
В каких ситуациях удобно применять предобученные модели машинного обучения внутри ClickHouse? Почему для такой задачи лучше всего подходит метод CatBoost? Не так давно мы провели встречу, посвящённую одновременному использованию этих двух опенсорс-технологий. На встрече выступил разработчик Николай Кочетов — его лекцией мы и решили с вами поделиться. Николай разбирает описанную задачу на примере алгоритма предсказания вероятности покупки.
— Сначала о том, как устроен ClickHouse. ClickHouse — это аналитическая распределенная СУБД. Она столбцовая и с открытым исходным кодом. Самое интересное слово здесь — «столбцовая». Что оно значит?
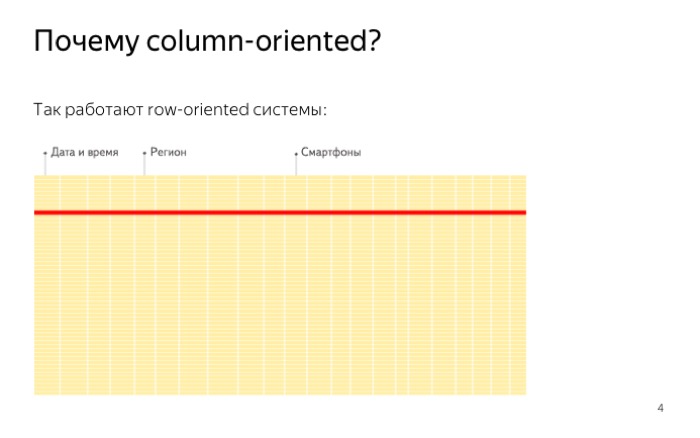
Вот как хранятся данные в обычных базах. Хранятся построчно, файлы записаны подряд. Другими словами, если нам нужно прочитать данные всего лишь для одного значения, мы вынуждены читать целую строчку. Это происходит из-за особенностей жесткого диска. Невозможно прочитать один байт, и случайное чтение стоит гораздо дороже, чем последовательное. В итоге мы читаем много лишних данных.

В ClickHouse все устроено совсем не так. ClickHouse хранит данные по столбцам, и значит, когда мы должны прочитать всего один признак, одну колонку, мы читаем ровно один файл. Это делается гораздо быстрее, примерно так, как на слайде.
Дополнительно ClickHouse сжимает данные, и то, что мы храним данные по столбцам, дает нам преимущество. Данные получаются более отдаленные и лучше сжимаются.
Сжатие нам тоже экономит место на диске и позволяет выполнять запросы быстрее во многих сценариях.
Насколько быстрый ClickHouse? Мы проводили тестирования по скорости в компании. Покажу лучше тестирования людей со стороны.
На графике сравнение ClickHouse, Spark и БД Amazon Redshift. ClickHouse на всех запросах работает в разы быстрее, хотя базы похожи по структуре, они тоже столбцовые.

ClickHouse поддерживает SQL-синтаксис. Это не честный SQL, это диалект. Также в ClickHouse есть возможность использовать специальные функции: работу с массивами, встроенные структуры данных или функции, специфичные для работы с URL. Вставка в ClickHouse тоже происходит быстро. Мы вставили данные и сразу же можем с ними работать. Получается работа в онлайне не только для запросов, но и для вставок.
Говоря про распределенные данные — ClickHouse может работать на ноутбуках, но прекрасно себя чувствует и на сотнях серверов. Например, в Яндекс.Метрике.
Перейдем ко второй части. Мы будем использовать некоторую вспомогательную задачу — предсказание вероятности покупки. Задача довольно простая. Допустим, есть данные из магазина. Хотим извлечь из них пользу, узнать больше информации о пользователях. Можно было бы считать вероятность покупки, что-то с ней делать. О том, что именно с ней делать, я подробно не буду рассказывать. Расскажу на примере. Например, можно разделить пользователей на две категории: хороших и не очень. Хорошим показывать больше рекламы, не очень хорошим меньше. И — экономить на рекламе либо получать бо́льшую конверсию.
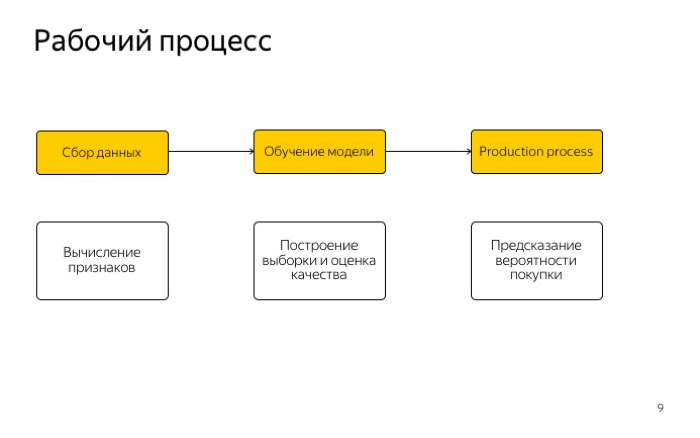
Посмотрим на рабочий процесс. Он очень простой и всем вам знаком, три этапа: работа с признаками, сбор данных и получение выборки.
Второй этап — обучение модели и оценка ее качества.
Последнее — использование модели в продакшене.
Откуда брать данные? Можно брать из Яндекс.Метрики, там данные хранятся внутри ClickHouse. Мы также будем использовать ClickHouse. Но данные, что мы брали, мы брали с использованием Logs API метрики. Мы представляли себя внешним пользователям и загружали данные с помощью того, что доступно внешним людям.
Какие данные мы могли получить? Во-первых, информацию о просмотренных страницах, какие товары видел, что он посещал. Также это состояние корзины пользователя и какие покупки он делал для этого.
Последнее — устройство, с которого пользователь заходил, тип браузера, десктоп или мобильный клиент.

