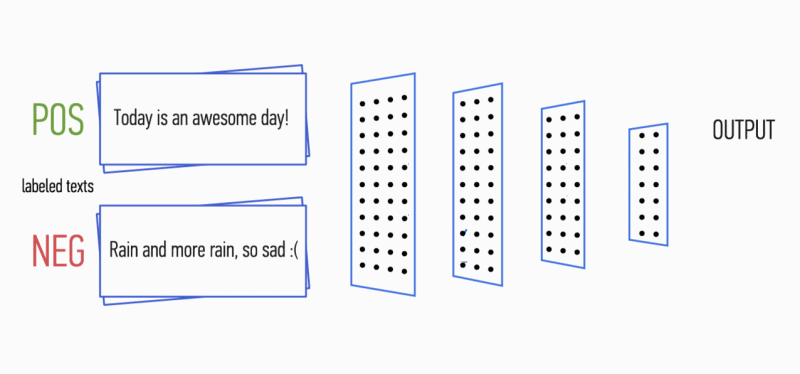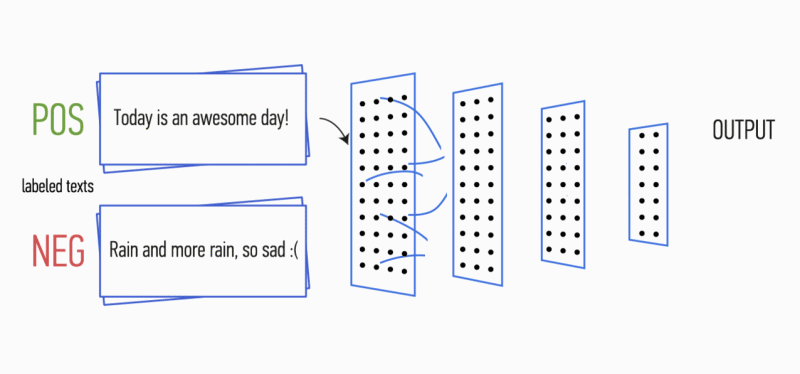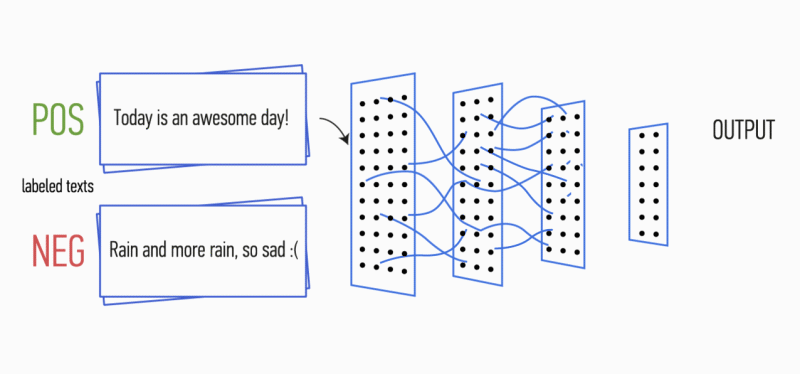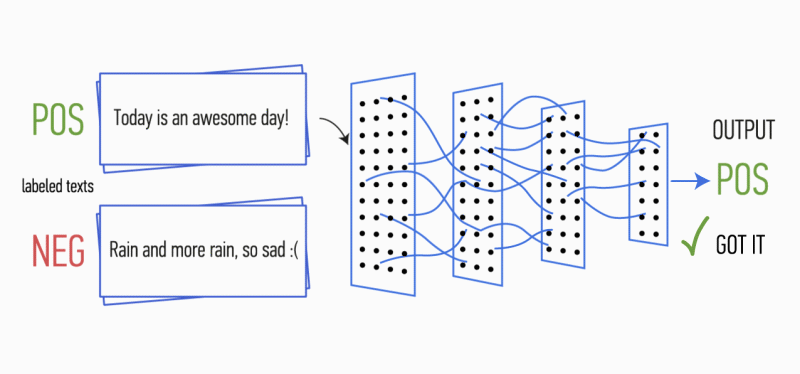
11 октября провели у нас в офисе Data Science Meetup. Говорили про нагрузочное тестирование, компьютерное зрение и реализацию скоринговых карт.
Под катом — делимся видео и презентациями докладчиков.

*фарм — (от англ. farming) — долгое и занудное повторение определенных игровых действий с определенной целью (получение опыта, добыча ресурсов и др.).
Недавно (1 октября) стартовала новая сессия прекрасного курса по DS/ML (очень рекомендую в качестве начального курса всем, кто хочет, как это теперь называется, "войти" в DS). И, как обычно, после окончания любого курса у выпускников возникает вопрос — а где теперь получить практический опыт, чтобы закрепить пока еще сырые теоретические знания. Если вы зададите этот вопрос на любом профильном форуме, то ответ, скорее всего, будет один — иди решай Kaggle. Kaggle — это да, но с чего начать и как наиболее эффективно использовать эту платформу для прокачки практических навыков? В данной статье автор постарается на своем опыте дать ответы на эти вопросы, а также описать расположение основных грабель на поле соревновательного DS, чтобы ускорить процесс прокачки и получать от этого фан.

