
Чем больше процессов тестирования автоматизированы, тем эффективнее релизный пайплайн и тем быстрее пользователи получают новые возможности в сервисе. Руководитель Android-разработки Яндекс.Недвижимости Александр Рогов вспомнил, как эволюционировало UI-тестирование в его команде, как разработчики пришли к идее автоматизации, почему использовали фреймворк Espresso, с какими проблемами столкнулись и что в итоге получили.
— Начать хотелось бы с небольшого исторического экскурса. Когда я пришел в команду, она была маленькая, из двух-трех человек. Был один менеджер, один тестировщик. Релизы катились редко, примерно раз в месяц. Релиз обычно был прикреплен к какой-то фиче. Пока фичу не сделаем, релиз не случался. Соответственно, каждый релиз у нас было регрессионное тестирование. Такой неспешный режим работы нас всех устраивал, все было хорошо.
Но продукт начал развиваться, команда начала увеличиваться, менеджеров становилось все больше. И у менеджеров появился конфликт интересов, чью фичу катить, к чьей фиче привязывать релиз и так далее. Мы решили, что надо принимать меры, а именно — ускорять наш процесс, исправить наше узкое место в виде тестирования.
Как я уже сказал, команда тестирования была маленькой, регулярные регрессы, и все это очень сильно нам мешало делать частые релизы. Что можно было поделать?
В принципе, можно было отказаться от регрессионного тестирования и довериться разработчику. С точки зрения разработки это самый оптимистичный сценарий, ничего никому делать не надо, все круто. Но с точки зрения продукта не хотелось идти таким путем. Можно было увеличить команду тестирования, но здесь бизнес был против. Это логично, потому что вариант не особо перспективный. Кодовая база все равно растет. Соответственно, команда тестирования тоже стала бы бесконечно расти.
Другой вариант — выборочное тестирование, когда мы на релизе проверяем только ту часть приложения, в которой были изменения. Это вариант получше, но не хотелось оставлять без внимания остальные участки нашего приложения. Хотелось быть уверенным, что мы там ничего не поломали.
И здесь как раз появляется идея автоматизации тестирования. На самом деле, в процессе автоматизации тестирования мы планомерно перебрали все эти варианты. Переход с регрессионного тестирования проходил примерно так, что количество покрытых тестов увеличилось, выборочное тестирование уменьшалось, и даже чуть-чуть увеличилась команда тестирования.
Мы решили заняться написанием инструментальных тестов. Это тесты, которые прогоняются на эмуляторе или устройстве. В их основе лежит класс Instrumentation, который предоставляют средства мониторинга взаимодействия приложения и системы.
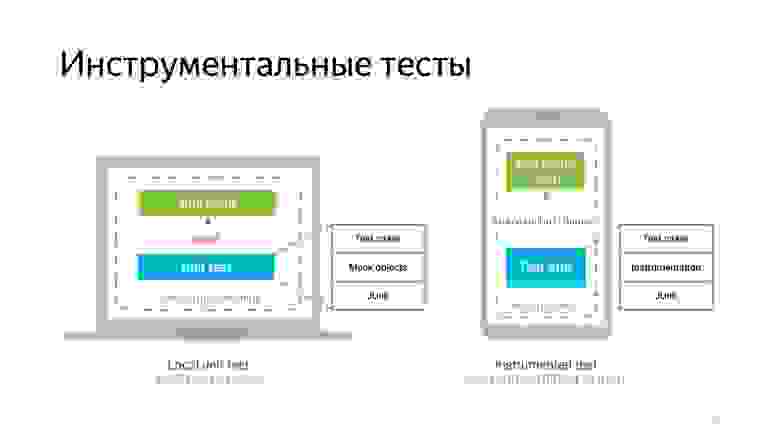
И в отличие от обычных UI-тестов, как я уже сказал, они прогоняются на реальном устройстве. То есть поднимается Application, запускаются тесты.
Для написания таких тестов мы решили использовать фреймворк Espresso, его разрабатывает Google.

Он позиционируется как очень простой и удобный инструмент для написания стабильных тестов. Рассмотрим некоторые основные компоненты Espresso. Здесь есть так называемые ViewMatchers — средства, которые позволяют нам искать элементы на экране.

ViewActions позволяют нам взаимодействовать с найденными элементами, а ViewAssertions — это некоторые проверки, которые мы можем выполнять с найденными элементами.

В качестве примера будем рассматривать простенькое приложение, в котором есть два экрана. Вводим пароль на одном, нажимаем кнопку «Проверить». Идем делать сетевой запрос. На втором экране отображаем результат нашей операции.
Пример такого теста будет выглядеть примерно так.

Рассмотрим основные части этого теста. Есть некоторые Rules, которые позволяют нам модифицировать процесс исполнения теста. Например, ActivityTestRule позволяет нам в начале каждого теста запускать Activity и выделять соответствующие ресурсы.

А в теле теста выполняются такие простейшие манипуляции. Мы находим элемент, выполняем, например, ввод текста.

Находим следующий элемент с кнопкой, выполняем нажатие.

Находим следующий элемент с результатом, проверяем его. Примерно так может выглядеть базовый тест Espresso.

Также фреймворк Espresso предоставляет нам базовый отчет, из которого мы можем понять, сколько по времени проходили наши тесты, какой процент тестов упал, а какой не упал.

Можно проваливаться по пакетам, по тестам.
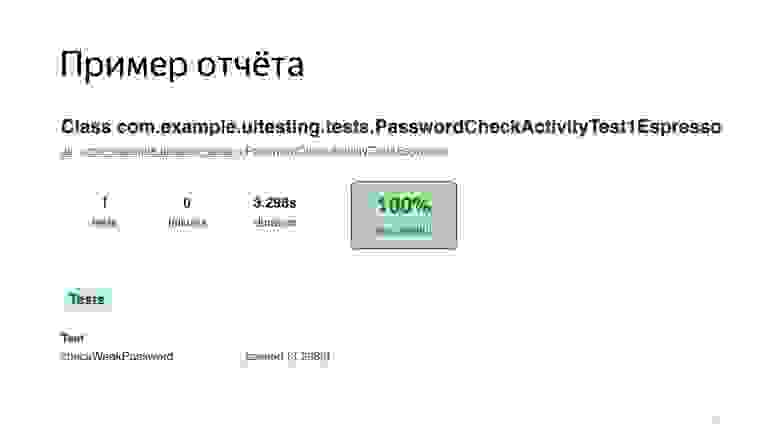
Можно посмотреть ошибки.

Для ошибок выводится самый простой crash logs, ничего особо интересного.
Проанализировав все эти средства Espresso, мы выделили для себя недостатки. Например, изолированность. По умолчанию все тесты Espresso прогоняются в рамках одного инстанса Instrumentation и, соответственно, одного инстанса Application. Также нет никакой изолированности от внешней среды, такой как интернет. И от других сторонних приложений. Мы подробнее поговорим об этом дальше.
Хрупкость тестов. Вы наверняка слышали, что любые UI-тесты достаточно хрупкие, подвержены факторам, которые приводят к их так называемым флакам. Также мы выделили себе такой пункт, как медленное исполнение UI-тестов по сравнению с юнит-тестами. Здесь нам предстояло подумать, как мы сможем прогонять их достаточно часто, чтобы отлавливать актуальные проблемы и оперативно на них реагировать.
Также нам не очень понравилось, как пишутся такие тесты. Нам показалось, что они достаточно многословны. И нам не понравился отчет. Обо всем этом подробнее мы и поговорим. Посмотрим, что мы делали, чтобы решить эти проблемы.
Как я уже сказал, по умолчанию все тесты запускаются в одном инстансе Instrumentation, но существует средство, которое позволяет эту проблему решить: Android Test Orchestrator.