То, что мы храним данные в ClickHouse, дает нам преимущества. Конкретно в том, что мы можем посчитать практически любые признаки, которые можем придумать, так как ClickHouse хранит данные в неагрегированном виде, есть пример — вычисление средней длительности сессии.

Пример имеет несколько особенностей. Первая — отсечение по датам. Мы использовали start и end_date, и ClickHouse с этим эффективно работает, он не будет читать то, что мы не запросили. Также мы использовали sampling: сказали, что будем читать 1/10 часть данных. ClickHouse делает это эффективно, он выбрасывает ненужные данные сразу после прочтения данных с диска.

Упомяну обучение моделей. Какие классификаторы мы использовали?
У нас есть обученная модель, она выдает хорошее качество. Как теперь ее внедрять?
Казалось бы, вопрос простой. Давайте делать просто: каждый понедельник выгружать из ClickHouse данные за предыдущий месяц, запускать питоновские скрипты, получать вероятность покупки и загружать обратно, скажем, в ту же таблицу ClickHouse. Это все хорошо работает, просто и эффективно написано, но возникают некоторые недостатки.
Первый недостаток в том, что данные должны выгружаться. Это может тормозить, причем не внутри ClickHouse, а скорее всего внутри питоновских скриптов.
Второй недостаток — мы готовим ответы заранее, и если мы считали вероятность покупки с понедельника на воскресенье, мы не можем это просто узнать со среды по четверг, например, или за прошлый год.
Один из способов это решить — внимательно посмотреть модель. Модель устроена просто: операции сложения, умножения, условные переходы. Давайте запишем модель в виде запросов ClickHouse, и сразу избавимся от наших недостатков. Во-первых, мы не используем выгрузку данных, а во-вторых, можем подставить любые даты и все будет работать.
Но возникает вопрос: какие алгоритмы мы можем перенести в СУБД? Первое, что приходит на ум, это использование линейных классификаторов.

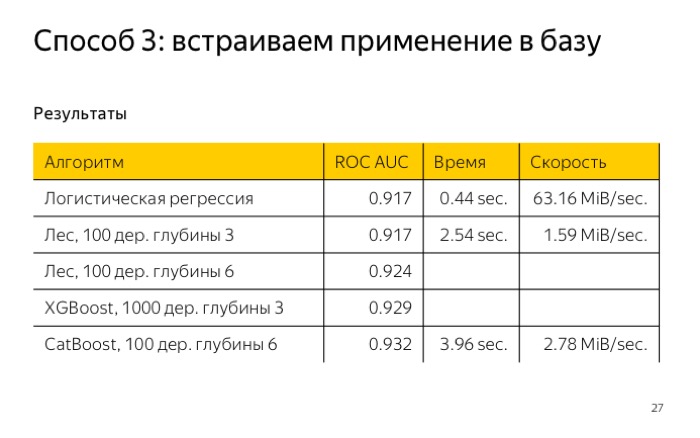
Для его применения нужно перемножить векторы весов на значение признаков и сравнить с каким-то порогом. Для примера, я обучил наши выборки логистической регрессии и получил качество log loss 0,041. Далее я проверил, насколько быстро это работает в ClickHouse, написал запрос, и он отработал меньше, чем за полсекунды. Неплохой результат.
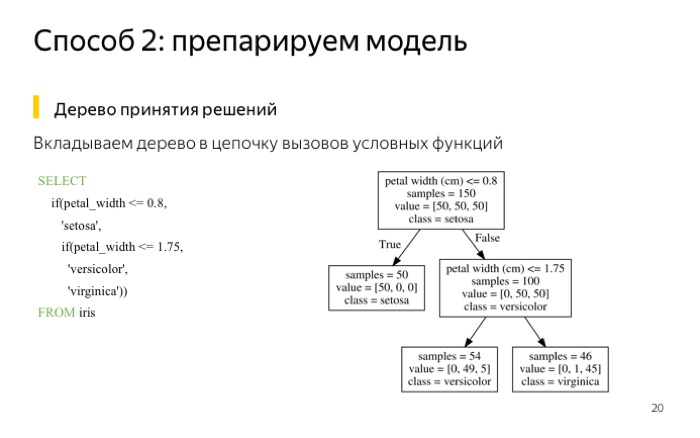
Если у нас что-то сложнее, чем линейная модель, например, деревья, их тоже можно написать в виде запроса ClickHouse. Что я сделал? Взял выборку ирисов. Эта выборка хороша тем, что для нее можно обучить маленькое дерево с глубиной два. У нее получается ошибка меньше 5%. Если вам так повезло, что у вас хорошая выборка, вы можете использовать маленькое дерево.

