю в B2B-команде Яндекс Маркета последние 3,5 года. Как уже понятно из заголовка, сейчас я вам расскажу про yet-another-миграцию с базы на базу, которая началась в середине 2021 года и заняла почти год. Получается, мемуары.
Вас ждёт рассказ о том, как мы:
- несколько месяцев чинили тесты и делали трансформер;
- десятки раз переливали данные;
- чинили баги незаметно для пользователей;
- заставили сервис работать на PostgreSQL быстрее, чем он работал на Oracle.

Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В этой лекции мы узнаем, что такое план выполнения запроса, как и зачем его читать (и почему это совсем непросто), и о каких проблемах с производительностью базы он может сигнализировать. Разберем, что такое Seq Scan, Bitmap Heap Scan, Index Scan и почему Index Only Scan бывает нехорош, чем отличается Materialize от Memoize, а Gather Merge от "просто" Gather.
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись (часть 1, часть 2).

Первоначальная документация YDB, опубликованная в рамках open-source запуска в 2022 году, имела структуру, на которую в значительной степени повлиял закон Конвея. Создание проекта с открытым исходным кодом значительно повышает планку того, что ожидается от документации по технологии. В нашем случае для быстрого создания большого количества контента перед запуском потребовалась командная работа по принципу «разделяй и властвуй». На раннем этапе такое четкое владение каждым фрагментом было полезным. Однако, поскольку общий объем документации со временем продолжает расти, читателям становится всё труднее находить нужную им информацию. Чтобы решить эту проблему, мы перепроектируем структуру документации, чтобы она была ориентирована на пользователя. Таким образом, если вы являетесь командой, работающей с кластером YDB, каждый может иметь свою собственную любимую директорию в документации в соответствии со своей ролью в команде и не отвлекаться на контент, ориентированный на читателей с другой ролью.
Эта реструктуризация ещё в процессе: появился новый раздел для DevOps-инженеров, а также дополнительные разделы для администраторов баз данных, разработчиков приложений, инженеров по безопасности, аналитиков и т.д. Перемещение контента может потребовать выработки новых привычек, но в долгосрочной перспективе такая структура должна упростить навигацию. Мы создаём перенаправление со старого URL на новый при перемещении любой страницы документации, чтобы свести неудобства к минимуму.

Привет, Хабр!
О том, как правильно готовить кластеризацию для PostgreSQL, написано уже достаточно. А потому сегодня вашему вниманию предлагается небольшой сборник рекомендаций, как администратору СУБД под управлением Patroni гарантированно проснуться в три часа ночи от звонка из отдела мониторинга.











Чего у меня не отнять, дак это мастерства заголовка...
В какой-то момент при локальной разработке (да, в общем-то и при тестировании на иных стендах) задумываешься о том, как бы избавиться от довольно монотонных действий. Одним из них является ввод пароля в рамках процесса аутентификации в PostgreSQL. В этой статье я расскажу как слегка автоматизировать данный процесс.
Данная статья является легким переосмыслением того, что я написал на медиуме. Ибо думать я продолжаю на русском.
TL;DR исходники к вашим услугам.
В рамках любых взаимодействий мы сталкиваемся с такими сущностями как авторизация и аутентификация. Повторять в 100500 раз что есть что я не буду (но мне не лень такую длинную ремарку напечатать, ага). В рамках PostgreSQL первое обеспечивается через Roles, а второе через Privileges.

Jesse Anderson, директор Big Data Institute, и Martin Kleppmann, автор книги «Высоконагруженные приложения. Программирование, масштабирование, поддержка», вместе исследуют меняющийся ландшафт обработки данных. Они начинают с истории создания книги Мартина, подчеркивая важность искусства задавать правильные вопросы. Мартин рассказывает об изменениях, произошедших в отрасли с 2017 года, подчеркивая рост облачных сервисов. Затем беседа приобретает новый поворот, когда Мартин погружается в академические круги, делясь своими соображениями о программном обеспечении для совместной работы на основе локального подхода и увлекательном мире Automerge. Начинающие инженеры‑программисты получат несколько советов о том, как найти тонкий баланс между простотой и гибкостью. В завершение обсуждают о различных карьерных путях в динамичной сфере инженерии данных, что делает разговор полезным для профессионалов на любом этапе их пути.

В жизни любого разработчика наступает момент, когда он роняет прод. Представьте: полдень, в Skyeng час пик, тысячи запланированных онлайн-уроков, а наша платформа лежит…
Все упало из-за ошибки в процессе деплоя, которая связана с тонкостью PostgreSQL. К сожалению, на этом моменте у нас прокололась не одна команда. И чтобы такое больше не произошло ни у нас, ни в другой компании — велкам под кат.

О плюсах платформы можно узнать на сайте производителя, по открытым материалам с конференций. Данный материал делает акцент на минусах системы, но это не значит, что платформа не заслуживает внимания клиентов. Лучший вариант всегда — сделай пилот до! И так, обратим внимание коллег из LuxMs на недостатки и риски:

Приветствую, current_user()!
Хочется тебе показать, как можно хранить sql-скрипты объектов БД так, чтобы было удобно и разработчику, и ревьюеру, а так-же рассказать о плюсах и минусах такого подхода.
Так-же хотелось-бы узнать твоё мнение о таком подходе и обсудить, возможно стоит что-нибудь добавить в нём.

Любая компания, ориентированная на персоналистское взаимодействие с пользователем, так или иначе занимается сбором, обработкой и сохранением его персональных данных (ФИО, возраст, электронная почта, место проживания или пребывания, объемы приобретенных товаров и многое другое). Подобные материалы интересны хакерам и иным злоумышленникам: правильно обработав эту информацию, всегда возможно, используя инструменты социальной инженерии, получить доступ к деньгам клиента.

В последние месяцы в мире FirebirdSQL происходит значительное оживление: помимо релиза Firebird 5 было опубликовано много инструментов, статей и материалов, что я решил подготовить небольшой дайждест для читателей Хабра, которые, вероятно, соскучились по новостям о любимой СУБД.
Во-первых, вышла новая версия Калькулятора Конфигураций для Firebird, с поддержкой Firebird 5. В калькулятор (полностью бесплатный, доступен без регистрации) вводятся характеристики сервера, ...