В четверг 4 октября я побывал на конференции DataVizDay в Минске в качестве спикера. Поделюсь самыми интересными идеями и впечатлением от Миснка.
Ключевые идеи:
Образ поп звезд привлекает миллионные аудитории, он состоит из внешнего вида, музыки, поступков и конечно же текстов их песен.
О чем поют популярные исполнители? Во все времена темы одинаковые: любовь, одиночество, секс, развлечения, вечные ценности.
Однако наверняка вы и сами чувствовали, что от каждого исполнителя остается свой осадок в душе, свой привкус. И вроде бы слова одинаковые, а оттенки разные. И у каждого — свой.
Та картина, которую артист рисует своими словами — уникальна и отображает их внутренний мир, их психологические портреты.
В статье мы пробуем через призму AI заглянуть за завесу слов и различить за ними душу таких популярных звезд как Drake, Rihanna, Coldplay, Twenty One Pilots, Dua Lipa, The Chainsmokers и Katy Perry.
Нашли кого-то из любимых артистов и Вам хочется узнать их скрытые эмоции и переживания?

Читайте дальше о том, как современная технология обработки естественного языка от IBM Watson Personality Insights помогает «читать между строк» эмоции, потребности, ценности и психологические особенности.

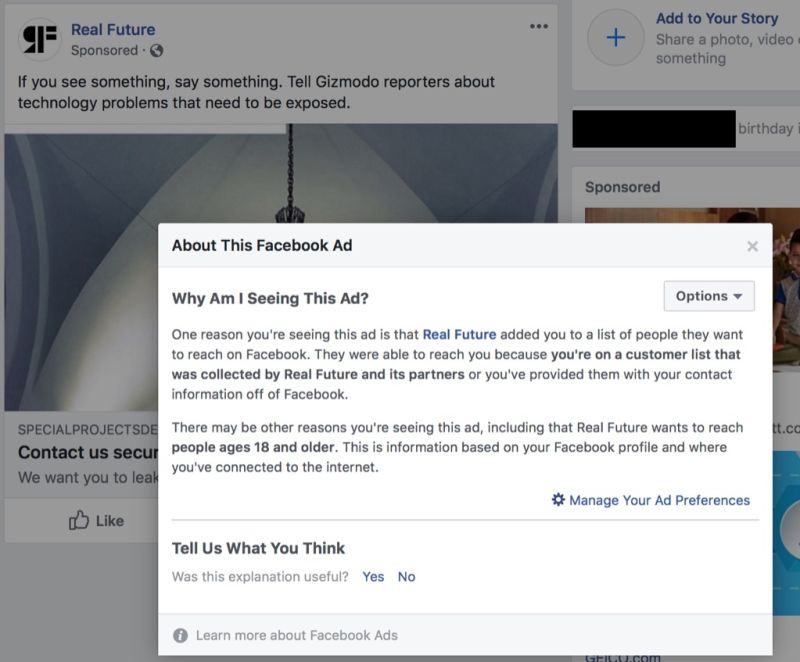
На прошлой неделе я запустила объявление в Facebook, которое было нацелено на профессора по информатике по имени Алан Мислов. Алан Мислов изучает, как конфиденциальность работает в социальных сетях и разработал теорию, согласно которой Facebook позволяет рекламодателям добираться до пользователей по контактной информации, собранной весьма нестандартными способами.
Я помогала ему проверить эту теорию, нацеливая рекламную кампанию на его аккаунт, таким способом, который по официальным рекомендациям от Facebook не должен был сработать. Я настроила рекламу для показа пользователю учетной запись Facebook, сопоставленной с номером стационарного телефона офиса Алана Мислова. Номером, который Мислов никогда не предоставлял в Facebook.
Алан Мислов увидел объявление всего через несколько часов
Друзья, добрый день.
Есть четкое понимание, что большая часть ICO проектов это по сути своей совсем нематериальный актив. ICO проект это не автомобиль мерседес-бенц – который ездит вне зависимости от того что его кто любит или нет. И основное влияние на ICO оказывает настроение народа – как настрой на основателя\founder ICO, так и самого проекта.
Было бы хорошо как-то измерить настрой народа по отношению к основателю ICO и\или к ICO проекту. Что и было проделано. Отчет ниже.
Результатом стал инструмент сбора позитивного\негативного настроения из Интернетов, в частности из твиттера.
Моё окружение это Windows 10 x64, использовал язык Python 3 в редакторе Spyder в Anaconda 5.1.0, проводное подключение к сети.
Настрой буду получать из постов твиттера. Сначала выясню, чем сейчас занимается основатель ICO и насколько положительно об этом отзываются на примере пары известных личностей.
Буду использовать python библиотеку tweepy. Для работы с твиттером необходимо в нем зарегистрироваться как разработчику, см. twitter/. Получить критерии доступа к твиттеру.


Сегодня в Сети можно найти огромное количество разнородной информации о наиболее востребованных языках программирования, библиотеках, фреймворках, операционных системах и прочих сущностях — назовём их технологиями. Число этих технологий постоянно растёт и становится ясно, что каждому, желающему пойти путём разработчика, необходимо фокусироваться на изучении некоторого наиболее востребованного стека, связанного с какой-либо ключевой технологией.

Сегментацией людей с помощью нейронных сетей уже никого не удивишь. Есть много приложений, таких как Sticky Ai, Teleport Live, Instagram, которые позволяют выполнять такую сложную задачу на мобильном телефоне в реалтайме.
Итак, предположим планета Земля столкнулась с внеземными цивилизациями. И от пришельцев из звездной системы Альфа Центавра поступает запрос на разработку нового продукта. Им очень понравилось приложение Sticky Ai, которое позволяет вырезать людей и делать стикеры, поэтому они хотят портировать приложение на свой межгалактический рынок.