Можно написать запрос, условно, в виде двух функций выбора, и все тоже будет хорошо работать. Ингридиентный бустинг или лес, например. Нужно посчитать сумму или среднее. Я тоже протестировал это для маленького леса, 100 деревьев глубиной 3, в итоге получил качество даже хуже, и работает он в ClickHouse 2,5 секунды.
Не все так плохо, если бы я обучал больше деревьев, качество было бы лучше. Но почему я так не делал? Вот почему.

Вот как выглядит третья часть леса на 100 деревьев. Мне видно, что это очень похоже на лес. И если сделать запрос еще больше, то ClickHouse начинает просто тормозить на парсинге.

И получили дополнительные недостатки. Помимо того, что запрос очень длинный, мы вынуждены его придумывать, и это может медленно работать в самой БД. К примеру, для деревьев, чтобы применить их, ClickHouse вынужден считать значение в каждом узле дерева. И это неэффективно, ведь мы могли бы посчитать значения только на пути от корня к листу.
Возникает проблема с производительностью, что-то может тормозить и неэффективно работать. Это не то, что мы хотим.

Мы хотели бы более простые вещи: сказать базе, что давай ты сама будешь разбираться с тем, как применять модель, мы просто скажем тебе, что здесь лежит библиотека машинного обучения, а ты мне дай просто функцию modelEvaluate, в которую мы положим список наших признаков. Такой подход, во-первых, обладает всеми преимуществами предыдущего, а во-вторых, перекладывает всю работу на базу данных. И всего есть один недостаток — ваша база должна поддерживать применение данных моделей.
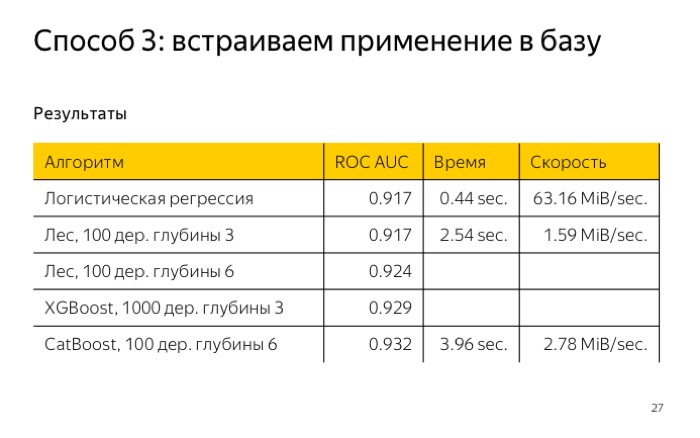
В ClickHouse мы это реализовали для CatBoost, конечно, протестировали. Получили наилучшее качество, при том что я обучал… Время обучения не очень большое, всего 4 секунды. Это сравнимо хорошо по сравнению с лесом 100 глубиной 3.

Что можно видеть в итоге?
Если вам важно видеть скорость работы, скорость обременения алгоритма, не так важно качество, то можно использовать логистическую регрессию, это все будет быстро работать.
Если вам важно качество, то обучите CatBoost и используйте его. Как же использовать CatBoost в ClickHouse?

Нужно сделать несколько довольно простых действий. Первое — описать конфигурацию модели. Всего 4 значимых строки. Тип модели — сейчас это CatBoost, возможно, когда-то добавим новое.
Имя модели, которое будет использоваться как параметр функции modelEvaluate().
Расположение обученной модели на файловой системе.
Время обновления. Здесь 0 — это значит, мы не будем перечитывать материал диска. Если стояло бы 5, перечитывали бы каждые 5 секунд.