Это инструмент, который позволяет запускать каждый тест изолированно от остальных, в своем инстансе Instrumentation. Для каждого теста будет запускаться свой Application. Не будет никакого разделяемого состояния между тестами.
Даже если нам необходимо почистить базу данных, мы можем использовать специальные флаги, как здесь на слайде, clearPackageData. Это позволит нам максимально изолировать тесты друг от друга.
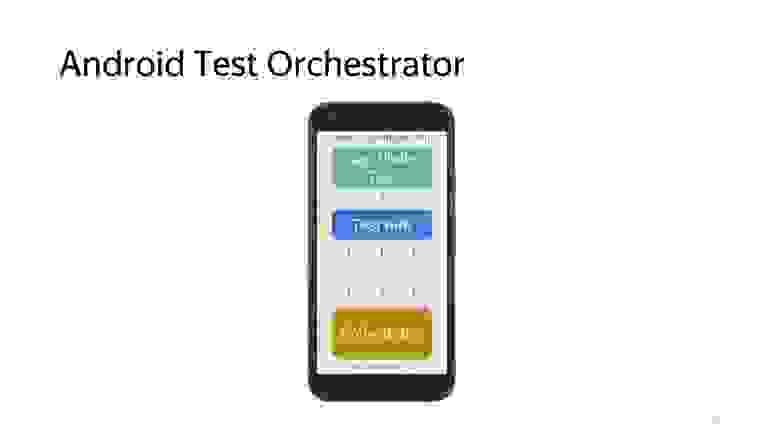
Концептуально это выглядит так: вместе с APK тестов и приложения устанавливается еще Orchestrator, и он управляет процессом исполнения тестов: поодиночке запускает каждый тест в своем инстансе Instrumentation.
Из плюсов, как я уже сказал, — максимальная изоляция состояния. Также получаются изолированные крэши. Поскольку каждый тест исполняется в своем Instrumentation, то если он падает по какой-то причине, то остальные тесты продолжают исполняться. В каком-то смысле повышается стабильность наших тестов. Из минусов: значительно замедляется исполнение тестов, так как на каждый тест мы запускаем свой инстанс Application.
Все современные приложения ходят в сеть, поэтому мы подвержены такому явлению, как отсутствие интернета. Что делать, если интернет пропал и тесты начинают падать? Нестабильные тесты — не то, к чему мы стремились. Мы хотели добиться максимально стабильного исполнения тестов, чтобы не тратить время на ненужные нам разборки.
Здесь мы решили использовать MockWebServer. Мы в своем проекте используем библиотеку OkHttpClient для сетевого взаимодействия. В ней есть модуль MockWebServer. Идея была запускать некий локальный WebServer и направлять все сетевые запросы нашего API на localhost.

Для реализации нам потребовалось переопределить Application для тестов.

Мы унаследовались от нашего реального Application.

Определили некий Dispatcher, куда мы будем мокать наши запросы. Запустили WebServer.

Далее нам необходимо, чтобы в тестах запускался именно наш тестовый Application, а не реальный.
Для этого нужно переопределить AndroidJUnitRunner, сделав кастомный, у которого есть специальный метод newApplication, позволяющий подменить реализацию на нашу тестовую.

Следующей задачей для нас стало перенаправить все наши сетевые запросы на localhost. Для этого нам помог Dagger 2, который мы используем в проекте.

Здесь все по аналогии. Есть некоторый Application-компонент, для теста мы создаем TestApplication-компонент, который наследуется от Application-компонента, но использует другие модули сетевого взаимодействия.

Вот пример такого модуля.

Оба модуля используют базовые сетевые модули, но предоставляют разную реализацию endpoint и OkHttpClient. Вот наш сетевой модуль, который как раз использует эти компоненты.

Когда мы запускаем что-то в тестах, то ходим на localhost.

Когда мы запускаем prod в сборку, то мы идем на продовый endpoint.

Что получилось в тесте? Добавляется вот такой блок для конфигурации WebServer. Здесь мы используем простенький DSL, в котором мы обращаемся к Instrumentation, получаем Application, кастуем его к нашему тестовому, и оттуда уже можем обращаться к его полям.

Помните, мы определили там Dispatcher? Какие плюсы? Такой подход позволяет нам изолироваться от внешней среды и тем самым повышается стабильность. Наши тесты становятся независимыми от интернета и перестают неупорядоченно падать.
Из минусов: необходимо готовить Mock’и ответов. Порой они бывают очень громоздкими, это повышает трудоемкость.

Пару слов об изоляции от внешних приложений. Здесь у Espresso есть отдельный модуль под названием Espresso-Intents. Он позволяет нам записывать ожидаемые Intent, которые запускает наше приложение, и мокать их ответ. Но на этом мы не будем подробно останавливаться.
Помните, я рассказал, что нам не понравилось, как пишутся Espresso-тесты и нам хотелось добиться чего-то более лаконичного? Изначально планировалось, что команда тестирования будет смотреть код наших тестов и таким образом валидировать их.

Пример. Если посмотреть на наш тест, то видно, что для совершения простых действий — введи текст, нажми на кнопку и так далее — нам приходится совершать много манипуляций.

Здесь нам на помощь пришли так называемые тестовые роботы. Идея этих роботов: мы пытаемся отделить то, что мы делаем, от того, как мы это делаем. Появляются высокоабстрактные методы взаимодействия, которые скрывают от нас детали реализации.

Пример такого тестового робота мы можем посмотреть здесь. Тестовый робот — это дополнительная абстракция, представляющая собой часть пользовательского интерфейса, для которой характерен набор неких базовых действий.

Например, в нашем случае на первом экране ввода пароля есть действие «ввести пароль» и действие «нажать на кнопку». Мы посмотрели и поняли: было бы удобно переиспользовать алгоритмы поиска элементов на экране, и тоже выделили их в отдельную абстракцию, которую мы назвали Lookup.

Таким образом, получается базовый тест, который был разбит на робота и Lookup и преобразился примерно так.

Что мы видим теперь? Появились некоторые контексты, мы видим два экрана. Для каждого экрана мы создали своего робота. В каждом роботе есть функциональность, характерная для этого экрана. В тесте мы теперь можем это четко наблюдать. Есть некоторое разделение по контексту, тесты стало проще воспринимать.
Как я уже сказал, появилась декомпозиция — по функциональности, по Matchers. Из минусов: появляются Boilerplates по написанию роботов. Поговорим о нем более подробно чуть позднее.
Поговорим про стабильность Espresso и поймем, за счет чего она достигается. Google позиционирует свой фреймворк как инструмент для написания стабильных тестов.

В основе этгого лежит следующий подход. Каждый раз, когда мы вызываем onView и пытаемся выполнить какие-то действия или проверки, они не будут выполнены до тех пор, пока очередь сообщений основного потока не будет пуста, либо не будет выполняться никаких AsyncTask, либо все так называемые IdlingResource будут находиться в состоянии idle.
Первые два пункта, очередь сообщений и AsyncTask, — это компоненты, которые известны системе Android, и она может их сама контролировать. Но существует множество других ресурсов, о которых Android не знает и не понимает, как их контролировать. Поэтому здесь вводится дополнительная абстракция IdlingResource. Этот инструмент предоставляет разработчику возможность определять такие асинхронные операции и сообщает фреймворку Espresso, что пока исполнять нельзя тест.

В качестве примера такого ресурса рассмотрим OkHttp3IdlingResource. Так как мы применяем библиотеку OkHttp, то можем без проблем использовать и его тоже. Подключить к нашему тесту можно с помощью Rules, о которых я уже говорил.

Здесь используется тип ExternalResource. Его особенность в том, что он выполняет действия до исполнения теста и после.

А создать такой ресурс можно опять-таки на основе доступа к нашему тестовому контексту, из которого мы можем получить OkHttpClient. Это реализовывается средствами Dagger.
Пример использования. Нам необходимо добавить такой Rule в тест. Для этого используется RuleChain, то есть цепочка Rules.

В цепочку можно добавлять сколько угодно правил.

Из плюсов IdlingResource: у пользователя появляется возможность размечать асинхронные ресурсы и тем самым повышать стабильность своего приложения. Из минусов: не всегда просто эти ресурсы реализовать. Природа наших приложений может быть в значительной степени асинхронной, не все ресурсы могут быть легко доступны из тестового кода, и здесь могут возникать проблемы.
Что же делать, если использование IdlingResource затруднительно? Мы хотим добиться написания стабильных тестов, но сейчас, например, не можем себе позволить реализовать IdlingResource во всех местах приложения.

Мы, например, использовали вот такой известный костыль. Грубо говоря, это цикл, в котором мы проверяем, не выполнилось ли наше условие, не оказались ли мы в ожидаемом состоянии. Если по истечении заданного интервала мы не оказались в ожидаемом состоянии, то тест падает. За счет этого простого инструмента, который не рекомендуем к использованию, а рекомендуем все-таки использовать IdlingResource, нам удалось добиться значительной стабильности исполнения наших тестов.

