

В рамках конкурса Shifts Challenge мы выкладываем в открытый доступ крупнейший в мире датасет для обучения беспилотных автомобилей, а также данные Яндекс.Переводчика и Погоды. Приглашаем исследователей в области машинного обучения присоединиться к поиску решения проблемы сдвига распределения данных в реальном мире по отношению к тому, с чем моделям приходится иметь дело при обучении.
Меня зовут Андрей Малинин, я старший исследователь в Yandex Research. Сегодня я расскажу о проблеме, о наших датасетах, а также о конкурсе, который мы проводим в рамках международной конференции NeurIPS 2021 совместно с учеными из Оксфордского и Кембриджского университетов.
Сдвиг распределения данных
Чтобы разработать модель, обычно используются три выборки данных: обучающая, отладочная и проверочная (те данные, с которыми модели придется работать в реальном мире). Считается, что эти три выборки, с одной стороны, независимы друг от друга (данные, например, в отладочной и проверочной выборках не должны пересекаться), а во-вторых, имеют одинаковое распределение. Исходя из этого, можно предположить, что модель, которая хорошо работает на отладочных данных, хорошо будет вести себя и в реальном мире — так как данные, пусть и разные, распределены одинаково.
К сожалению, в реальном мире все намного сложнее: разрабатывая модель, мы не можем наперед просчитать все ситуации, в которые она попадет. Наша модель в любой момент может столкнуться с так называемым сдвигом распределения (англ. distributional shift) — то есть ситуации, в которые она попадет, будут ей незнакомы просто потому, что она никогда не видела таких данных и не знает, как себя вести.
Если сдвиг распределения данных в реальном мире значителен относительно обучающей выборки (например, модель машинного перевода, которая училась на классической литературе, вдруг возьмется переводить твиты), недостаточно надежные модели будут ошибаться. Поэтому, попадая в реальный мир, модели должны быть готовы справляться со сдвигом, который их там ждет.
Этим, однако, дело не ограничивается. Чтобы модель работала эффективно и безошибочно, о вероятности ошибки лучше знать заранее: следовательно, модель должна давать оценку неопределенности относительно своих решений. Поэтому мы хотим добиться от моделей, с одной стороны, устойчивой работы при сдвиге распределения, а с другой — умения оценивать неопределенность.
Сейчас большинство исследований, посвященных устойчивости к сдвигу распределения и неопределенности, нацелены на решение задачи классификации изображений. Задача эта, безусловно, очень важна, но в масштабных промышленных проектах, помимо классификации изображений, есть и другие — включая те, в которых влияние ошибок, вызванных сдвигами распределения, может быть довольно значительным.
Shifts Challenge
Мы хотим помочь ML-сообществу преодолеть разрыв между исследованиями и технологиями в реальном мире, поэтому объявляем о соревнованиях Shifts Challenge, которые проводим вместе с Оксфордским и Кембриджским университетами в рамках конференции NeurIPS 2021.
Цель соревнования — повысить осведомленность сообщества о влиянии сдвигов распределения данных на работу моделей, разработать модели, устойчивые к сдвигам, а также научиться определять сдвиги, оценивая степень неопределенности в прогнозах.
В конкурсе три трека, для которых мы подготовили датасеты из разных сфер применения моделей: прогнозирования погоды, машинного перевода и предсказания участников движения на дороге.
Конкурс проводится в два этапа:
Первый этап, с 16 июля по 17 октября. Мы публикуем обучающий и отладочный датасеты. Участники разрабатывают модели и загружают их на отладочный лидерборд.
Второй этап, с 17 октября по 31 октября. Мы публикуем проверочную выборку. У участников есть две недели, чтобы настроить модели и загрузить их предсказания на сайт. Все результаты появятся в проверочном лидерборде.
После этого мы в течение месяца будем проверять решения участников, а 30 ноября объявим победителей: участники, занявшие призовые места, получат денежные призы.
А теперь подробнее расскажу о треках.
Предсказание траекторий движения
Проблема прогнозирования движения — одна из самых важных в сфере автономного вождения: беспилотному автомобилю, как и любому другому, требуется время на изменение скорости и направления. Чтобы обеспечить безопасную и комфортную поездку, модуль планирования должен предсказывать, где окажутся другие автомобили и прочие участники движения (например, пешеходы), на несколько секунд вперед.
