

Привет, Хабр. Меня зовут Святослав Фельдшеров, я разрабатываю инфраструктуру в поиске Яндекса. Когда-то она представляла из себя бутерброд. Каждый её слой могли эффективно разрабатывать единицы людей. Однако верхний добавлял пикантности. Этот слой представлял из себя Apache с кучей Perl’овых модулей.
Поддерживать большой объём кода на стареющем языке программирования дорого и сложно, развивать — ещё дороже и сложнее. Так верхний слой Поиска оказался разделён на микросервисы, целую вселенную микросервисов. Как это обычно бывает, создавая что-то своё, мы получили нечто непохожее на всё, существующее снаружи.
Сегодня я расскажу, что у нас получилось, какие достоинства и недостатки у нашего решения. Возможно, нечто подобное уже существует в опенсорсе или в вашей компании, поэтому буду рад обсудить тему в комментариях.
Почему наша вселенная альтернативная?
Что приходит в голову первым, если задуматься о микросервисной инфраструктуре? Облако, большое количество сервисов, которые «общаются» между собой. Здесь мы не привнесли ничего нового, сейчас в поиске Яндекса больше сотни различных сервисов. Но что значит «общаются»?
Архитектуру любого крупного сервиса Яндекса, в том числе Поиска, можно представить в виде большого графа. Его узлы — сервисы, рёбра — потоки передачи данных. Перейдём к примерам. Рассмотрим сервис больше чем из одного компонента: балансер, некоторый фронтенд, обращающийся к шардированному бэкенду:

В чём проблема этой картинки? Допустим, вы отправили запрос в первый бэкенд, а он вернулся с кодом 500 или затаймаутился. Самая простая гипотеза — обычное невезение: затупила сеть, инстансу бэкенда, в который вы попали, стало плохо. Перезапросить ошибку в таком случае — вполне естественное желание. Но нельзя же повторять запросы бесконечно: если проблема посерьёзнее невезения, получим DDOS своими руками, бэкенд ляжет и не сможет вернуться к работе без вмешательства человека. Чтобы нагрузка не превышала разумную, важно предусмотреть в структуре балансера и фронтенда бюджеты на повторные запросы и классифицировать ошибки: перезапрашиваемые, быстрые, неперезапрашиваемые. Написать такую логику не очень сложно, но потребуются усилия и внимание всех команд компании.
Такой подход сработает для сервиса из одного слоя, как на картинке выше. Но если слоёв больше — n, возникает проблема: нагрузка на нижний слой возрастет как (k)^n, где k — максимальное количество перезапросов на одном слое, оно же «рейт перезапросов». Побороть эту проблему сложнее: либо не делать сервисы многослойными, либо пробрасывать информацию про бюджет вместе с запросом и ответом каждого сервиса.
Вторая проблема — отслеживание пути запроса. Чтобы новый член команды мог узнать, как запрос попадает в какую-либо компоненту сервиса, ему потребуется прочитать код проекта от начала до конца. Для огромных систем масштаба поиска Яндекса это неосуществимо.
Третья проблема: логи об ошибках обращений в соседние микросервисы распределены по всему кластеру. И чтобы получить полное понимание того, что происходило с запросом, нужно погрепать несколько различных логов (в нашем случае — балансера, фронта и бэкендов). Для полноценного расследования того, что произошло с запросом, нужно прочитать их все. С решением этой задачи хорошо помогают системы сбора ошибок или трейса запросов.
Четвертая проблема — это, конечно, мониторинги. Нужно отслеживать состояние каждого сервиса, оценивать, как его видят потребители. Если некоторый внутренний сервис X участвует в обработке запроса, к нему ходят другие сервисы. Для всех них нужны мониторинги ответов X, то есть любой компонент системы должен отдавать статистику о запросах, которые он делает. Если в системе два компонента, как выше, это вполне приемлемо. С увеличением числа компонентов, количество стыков, где может возникнуть проблема, рано или поздно станет слишком велико.
Пятая проблема. Назовём ответы всех сервисов, которые мы получили к текущему моменту, состоянием выполнения запроса. Физически у него нет единой локации, оно распределено между всеми опрошенными сервисами.
Если инстанс сервиса, к которому мы обратились, почему-то не смог ответить наверх, всё, что ниже него, сработало вхолостую: ответы хранятся только в памяти текущего инстанса. Единственная надежда — всё, что отработало, запишет результаты в кеш, и мы сможем быстро восстановить их при перезапросе. Но поддержка таких кешей для каждого микросервиса уже не самая простая задача.
Шестая проблема. Добавление нового функционала требует доработки каждого сервиса, через который проходит запрос. Помните сравнение с бутербродом? Каждый раз потребуется вносить изменения в каждый слой, увеличится нагрузка на разработчиков.
Несколько лет назад, наш Поиск с переменным успехом решал эти проблемы. Но с ростом сложности системы пятая и шестая проблемы начали болеть слишком сильно. Тут-то и зародилась альтернативная вселенная.
Всё сетевое хождение в нашей вселенной выполняет один сервис — Apphost. В его конфиге прописаны связи и зависимости между сервисами. Например, граф для сервиса из примера выше в мире Apphost выглядел бы как-то так:

Напомню: это граф зависимостей потоков данных между сервисами. Каждая вершина — отдельный сервис в нашем облаке.
Почему нам так нравится наша вселенная?
Она решает описанные выше проблемы.
Если каждая команда пишет перезапросы самостоятельно, легко перегрузить источники. В Apphost прописаны хорошие перезапросы с бюджетами, что исключает рукотворный DDOS. При этом во всех хороших инсталляциях над Apphost есть только балансировщик нагрузки, то есть в системе три слоя. Рейт перезапросов мы настроили в 10% от потока, и проблема «сервис уложило перезапросами» почти решена.
Путь запроса и расположение интересующего сервиса можно посмотреть в конфиге Apphost. Это всё равно непросто, например основной граф веб-поиска выглядит так:

Но представьте, каково было бы собирать то же самое из кода по всему проекту!
Проблема мониторингов тоже исчерпана: запросы делает ровно один компонент, и его ошибки видны на графиках. А логи Apphost позволяют почти мгновенно вычислить больной сервис, и, главное, проследить процесс выполнения запроса.
Статус запроса теперь хранится в Apphost и теряется, только если тот умер. На сдачу получили приятную оптимизацию: если из-за ошибки критически важного источника весь граф выполнить не получится, процесс прерывается. До оставшейся части источников запросы не дойдут, а уже отправленные можно отменить.
Что касается добавления нового функционала, доработка каждого сервиса больше не требуется. Достаточно разработать новую вершину и включить её в граф. Это ускоряет развитие продукта: почти исчезает необходимость синхронизации между командами, пропадают узкие места в разработке. Добавить изменение, не погружаясь при этом в чужую кодовую базу, может любой разработчик.
И на солнце бывают пятна: узкие места Apphost
Хотя наш мир нам нравится, у жизни в нём есть свои сложности.
Первое, что бросается в глаза — неравномерное потребление сети. Apphost делает запросы в каждый источник и передаёт в него данные. Если посмотреть на запросы по сети, получится звезда:
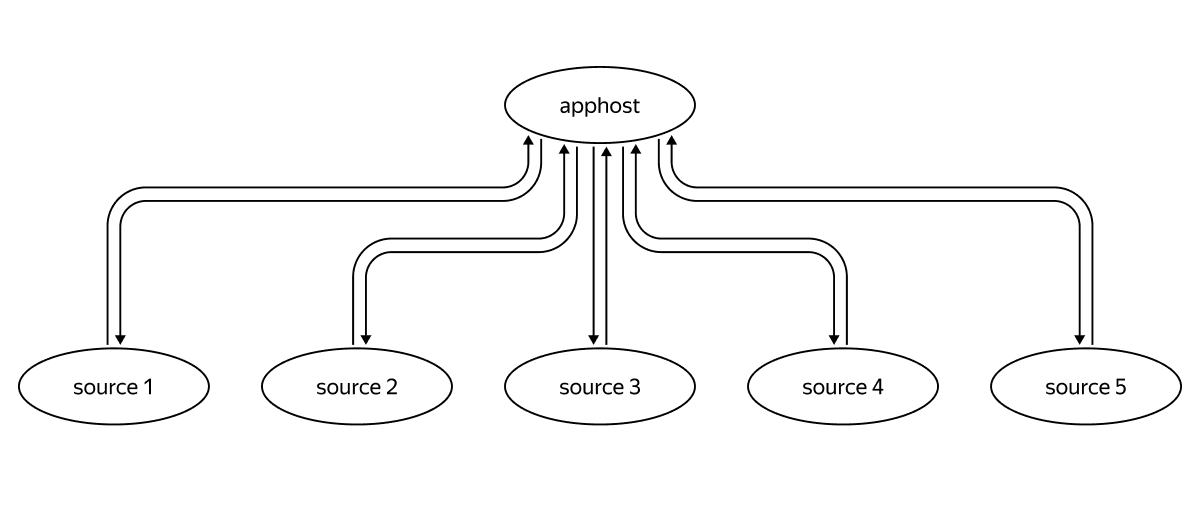
Кажется, что если бы источники сами передавали информацию друг другу, количество переданных данных упало бы почти вдвое. Но часто между сервисами есть как минимум один балансер, то есть запрос из одного в другой попадает за два сетевых хопа, так же как в Apphost. Таким образом, оверхед не очень большой, а централизация в этом месте даёт плюсы, о которых я говорил выше.
Так как основной потребитель сети — Apphost, мы расселяем его контейнеры, маленькие по вычислительной мощности, на большое количество физических хостов. Так нагрузку на сеть удаётся распределить равномерно. Теоретически можно учитывать потоки данных в графах при планировании расселения контейнеров и делать так, чтобы большая часть коммуникации проходила в одной стойке, но пока это очень далекое будущее.
Второе несовершенство системы — наличие в некотором смысле единой точки отказа. Apphost не работает = не работает ничего. Но если присмотреться, эта ситуация не сильно отличается от общепринятой: не работает балансировщик нагрузки над вашим сервисом или первый сервис, принимающий запрос = ничего не работает. На деле так как инстансов Apphost много, они живут на машинах из разных стоек — значит, сервис выживает при выпадении хоста, стойки или даже целого датацентра.
Заключение
Apphost, как мы его видим, хорош для больших сервисов, которые не умещаются на одну машину. Он позволяет декомпозировать почти неограниченно, не превращая дебаг в ад. Однако для маленьких сервисов, состоящих из одной-двух не очень сложных компонент, переложение на аппхостовый граф может усложнить систему, поскольку появится новая, избыточная сущность.
Для меня до сих пор загадка есть ли что-нибудь похожее в опенсорсе. Но и как делать проекты масштаба нашего Поиска без аналога Apphost, представить не могу. Слышал про похожие идеи у Dropbox, Uber и Microsoft, но не знаю деталей о них. Если вы сталкивались с чем-то подобным, приходите обсудить в комментариях.
Спасибо!