Далее нужно сказать ClickHouse, где лежит файл с конфигурацией, это нижний параметр на слайде. Там используется звездочка, это значит, что все файлы, что подходят под эту маску, будут загружены.
Также нужно сказать ClickHouse, где лежит сама библиотека машинного обучения, а именно модуль обертки для CatBoost.

Все, когда мы это указали, у нас получается возможность функцию modelEvaluate(), которая принимает первым аргументом имя модели из конфигурационного файла, остальным наши признаки. Причем надо указывать сначала числовые признаки, затем категориальные. Но не беспокойтесь, если вы что-то перепутаете. Во-первых, ClickHouse скажет вам, что у вас ошибка. Во-вторых, вы можете протестировать качество и понять, что все не так, как вы думали.

Чтобы было удобнее тестировать, мы также добавили поддержку чтения из пула данных CatBoost. Наверное, кто-то работал с CatBoost из консоли вместо того, чтобы работать с ним из Python или из R. Тогда вам пришлось бы использовать специальный формат описания вашей выборки. Формат довольно простой — всего два файла. Первый — TSV c тремя колонками, номер признака и его тип: категориальный, числовой или таргет. Плюс дополнительный опциональный параметр имени. Второй файл — сами данные, тоже TSV.

Как раз в ClickHouse мы добавили табличную функцию сatBoostPool, которая принимает эти два файла как аргументы, а возвращает специальную таблицу типа file, временную, из которой можно читать данные.
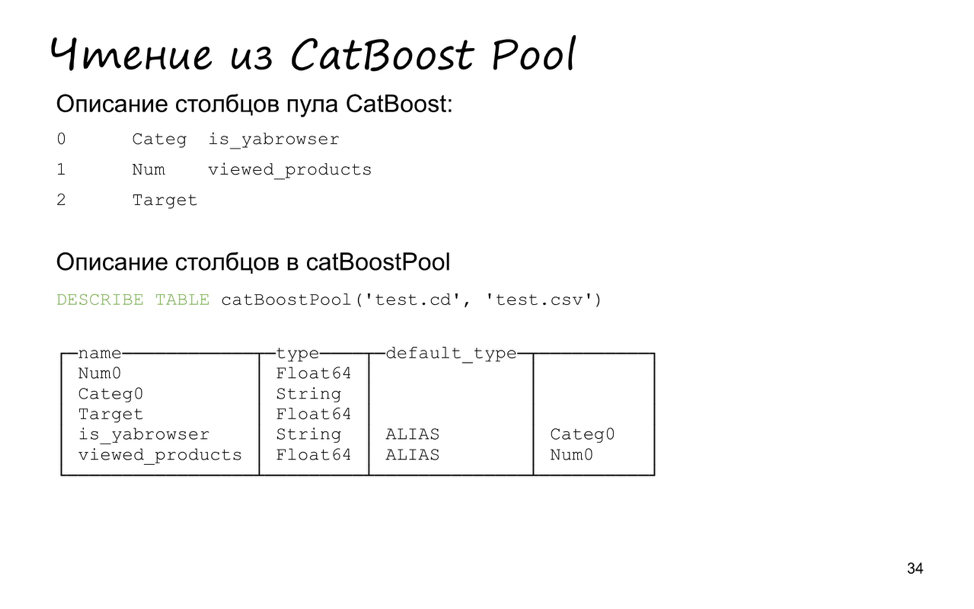
Я создал маленький CatBoost Pool из трех значений: два признака и таргет. В нем лежит пять строчек. Два — признаки, один — таргет, еще два дополнительно ALIAS.
Также поменялись местами числовая и категориальная фичи. Это сделано для удобства, чтобы можно было подавать параметры в функцию playModule в нужном порядке.

Если мы сделаем describe того, что выдаст запрос SELECT *, то значений стало меньше, остались всего два признаки в нужном порядке. Это снова сделано для того, чтобы можно было удобно использовать CatBoost Pool, а именно передавать звездочку в качестве остальных аргументов функции moduleEvaluate.

Давайте попробуем что-то применить. Для начала посчитаем вероятность покупки. Что мы будем использовать? В первую очередь, будем считать из CatBoost Pool, использовать функцию moduleEvaluate и передавать звездочку вторым параметром.
Последняя строчка, третья, применение сигмоида.

