
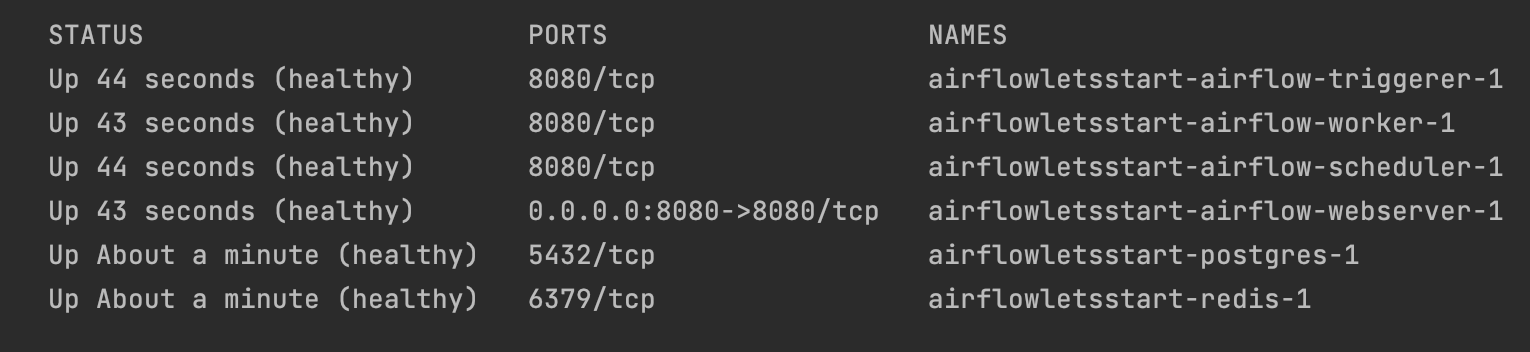
Всем привет! Меня зовут Михаил. Данная статья адресована тем, кто хотел бы познакомиться с Airflow и тем как его можно применять в организации рутинных процессов инфообмена.
Всем привет! Меня зовут Михаил. Данная статья адресована тем, кто хотел бы познакомиться с Airflow и тем как его можно применять в организации рутинных процессов инфообмена.

Привет, Хабр! Меня зовут Никита Летов, я тимлид бэкенд-разработки мобильного приложения Росбанка для физических лиц. Этот пост входит в серию постов по разработке бэкенд-микросервисов на Java и Spring и является адаптацией моего доклада с JPoint 2022.
Также хочу предупредить, что данный пост не cookbook и не предоставляет идеально приготовленное решение какой-либо бизнес-проблемы. Это разбор одной технологии, которая при правильном использовании может помочь вам в решении реальной проблемы. А может и не помочь — всё зависит от ее природы.

В мире современного дата-инжиниринга и MLOps необходимость оркестрации распределенных конвейеров данных с применением платформ управления рабочими процессами (workflow management platforms) становятся все очевиднее. Инструменты оркестрации рабочих процессов могут взять на себя тяготы обработки и распределения данных между системами и задачами, что по-прежнему является довольно сложным процессом.
Оркестрация рабочих процессов является естественным ответом на растущую с течением времени сложность рабочих процессов и конвейеров. Очень часто команды разработчиков начинают с управления и обработки задач вручную, включая очистку данных, обучение, отслеживание результатов, развертывание и т. д. Но по мере усложнения задач и рабочих процессов ручная оркестрация становится все более трудоемкой.
Это стало причиной развития платформ управления рабочими процессами и оркестрации в последние годы.

Релиз Apache Flink 1.4.0 в декабре 2017 года стал знаковым событием для потоковой обработки данных с помощью Flink: была представлена новая фича под названием TwoPhaseCommitSinkFunction (соответствующий issue в Jira), которая извлекает общую логику протокола двухфазной фиксации транзакции (two-phase commit protocol) и позволяет создавать end-to-end exactly-once приложения с Flink и набором источников и потребителей данных, включая Apache Kafka версии 0.11 и выше. Она обеспечивает уровень абстракции и для достижения end-to-end exactly-once семантики требует от пользователя реализовать всего лишь пару методов.
Если вы уже услышали все, что вам нужно было услышать, позвольте нам указать вам соответствующий раздел в документации Flink, где вы можете прочитать о том, как использовать TwoPhaseCommitSinkFunction.
Но если вы хотите узнать больше, то в этой статье мы поделимся подробным обзором этой фичи и того, что Flink оставляет за кулисами.

В предыдущих частях мы рассмотрели вопросы мониторинга потоков данных и состояния системы средствами GUI NiFi и задач отчетности. В этой части поближе познакомимся с задачами отчетности Site-to-Site. При отправке данных из одного экземпляра NiFi в другой можно использовать множество различных протоколов, однако, предпочтительным является NiFi Site-to-Site. Данный протокол предлагает безопасную и эффективную передачу данных из узлов в одном экземпляре NiFi, производящем данные, на узлы в другом экземпляре, являющимся приемником этих данных.