Как использовать это в тесте? Предположим, мы нажали на кнопку «проверить пароль», переходим на вторую Activity, и на ней мы, прежде чем выполнять проверку, можем дождаться — действительно ли элемент появился на экране? Если да — выполнить проверку. Интеграция такой конструкции в тесте выглядит достаточно лаконично. Чуть-чуть избыточно, но что делать.
Из плюсов: простой способ повышения стабильности. Из минусов: в тестах появляется дополнительный код, и теоретически, это может негативно повлиять на время исполнения тестов, привести к дополнительным простоям.
Еще одним пунктом, о котором я говорил, был отчет. Нам не понравился базовый отчет, нам хотелось большего: проще узнавать, в чем проблема, быстрее реагировать на возникающие сложности.

Здесь мы решили попробовать использовать фреймворк построения отчетов Allure. Легковесный, предоставляет дополнительные средства построения отчета. Интеграция Allure происходит очень просто. Достаточно унаследоваться от их AllureAndroidJUnitRunner, и это уже позволит вам строить отчет. Также в Allure предоставляется базовый набор Rules. Например, есть ScreenshotRule, WindowHierarchyRule, LogcatRule. То есть, если у вас происходит тест, к нему автоматически будут добавлены скриншоты, логи из Logcat, иерархия представлений. Уже можно будет проанализировать результаты, информации чуть больше, чем в случае с Espresso.
Генерация отчета происходит либо из командной строки, либо с помощью Allure Gradle plugin.
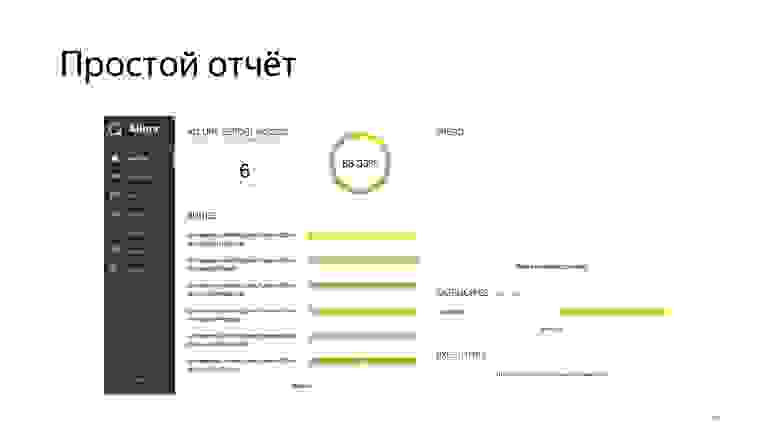
Отчет выглядит примерно так. Опять-таки, мы видим, сколько тестов выполнилось, сколько нет и сколько они выполнялись по времени.

Можно проваливаться в тесты.
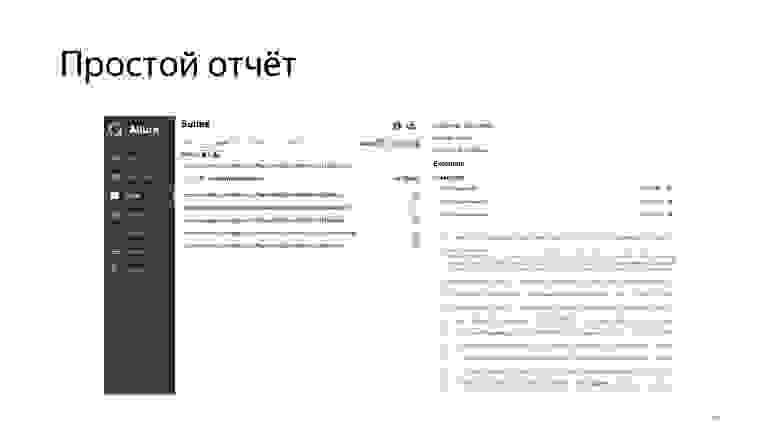
Увидеть, как раз на этом скриншоте, что к сфейленному тесту добавилась дополнительная информация. Еще одна интересная возможность, которую предоставляет Allure: накопление информации и ведение статистики. То есть когда вы агрегируете Allure-отчеты в одном месте, можно вести настоящий трекинг того, как проходило ваше тестирование, как вы фиксили проблемы, как они появлялись, исчезали и так далее.
Но еще одна важная особенность Allure-отчетов — средства документирования, которые он предоставляет. Это специальные средства, которые позволяют размечать ваш тест так, чтобы его шаги или особенности его исполнения попадали в этот отчет либо с помощью аннотаций, либо с помощью классов, если аннотации нам не подошли.
Мы были очень заинтересованы в том, чтобы получился более документированный отчет, чтобы команда тестирования смотрела не в код наших тестов, а в отчет и понимала, что там происходило.

Для этого мы решили создать прослойку между основными компонентами Espresso, которые мы назвали именованные компоненты.

Это просто обертка, которая добавляет имя. Таким образом появились обертки для Matchers.

И для Assertions, и для Actions.

И для Interaction. Входной точкой для наших тестов стал уже не Espresso#onView, а NamedViewInteraction#onView.

Идея была в том, что для всех действий добавляется человекопонятное имя, которое будет отражено в отчете с помощью команды step, которую здесь можно видеть.
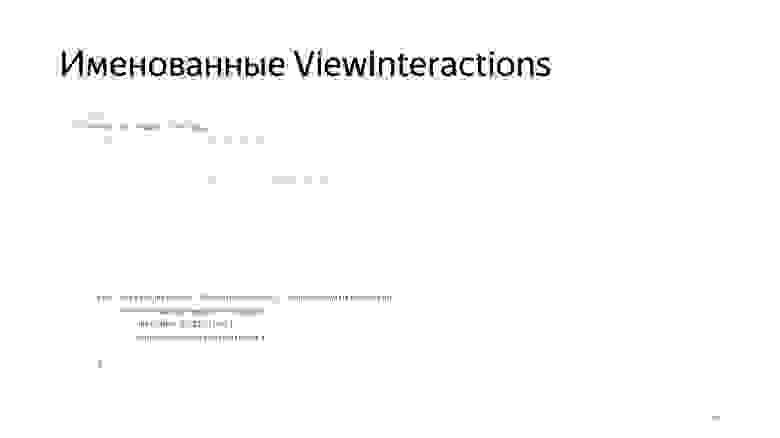
То есть каждый раз, когда мы выполняем проверку, в отчете будет зафиксировано, что именно мы проверяем.

Также мы модифицировали всех наших роботов, добавив в их входную точку команду step, которая говорит, что начинается активность. И модифицировали все наши Lookup — добавили к ним человекопонятные имена.

Это привело к тому, что сгенерировался вот такой отчет, из которого уже можно понять, что и в каком контексте происходит, что и куда мы вводим.

Тестирование может прочитать этот отчет и понять, какой пользовательский сценарий мы этим покрыли.
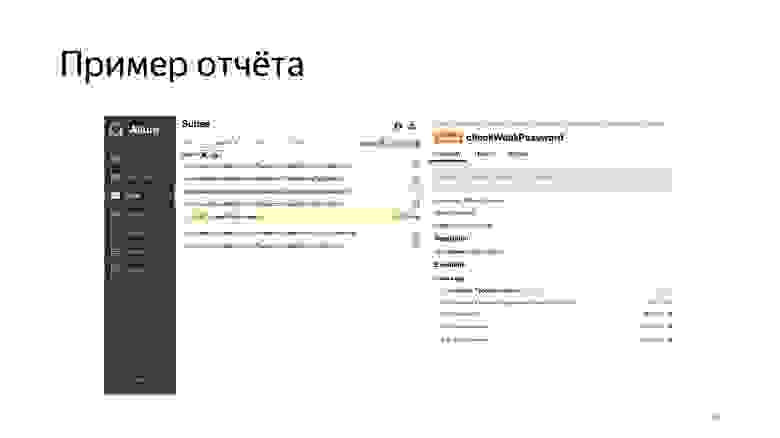
Также здесь можно видеть, на каком шаге произошла ошибка. Нам это очень понравилось.
Из плюсов: появилась функциональность по конфигурированию отчета и некая автодокументируемость. Из минусов: необходимо решить инфраструктурные задачи: например, как мы строим этот отчет, как храним и передаем файлы Allure. Также замедляется время исполнения тестов, поскольку появляется больше работы с файлами, мы начинаем хранить скриншоты и так далее.
На этом этапе у нас уже был какой-никакой подход к написанию тестов. Они были достаточно стабильными. У нас уже был отчет, и мы стали задумываться, насколько качественно мы вообще проверяем UI?
Ведь если бы проверял тестировщик, он смотрел бы не только на то, что написано в поле, что это хороший пароль. Он проверял бы, как элемент расположен на экране, смотрел бы на цвет текста, на шрифт и так далее. Мы подумали над этим, и вот пример такой проблемы. Кто-то поменял верстку. Или мы обновили какую-то библиотеку, и верстка поехала, constraint сломался, или еще что-то.

