
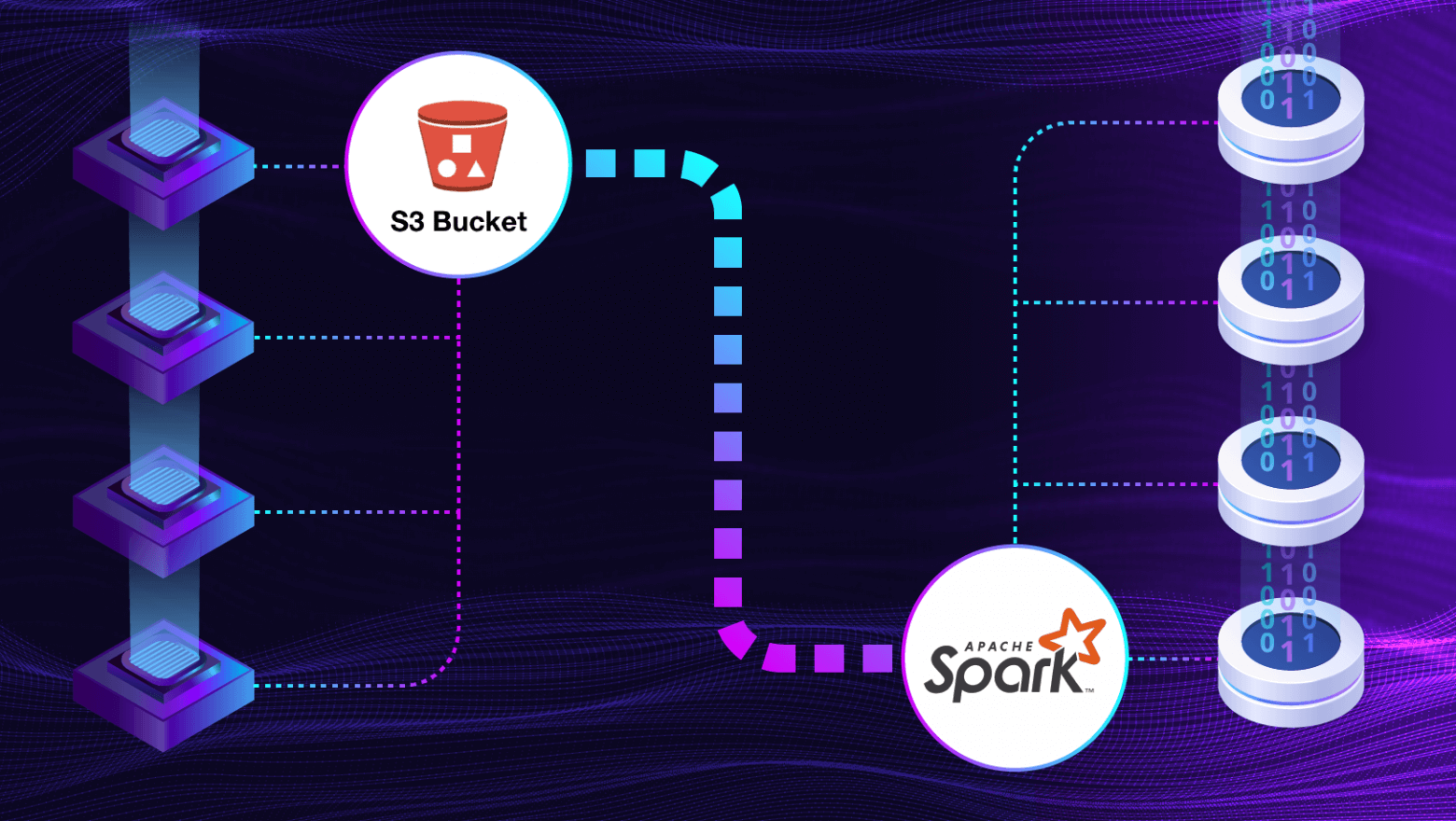
Всем привет!
В этой статье мы расскажем, как нам удалось настроить взаимодействие Apache Spark и S3 для обработки больших файлов: с какими проблемами пришлось столкнуться и как нам удалось их решить.
Всем привет!
В этой статье мы расскажем, как нам удалось настроить взаимодействие Apache Spark и S3 для обработки больших файлов: с какими проблемами пришлось столкнуться и как нам удалось их решить.

Несколько месяцев я пытался разбираться в ML и когда мне под руку попался легенький хакатон для школьников, связанный с CV, я решил, что это мой шанс!
Изучая задачу, я понял, что мне нужно обнаруживать чаек по фотографиям. Для решения задачи я решил использовать yolov8s, потому что он мне показался оптимальнейшим из линейки yolov8 для моего случая. Также, мне как-то рассказывали про sahi (Slicing Aided Hyper Inference), и я решил, что это мой шанс попробовать этот инструмент в качестве улучшения конечного результата.
Итак, у меня был датасет, включающий фотографии, уже разбитые на train, validation, test, запакованные в zip архив. Первым делом, я клонирую репозиторий для yolov8, устанавливаю и импортирую необходимые на первых парах библиотеки и распаковываю то, что нужно распаковать.