Большинство компаний, разрабатывающих беспилотные автомобили, тестируют свои технологии в одной или нескольких локациях. Мир при этом невероятно разнообразен, и в новых городах или странах автомобили будут встречаться с абсолютно новыми для себя условиями движения, будь то другая погода или различия в ПДД. Кроме того, даже в очень похожих ситуациях манера вождения в разных странах может отличаться. Например, в Тель-Авиве водители чаще торопятся въехать на круговой перекресток, а в Иннополисе наоборот спешат выехать с него.
Поэтому очень важно научить беспилотный транспорт применять в новых для него местах как можно больше накопленных знаний и опыта — то есть справляться с тем самым сдвигом распределения. Другими словами, беспилотный автомобиль, который учился ездить безоблачным летом, должен справиться с поездкой по заснеженным дорогам.
В рамках этого трека мы публикуем крупнейший в мире датасет прогнозирования движения транспортных средств. Он собран разработчиками беспилотных автомобилей Яндекса и содержит 600 тысяч размеченных сцен (это более 1600 часов вождения): в датасет вошли поездки беспилотников по городам России, США и Израиля в самую разную погоду — от безоблачного ясного дня до заснеженной ветреной ночи. Суть задания в этом треке: спрогнозировать для каждого транспортного средства 5-секундные траектории движения, а также выдать понятную метрику неопределенности прогноза.
Машинный перевод
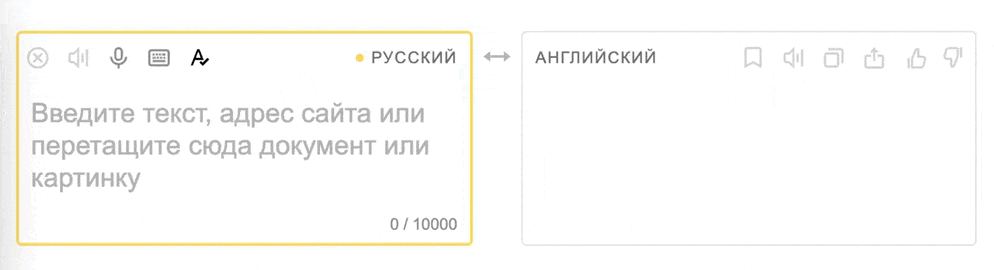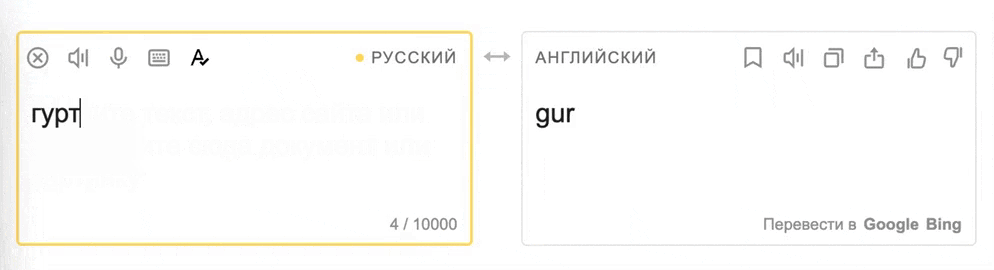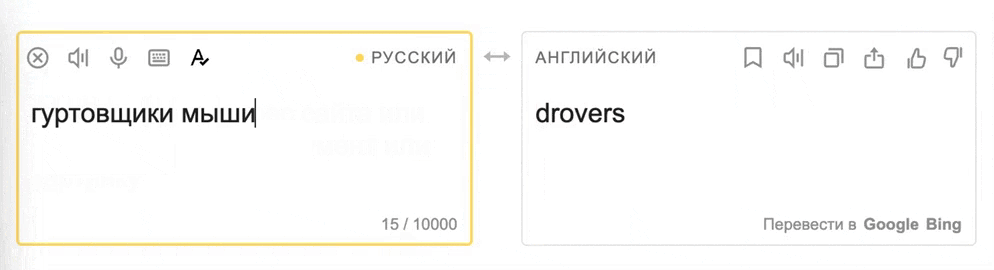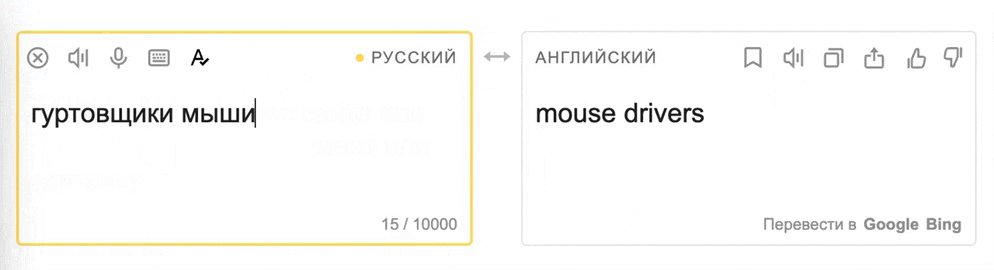
Сервисы машинного перевода, такие как Яндекс.Переводчик, часто сталкиваются с нетипичным и необычным использованием языка, включая сленг, ненормативную лексику, плохую грамматику, орфографические и пунктуационные ошибки, а также эмодзи — язык, а особенно повседневный онлайн-вариант, все же достаточно живой. Для современных моделей, которые используются в машинном переводе, такой язык представляет серьезную проблему, так как большинство переводчиков обучаются на чуть более формальном языке: классической литературе, юридических документах или статьях Википедии.
Для качественного машинного перевода важно, чтобы модели были устойчивы к нестандартной лексике и ошибкам и в любом случае выдавали качественный перевод — даже если перевести нужно фразу из мема.
В треке перевода мы использовали для обучения англо-русский корпус WMT’20, который в основном состоит из государственных и новостных текстов. В них мало ошибок, язык формальный — именно на таких «стерильных» текстах обучаются многие системы машинного перевода.
