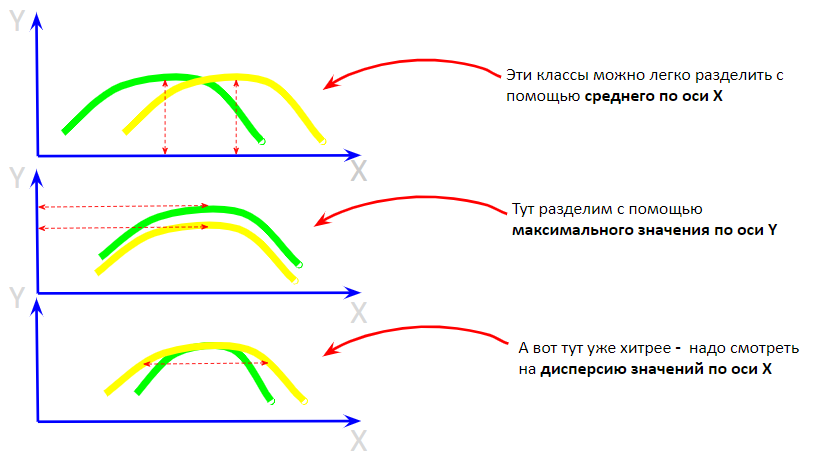
С каждым днем компании все чаще сталкиваются с проблемой, что аналитика рекламных кампаний занимает много времени у сотрудников, что увеличивает сроки выполнения задач. Помимо этого, выводы, сделанные на основании исследований эффективности рекламных каналов, являются субъективными и имеют приблизительное значение. Из-за этого стратегия маркетинга и компании в целом составляется неверно, что ухудшает ситуацию бизнеса, либо оставляет ее без изменений.
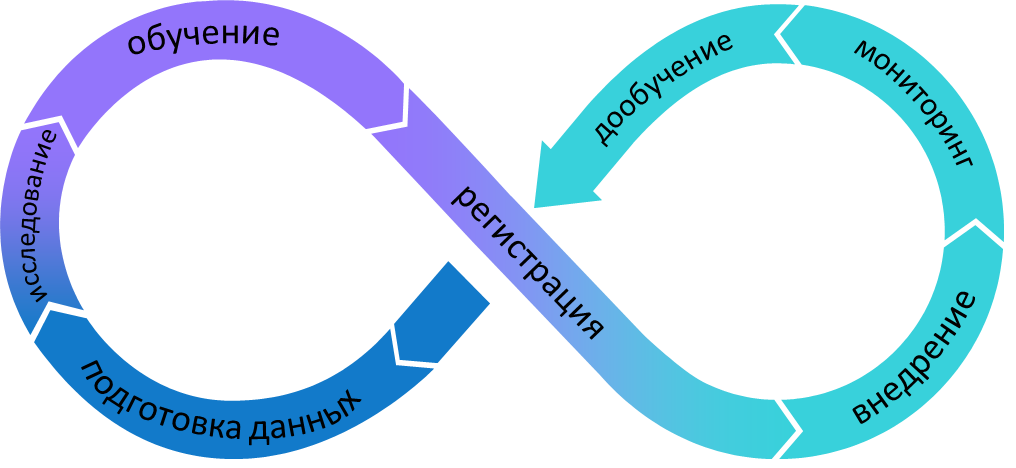
Исходя из существующей проблемы, компании приходят к выводу, что им необходима сквозная аналитика, которая поможет решить данную задачу и устранить недостатки.
Внедрение сквозной аналитики в компании «Leasing Company» прошло успешно, все работает стабильно, однако еще будут проведены доработки в дашбордах и со временем будут подключены новые источники информации. С точки зрения экономики, данное внедрение можно считать дорогостоящим, однако, это разовые траты, которые окупятся после первого же месяца, так как аналитика поможет дать четкие и объективные суждения, насчет состояния рекламных кампаний, снизит затраты и увеличит прирост как клиентов, так и доходы компании. Помимо этого, будет сэкономлено время на выполнение других задач.
Компании необходимо добавить оставшиеся рекламные источники, чтобы вся информация хранилась в одном месте и позволяла быстро анализировать данные, которые постоянно автоматически обновляются. Самым основным источником будет являться подключенная CRM – система. Именно она хранит в себе самую важную информацию о клиентах.
Внедрение сквозной аналитики однозначно является одним из полезных современных решений по повышению эффективности всей компании, увеличению ее доходов и укрепление своих позиций на рынке или даже выход на новый уровень.