Текущий тест на эту проблему никак не реагирует, но тестирование в ручном режиме смогло бы ее обнаружить. Мы пришли к тому, что решили сравнивать скриншоты.

Для этого мы написали простой Interaction и абстракции в стиле Espresso.

Выглядит это примерно так. В роботе появляется функциональность по сравнению скриншотов. Что произошло в отчете?

В отчет в случае ошибки мы добавляем то, что ожидали увидеть, то, что получили, и diff.
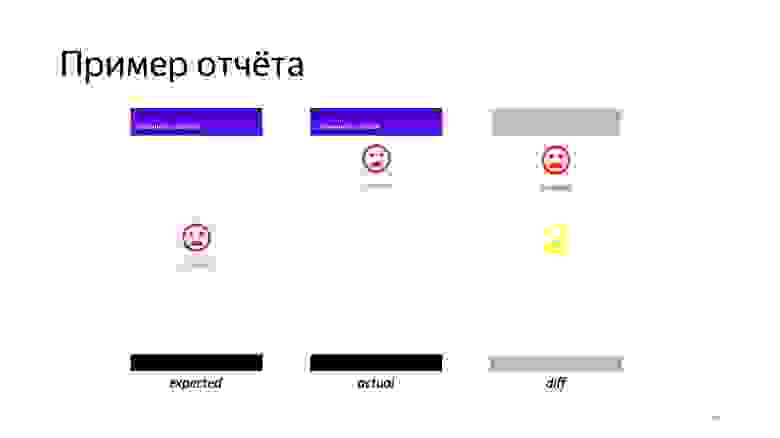
Теперь мы проверяем не то, что конкретная строка совпадает, а общее расположение элементов, их композицию на экране.

Из интересного можно отметить, как в принципе стоит сравнивать скриншоты, ведь мы делаем скриншоты-эталоны на одном эмуляторе, а сравниваем неизвестно где, на CI. Следует уделить влияние конфигурации ваших эмуляторов, именно тех, на которых вы делаете скриншоты, чтобы они совпадали с теми, на которых вы эти тесты прогоняете.
На что следует обратить внимание? Конечно, на форм-фактор, то есть на размер вашего экрана и режим отрисовки. В нашем случае нам необходимо было выключить GPU и скрыть кнопки. Если этого не сделать, у вас могут появляться различные артефакты из-за разницы реализации anti-aliasing в той или иной среде.
Скриншоты позволили нам проводить комплексную проверку UI. Написание тестов в целом ускорилось, потому что нам больше не надо было делать много разных проверок, достаточно было делать одну. Но опять появился ворох новых инфраструктурных задач, таких как хранение скриншотов, создание эталонов и прочее. Также это привело к тому, что тесты значительно замедлились: стало еще больше работы с файлами и появилось сравнение скриншотов.
Я говорил, что у нас были претензии к роботам, некоторый Boilerplate, и мы пришли к осознанию того, что это тоже хотелось бы поправить.

Посмотрим на проблему. Предположим, появляется новая функциональность. Например, мы захотели проверять, что элементы — кнопка или поле ввода — видны. Тогда в соответствии с подходом робота нам надо эту функциональность вывести в робот.

Потом на экране неожиданно появилась еще одна кнопка, и для нее мы тоже должны продублировать функциональность по нажатию и проверке видимости.

Или вдруг появился еще один робот, и возникают еще какие-то кнопки, поля ввода. Здесь мы тоже дублируем функциональность, которая по сути имеет одну и ту же реализацию. Изменяется лишь Matcher, который мы используем.
Здесь, вдохновившись подходом из библиотеки Kakao, мы пришли к так называемому компонентному подходу.

Идея компонентного подхода: мы выделяем функциональность не в робота, а в компонент. Роботы заменяются так называемыми Screens. Каждый Screen представляет какую-то часть UI по аналогии с роботом, но хранит набор компонент, которые есть в этой части UI.

Базовый Screen предоставляет базовую функциональность.

Базовые компоненты тоже представляют какую-то функциональность, а конкретный компонент, например EditText, предоставляет функциональность по вводу текста.

А в тесте получилось следующее.

Контекст остался: мы по-прежнему можем понимать, где производим действия. Единственное, чуть понизился уровень абстракции. Теперь мы вынуждены взаимодействовать с компонентами и вызывать на них действия.
Нас этот подход устроил. Прежде всего потому, что мы хотели ускорить написание тестов, снизить количество Boilerplate-кода. А для команды тестирования у нас уже были отчеты, которые позволили им больше не смотреть в тело теста без лишней необходимости. Минус я уже отметил: понизился уровень абстракции.
Наверное, вы заметили, что многое из того, что мы делали, негативно влияло на скорость выполнения. Что же делать?
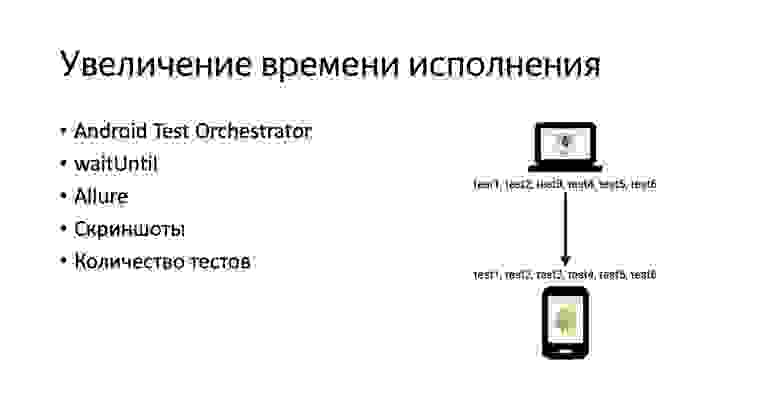
Количество тестов растет, мы используем Orchestrator, waitUntil, Allure и так далее, замедление усиливается. Рассмотрим несколько вариантов. Можно делать частичное исполнение тестов. Например, мы не всегда прогоняем все тесты на каждый пул-реквест, на каждый коммит, а начинаем прогонять их порциями.
Либо мы реализовываем параллельное исполнение тестов с достижением необходимого, желаемого времени исполнения. Мы решили покопать в сторону этого варианта, посмотреть, что мы можем сделать с точки зрения параллельного исполнения.
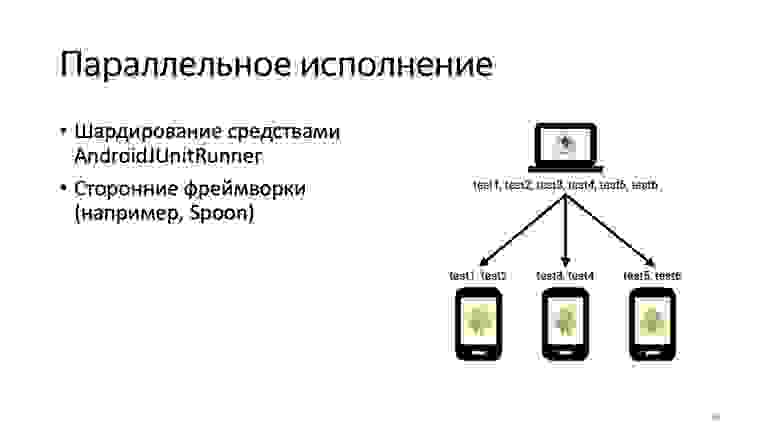
Существует средство шардирования исполнения тестов через AndroidJUnitRunner. Однако оно доступно только из командной строки. Нам этот вариант тогда показался не очень удобным. Мы еще немного покопали в сторону сторонних фреймворков — например, Spoon. Но втягивание сторонних фреймворков нам казалось избыточным.
Есть Gradle-команда — выполняешь и получаешь список подключенных устройств. Разделяешь тесты по этим устройствам, исполняешь их на этих устройствах. Собираешь результат. Хотелось добиться чего-то такого, казалось бы, простого. Зачем здесь отдельный фреймворк?

