В последнее время вопрос безопасности данных обсуждается очень широко, но довольно часто речь идет прежде всего о защите сети. В современных условиях это вполне объяснимо, ведь процент сотрудников, работающих дистанционно, постоянно увеличивается и мы все сильнее полагаемся на облачные технологии. Однако выбор правильного способа защиты самого устройства хранения данных остается не менее актуальным вопросом.
Для обеспечения безопасности данных необходимо внимательно проанализировать все компоненты — системы, аппаратное оборудование, программное обеспечение и приложения, чтобы определить возможности для улучшения существующей инфраструктуры. Более того, работа самых передовых средств защиты данных должна не только обеспечивать идеальные результаты, но и быть практически незаметной для конечных пользователей.
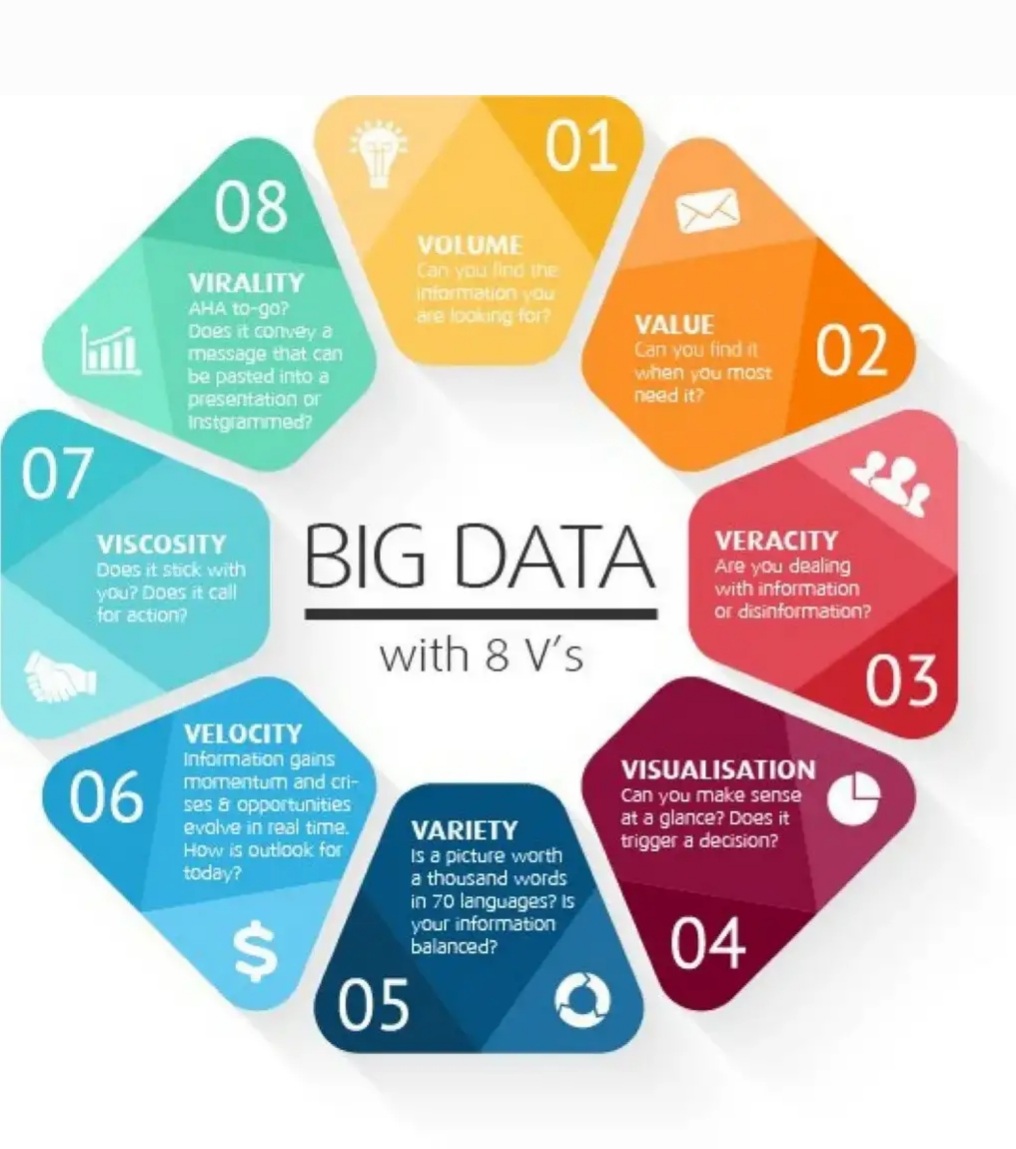
Возможности для улучшения инфраструктуры хранения данных есть, и в этой статье мы рассмотрим четыре области, в который уже сейчас существуют доказавшие свою эффективность концептуальные решения, позволяющие, как показывают свежие данные, добиться серьезных позитивных изменений.