Данные для отладки и проверки модели состоят из двух частей: со сдвигом и без. Данные без сдвига взяты из англо-русского корпуса Newstest’19, а также из корпуса новостных текстов, собранных службой Global Voices и переведенных Яндексом. Данные со сдвигом для отладки взяты из подготовленного для WMT Robustness Challenge корпуса Reddit и также переведены Яндексом. Для проверки модели на данных со сдвигом мы также собрали, перевели и разметили дополнительные данные с Reddit.
Задача модели — перевести предложение с исходного языка на целевой. Важно, чтобы модель была устойчива к неформальному и нетипичному использованию языка, обеспечивала высокое качества перевода на выборках со сдвигом распределения и указывала высокую степень неопределенности на тех примерах, на которых она ошибается.
Предсказание погоды

Составление прогноза погоды с помощью моделей — тоже задача нетривиальная. Во-первых, данные по климатическим зонам могут быть нерепрезентативны: где-то метеостанций больше, где-то — меньше. Кроме того, климатические процессы довольно нестационарны (другими словами, климат весьма изменчив). Поэтому даже самые качественные модели предсказания погоды могут со временем стать неактуальными и давать неправильные прогнозы.
Для трека предсказания погоды мы предоставляем участникам данные, собранные командой Яндекс.Погоды. Они табличные, каждый временной отрезок соотнесен с разными климатическими характеристиками: показателями атмосферного давления, влажности, измерениями ожидаемой температуры на определенной широте и долготе и так далее — всего 111 характеристик.
Участникам трека нужно разработать модель, предсказывающую измеренную метеостанцией температуру на определенной широте и долготе в определенный момент времени с учетом всех доступных измерений и прогнозов. Модель должна быть устойчива к сдвигам по времени и климатическим зонам, а также указывать высокую степень неопределенности на примерах, на которых она ошибается.
Как начать
Подробные условия, тайминг и описания доступных датасетов можно найти на сайте конкурса. Детали датасетов, метрик оценки и бенчмарков есть в нашей статье.
Ссылки на данные доступны в нашем репозитории на GitHub. Чтобы помочь вам начать работу, мы загрузили туда примеры и сделали базовые модели доступными для скачивания.
Призываем участников челленджа присоединиться к нашему сообществу в Slack — там можно задавать вопросы организаторам и дискутировать с другими участниками.
Мы надеемся, что NeurIPS 2021 Shifts Challenge приблизит нас к пониманию того, как модели могут предсказывать неопределенность, работать со сдвигами распределения в данных, и как следствие — к более надежным и безопасным технологиям.