Решили попробовать сделать нечто подобное. Для этого мы написали свой Gradle-таск, в основе которого так называемый Worker API Gradle. Его идея в том, что существуют специальные абстракции: WorkerExecutor, который позволяет параллельно исполнять некоторые подтаски в рамках одной корневой таски, и действие WorkAction. Конфигурировать их можно с помощью WorkParameters.

Также мы проанализировали базовую команду для запуска Android-тестов — connectedAndroidTest, и выясняли, какие в принципе существуют абстракции, чтобы сделать нечто похожее. Обнаружили, что существует некий AndroidTestOrchestratorRemoteAndroidTestRunner, позволяющий из кода запускать тесты. У него есть дополнительный ITestRunListener и набор средств конфигурации этого Runner. Однако часть API, которые мы тогда нашли, начиная с Gradle 4.0 стали Deprecated, поэтому нам пришлось скопировать некоторые компоненты в проект.
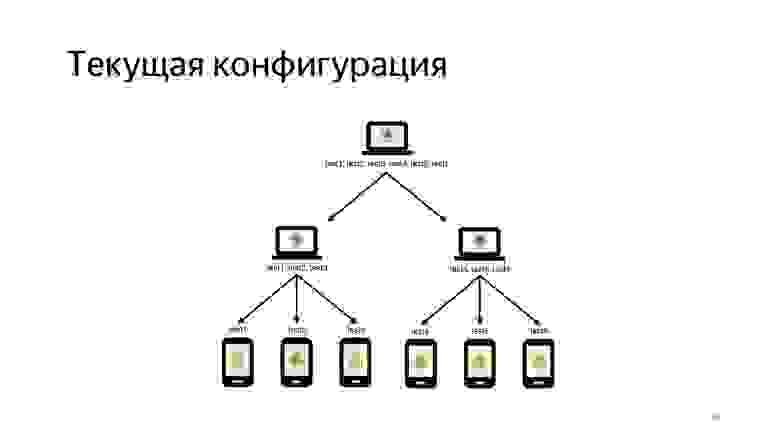
Текущая конфигурация исполнения наших тестов выглядит примерно так. Мы запускаем два агента. На каждом запускаем по восемь эмуляторов — здесь их для краткости три.

Как можно заметить, на 16 эмуляторах тесты исполняются примерно за 30 минут, а последовательное их исполнение занимает порядка 5 часов. Но это не совсем честное время. Столько мы потратим только на исполненея тестов, без накладных расходов с точки зрения инфраструктуры.
Чего мы добились, проделав все это?
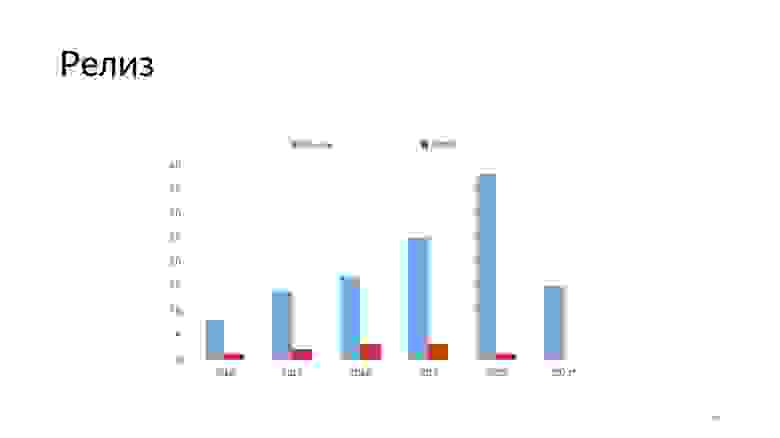
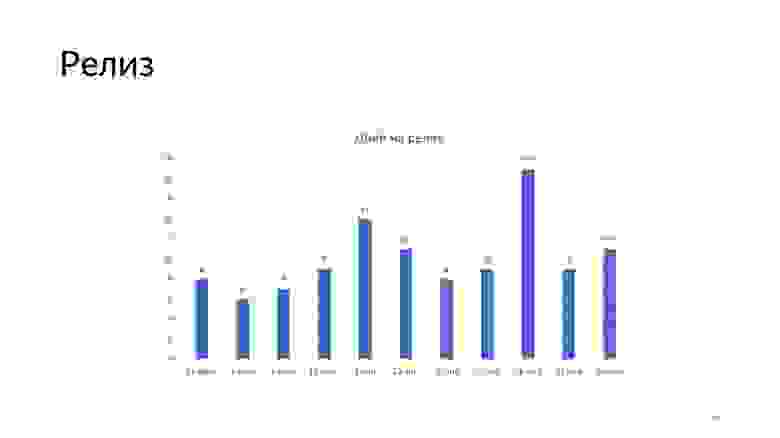
Если посмотреть на этот график, то за год с момента интеграции UI-тестов количество наших релизов значительно выросло. Количество HotFix снижается. То есть тесты помогают нам писать более стабильный код, вносить масштабные исправления в проект без особой оглядки.
Сейчас у нас, по утверждению команды QA, автоматизирован 71% регрессионного тестирования, и сформирован план по дальнейшей автоматизации. На релизе мы проводим выборочное тестирование, которое занимает порядка двух-трех часов. Релизы случаются примерно раз в одну-две недели, как можно заметить по этому графику за последние три месяца.
Что с проблемами, которые были обозначены в самом начале?
Для изолированности наших тестов мы используем такие средства, как Android Test Orchestrator, MockWebServer, Espresso Intens. Dagger 2 помогает подменять зависимости в тестовой среде. Для стабильности у нас есть IdlingResource, есть костыль waitUntil. Так как мы используем кастомный Gradle-таск, есть возможность перезапускать тесты, которые по непредсказуемым причинам падают. Что касается времени исполнения тестов, нам удалось реализовать параллельное исполнение средствами кастомной Gradle-таски.
У нас сейчас написано примерно полторы тысячи тестов. Они исполняются примерно за один час с учетом всех накладных расходов. Гоняем мы их на каждый коммит, на каждый пул-реквест.
В написании тестов используются подходы с тестовым роботом. Выделили Matcher и Lookup, используем компонентный подход, сравнение скриншотов для упрощения написания. Отчеты строятся в Allure, который предоставляет нам некоторую автодокументируемость. Это позволяет команде тестирования анализировать тесты, которые мы реализовали, и фиксировать, какую часть регресса мы покрыли.
Что же дальше? У нас есть планы по расширению использования IdlingResource. Сейчас мы их, к сожалению, используем только для OkHttpClient. Также есть планы по улучшению инфраструктуры параллельного исполнения тестов. Сейчас возникают очень большие накладные расходы: как я сказал, тесты исполняются за 30 минут, а все остальное время занимают процессы передачи управления между подзадачами. И, разумеется, можно предпринимать еще какие-то шаги по улучшению нашего отчета.
Специально для вас я подготовил репозиторий с исходными кодами всего этого параллелизма, всех подходов, о которых я рассказал. Подробнее можно посмотреть там. Спасибо за внимание.
Полезные ссылки:
— developer.android.com/training/testing/espresso
— jakewharton.com/testing-robots
— docs.qameta.io/allure
— github.com/KakaoCup/Kakao
— Начать хотелось бы с небольшого исторического экскурса. Когда я пришел в команду, она была маленькая, из двух-трех человек. Был один менеджер, один тестировщик. Релизы катились редко, примерно раз в месяц. Релиз обычно был прикреплен к какой-то фиче. Пока фичу не сделаем, релиз не случался. Соответственно, каждый релиз у нас было регрессионное тестирование. Такой неспешный режим работы нас всех устраивал, все было хорошо.
Но продукт начал развиваться, команда начала увеличиваться, менеджеров становилось все больше. И у менеджеров появился конфликт интересов, чью фичу катить, к чьей фиче привязывать релиз и так далее. Мы решили, что надо принимать меры, а именно — ускорять наш процесс, исправить наше узкое место в виде тестирования.
Как я уже сказал, команда тестирования была маленькой, регулярные регрессы, и все это очень сильно нам мешало делать частые релизы. Что можно было поделать?
В принципе, можно было отказаться от регрессионного тестирования и довериться разработчику. С точки зрения разработки это самый оптимистичный сценарий, ничего никому делать не надо, все круто. Но с точки зрения продукта не хотелось идти таким путем. Можно было увеличить команду тестирования, но здесь бизнес был против. Это логично, потому что вариант не особо перспективный. Кодовая база все равно растет. Соответственно, команда тестирования тоже стала бы бесконечно расти.
Другой вариант — выборочное тестирование, когда мы на релизе проверяем только ту часть приложения, в которой были изменения. Это вариант получше, но не хотелось оставлять без внимания остальные участки нашего приложения. Хотелось быть уверенным, что мы там ничего не поломали.
И здесь как раз появляется идея автоматизации тестирования. На самом деле, в процессе автоматизации тестирования мы планомерно перебрали все эти варианты. Переход с регрессионного тестирования проходил примерно так, что количество покрытых тестов увеличилось, выборочное тестирование уменьшалось, и даже чуть-чуть увеличилась команда тестирования.
Автоматизация UI-тестирования
Мы решили заняться написанием инструментальных тестов. Это тесты, которые прогоняются на эмуляторе или устройстве. В их основе лежит класс Instrumentation, который предоставляют средства мониторинга взаимодействия приложения и системы.