Задачи отчетности (Reporting Tasks)
В первой статье мы рассмотрели вопросы мониторинга потоков данных и состояния системы средствами GUI NiFi. Теперь рассмотрим, как передать необходимые метрики и отчеты об ошибках и состоянии кластера во внешние системы. NiFi предоставляет возможность сообщать о состоянии, статистике, показателях и информации мониторинга внешним службам с помощью интерфейса задач отчетности (Reporting Task).
Apache NiFi предоставляет несколько вариантов задач отчетности для поддержки внешних систем мониторинга, таких как Ambari, Grafana, Prometheus и т. д. Разработчик может создать пользовательскую задачу отчетности или настроить встроенные задачи для отправки метрик NiFi во внешние системы мониторинга.
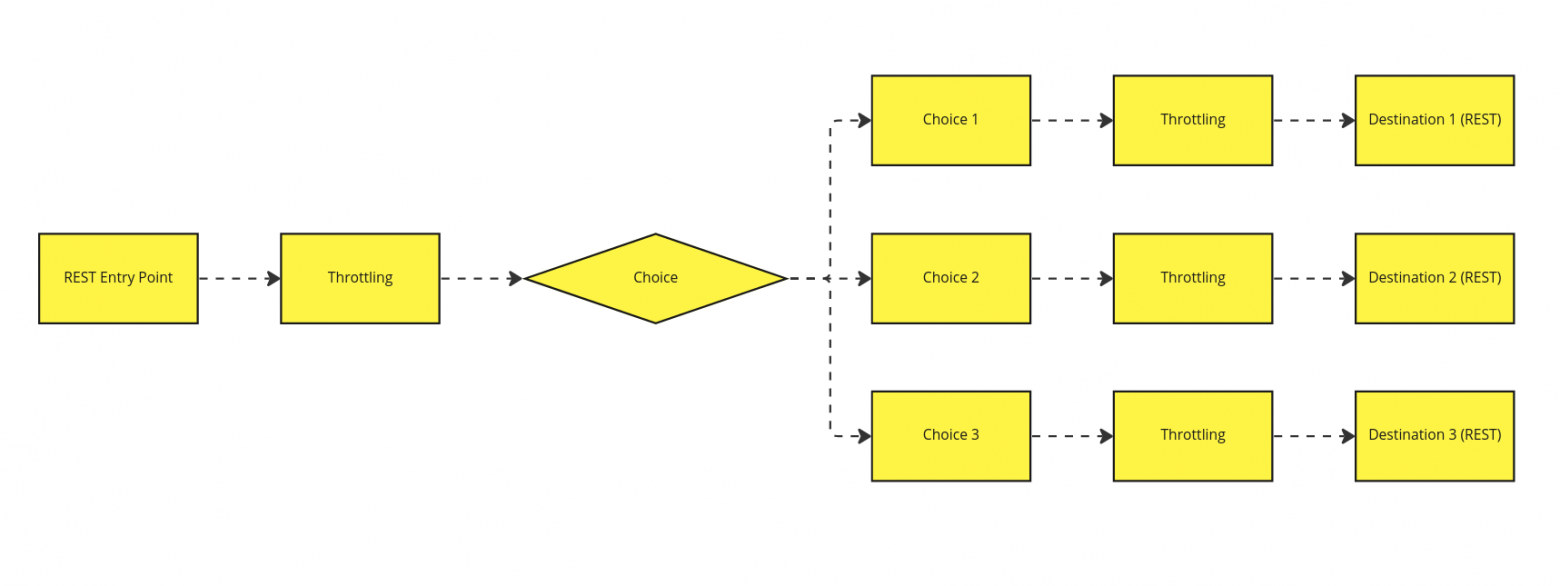
В данной статье я бы хотел раскрыть тему создания сложных маршрутов в Apache Camel с помощью компонента Direct.

Привет! Меня зовут Иван Пономарёв, я разработчик в Synthesized, преподаю в МФТИ и EEUAS. На этом митапе Росбанка и Jug.ru я расскажу о тестировании Kafka Streams и, в частности, об особенностях инструмента TopologyTestDriver. Этот доклад я подготовил совместно с Джоном Рослером (John Roesler), разработчиком из Confluent, коммитером и одним из продакт-менеджеров Apache Kafka.
Семь Open Source и два low-code-продукта для визуализации BI-аналитики от AFFINAGE
Для решение клиентских задач мы постоянно ищем способы сделать лучше. И очень часто сделать лучше значит сменить продукт. Поэтому мы постоянно анализируем рынок различных nocode-решений. Мы решили поделиться накопленными знаниями о такой важной задаче как построение аналитических дашбордов.

Подружить REST и Apache Kafka кажется нетривиальной задачей. Однако с ней удалось справиться экспертам Группы «Иннотех». Ведущий разработчик Кирилл Воронин рассказал подробности решения задачи перевода асинхронных запросов в синхронные.