Давайте усложним запрос, посчитаем качество. Напишем предыдущий запрос как подзапрос ClickHouse. Всего мы добавили две значимые строчки, подсчет метрики logloss. Посчитали среднее, получили значение из таблицы.
Меня заинтересовало, насколько быстро такой запрос работает. Я провел три теста и получил вот такой график.
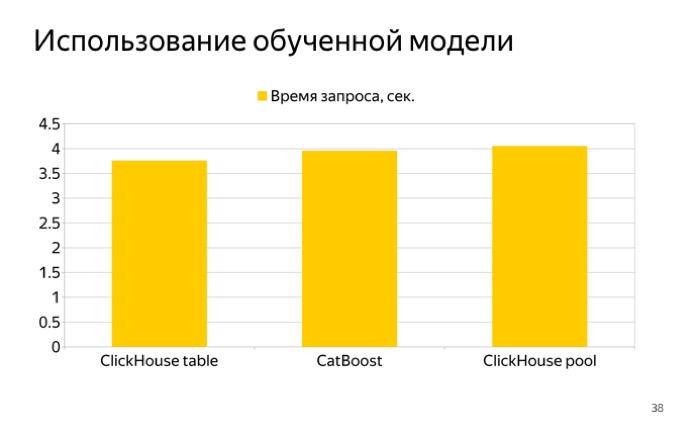
Слева — чтение из таблицы, справа — из пула. Видно, что столбцы почти одинаковые, разницы почти нет, но чтение из таблицы ClickHouse работает чуть быстрее — видимо, потому, что ClickHouse сжимает данные, и мы не тратим лишнее время на чтение из файла. А CatBoost Pool не сжимает, так что мы тратим время на чтение и на транспонирование признаков. Получается немного быстрее, но все же CatBoost Pool удобно использовать для тестов.
Подведем итоги. Интеграция заключается в том, что мы можем применять обученные модели, использовать CatBoost Pool и читать из него данные, что довольно удобно. В планах — добавить применение других моделей. Также под вопросом задача обучения внутри базы данных, но пока мы не решили, делать ли его. Если будет много запросов — всерьез над этим подумаем.
У нас есть русская и английская группы в Telegram, где мы активно отвечаем, есть GitHub, почтовая рассылка. Если возникают вопросы — можете прислать вопросы мне на почту, в Telegram или в Google-группу. Спасибо!
— Сначала о том, как устроен ClickHouse. ClickHouse — это аналитическая распределенная СУБД. Она столбцовая и с открытым исходным кодом. Самое интересное слово здесь — «столбцовая». Что оно значит?
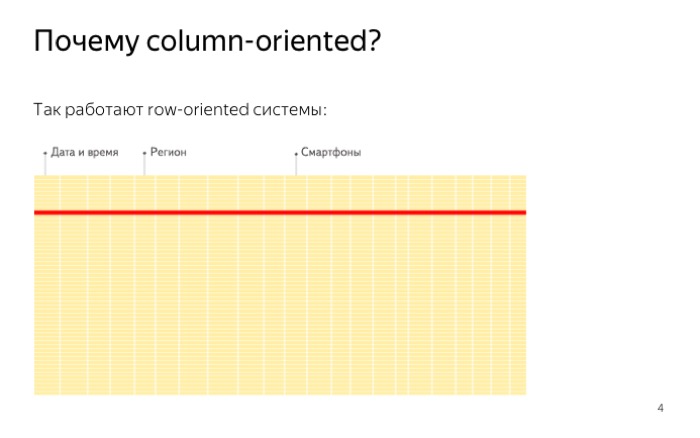
Вот как хранятся данные в обычных базах. Хранятся построчно, файлы записаны подряд. Другими словами, если нам нужно прочитать данные всего лишь для одного значения, мы вынуждены читать целую строчку. Это происходит из-за особенностей жесткого диска. Невозможно прочитать один байт, и случайное чтение стоит гораздо дороже, чем последовательное. В итоге мы читаем много лишних данных.

В ClickHouse все устроено совсем не так. ClickHouse хранит данные по столбцам, и значит, когда мы должны прочитать всего один признак, одну колонку, мы читаем ровно один файл. Это делается гораздо быстрее, примерно так, как на слайде.
Дополнительно ClickHouse сжимает данные, и то, что мы храним данные по столбцам, дает нам преимущество. Данные получаются более отдаленные и лучше сжимаются.
Сжатие нам тоже экономит место на диске и позволяет выполнять запросы быстрее во многих сценариях.
Насколько быстрый ClickHouse? Мы проводили тестирования по скорости в компании. Покажу лучше тестирования людей со стороны.
На графике сравнение ClickHouse, Spark и БД Amazon Redshift. ClickHouse на всех запросах работает в разы быстрее, хотя базы похожи по структуре, они тоже столбцовые.