И в отличие от обычных UI-тестов, как я уже сказал, они прогоняются на реальном устройстве. То есть поднимается Application, запускаются тесты.
Для написания таких тестов мы решили использовать фреймворк Espresso, его разрабатывает Google.

Он позиционируется как очень простой и удобный инструмент для написания стабильных тестов. Рассмотрим некоторые основные компоненты Espresso. Здесь есть так называемые ViewMatchers — средства, которые позволяют нам искать элементы на экране.

ViewActions позволяют нам взаимодействовать с найденными элементами, а ViewAssertions — это некоторые проверки, которые мы можем выполнять с найденными элементами.

В качестве примера будем рассматривать простенькое приложение, в котором есть два экрана. Вводим пароль на одном, нажимаем кнопку «Проверить». Идем делать сетевой запрос. На втором экране отображаем результат нашей операции.
Пример такого теста будет выглядеть примерно так.

Рассмотрим основные части этого теста. Есть некоторые Rules, которые позволяют нам модифицировать процесс исполнения теста. Например, ActivityTestRule позволяет нам в начале каждого теста запускать Activity и выделять соответствующие ресурсы.

А в теле теста выполняются такие простейшие манипуляции. Мы находим элемент, выполняем, например, ввод текста.

Находим следующий элемент с кнопкой, выполняем нажатие.

Находим следующий элемент с результатом, проверяем его. Примерно так может выглядеть базовый тест Espresso.

Также фреймворк Espresso предоставляет нам базовый отчет, из которого мы можем понять, сколько по времени проходили наши тесты, какой процент тестов упал, а какой не упал.

Можно проваливаться по пакетам, по тестам.

Можно посмотреть ошибки.

Для ошибок выводится самый простой crash logs, ничего особо интересного.
Проанализировав все эти средства Espresso, мы выделили для себя недостатки. Например, изолированность. По умолчанию все тесты Espresso прогоняются в рамках одного инстанса Instrumentation и, соответственно, одного инстанса Application. Также нет никакой изолированности от внешней среды, такой как интернет. И от других сторонних приложений. Мы подробнее поговорим об этом дальше.
Хрупкость тестов. Вы наверняка слышали, что любые UI-тесты достаточно хрупкие, подвержены факторам, которые приводят к их так называемым флакам. Также мы выделили себе такой пункт, как медленное исполнение UI-тестов по сравнению с юнит-тестами. Здесь нам предстояло подумать, как мы сможем прогонять их достаточно часто, чтобы отлавливать актуальные проблемы и оперативно на них реагировать.
Также нам не очень понравилось, как пишутся такие тесты. Нам показалось, что они достаточно многословны. И нам не понравился отчет. Обо всем этом подробнее мы и поговорим. Посмотрим, что мы делали, чтобы решить эти проблемы.
Изолированность между тестами
Как я уже сказал, по умолчанию все тесты запускаются в одном инстансе Instrumentation, но существует средство, которое позволяет эту проблему решить: Android Test Orchestrator.

Это инструмент, который позволяет запускать каждый тест изолированно от остальных, в своем инстансе Instrumentation. Для каждого теста будет запускаться свой Application. Не будет никакого разделяемого состояния между тестами.
Даже если нам необходимо почистить базу данных, мы можем использовать специальные флаги, как здесь на слайде, clearPackageData. Это позволит нам максимально изолировать тесты друг от друга.

Концептуально это выглядит так: вместе с APK тестов и приложения устанавливается еще Orchestrator, и он управляет процессом исполнения тестов: поодиночке запускает каждый тест в своем инстансе Instrumentation.
Из плюсов, как я уже сказал, — максимальная изоляция состояния. Также получаются изолированные крэши. Поскольку каждый тест исполняется в своем Instrumentation, то если он падает по какой-то причине, то остальные тесты продолжают исполняться. В каком-то смысле повышается стабильность наших тестов. Из минусов: значительно замедляется исполнение тестов, так как на каждый тест мы запускаем свой инстанс Application.
Изолированность от внешней среды
Все современные приложения ходят в сеть, поэтому мы подвержены такому явлению, как отсутствие интернета. Что делать, если интернет пропал и тесты начинают падать? Нестабильные тесты — не то, к чему мы стремились. Мы хотели добиться максимально стабильного исполнения тестов, чтобы не тратить время на ненужные нам разборки.
Здесь мы решили использовать MockWebServer. Мы в своем проекте используем библиотеку OkHttpClient для сетевого взаимодействия. В ней есть модуль MockWebServer. Идея была запускать некий локальный WebServer и направлять все сетевые запросы нашего API на localhost.

Для реализации нам потребовалось переопределить Application для тестов.

Мы унаследовались от нашего реального Application.

Определили некий Dispatcher, куда мы будем мокать наши запросы. Запустили WebServer.

Далее нам необходимо, чтобы в тестах запускался именно наш тестовый Application, а не реальный.
Для этого нужно переопределить AndroidJUnitRunner, сделав кастомный, у которого есть специальный метод newApplication, позволяющий подменить реализацию на нашу тестовую.

Следующей задачей для нас стало перенаправить все наши сетевые запросы на localhost. Для этого нам помог Dagger 2, который мы используем в проекте.

Здесь все по аналогии. Есть некоторый Application-компонент, для теста мы создаем TestApplication-компонент, который наследуется от Application-компонента, но использует другие модули сетевого взаимодействия.

Вот пример такого модуля.

Оба модуля используют базовые сетевые модули, но предоставляют разную реализацию endpoint и OkHttpClient. Вот наш сетевой модуль, который как раз использует эти компоненты.

Когда мы запускаем что-то в тестах, то ходим на localhost.

Когда мы запускаем prod в сборку, то мы идем на продовый endpoint.

Что получилось в тесте? Добавляется вот такой блок для конфигурации WebServer. Здесь мы используем простенький DSL, в котором мы обращаемся к Instrumentation, получаем Application, кастуем его к нашему тестовому, и оттуда уже можем обращаться к его полям.

Помните, мы определили там Dispatcher? Какие плюсы? Такой подход позволяет нам изолироваться от внешней среды и тем самым повышается стабильность. Наши тесты становятся независимыми от интернета и перестают неупорядоченно падать.
Из минусов: необходимо готовить Mock’и ответов. Порой они бывают очень громоздкими, это повышает трудоемкость.

Пару слов об изоляции от внешних приложений. Здесь у Espresso есть отдельный модуль под названием Espresso-Intents. Он позволяет нам записывать ожидаемые Intent, которые запускает наше приложение, и мокать их ответ. Но на этом мы не будем подробно останавливаться.
Улучшаем восприятие теста
Помните, я рассказал, что нам не понравилось, как пишутся Espresso-тесты и нам хотелось добиться чего-то более лаконичного? Изначально планировалось, что команда тестирования будет смотреть код наших тестов и таким образом валидировать их.

Пример. Если посмотреть на наш тест, то видно, что для совершения простых действий — введи текст, нажми на кнопку и так далее — нам приходится совершать много манипуляций.

Здесь нам на помощь пришли так называемые тестовые роботы. Идея этих роботов: мы пытаемся отделить то, что мы делаем, от того, как мы это делаем. Появляются высокоабстрактные методы взаимодействия, которые скрывают от нас детали реализации.