В первой статье из серии об использовании Apache Cassandra в машинном обучении мы обсудили цели и задачи машинного обучения, и поговорили почему Cassandra — превосходный инструмент для обработки больших наборов данных. Также рассмотрели технологический стек, используемый Uber, Facebook и Netflix. Обе статьи основаны на воркшопе Machine Learning with Apache Cassandra and Apache Spark (Машинное обучение с помощью Apache Cassandra и Apache Spark).
В этой статье мы рассмотрим интеграцию Apache Spark с Cassandra и построение эффективных алгоритмов и решений. Мы также обсудим обучение с учителем, без учителя и метрики машинного обучения. Примеры и упражнения доступны на GitHub.

Apache NiFi динамично развивается и на сегодняшний день обладает достаточно большим набором возможностей, позволяющим отслеживать состояние потоков данных, ошибки и предупреждения, возникающие в процессорах и на кластере, а также состояние кластера.
Первая статья посвящена мониторингу потоков данных с помощью инструмента GUI NiFi. В последующих материалах мы рассмотрим задачи отчетности, опишем примеры сбора метрик и визуализации при помощи таких популярных систем, как Prometheus и Grafana.

Любому надёжному конвейеру потоковой обработки данных нужны механизмы обнаружения и обработки ошибок. В этой статье вы узнаете, как реализовать обработку ошибок с помощью очереди недоставленных сообщений (Dead Letter Queue) в инфраструктуре Apache Kafka.
Мы рассмотрим несколько вариантов: кастомная реализация, Kafka Streams, Kafka Connect, Spring Framework и Parallel Consumer. Вы увидите, как Uber, CrowdStrike и Santander Bank реализуют надёжные механизмы обработки ошибок в реальном времени и в огромном масштабе.








Пробуем поставить Opensource облачное хранилище NextCloud для повседневного пользования на домашний компьютер с ОС Windows. Подробный гайд.
В этой статье:
Анализ целесообразности развертывания облака дома. Поэтапная настройка. Проблемы и технические решения. Плюсы и минусы NextCloud. Запуск NextCloud в Docker. Подробный разбор параметров контейнера NextCloud AIO. VPN-тоннель домой с использованием сервиса Hamachi. Обход проблемы отсутствия белого ip. Настройка reverse-proxy на базе Nginx, Apache или Caddy. Запуск HTTPS-сервера на домашнем компьютере. Получение SSL-сертификата с помощью сервиса letsencrypt. Краткий разбор форматов SSL-сертификатов. Настройка файервола в Windows.

Цепочка поставок в пищевой промышленности и ритейле — это сложная, медленная и ненадёжная система. В этой статье мы рассмотрим развёртывание Apache Kafka для обработки данных в реальном времени в таких сферах, как производство, логистика, розничная торговля, доставка, рестораны и другие части бизнеса. Это будут примеры из настоящих компаний: Walmart, Albertsons, Instacart, Domino’s Pizza, Migros и т. д.

Даже если у вас большой опыт работы с Apache Kafka, время от времени наверняка случается зайти в тупик. Например, когда вы конфигурируете и изучаете клиенты или настраиваете и отслеживаете брокеры. Попробуй за всем уследить, когда в конвейере Kafka столько компонентов. В этой статье описано пять частых ошибок и советы по тому, как их избежать на всех этапах — от конфигурирования клиентов и брокеров до планирования и мониторинга. Эти рекомендации сэкономят вам время и силы.

Если вы используете GitHub для создания приложений Apache Kafka®, наверняка вы захотите интегрировать Kafka в свою среду разработки и эксплуатации GitOps. Эта статья для тех, кто понимает принципы GitOps, ценность непрерывной интеграции и поставки (CI/CD) и важность промежуточных сред (staging).
Мы поговорим о том, как применять принципы GitOps к жизненному циклу разработки клиентского приложения Kafka с помощью GitHub Actions — для тестирования в локальной среде и Confluent Cloud, со Schema Registry и без него, и для эволюции схемы.

В предыдущей публикации, посвященной Apache Superset, я лишь обзорно коснулся темы создания дашбордов, так как основной акцент хотелось сделать на технических нюансах запуска. У читателей возникли резонные вопросы о возможностях данного BI инструмента для разработки интерактивной отчетности для компании, а также многих интересовало насколько конкурентно он смотрится по фоне аналогов. Плюс рукопись изобиловала техническими моментами, а между тем, BI это в первую очередь про аналитику и бизнес. Поэтому решил написать короткую дополнительную статью, где не будет кода, но будет текст)

Добрый день, меня зовут Рустам Ахметов, я архитектор ГК Юзтех и интеграционной шины данных UseBus. В предыдущей статье я рассказывал о Kafka и её аналогах, а сегодня хочу рассмотреть NiFi.
Вы узнаете:

Все об использовании шаблонов в Airflow с примерами кода. Продолжение серии публикаций astronomer.io