ClickHouse поддерживает SQL-синтаксис. Это не честный SQL, это диалект. Также в ClickHouse есть возможность использовать специальные функции: работу с массивами, встроенные структуры данных или функции, специфичные для работы с URL. Вставка в ClickHouse тоже происходит быстро. Мы вставили данные и сразу же можем с ними работать. Получается работа в онлайне не только для запросов, но и для вставок.
Говоря про распределенные данные — ClickHouse может работать на ноутбуках, но прекрасно себя чувствует и на сотнях серверов. Например, в Яндекс.Метрике.
Перейдем ко второй части. Мы будем использовать некоторую вспомогательную задачу — предсказание вероятности покупки. Задача довольно простая. Допустим, есть данные из магазина. Хотим извлечь из них пользу, узнать больше информации о пользователях. Можно было бы считать вероятность покупки, что-то с ней делать. О том, что именно с ней делать, я подробно не буду рассказывать. Расскажу на примере. Например, можно разделить пользователей на две категории: хороших и не очень. Хорошим показывать больше рекламы, не очень хорошим меньше. И — экономить на рекламе либо получать бо́льшую конверсию.
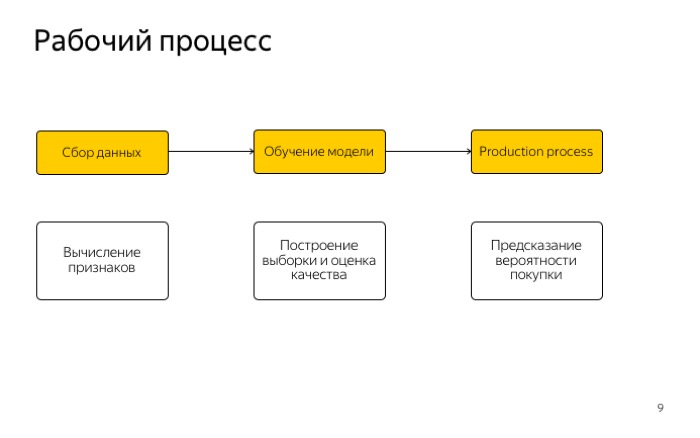
Посмотрим на рабочий процесс. Он очень простой и всем вам знаком, три этапа: работа с признаками, сбор данных и получение выборки.
Второй этап — обучение модели и оценка ее качества.
Последнее — использование модели в продакшене.
Откуда брать данные? Можно брать из Яндекс.Метрики, там данные хранятся внутри ClickHouse. Мы также будем использовать ClickHouse. Но данные, что мы брали, мы брали с использованием Logs API метрики. Мы представляли себя внешним пользователям и загружали данные с помощью того, что доступно внешним людям.
Какие данные мы могли получить? Во-первых, информацию о просмотренных страницах, какие товары видел, что он посещал. Также это состояние корзины пользователя и какие покупки он делал для этого.
Последнее — устройство, с которого пользователь заходил, тип браузера, десктоп или мобильный клиент.

То, что мы храним данные в ClickHouse, дает нам преимущества. Конкретно в том, что мы можем посчитать практически любые признаки, которые можем придумать, так как ClickHouse хранит данные в неагрегированном виде, есть пример — вычисление средней длительности сессии.

Пример имеет несколько особенностей. Первая — отсечение по датам. Мы использовали start и end_date, и ClickHouse с этим эффективно работает, он не будет читать то, что мы не запросили. Также мы использовали sampling: сказали, что будем читать 1/10 часть данных. ClickHouse делает это эффективно, он выбрасывает ненужные данные сразу после прочтения данных с диска.

Упомяну обучение моделей. Какие классификаторы мы использовали?
У нас есть обученная модель, она выдает хорошее качество. Как теперь ее внедрять?
Казалось бы, вопрос простой. Давайте делать просто: каждый понедельник выгружать из ClickHouse данные за предыдущий месяц, запускать питоновские скрипты, получать вероятность покупки и загружать обратно, скажем, в ту же таблицу ClickHouse. Это все хорошо работает, просто и эффективно написано, но возникают некоторые недостатки.
Первый недостаток в том, что данные должны выгружаться. Это может тормозить, причем не внутри ClickHouse, а скорее всего внутри питоновских скриптов.
Второй недостаток — мы готовим ответы заранее, и если мы считали вероятность покупки с понедельника на воскресенье, мы не можем это просто узнать со среды по четверг, например, или за прошлый год.
Один из способов это решить — внимательно посмотреть модель. Модель устроена просто: операции сложения, умножения, условные переходы. Давайте запишем модель в виде запросов ClickHouse, и сразу избавимся от наших недостатков. Во-первых, мы не используем выгрузку данных, а во-вторых, можем подставить любые даты и все будет работать.
Но возникает вопрос: какие алгоритмы мы можем перенести в СУБД? Первое, что приходит на ум, это использование линейных классификаторов.