Пример такого тестового робота мы можем посмотреть здесь. Тестовый робот — это дополнительная абстракция, представляющая собой часть пользовательского интерфейса, для которой характерен набор неких базовых действий.

Например, в нашем случае на первом экране ввода пароля есть действие «ввести пароль» и действие «нажать на кнопку». Мы посмотрели и поняли: было бы удобно переиспользовать алгоритмы поиска элементов на экране, и тоже выделили их в отдельную абстракцию, которую мы назвали Lookup.

Таким образом, получается базовый тест, который был разбит на робота и Lookup и преобразился примерно так.

Что мы видим теперь? Появились некоторые контексты, мы видим два экрана. Для каждого экрана мы создали своего робота. В каждом роботе есть функциональность, характерная для этого экрана. В тесте мы теперь можем это четко наблюдать. Есть некоторое разделение по контексту, тесты стало проще воспринимать.
Как я уже сказал, появилась декомпозиция — по функциональности, по Matchers. Из минусов: появляются Boilerplates по написанию роботов. Поговорим о нем более подробно чуть позднее.
Стабильность Espresso
Поговорим про стабильность Espresso и поймем, за счет чего она достигается. Google позиционирует свой фреймворк как инструмент для написания стабильных тестов.

В основе этгого лежит следующий подход. Каждый раз, когда мы вызываем onView и пытаемся выполнить какие-то действия или проверки, они не будут выполнены до тех пор, пока очередь сообщений основного потока не будет пуста, либо не будет выполняться никаких AsyncTask, либо все так называемые IdlingResource будут находиться в состоянии idle.
Первые два пункта, очередь сообщений и AsyncTask, — это компоненты, которые известны системе Android, и она может их сама контролировать. Но существует множество других ресурсов, о которых Android не знает и не понимает, как их контролировать. Поэтому здесь вводится дополнительная абстракция IdlingResource. Этот инструмент предоставляет разработчику возможность определять такие асинхронные операции и сообщает фреймворку Espresso, что пока исполнять нельзя тест.

В качестве примера такого ресурса рассмотрим OkHttp3IdlingResource. Так как мы применяем библиотеку OkHttp, то можем без проблем использовать и его тоже. Подключить к нашему тесту можно с помощью Rules, о которых я уже говорил.

Здесь используется тип ExternalResource. Его особенность в том, что он выполняет действия до исполнения теста и после.

А создать такой ресурс можно опять-таки на основе доступа к нашему тестовому контексту, из которого мы можем получить OkHttpClient. Это реализовывается средствами Dagger.
Пример использования. Нам необходимо добавить такой Rule в тест. Для этого используется RuleChain, то есть цепочка Rules.

В цепочку можно добавлять сколько угодно правил.

Из плюсов IdlingResource: у пользователя появляется возможность размечать асинхронные ресурсы и тем самым повышать стабильность своего приложения. Из минусов: не всегда просто эти ресурсы реализовать. Природа наших приложений может быть в значительной степени асинхронной, не все ресурсы могут быть легко доступны из тестового кода, и здесь могут возникать проблемы.
Что же делать, если использование IdlingResource затруднительно? Мы хотим добиться написания стабильных тестов, но сейчас, например, не можем себе позволить реализовать IdlingResource во всех местах приложения.

Мы, например, использовали вот такой известный костыль. Грубо говоря, это цикл, в котором мы проверяем, не выполнилось ли наше условие, не оказались ли мы в ожидаемом состоянии. Если по истечении заданного интервала мы не оказались в ожидаемом состоянии, то тест падает. За счет этого простого инструмента, который не рекомендуем к использованию, а рекомендуем все-таки использовать IdlingResource, нам удалось добиться значительной стабильности исполнения наших тестов.

Как использовать это в тесте? Предположим, мы нажали на кнопку «проверить пароль», переходим на вторую Activity, и на ней мы, прежде чем выполнять проверку, можем дождаться — действительно ли элемент появился на экране? Если да — выполнить проверку. Интеграция такой конструкции в тесте выглядит достаточно лаконично. Чуть-чуть избыточно, но что делать.
Из плюсов: простой способ повышения стабильности. Из минусов: в тестах появляется дополнительный код, и теоретически, это может негативно повлиять на время исполнения тестов, привести к дополнительным простоям.
Улучшаем отчет
Еще одним пунктом, о котором я говорил, был отчет. Нам не понравился базовый отчет, нам хотелось большего: проще узнавать, в чем проблема, быстрее реагировать на возникающие сложности.

Здесь мы решили попробовать использовать фреймворк построения отчетов Allure. Легковесный, предоставляет дополнительные средства построения отчета. Интеграция Allure происходит очень просто. Достаточно унаследоваться от их AllureAndroidJUnitRunner, и это уже позволит вам строить отчет. Также в Allure предоставляется базовый набор Rules. Например, есть ScreenshotRule, WindowHierarchyRule, LogcatRule. То есть, если у вас происходит тест, к нему автоматически будут добавлены скриншоты, логи из Logcat, иерархия представлений. Уже можно будет проанализировать результаты, информации чуть больше, чем в случае с Espresso.
Генерация отчета происходит либо из командной строки, либо с помощью Allure Gradle plugin.

Отчет выглядит примерно так. Опять-таки, мы видим, сколько тестов выполнилось, сколько нет и сколько они выполнялись по времени.

Можно проваливаться в тесты.

Увидеть, как раз на этом скриншоте, что к сфейленному тесту добавилась дополнительная информация. Еще одна интересная возможность, которую предоставляет Allure: накопление информации и ведение статистики. То есть когда вы агрегируете Allure-отчеты в одном месте, можно вести настоящий трекинг того, как проходило ваше тестирование, как вы фиксили проблемы, как они появлялись, исчезали и так далее.
Но еще одна важная особенность Allure-отчетов — средства документирования, которые он предоставляет. Это специальные средства, которые позволяют размечать ваш тест так, чтобы его шаги или особенности его исполнения попадали в этот отчет либо с помощью аннотаций, либо с помощью классов, если аннотации нам не подошли.
Мы были очень заинтересованы в том, чтобы получился более документированный отчет, чтобы команда тестирования смотрела не в код наших тестов, а в отчет и понимала, что там происходило.

Для этого мы решили создать прослойку между основными компонентами Espresso, которые мы назвали именованные компоненты.

Это просто обертка, которая добавляет имя. Таким образом появились обертки для Matchers.

И для Assertions, и для Actions.

И для Interaction. Входной точкой для наших тестов стал уже не Espresso#onView, а NamedViewInteraction#onView.

Идея была в том, что для всех действий добавляется человекопонятное имя, которое будет отражено в отчете с помощью команды step, которую здесь можно видеть.

То есть каждый раз, когда мы выполняем проверку, в отчете будет зафиксировано, что именно мы проверяем.

Также мы модифицировали всех наших роботов, добавив в их входную точку команду step, которая говорит, что начинается активность. И модифицировали все наши Lookup — добавили к ним человекопонятные имена.

Это привело к тому, что сгенерировался вот такой отчет, из которого уже можно понять, что и в каком контексте происходит, что и куда мы вводим.

Тестирование может прочитать этот отчет и понять, какой пользовательский сценарий мы этим покрыли.

Также здесь можно видеть, на каком шаге произошла ошибка. Нам это очень понравилось.
Из плюсов: появилась функциональность по конфигурированию отчета и некая автодокументируемость. Из минусов: необходимо решить инфраструктурные задачи: например, как мы строим этот отчет, как храним и передаем файлы Allure. Также замедляется время исполнения тестов, поскольку появляется больше работы с файлами, мы начинаем хранить скриншоты и так далее.
Качество тестов
На этом этапе у нас уже был какой-никакой подход к написанию тестов. Они были достаточно стабильными. У нас уже был отчет, и мы стали задумываться, насколько качественно мы вообще проверяем UI?
Ведь если бы проверял тестировщик, он смотрел бы не только на то, что написано в поле, что это хороший пароль. Он проверял бы, как элемент расположен на экране, смотрел бы на цвет текста, на шрифт и так далее. Мы подумали над этим, и вот пример такой проблемы. Кто-то поменял верстку. Или мы обновили какую-то библиотеку, и верстка поехала, constraint сломался, или еще что-то.

Текущий тест на эту проблему никак не реагирует, но тестирование в ручном режиме смогло бы ее обнаружить. Мы пришли к тому, что решили сравнивать скриншоты.