Привет, Хабр! Меня зовут Иван Сивков, я наставник на курсе «Специалист по Data Science» в Яндекс Практикуме. В этой статье покажу, как построить пайплайн в библиотеке scikit-learn на базе встроенных инструментов и сократить количество кода при преобразовании данных. Эта статья рассчитана на новичков, которые только начинают изучать Data Science, но уже знают основные понятия.

Что делать, когда нет входных данных для вычислений и обработки системой? Как управлять процессом, когда точно неизвестно, как именно протекает процесс? На помощь приходят теоретические расчеты и кратковременные эксперименты...


Продолжаем разбирать подходы призеров Kaggle-соревнований от американской национальной футбольной лиги (NFL). Участники этого челленджа детектировали столкновения игроков в американском футболе, анализируя данные с видеокамер и датчиков, прикрепленных к форме футболистов. В продолжении первой части статьи расскажу про самые успешные подходы к этой задаче.

Привет, Хабр! Сегодня рассказываем, чем отличаются подходы к построению распределённых хранилищ данных Data Warehouse (DWH) и Data Lake и в чём специфика задач специалистов, работающих с данными.
В статье сначала опишем паттерны построения распределённых хранилищ, чтобы понимать, через какие процессы проходят данные. А после поговорим о задачах специалистов по работе с данными и необходимых для каждой позиции навыках.
P.S. На картинке спрятаны 6 инструментов для работы с данными. Узнали их?

Предположим: вы полны желания изучить манящий массив данных. К счастью, для этого достаточно вашего компьютера. Итак, вы открываете блокнот Python или REPL, чтобы начать работать: какую библиотеку использовать? Естественно, вы можете обратиться к старой доброй Pandas. А как насчет новой модной библиотеки фреймов данных, например Polars или datatable? А ещё, для разнообразия, можно попробовать встроенный SQL с помощью DuckDB.
Давайте погрузимся в прекрасную область фреймов данных, чтобы сделать выбор!
PS: Используйте DuckDB, если вам удобно работать с SQL, Polars или Pandas с поддержкой PyArrow, если вам не нужно какое-то специфическое расширение NumPy, и задействуйте PyArrow в том случае, если вы не против ручной оптимизации.
Привет, Хабр! Я недавно начал свой путь в data science, хочу поделиться реализацией алгоритмов по обработке матриц.

В этой статье хотелось бы погрузить вас в мир данных и вспомнить: какие встречались проекты, связанные с хранилищами и данными, какие задачи приходилось решать, а также какие навыки пригодились.
Но вначале придется разобрать извечные вопросы: кто же такие аналитики, что такое данные и понять – должны ли они быть вместе?

Всем привет! В предыдущих статьях (1 и 2) я рассказывал про концепцию индексирования данных смарт-контрактов на блокчейне в общем и в частности через средства The Graph, а также про то, как использовать готовые "сабграфы" на The Graph Hosted Service, чтобы, не написав ни строки кода, делать к ним GraphQL запросы и получать данные популярных децентрализованных приложений. Однако, если вы присматриваетесь к Web3 разработке, то вероятно вам и самим придется разрабатывать такие сабграфы для своего приложения. Эту тему (разработка собственных сабграфов стандарта The Graph) я бы и хотел осветить в данном материале. Чтобы пример был не сферический и в вакууме, будем рассматривать существующий смарт-контракт проекта TornadoCash.

Databricks — это аналитическая платформа для облачных вычислений, работы с большими данными и машинного обучения. Компания разрабатывает data lake и работает с фреймворком Apache Spark. Приводим перевод статьи Databricks о нововведениях Apache Spark 3.4, который вошел в релиз Databricks Runtime 13.0.