Для его применения нужно перемножить векторы весов на значение признаков и сравнить с каким-то порогом. Для примера, я обучил наши выборки логистической регрессии и получил качество log loss 0,041. Далее я проверил, насколько быстро это работает в ClickHouse, написал запрос, и он отработал меньше, чем за полсекунды. Неплохой результат.
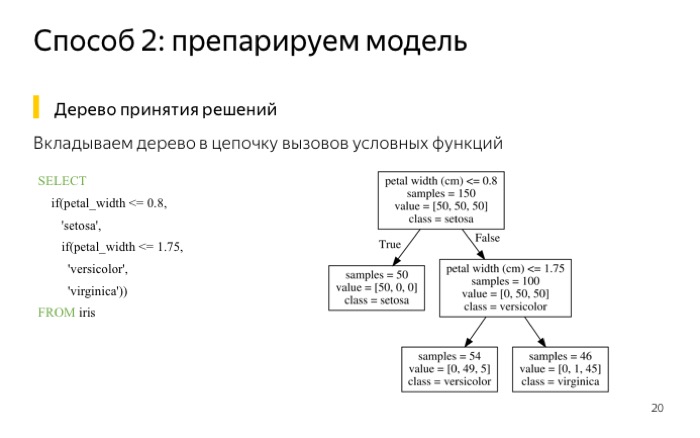
Если у нас что-то сложнее, чем линейная модель, например, деревья, их тоже можно написать в виде запроса ClickHouse. Что я сделал? Взял выборку ирисов. Эта выборка хороша тем, что для нее можно обучить маленькое дерево с глубиной два. У нее получается ошибка меньше 5%. Если вам так повезло, что у вас хорошая выборка, вы можете использовать маленькое дерево.

Можно написать запрос, условно, в виде двух функций выбора, и все тоже будет хорошо работать. Ингридиентный бустинг или лес, например. Нужно посчитать сумму или среднее. Я тоже протестировал это для маленького леса, 100 деревьев глубиной 3, в итоге получил качество даже хуже, и работает он в ClickHouse 2,5 секунды.
Не все так плохо, если бы я обучал больше деревьев, качество было бы лучше. Но почему я так не делал? Вот почему.

Вот как выглядит третья часть леса на 100 деревьев. Мне видно, что это очень похоже на лес. И если сделать запрос еще больше, то ClickHouse начинает просто тормозить на парсинге.

И получили дополнительные недостатки. Помимо того, что запрос очень длинный, мы вынуждены его придумывать, и это может медленно работать в самой БД. К примеру, для деревьев, чтобы применить их, ClickHouse вынужден считать значение в каждом узле дерева. И это неэффективно, ведь мы могли бы посчитать значения только на пути от корня к листу.
Возникает проблема с производительностью, что-то может тормозить и неэффективно работать. Это не то, что мы хотим.

Мы хотели бы более простые вещи: сказать базе, что давай ты сама будешь разбираться с тем, как применять модель, мы просто скажем тебе, что здесь лежит библиотека машинного обучения, а ты мне дай просто функцию modelEvaluate, в которую мы положим список наших признаков. Такой подход, во-первых, обладает всеми преимуществами предыдущего, а во-вторых, перекладывает всю работу на базу данных. И всего есть один недостаток — ваша база должна поддерживать применение данных моделей.
В ClickHouse мы это реализовали для CatBoost, конечно, протестировали. Получили наилучшее качество, при том что я обучал… Время обучения не очень большое, всего 4 секунды. Это сравнимо хорошо по сравнению с лесом 100 глубиной 3.

Что можно видеть в итоге?
Если вам важно видеть скорость работы, скорость обременения алгоритма, не так важно качество, то можно использовать логистическую регрессию, это все будет быстро работать.
Если вам важно качество, то обучите CatBoost и используйте его. Как же использовать CatBoost в ClickHouse?

Нужно сделать несколько довольно простых действий. Первое — описать конфигурацию модели. Всего 4 значимых строки. Тип модели — сейчас это CatBoost, возможно, когда-то добавим новое.
Имя модели, которое будет использоваться как параметр функции modelEvaluate().
Расположение обученной модели на файловой системе.
Время обновления. Здесь 0 — это значит, мы не будем перечитывать материал диска. Если стояло бы 5, перечитывали бы каждые 5 секунд.

Далее нужно сказать ClickHouse, где лежит файл с конфигурацией, это нижний параметр на слайде. Там используется звездочка, это значит, что все файлы, что подходят под эту маску, будут загружены.
Также нужно сказать ClickHouse, где лежит сама библиотека машинного обучения, а именно модуль обертки для CatBoost.

Все, когда мы это указали, у нас получается возможность функцию modelEvaluate(), которая принимает первым аргументом имя модели из конфигурационного файла, остальным наши признаки. Причем надо указывать сначала числовые признаки, затем категориальные. Но не беспокойтесь, если вы что-то перепутаете. Во-первых, ClickHouse скажет вам, что у вас ошибка. Во-вторых, вы можете протестировать качество и понять, что все не так, как вы думали.