Для этого мы написали простой Interaction и абстракции в стиле Espresso.

Выглядит это примерно так. В роботе появляется функциональность по сравнению скриншотов. Что произошло в отчете?

В отчет в случае ошибки мы добавляем то, что ожидали увидеть, то, что получили, и diff.

Теперь мы проверяем не то, что конкретная строка совпадает, а общее расположение элементов, их композицию на экране.

Из интересного можно отметить, как в принципе стоит сравнивать скриншоты, ведь мы делаем скриншоты-эталоны на одном эмуляторе, а сравниваем неизвестно где, на CI. Следует уделить влияние конфигурации ваших эмуляторов, именно тех, на которых вы делаете скриншоты, чтобы они совпадали с теми, на которых вы эти тесты прогоняете.
На что следует обратить внимание? Конечно, на форм-фактор, то есть на размер вашего экрана и режим отрисовки. В нашем случае нам необходимо было выключить GPU и скрыть кнопки. Если этого не сделать, у вас могут появляться различные артефакты из-за разницы реализации anti-aliasing в той или иной среде.
Скриншоты позволили нам проводить комплексную проверку UI. Написание тестов в целом ускорилось, потому что нам больше не надо было делать много разных проверок, достаточно было делать одну. Но опять появился ворох новых инфраструктурных задач, таких как хранение скриншотов, создание эталонов и прочее. Также это привело к тому, что тесты значительно замедлились: стало еще больше работы с файлами и появилось сравнение скриншотов.
Улучшаем тестовых роботов
Я говорил, что у нас были претензии к роботам, некоторый Boilerplate, и мы пришли к осознанию того, что это тоже хотелось бы поправить.

Посмотрим на проблему. Предположим, появляется новая функциональность. Например, мы захотели проверять, что элементы — кнопка или поле ввода — видны. Тогда в соответствии с подходом робота нам надо эту функциональность вывести в робот.

Потом на экране неожиданно появилась еще одна кнопка, и для нее мы тоже должны продублировать функциональность по нажатию и проверке видимости.

Или вдруг появился еще один робот, и возникают еще какие-то кнопки, поля ввода. Здесь мы тоже дублируем функциональность, которая по сути имеет одну и ту же реализацию. Изменяется лишь Matcher, который мы используем.
Здесь, вдохновившись подходом из библиотеки Kakao, мы пришли к так называемому компонентному подходу.

Идея компонентного подхода: мы выделяем функциональность не в робота, а в компонент. Роботы заменяются так называемыми Screens. Каждый Screen представляет какую-то часть UI по аналогии с роботом, но хранит набор компонент, которые есть в этой части UI.

Базовый Screen предоставляет базовую функциональность.

Базовые компоненты тоже представляют какую-то функциональность, а конкретный компонент, например EditText, предоставляет функциональность по вводу текста.

А в тесте получилось следующее.

Контекст остался: мы по-прежнему можем понимать, где производим действия. Единственное, чуть понизился уровень абстракции. Теперь мы вынуждены взаимодействовать с компонентами и вызывать на них действия.
Нас этот подход устроил. Прежде всего потому, что мы хотели ускорить написание тестов, снизить количество Boilerplate-кода. А для команды тестирования у нас уже были отчеты, которые позволили им больше не смотреть в тело теста без лишней необходимости. Минус я уже отметил: понизился уровень абстракции.
Время исполнения тестов
Наверное, вы заметили, что многое из того, что мы делали, негативно влияло на скорость выполнения. Что же делать?

Количество тестов растет, мы используем Orchestrator, waitUntil, Allure и так далее, замедление усиливается. Рассмотрим несколько вариантов. Можно делать частичное исполнение тестов. Например, мы не всегда прогоняем все тесты на каждый пул-реквест, на каждый коммит, а начинаем прогонять их порциями.
Либо мы реализовываем параллельное исполнение тестов с достижением необходимого, желаемого времени исполнения. Мы решили покопать в сторону этого варианта, посмотреть, что мы можем сделать с точки зрения параллельного исполнения.

Существует средство шардирования исполнения тестов через AndroidJUnitRunner. Однако оно доступно только из командной строки. Нам этот вариант тогда показался не очень удобным. Мы еще немного покопали в сторону сторонних фреймворков — например, Spoon. Но втягивание сторонних фреймворков нам казалось избыточным.
Есть Gradle-команда — выполняешь и получаешь список подключенных устройств. Разделяешь тесты по этим устройствам, исполняешь их на этих устройствах. Собираешь результат. Хотелось добиться чего-то такого, казалось бы, простого. Зачем здесь отдельный фреймворк?

Решили попробовать сделать нечто подобное. Для этого мы написали свой Gradle-таск, в основе которого так называемый Worker API Gradle. Его идея в том, что существуют специальные абстракции: WorkerExecutor, который позволяет параллельно исполнять некоторые подтаски в рамках одной корневой таски, и действие WorkAction. Конфигурировать их можно с помощью WorkParameters.

Также мы проанализировали базовую команду для запуска Android-тестов — connectedAndroidTest, и выясняли, какие в принципе существуют абстракции, чтобы сделать нечто похожее. Обнаружили, что существует некий AndroidTestOrchestratorRemoteAndroidTestRunner, позволяющий из кода запускать тесты. У него есть дополнительный ITestRunListener и набор средств конфигурации этого Runner. Однако часть API, которые мы тогда нашли, начиная с Gradle 4.0 стали Deprecated, поэтому нам пришлось скопировать некоторые компоненты в проект.

Текущая конфигурация исполнения наших тестов выглядит примерно так. Мы запускаем два агента. На каждом запускаем по восемь эмуляторов — здесь их для краткости три.

Как можно заметить, на 16 эмуляторах тесты исполняются примерно за 30 минут, а последовательное их исполнение занимает порядка 5 часов. Но это не совсем честное время. Столько мы потратим только на исполненея тестов, без накладных расходов с точки зрения инфраструктуры.
Итог
Чего мы добились, проделав все это?

Если посмотреть на этот график, то за год с момента интеграции UI-тестов количество наших релизов значительно выросло. Количество HotFix снижается. То есть тесты помогают нам писать более стабильный код, вносить масштабные исправления в проект без особой оглядки.
Сейчас у нас, по утверждению команды QA, автоматизирован 71% регрессионного тестирования, и сформирован план по дальнейшей автоматизации. На релизе мы проводим выборочное тестирование, которое занимает порядка двух-трех часов. Релизы случаются примерно раз в одну-две недели, как можно заметить по этому графику за последние три месяца.

Что с проблемами, которые были обозначены в самом начале?
Для изолированности наших тестов мы используем такие средства, как Android Test Orchestrator, MockWebServer, Espresso Intens. Dagger 2 помогает подменять зависимости в тестовой среде. Для стабильности у нас есть IdlingResource, есть костыль waitUntil. Так как мы используем кастомный Gradle-таск, есть возможность перезапускать тесты, которые по непредсказуемым причинам падают. Что касается времени исполнения тестов, нам удалось реализовать параллельное исполнение средствами кастомной Gradle-таски.
У нас сейчас написано примерно полторы тысячи тестов. Они исполняются примерно за один час с учетом всех накладных расходов. Гоняем мы их на каждый коммит, на каждый пул-реквест.
В написании тестов используются подходы с тестовым роботом. Выделили Matcher и Lookup, используем компонентный подход, сравнение скриншотов для упрощения написания. Отчеты строятся в Allure, который предоставляет нам некоторую автодокументируемость. Это позволяет команде тестирования анализировать тесты, которые мы реализовали, и фиксировать, какую часть регресса мы покрыли.
Что же дальше? У нас есть планы по расширению использования IdlingResource. Сейчас мы их, к сожалению, используем только для OkHttpClient. Также есть планы по улучшению инфраструктуры параллельного исполнения тестов. Сейчас возникают очень большие накладные расходы: как я сказал, тесты исполняются за 30 минут, а все остальное время занимают процессы передачи управления между подзадачами. И, разумеется, можно предпринимать еще какие-то шаги по улучшению нашего отчета.
Специально для вас я подготовил репозиторий с исходными кодами всего этого параллелизма, всех подходов, о которых я рассказал. Подробнее можно посмотреть там. Спасибо за внимание.
Полезные ссылки:
— developer.android.com/training/testing/espresso
— jakewharton.com/testing-robots
— docs.qameta.io/allure
— github.com/KakaoCup/Kakao