Приветствуем читателей Хабра! Мы, команда дата-сайентистов и дата-аналитиков компании «ДатаЛаб»* (ГК «Автомакон»), запускаем серию статей, в которых поднимем актуальные темы и предложим свои решения проблемных ситуаций онлайн-ритейла. Каждый день мы решаем бизнес-задачи ритейла по повышению продаж, сокращению издержек и управлению рисками.
Стартуем со статьи, в которой рассмотрим одну из самых распространенных проблем в онлайн-ритейле – отсутствие товара (out-of-stock) в моменте и поделимся рекомендациями по ее устранению.
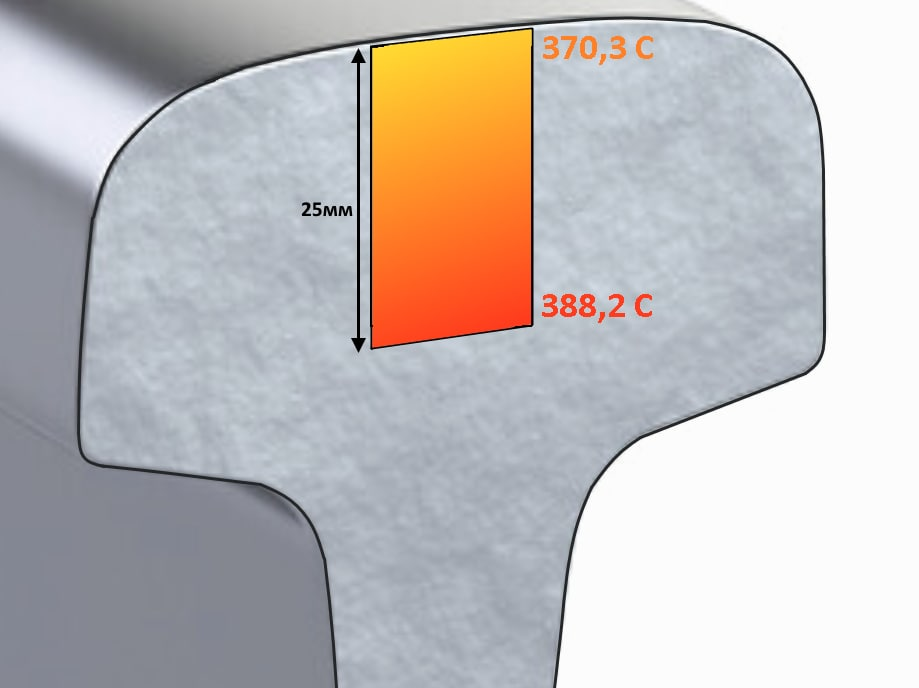
Цифровая трансформация подобна ремонту: однажды начавшись, не заканчивается уже никогда. Разработчики и дата-сайентисты выискивают по цехам ЕВРАЗа — где бы ещё причинить пользу своими знаниями и умениями? На этот раз им на глаза попалось производство рельсов. И увидели они, что это хорошо, но можно ещё лучше…
Конечно, в действительности процесс принятия решений выглядит немного иначе. Однако термоупрочнение рельсов — действительно перспективный объект для цифровизации. Под катом вы сможете прочесть, как строилась математическая модель остывания рельса, а главное — зачем.


В последние годы растет сложность IT-инфраструктуры в компаниях и, соответственно, спрос на сервисы мониторинга ее работоспособности. Их все больше покупают, в них все чаще инвестируют. Но в данной статье мы расскажем о новом смежном тренде - Data Observability. Что это и чем она отличается от Infrastructure Observability?
Классический мониторинг - это наблюдение за работой инфраструктуры и приложений. А Data Observability позволяет осуществлять мониторинг потоков данных (и даже бизнес-процессов) и находить в них сбои.
Рассмотрим несколько примеров.


Всем привет! Представим, что вам нужен доступ к данным каких-либо смарт-контрактов на Ethereum (или Polygon, BSC и т.д.), например, Uniswap, SushiSwap, AAVE (или даже PEPE-coin) в реальном времени, чтобы анализировать их с помощью стандартных инструментов дата-аналитиков: Python, Pandas, Matplotlib и т.д. В этом туториале я покажу инструменты для доступа к данным на блокчейне, которые больше похожи на хирургический скальпель (сабграфы The Graph), чем на швейцарский нож (доступ к RPC ноде) или, скажем, молоток (готовые API от компаний-разработчиков). Надеюсь, мои неумелые метафоры вас не пугают. Кому интересно научиться, добро пожаловать под кат.
Скажите, если к вам придёт потенциальный клиент, но вместо красивого сайта, приложения или сотрудника его встретит чатик с текстовой нейросетью, которая что-то знает о вашем продукте и теоретически может его продать – вам будет комфортно? Это, может, нетипично для энтузиаста, закопавшегося по уши во всякие GPT и PaLM, но лично мне в такой ситуации будет очень страшно. А вдруг нейросеть продаст что-то несуществующее? Или вообще ничего не будет продавать? Или нагрубит клиенту?
Похоже что эти опасения разделяют многие: каждую неделю появляется ворох новых сервисов, пишущих нейросетью что-то для последующей обработки человеком (начиная с кода и заканчивая рекламными текстами), а вот примеров, в которых нейросеть "пускают" напрямую к клиентам далеко не так много. Но, как мне кажется, я нашёл способ от этих опасений в существенной степени избавиться. (Конечно, может быть, кто-то уже нашёл его раньше и я просто этого не заметил, но что уж поделаешь, сфера новая и очень быстро развивается.)
В этой статье я на примере простого сервиса для маршрутизации заявок в техподдержку покажу свой подход к созданию сервисов на нейросетях, которые не страшно напрямую использовать для общения с клиентами или в других важных процессах. А также приблизительно измерю процент случаев, в которых такой сервис сможет корректно отработать, и постараюсь отследить влияние различных особенностей запросов к нейросети на этот процент.