Чтобы было удобнее тестировать, мы также добавили поддержку чтения из пула данных CatBoost. Наверное, кто-то работал с CatBoost из консоли вместо того, чтобы работать с ним из Python или из R. Тогда вам пришлось бы использовать специальный формат описания вашей выборки. Формат довольно простой — всего два файла. Первый — TSV c тремя колонками, номер признака и его тип: категориальный, числовой или таргет. Плюс дополнительный опциональный параметр имени. Второй файл — сами данные, тоже TSV.

Как раз в ClickHouse мы добавили табличную функцию сatBoostPool, которая принимает эти два файла как аргументы, а возвращает специальную таблицу типа file, временную, из которой можно читать данные.
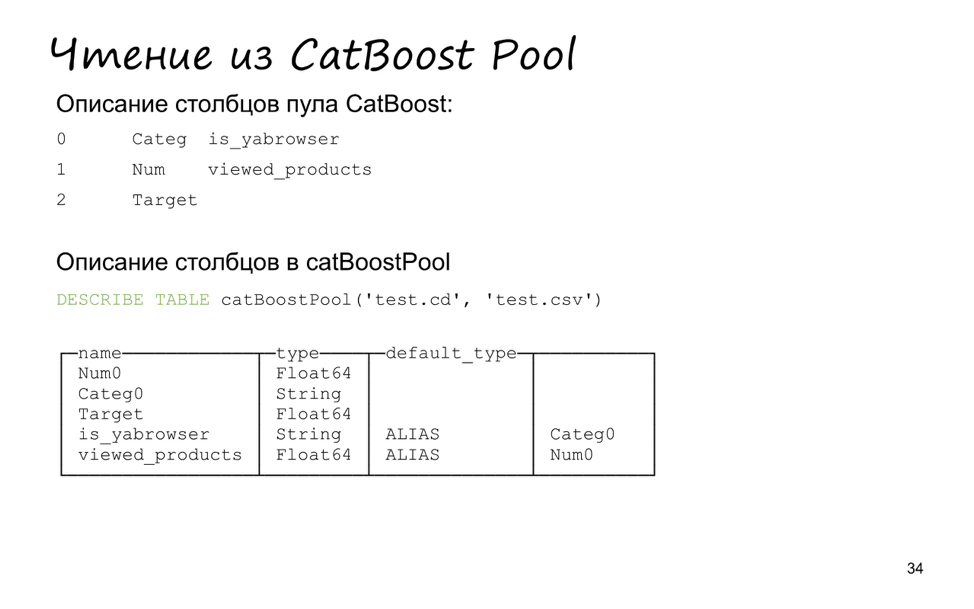
Я создал маленький CatBoost Pool из трех значений: два признака и таргет. В нем лежит пять строчек. Два — признаки, один — таргет, еще два дополнительно ALIAS.
Также поменялись местами числовая и категориальная фичи. Это сделано для удобства, чтобы можно было подавать параметры в функцию playModule в нужном порядке.

Если мы сделаем describe того, что выдаст запрос SELECT *, то значений стало меньше, остались всего два признаки в нужном порядке. Это снова сделано для того, чтобы можно было удобно использовать CatBoost Pool, а именно передавать звездочку в качестве остальных аргументов функции moduleEvaluate.

Давайте попробуем что-то применить. Для начала посчитаем вероятность покупки. Что мы будем использовать? В первую очередь, будем считать из CatBoost Pool, использовать функцию moduleEvaluate и передавать звездочку вторым параметром.
Последняя строчка, третья, применение сигмоида.

Давайте усложним запрос, посчитаем качество. Напишем предыдущий запрос как подзапрос ClickHouse. Всего мы добавили две значимые строчки, подсчет метрики logloss. Посчитали среднее, получили значение из таблицы.
Меня заинтересовало, насколько быстро такой запрос работает. Я провел три теста и получил вот такой график.

Слева — чтение из таблицы, справа — из пула. Видно, что столбцы почти одинаковые, разницы почти нет, но чтение из таблицы ClickHouse работает чуть быстрее — видимо, потому, что ClickHouse сжимает данные, и мы не тратим лишнее время на чтение из файла. А CatBoost Pool не сжимает, так что мы тратим время на чтение и на транспонирование признаков. Получается немного быстрее, но все же CatBoost Pool удобно использовать для тестов.
Подведем итоги. Интеграция заключается в том, что мы можем применять обученные модели, использовать CatBoost Pool и читать из него данные, что довольно удобно. В планах — добавить применение других моделей. Также под вопросом задача обучения внутри базы данных, но пока мы не решили, делать ли его. Если будет много запросов — всерьез над этим подумаем.
У нас есть русская и английская группы в Telegram, где мы активно отвечаем, есть GitHub, почтовая рассылка. Если возникают вопросы — можете прислать вопросы мне на почту, в Telegram или в Google-группу. Спасибо!
